はじめに
アプリの企画やマーケティング担当の皆さん、 「アプリレビュー」 を最大限活用できていますか?
「大量のレビューを目視でチェックするのは限界…」
「クレームばかりに見えて、改善のヒントが見つからない…」
もしそう感じているなら、非常にもったいないことです。アプリレビューは、ユーザーがわざわざ時間を割いて届けてくれた「プロダクト改善のヒント(宝の山)」そのものです。
今回は、Google Colab(ブラウザで動く無料ツール)を使って、iOS/Androidのレビューを自動収集し、AIで「アプリレビュー」を客観的な改善提案に変える最強の時短術をご紹介します。
プログラミングの知識は不要です。この記事にあるコードをコピペするだけで、今日からあなたも「データで語れる」分析のプロになれます!
なぜ今、レビュー分析なのか?
よくある「誤解」と「機会」
レビューに対して、以下のようなイメージを持っている方は多いかもしれません。
- ❌ 誤解: レビューはクレームばかりで気が滅入る
- ❌ 誤解: 極端な意見(★1/★5)が多くて参考にならない
- ❌ 誤解: 結局、機能追加は「偉い人の鶴の一声」で決まる
しかし、データを正しく扱うことで、これらは 「宝の山」 に変わります。
「木」だけでなく「森」を見る
個別のレビューを読み込む(定性分析)ことは、ユーザーの熱量や具体的な利用シーンを知る上で重要です。
しかし、それだけでは「全体で何が起きているか」が見えづらく、主観に左右されがちです。
そこで必要なのが 定量分析(森を見るアプローチ) です。数千件のレビューをデータとして扱い、単語頻度や評価推移を可視化することで、「なんとなく評判が悪い」ではなく「先月のアップデート以降、ログイン周りで不満が急増している」 **という客観的な事実(ファクト)を導き出せます。
実践!レビュー分析のステップ
今回は、環境構築不要の Google Colab を使って、以下の流れで分析を行います。
- データ収集: 両OSのストアからレビューを自動取得
- 定量分析: 評価分布と時系列推移の可視化
- 定性分析: 形態素解析とWordCloudによる可視化
手順1:Google Colabの準備
Google Colab にアクセスし、「ノートブックを新規作成」をクリックしてください。
これはGoogleが提供する無料のツールで、ブラウザ上で動きます。
手順2:ライブラリの準備
分析に必要なライブラリを一括でインストールし、読み込みます。
以下のコードを最初のセルに貼り付けて実行(再生ボタンをクリック)してください。
# 1. ライブラリのインストール
!pip install google_play_scraper japanize-matplotlib janome
# 2. ライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
from google_play_scraper import Sort, reviews_all
# from app_store_scraper import AppStore <-- 削除
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
from collections import Counter
# グラフのスタイル設定
sns.set(font="IPAexGothic")
plt.rcParams['figure.figsize'] = (10, 6)
print("✅ 環境構築が完了しました")

手順3:レビューデータの取得
次は、対象アプリのIDを指定してデータを取得します。
※この収集方法はこちらの記事を参考にしております
Android (Google Play) の場合
アプリのパッケージ名(URLの id= の後ろの部分)を指定します。
例:https://play.google.com/store/apps/details?id=com.example.app なら com.example.app です。
!pip install google-play-scraper
from google_play_scraper import app
from google_play_scraper import Sort, reviews_all
import numpy as np
import pandas as pd
# アプリケーションのパッケージ名
app_id = "jp.co.br31ice.android.thirtyoneclub" # ←ここにapp_idを入れる!
