概要
AmplifyのAPI機能で生成されたDynamoDBのテーブルに対し、S3に保存されたcsvデータを流し込む一手段です。
流れは以下3ステップ。
1. "apmlify add API" + "amplify push" でDynamoDBテーブルを作成(ここは説明しません)
2. S3バケットに流し込みたいcsvファイルを保存(複数可)
3. Lambdaにデータ流し込みの関数を作成し実行
背景
職場で、アプリケーションのバックエンドをLaravelからAWS Amplifyに移行することとなりました。
それに伴いデータもMySQLからDynamoDBにデータの移行が必要となり、
テーブルデータをcsvに書き出した後Dynamoでインポートしようと試みました。
このミッションに壁として立ちはだかったのが、DynamoDBにはcsvのインポート機能がありません。
(エクスポート機能はあり。)
なんでインポートはないねんって感じですが、__"Dynamo csv インポート"__でググると一応方法は出てきます。
単純にcsvファイルをDynamoDBに流し込む手順については、
AWS公式のブログ【Amazon DynamoDB への CSV 一括取り込みの実装】
にて分かりやすく手順が説明されています。
上記記事の概要は、__S3に流し込みたいcsvを保存し、流し込み用に新しくテーブルも作成する__という物です。
記事内でCloudFormationのテンプレートが配布されており親切簡単なのですが、
この手順ではAmplifyですでに生成されているテーブルに流し込むことができません。
本記事では、AmplifyのAPI機能で生成されたDynamoDBテーブルに対し、
S3に保存されたcsvファイルのデータを流し込む手順を紹介します。
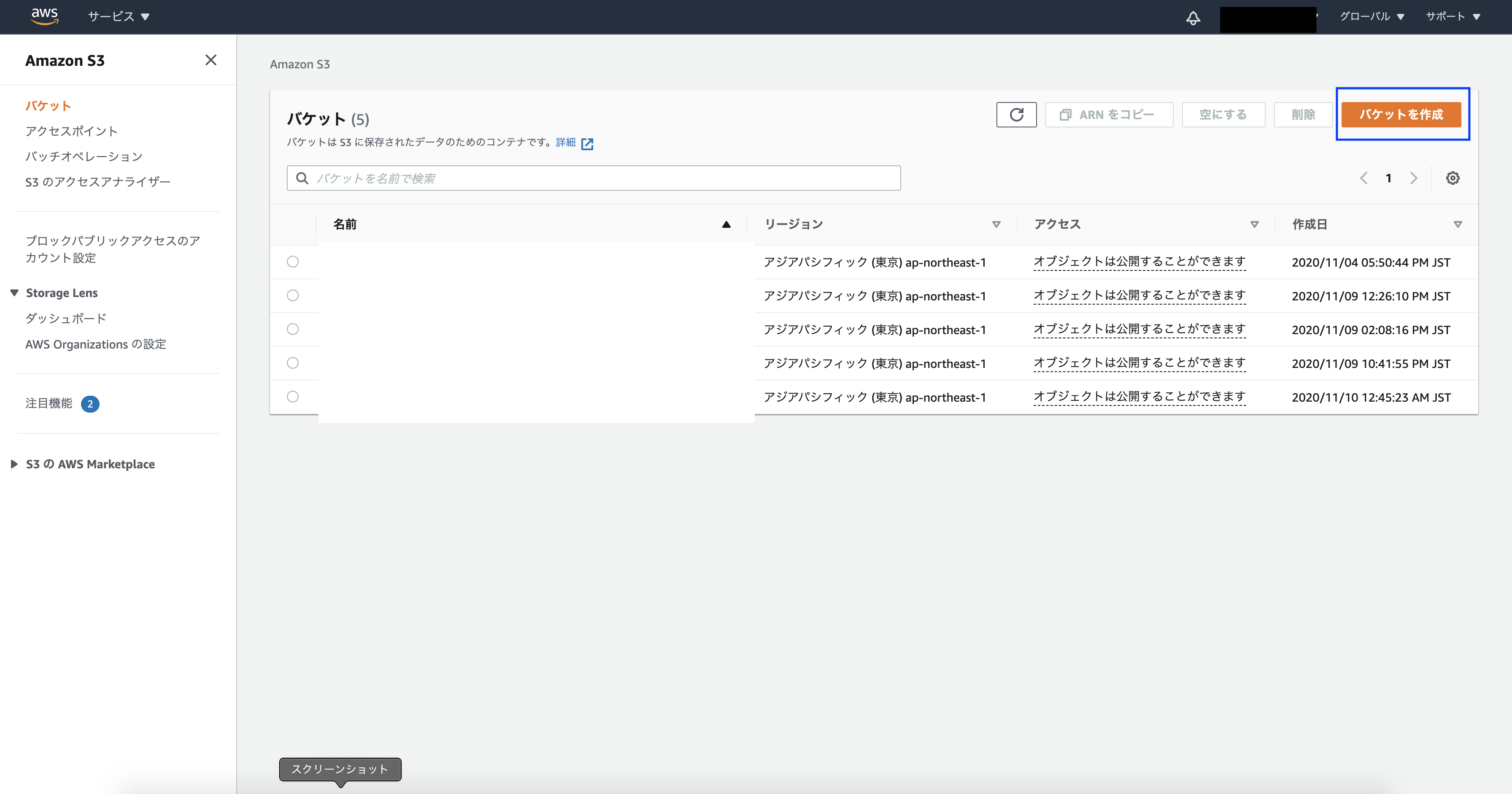
手順1 - S3のバケットを作成 -
S3に任意の名前でバケットを作成し、テーブルデータの入ったcsvファイルを保存しましょう。
S3の管理画面から【バケットを作成】
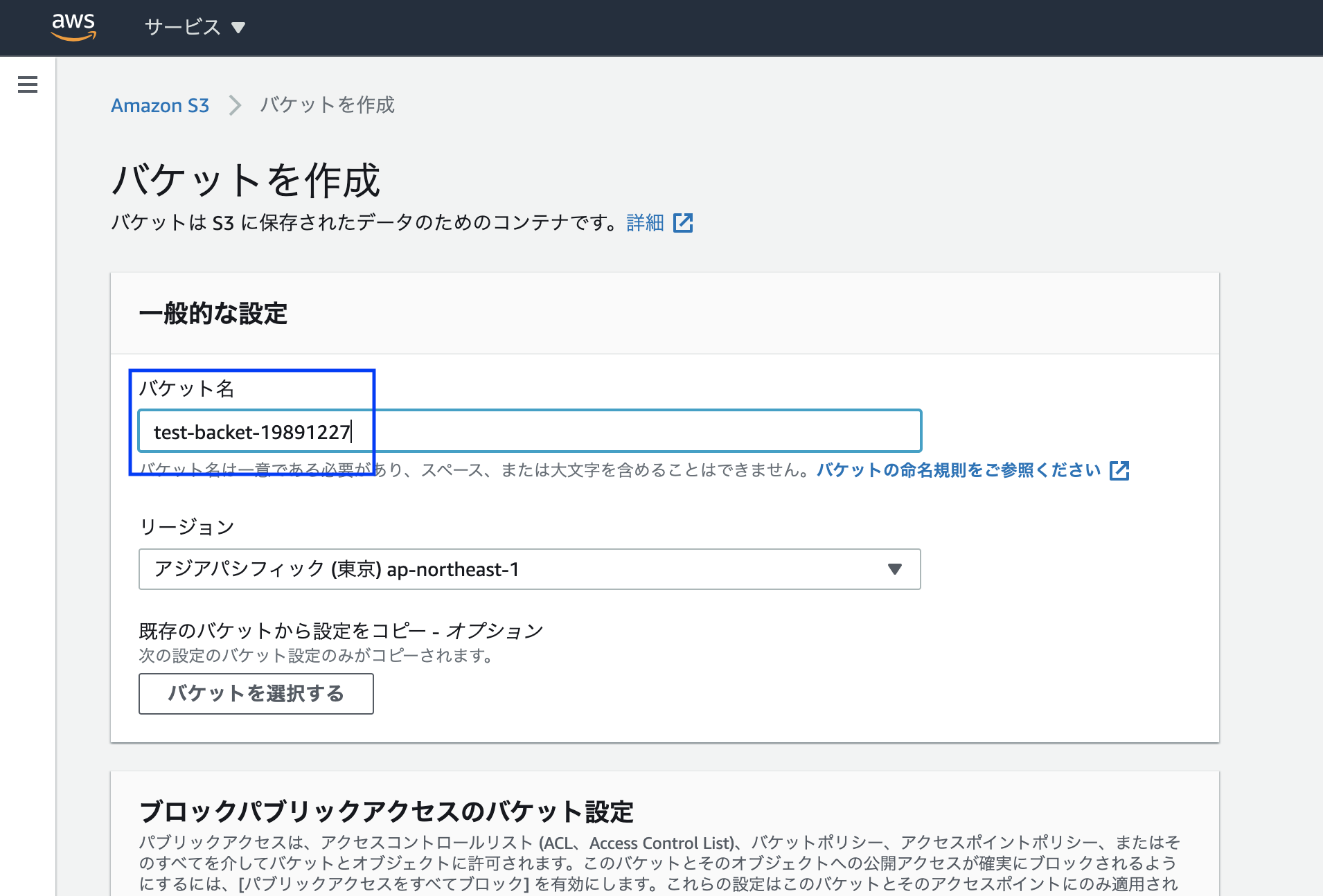
バケット名を決めます。
- 名前は重複不可
- 大文字不可
