RLとMemory駆動のパーソナルエージェント、実測Macaron AI
人工知能は生産性だけでなく、人間関係にも関わる。
人とAIの関係は通常、有用なアシスタントと架空のキャラクターという二大カテゴリーに分類される。
ChatGPT、Gemini、Claude、Cursorなどのアシスタントはタスク解決において非常に効率的です。その成功は疑いようもなく、ChatGPTだけでも現在約3億人の日次アクティブユーザーを抱えています。しかし、これらの関係は依然として取引レベルに留まり、感情的な深みが欠けています。
Character.ai、Talkie、MidRealに代表される架空のキャラクターは、魅力的な物語と感情的な共鳴によってユーザーを惹きつけます。ユーザーは当初、これらの架空の世界に熱狂します。しかし没入が進むにつれ、長時間の没入はしばしば虚無感や現実との乖離をもたらし、最終的には逃避を渇望させるようになります。本来は慰めとなるはずの関係が、かえって未解決の現実世界の問題を拡大してしまうのです。
Macaron AIが目指すのは第三の道:ドラえもん的関係です。長期記憶+強化学習の技術により、実用的な解決策と感情的な温かさを融合させます。
以上はMacaron AI CEO Chen KaijieがMacaron公式サイトに投稿したブログ[1]からの抜粋であり、原文のまま転載することで、Macaron AIの理念を最も原初的な形で理解することを目的としています。本稿では、技術的な差異と複数のユースケースを分析し、Macaron AIの製品価値をさらに掘り下げます。
💡 目次 💡
01 6つのQ&Aで知るMacaron AIの基本
02 技術面でのMacaron AIの独自性
03 2つのユースケースで検証するMacaron AI
04 提案
6つのQ&AでMacaron AIを素早く理解
Macaron AIのCEOであるChen Kaijieは、Macaronを立ち上げる前にMidRealを創設しました。これは世界中で300万人以上のユーザーを抱えるAIストーリーテリングプラットフォームです。またGPT-2を用いてAIゲームエージェントを構築した経験や、約150万ドルのARR規模を持つロボット企業を運営した実績もあります。このことから、同チームがAIアプリに対して十分な知見と実践経験を有していることが伺えます。