# レビューの取得
# sleep_milliseconds を調整することで、スクレイピングの間隔を制御できます。
# lang と country を設定することで、取得するレビューの言語と国を指定できます。
# sort を設定することで、レビューの並び順を指定できます。
android_reviews = reviews_all(
app_id = app_id,
sleep_milliseconds=1000,
lang='ja',
country='jp',
sort=Sort.MOST_RELEVANT,
)
# 取得したレビューをDataFrameに変換
android_reviews_df = pd.DataFrame(android_reviews)
# DataFrameをCSVファイルとして保存
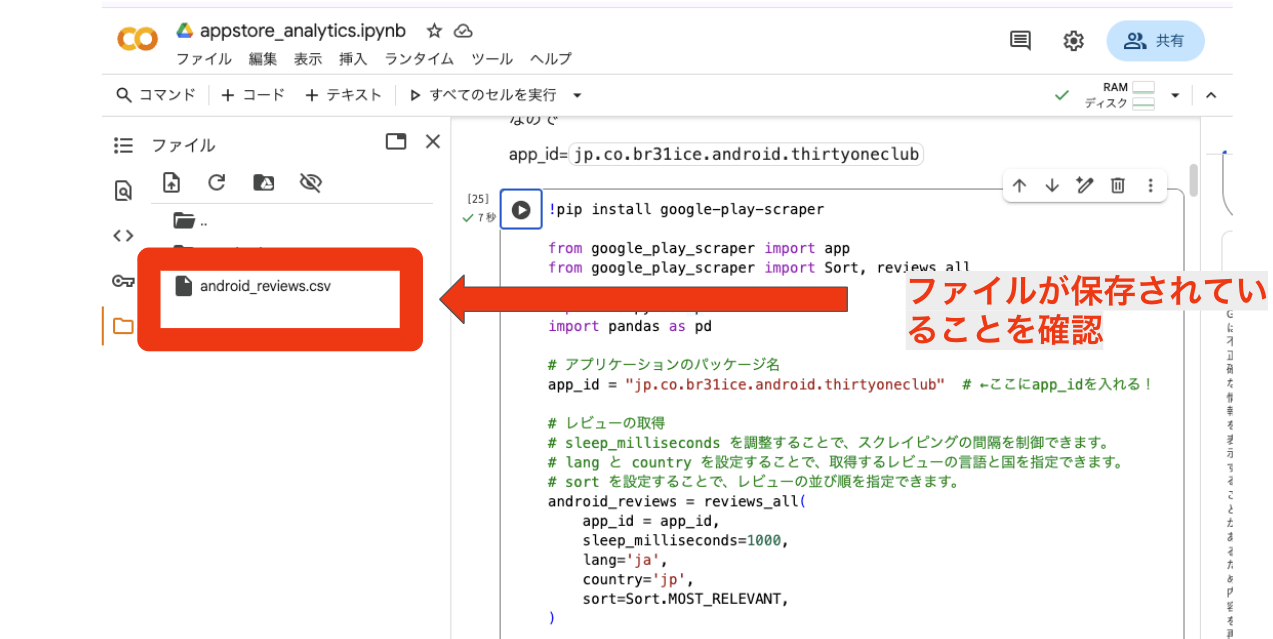
android_reviews_df.to_csv('android_reviews.csv', index=False)
print("android_reviews.csv が保存されました。")
# DataFrameの表示
display(android_reviews_df)
成功すると、左側のフォルダにCSVファイルが出力されます!
iOS (App Store) の場合
アプリ名とIDを指定します。
(※App Storeからは直近から最大500件しか取得できません😭)
例:https://apps.apple.com/jp/app/example-app/id123456789 なら app_name は example-app、app_id は 123456789 です。
import requests
import xml.etree.ElementTree as ET
import time
import pandas as pd
# ---------------------------------------------------------
# 1. 設定(Android版の引数設定と同じ感覚で変更できます)
# ---------------------------------------------------------
ios_app_id = '910133705' # ←ここにアプリIDを入れる
country = 'jp' # 国コード
page_limit = 10 # 取得するページ数
# ---------------------------------------------------------
# 2. レビューの取得処理(スクリプト実行)
# ---------------------------------------------------------
ios_reviews_list = []
# XMLの名前空間定義
ns = {
'atom': 'http://www.w3.org/2005/Atom',
'im': 'http://itunes.apple.com/rss'
}
print(f"アプリID: {ios_app_id} のレビュー取得を開始します...")