などルールがあるので注意しましょう。
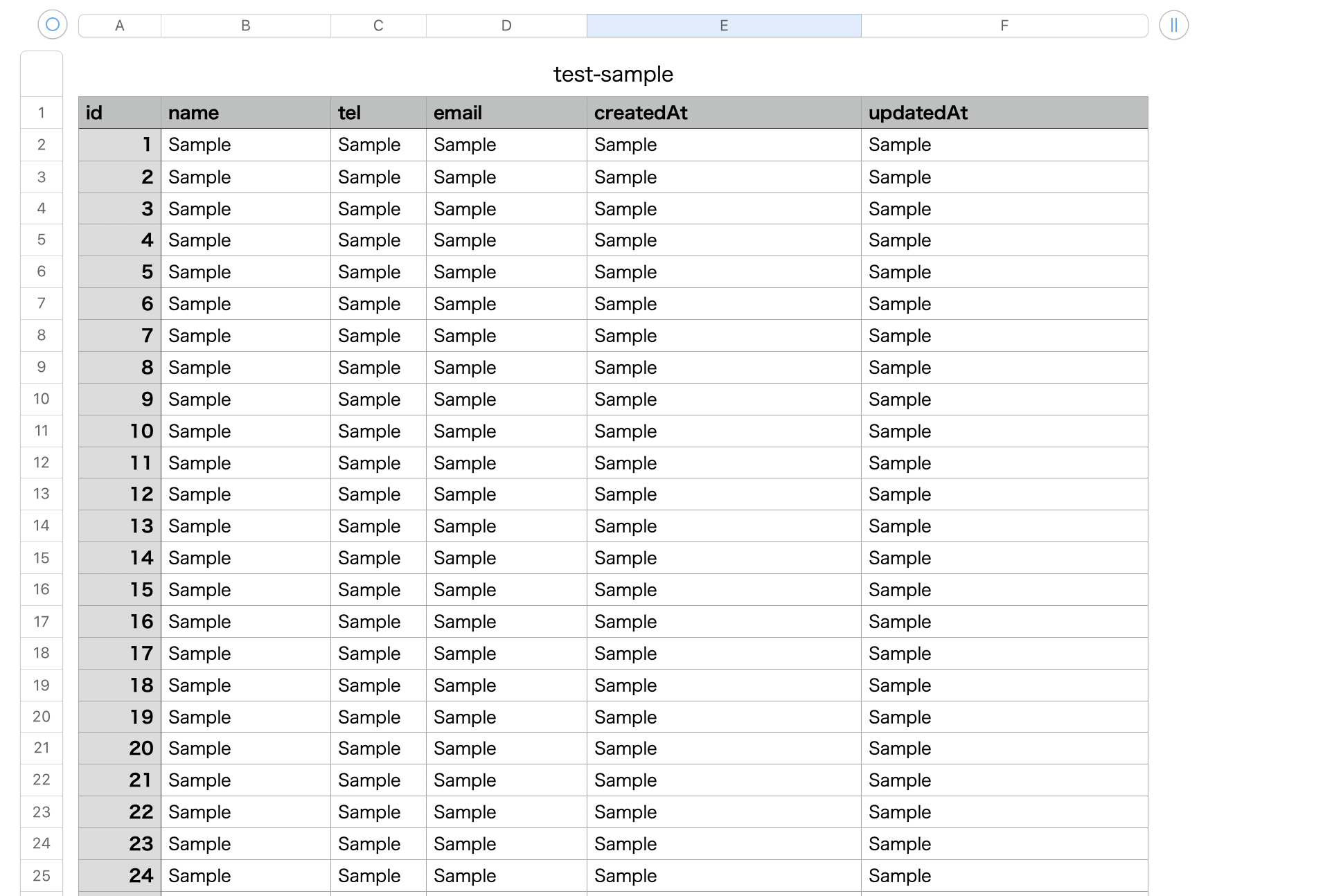
手順2 - バケットにcsvファイルを保存 -
今回のサンプルデータは以下のようにしました。
1テーブルに対し、csv1ファイルとしてください。
※ 注意点として、カラム名をAmplifyで定義したスキーマと合わせましょう。
とくにSQLがスネークケースで命名されている場合、キャメルケースへの変更が必要です。
作成したS3バケットに保存します。
複数ある場合はすべて同じバケット内に保存してOKです。
手順3 - Lambda関数を記述 -
Lambdaで流し込みの処理を作ります。
Lambda管理画面で新規関数を作成します。
関数作成画面で、以下のように設定してください。
- 一から作成
- 関数名は適当に設定
- ランタイムにPython3.7を設定(Lambda関数はいくつかの言語で記述できますが、今回はPythonを使用)
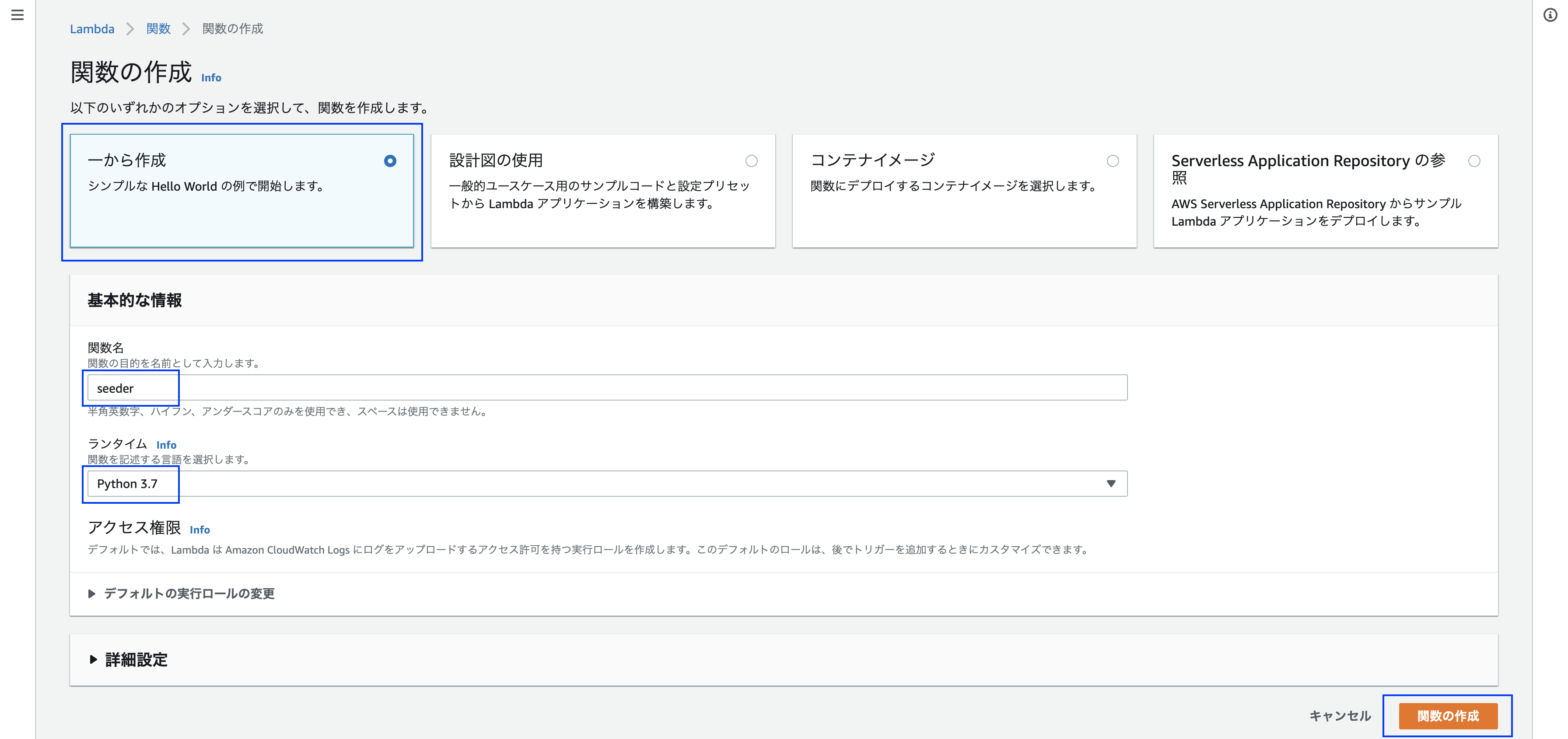
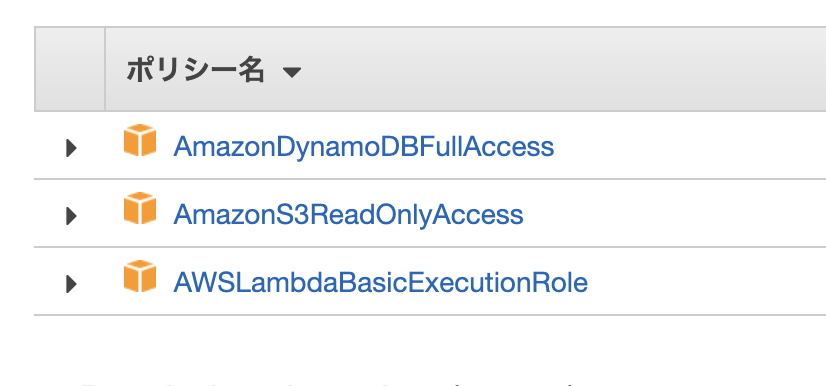