Q&A形式で、Macaron AIの独自性を素早く理解しましょう。
Q1:対話インターフェースという点では、Macaron AIのポジショニングは汎用エージェントやコンパニオン型エージェントとどう違うのですか?
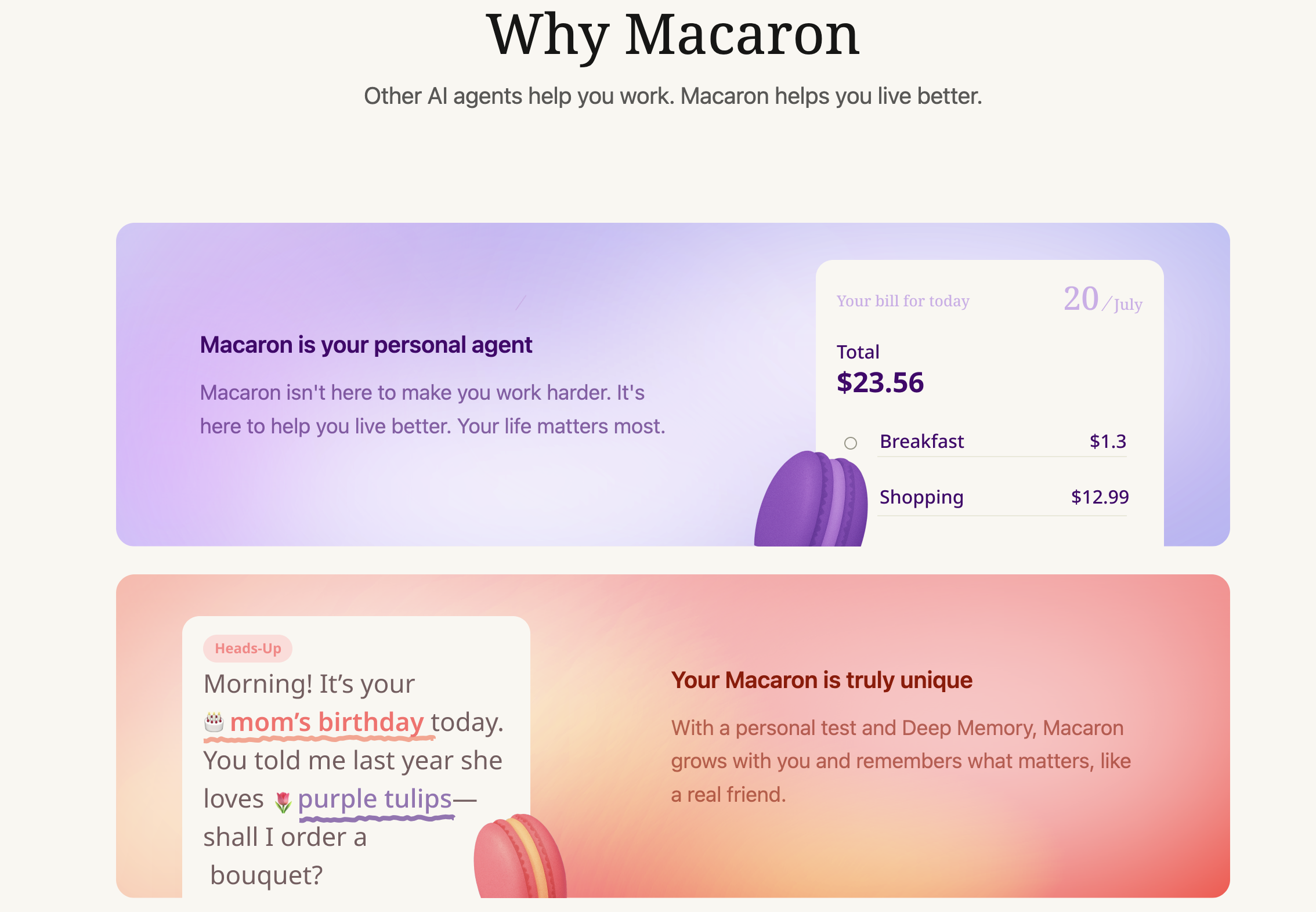
A:多くの汎用エージェントは生産性ツールとして位置付けられ、文書作成・情報検索・要約を支援します。コンパニオン型エージェントは情緒的価値を提供します。Macaron AIは両者の間を埋める存在として、長期的な伴走・感情の共鳴・能動的な支援を重視しています。
Q2:製品機能面で、Macaron AIの独自性はどこにありますか?
A:Macaron AIは長期記憶(Deep Memory)を導入し、自然言語と対話に基づき、ユーザー向けに様々なミニアプリ(Mini Apps)を生成します:
記憶システム:ユーザーの好み、習慣、目標、さらには感情反応まで長期的に記憶し、その後の会話で能動的に呼び出します。例えばユーザーが以前に「旅行資金を貯めている」と述べた場合、次に消費について話題になると、予算を考慮するかどうかをリマインドします。
自動生成される小型アプリ:ユーザーのニーズをツール化し、軽量なアプリケーションを生成します。例えば請求書の分類、スケジュールリマインダー、学習進捗の追跡など、単なるテキスト回答にとどまりません。この点は通義千問の「発見エージェント」と類似しており、ツールストアを提供し、対話に基づいて個別ツールを自動生成しますが、Macaronは強化学習駆動で自動生成されるため、ユーザーの習慣により適合します。
Q3:Macaron AIが採用する中核技術は?
A:主に3点に集約されます:
長期記憶:Macaronは「深層記憶を内蔵」し、ユーザーの重要データをインテリジェントに記憶します。
強化学習:システムのヒントでモデル出力を微調整するだけでなく、RLメカニズムで動的に最適化します:何を記憶し、何を記憶せず、いつ記憶を呼び出すかを決定します。
文脈のブロック処理:入力または出力が長い場合、ブロック処理を行い、記憶と組み合わせて結果を生成し、忘却や脱線を回避します。
Macaronのコア技術は、すべて「記憶」という製品設計の基盤を中心に展開されていると理解できます。
Q4:「組み込み型深層記憶」とは何を意味するのか?