for page in range(1, page_limit + 1):
url = f"https://itunes.apple.com/{country}/rss/customerreviews/page={page}/id={ios_app_id}/sortby=mostrecent/xml"
try:
# データ取得
response = requests.get(url)
response.raise_for_status()
# 解析
root = ET.fromstring(response.content)
entries = root.findall('atom:entry', ns)
# データが無い、またはアプリ情報のみ(1件以下)の場合は終了
if len(entries) <= 1:
if page > 1:
print(f"ページ{page}でデータが途切れました。取得を終了します。")
break
# データの抽出(最初の1件はアプリ情報なのでスキップ)
for entry in entries[1:]:
version_element = entry.find('im:version', ns)
review_version = version_element.text if version_element is not None else ''
# 辞書を作成(Android版のカラム名に合わせています)
review = {
'reviewId': entry.find('atom:id', ns).text,
'userName': entry.find('atom:author/atom:name', ns).text,
'userImage': None,
'content': entry.find('atom:content[@type="text"]', ns).text,
'score': int(entry.find('im:rating', ns).text), # 数値化
'thumbsUpCount': 0,
'reviewCreatedVersion': review_version,
'at': entry.find('atom:updated', ns).text,
'replyContent': None,
'repliedAt': None,
'appVersion': review_version
}
ios_reviews_list.append(review)
print(f"ページ{page} 完了 (現在 {len(ios_reviews_list)} 件)")
time.sleep(3) # 負荷軽減
except Exception as e:
print(f"エラー発生(ページ{page}): {e}")
break