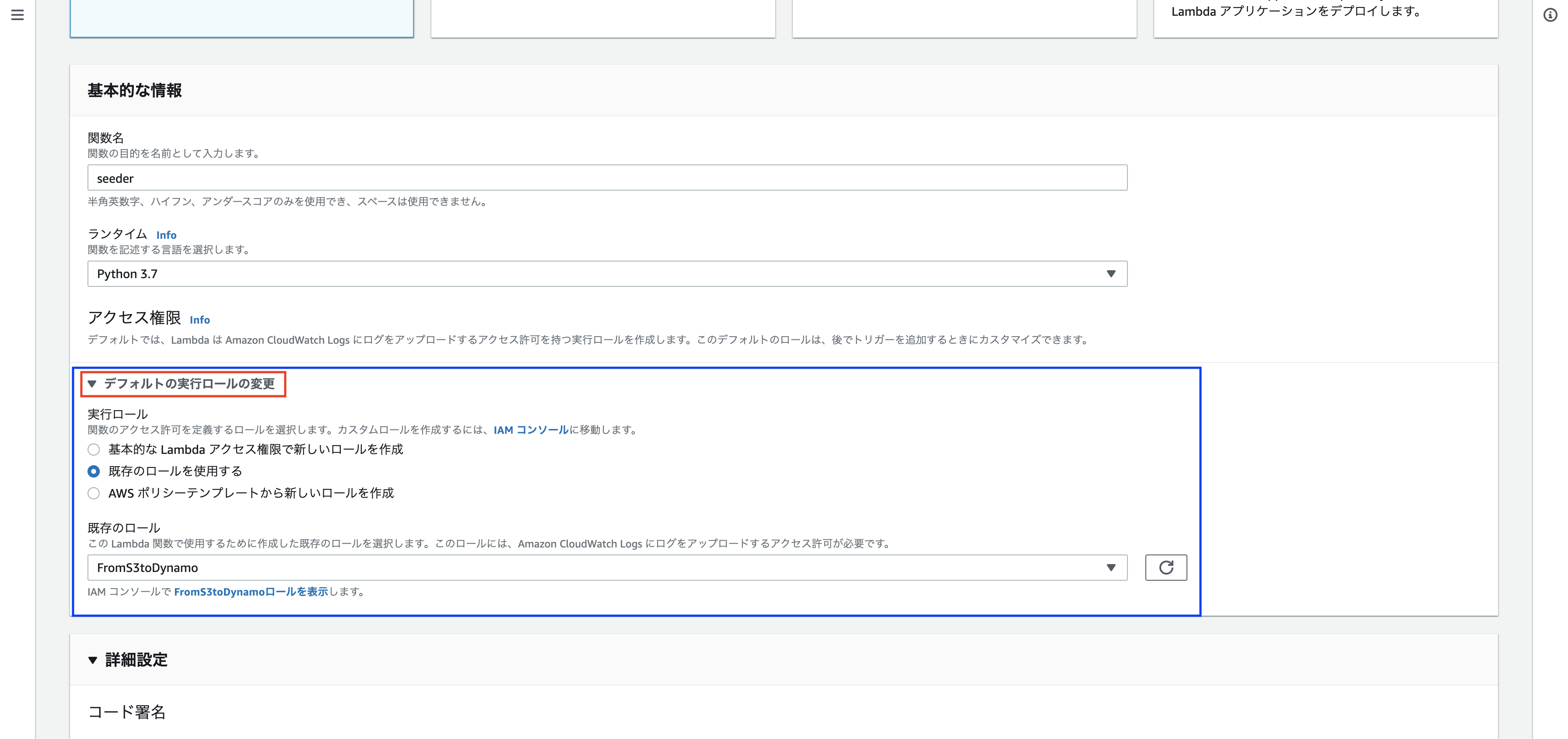
※ 注意点として【デフォルトの実行ロールの変更】の設定が必要です。
S3やDynamoDBの操作権限をLambdaに与える為です。
IAMで、以下のポリシー(権限)を持ったIAMロールを作成しておいてください。
作成したロールを、Lambdaの作成画面でアタッチします。
続いて関数を記述します。
とりあえず動かすという場合は以下をコピペでOKです。
import json
import boto3
import os
import csv
import codecs
import sys
s3 = boto3.resource('s3')
dynamodb = boto3.resource('dynamodb')
# S3バケット名
bucket = "test-backet-19891227"
# csvファイル名と流し込みたいDynamoDBテーブル名をペアで設定
files = [
{
'csv': "test-sample.csv",
'tableName': "User-wvtmmaqkirg3dksvj2dbasup44-dev"
},
]
def lambda_handler(event, context):
for file in files:
#get() does not store in memory
try:
print(file['csv'])
obj = s3.Object(bucket, file['csv']).get()['Body']
except:
print("S3オブジェクトを読み込めませんでした")
try:
table = dynamodb.Table(file['tableName'])
except:
print("DynamoDBを読み込めませんでした")
batch_size = 100
batch = []
#DictReader is a generator; not stored in memory
for row in csv.DictReader(codecs.getreader('utf-8')(obj)):
# 行数が100になったタイミングで一度DBへ書き込み
if len(batch) >= batch_size:
write_to_dynamo(batch, file['tableName'])
batch.clear()
batch.append(row)
if batch:
write_to_dynamo(batch, file['tableName'])
return {
'statusCode': 200,
'body': json.dumps('完了')
}
def write_to_dynamo(rows, tbl):
try:
table = dynamodb.Table(tbl)
except:
print("DynamoDBを読み込めませんでした")
try:
with table.batch_writer() as batch:
for i in range(len(rows)):
batch.put_item(
Item=rows[i]
)
except:
print("挿入処理に失敗しました")
- importで必要なライブラリを呼び出し
- 定数backetに作成したS3バケットの名前を設定