# ---------------------------------------------------------
# 3. DataFrameへの変換・保存・表示
# ---------------------------------------------------------
ios_reviews_df = pd.DataFrame(ios_reviews_list)
# 日付型への変換(分析しやすくするため)
if not ios_reviews_df.empty:
ios_reviews_df['at'] = pd.to_datetime(ios_reviews_df['at'])
# CSV保存
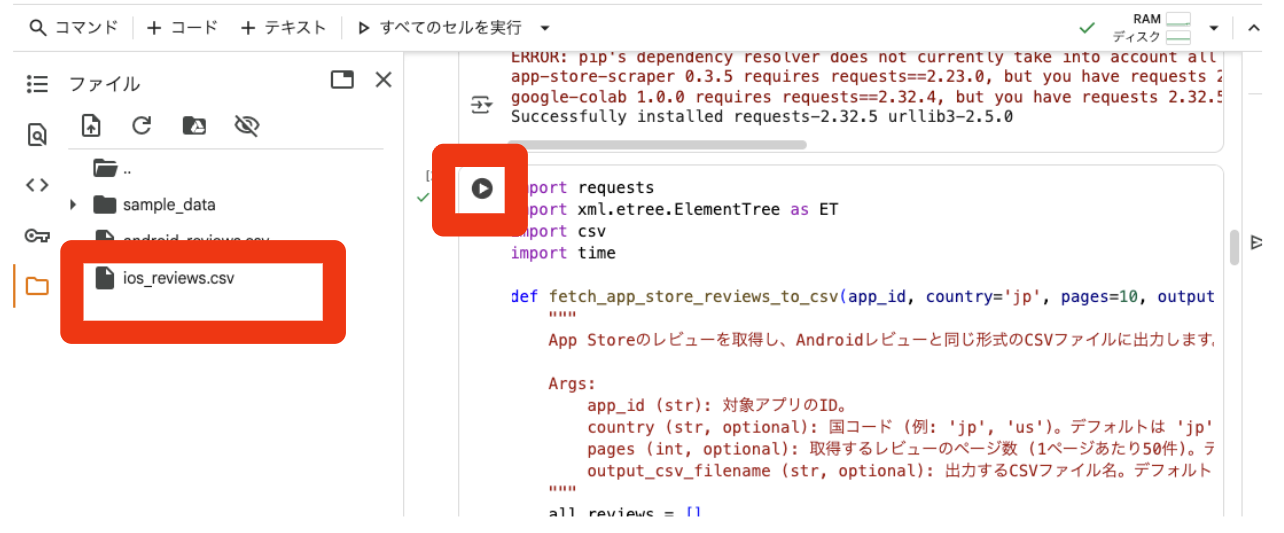
ios_reviews_df.to_csv('ios_reviews.csv', index=False)
print("ios_reviews.csv が保存されました。")
# 表示
display(ios_reviews_df)
こちらも同様に実行後、CSVファイルが保存されているか確認してみてください
データの統合
両OSのデータを一つにまとめます。
import pandas as pd
# CSVファイルを読み込む
try:
android_df = pd.read_csv('android_reviews.csv')
print("android_reviews.csv を読み込みました。")
except FileNotFoundError:
print("エラー: android_reviews.csv が見つかりません。ファイルが正しく保存されているか確認してください。")
android_df = pd.DataFrame() # ファイルが見つからない場合は空のDataFrameを作成
try:
ios_df = pd.read_csv('ios_reviews.csv')
print("ios_reviews.csv を読み込みました。")
except FileNotFoundError:
print("エラー: ios_reviews.csv が見つかりません。ファイルが正しく保存されているか確認してください。")
ios_df = pd.DataFrame() # ファイルが見つからない場合は空のDataFrameを作成
# 各DataFrameにOSを示す列を追加
if not android_df.empty:
android_df['os'] = 'android'
# iOSデータフレームに存在しない列をNaNで追加
for col in ios_df.columns:
if col not in android_df.columns:
android_df[col] = None
if not ios_df.empty:
ios_df['os'] = 'ios'
# Androidデータフレームに存在しない列をNaNで追加
for col in android_df.columns:
if col not in ios_df.columns:
ios_df[col] = None
# 両方のDataFrameの列を揃える (結合前に必要)
# 存在しない列をNoneで埋める
all_columns = list(set(android_df.columns) | set(ios_df.columns))
if not android_df.empty:
android_df = android_df.reindex(columns=all_columns)
if not ios_df.empty:
ios_df = ios_df.reindex(columns=all_columns)
# データフレームを結合
combined_reviews_df = pd.concat([android_df, ios_df], ignore_index=True)
# 結合したDataFrameを表示
display(combined_reviews_df.head())
display(combined_reviews_df.tail())
# 結合したDataFrameの情報を表示
combined_reviews_df.info()
# 結合したDataFrameを新しいCSVファイルとして保存 (任意)
combined_reviews_df.to_csv('combined_reviews.csv', index=False, encoding='utf-8-sig')
print("\ncombined_reviews.csv が保存されました。")
こちらも同様に実行後、CSVファイルが保存されているか確認してみてください

手順4:geminiを使ってレビューさせてみよう!
手順3で作成されたcombined_reviews.csv をgeminiを読み込ませて、レビューデータを分析してみましょう!
ここからはあなたの自由!分析してほしいことをgeminiを問いかけてみましょう!
combined_reviews.csv の右側のgeminiマークをクリック
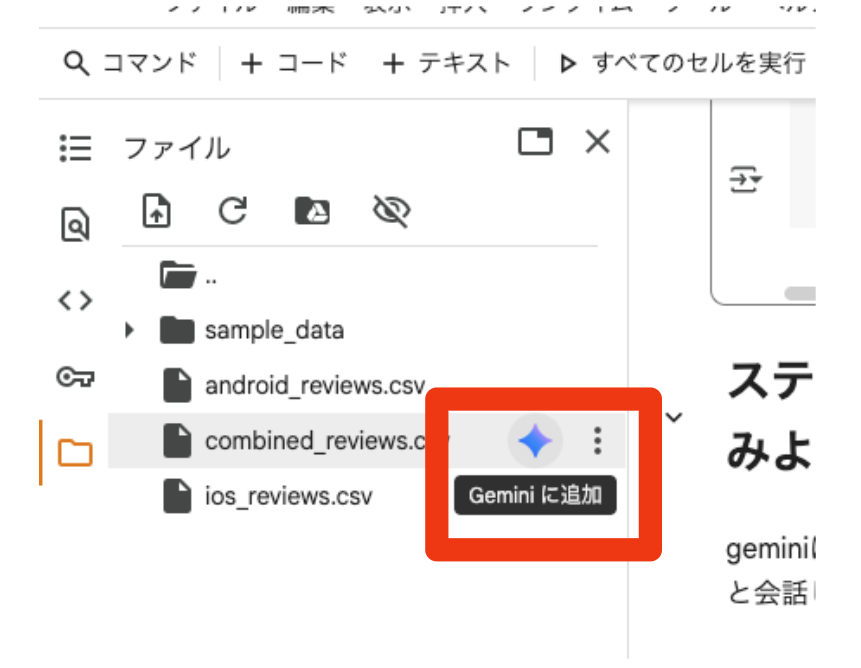
geminiのチャット画面が開くので、そこで分析したいことチャットで入力
コード実行の承認を求められるので、承認
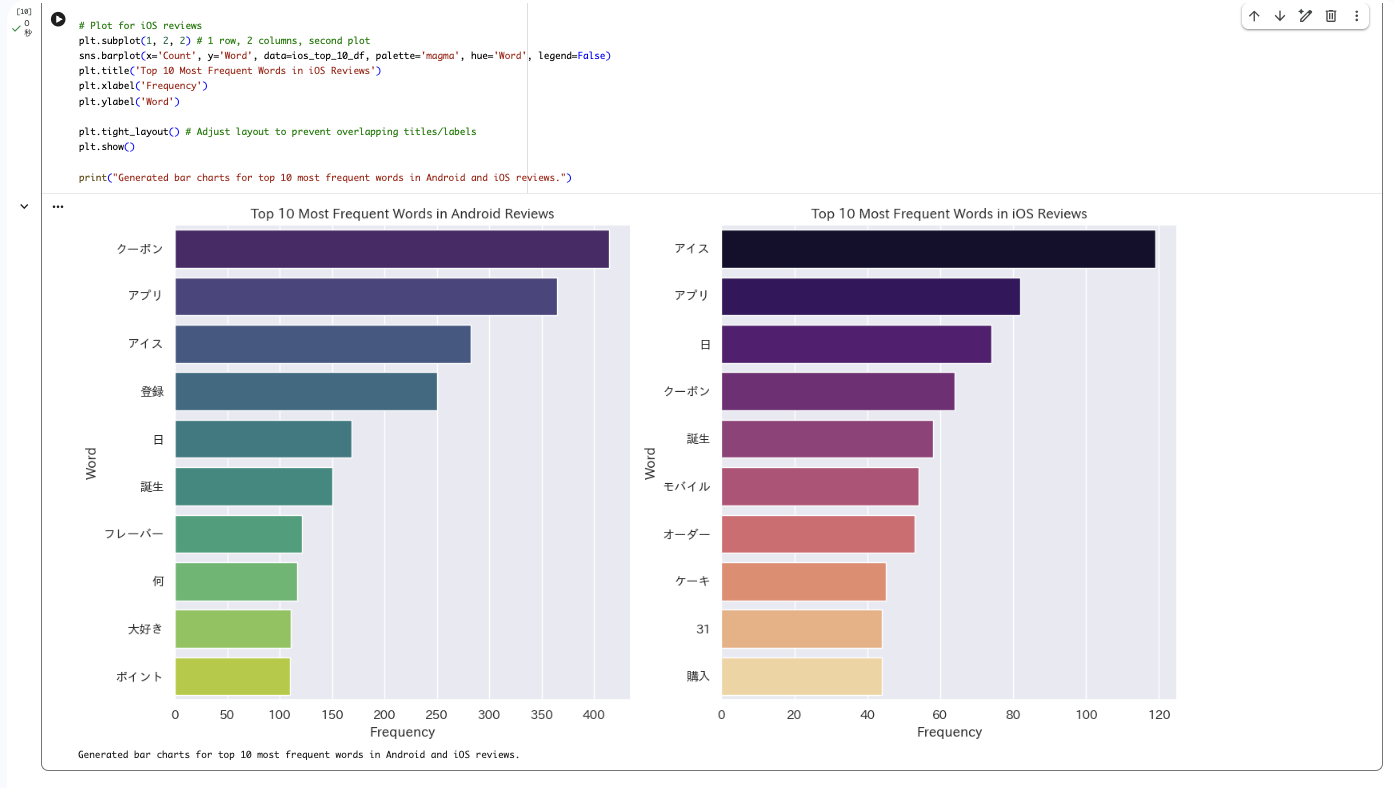
結果が出力!
グラフに合わせて、分析のサマリーも出してくれます!

まとめ
これまでの分析は「WordCloudを作る」「頻度を数える」といった 手法ありき でした。
しかし、これからの分析は 「何を知りたいか」 という問いさえあれば十分です。
Pythonコードでデータを集め(収集の自動化)、Geminiに問いかける(分析の高度化)。この2つを組み合わせれば、あなたは今日から、どんなデータも自在に操る「分析のプロ」です。
ぜひ、あなたのアプリの「宝の山」を掘り起こしてみてください!