- filesに、辞書型を配列で設定します。ここで、キーcsvにはS3に保存したcsvファイル名を、キーtableNameには流し込みたいテーブル名を記載(複数のcsvファイルを流し込みたい場合は、配列を伸ばして行けばOK)
- その後はcsvから1列ずつ取り出してDynamoDBに貼り付けていく処理
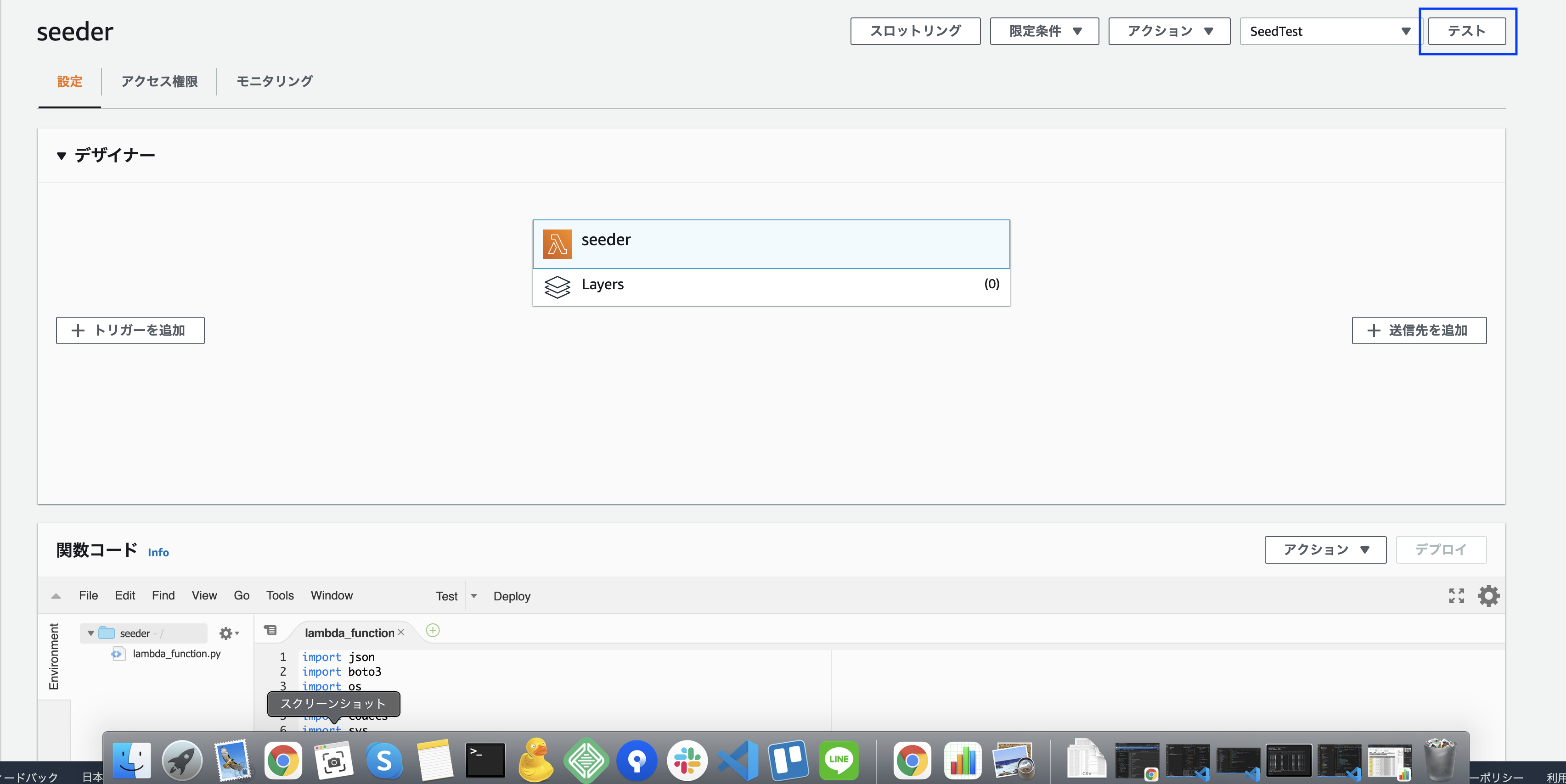
手順4 - Lambda関数を実行 -
今回は手動で関数を実行します。(今回のケースでは一度実行したら終わりなので)
関数の管理画面で、右上の「テスト」をクリックすると関数を実行できます。
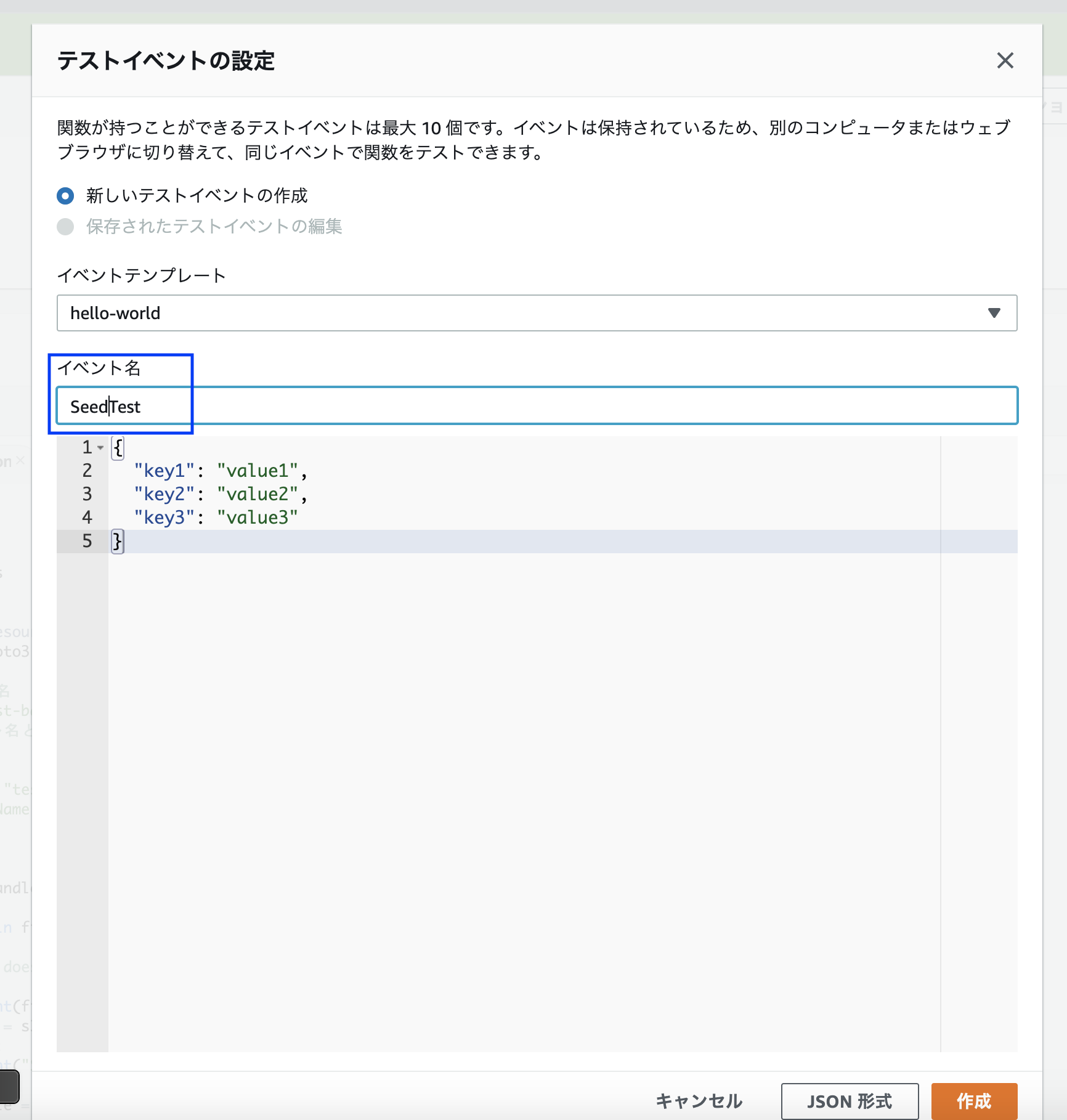
テストイベントとして登録する必要がありますが、適当な名前をつけ、その他はノータッチでOKです。
(関数に引数などある場合はここで設定)
実行すると、DynamoDBにCSVデータが書き込まれています。
試したところ、データ500個に対し10秒程度で完了しました。
まとめ
既存のDynamoDBテーブルにcsvからデータを流し込むことができました。
新API+DBで、実データを用いてフロントの表示を確認したい時など有効かなと思います。
Lambda関数実行でエラーが出た場合は、CloudWatchで詳細のエラーログが見れるので、確認してみてください。
私の場合は、csvの中身が若干崩れていたことで、動作しないエラーにハマりました。
(JSON型のデータをSQLに入れていた為、カンマ区切りでcsv化した時にJSONがバラバラになってしまっていました。。)
実際のDB移行時は、当分は移行前後の状態を同時運用して様子をみたいという場合もあるでしょう。
その場合は、CloudFormationでSQLとDynamoDBを同期するような形でLambdaを動かす形になるのかなと思います。
AWSにあまり触れたことがなかった為調べながらでしたが、なんとかできました。。
おかしな点などあればコメントでお知らせいただけると嬉しいです。
参考記事
コードなど、以下記事を参考にさせていただいています。
AWS公式のブログ【Amazon DynamoDB への CSV 一括取り込みの実装】