「組み込み型深層記憶」とは、記憶がシステムアーキテクチャの一部であり、対話コンテキストを超えて、書き込み/読み取り/忘却のタイミングを能動的に決定できることを意味します。これはエージェントの長期目標と緊密に連携し、共同最適化されることで、Macaronがユーザーを最も理解するという究極目標を実現するものであり、単なるコンテキスト情報保存ではありません。
公式情報によると、「組み込み型深層記憶」は以下のように機能します:
デフォルトで有効化:記憶はMacaronの設計基盤である。
選択的保存:RL(強化学習)により長期保存に値する情報を判断。
能動的呼び出し:応答生成時、記憶が推論経路に能動的に組み込まれる。Agentic Memoryの考え方と同様であり、「内建深度記憶」はAgentic Memoryの製品化実装と理解できる。
技術的観点から見ると、Macaron AIは記憶を中核ロジックとし、RLフレームワークと緊密に連携させて構築された製品である。
Q5:この設計はユーザー体験にどのような差異をもたらすか?
A:二つのシナリオを想定できる:
ChatGPTに「生活費の記録を手伝って」と依頼すると、統計対象や分類方法を尋ねた後、最終的に表形式で提供する。
Macaronで「最近出費が大きすぎる」と言うと、以下のような対応が考えられます:
支出の分類・集計の必要性を自発的に確認;
「家計簿ツール」を自動生成;
次回消費について話す際に「飲食費が40%を占めています」とリマインド。
この体験の差異は、Macaronの長期記憶+ツール生成メカニズムに由来します。
Q6:ユーザーは特定の記憶を削除できますか?
A:記憶はMacaronの中核的な製品ロジックであり、公式では個々の記憶を削除するオプションは提供していません。ただし、会話を通じてMacaronに特定の話を忘れさせることは試みられます。これは他の記憶機能を提供する製品との違いでもあります。例えばChatGPTはユーザーのプライバシーとデータセキュリティを考慮し、保存済み記憶の有効化/無効化オプションをユーザーに提供しています。
技術的に、Macaron AIはどのような違いがあるか?
Macaron AIが現在公開しているインフラストラクチャやアルゴリズムに関する技術詳細は、公式の技術ブログ[2]を中心にまだ限られています。
コスト最適化
Macaronは、自社開発の全同期強化学習(All-Sync RL)アーキテクチャ、LoRA適応、および自社開発のマルチ畳み込みDAPOフレームワークの統合による相乗効果により、GPUのアイドル時間を最小限に抑え、トレーニング時間を短縮しています。例えば、従来9時間かかっていた典型的なステップが、現在ではわずか1.5時間で完了します。最終的に、DeepSeekの6710億パラメータモデルは、48枚のH100 GPUのみでトレーニングを完了でき、同等の構成では通常512枚が必要でした。
記憶効果
は、標準的なグループポリシー最適化GRPOに代わる独自開発のマルチコンボリューションDAPOフレームワークを採用した記憶システムを構築。このモデルは、非常に長い生成シーケンスにおいて文脈と一貫性を維持する能力を示し、完全なソフトウェアプロジェクトの生成に成功した。例えば、ユーザーの嗜好を保持し外部APIと正しく連携するパーソナライズされた日常服装提案ツールを生成した。このエンドツーエンド強化学習記憶手法は、複雑なステートフルエージェント開発分野における大きな進歩を示す。
この記憶システムは当初FireActによって検証された。FireActは、MacaronチームとKarthik Narasimhan(元GPT論文共著者)、OpenAI研究員の姚舜宇が2023年に共同で実施した研究である。FireActは、複雑な推論タスクにおいて、強化学習による事後軌跡の微調整を経たエージェントの行動が、プロンプトベースの手法よりも77%優れていることを初めて実証した。
長い入力処理時には、従来のロングコンテキストLLMのように全てを直接入力するのではなく、単一対話ラウンドの最大長制限下で、RLを介したエージェント的記憶を用いてブロック単位で記憶を結合しながら段階的に処理する。長い出力生成時も同様に、RLを介したエージェント的記憶を用い、問題と更新され続ける記憶を組み合わせながら、思考過程と最終回答を段階的に生成する。
要約すると、Macaronの記憶システムは永続性・自己進化・最適化を特徴とし、各インタラクション開始時に専用の記憶トークン(標準推論トークンとは異なる)を活性化し、リアルタイム検索・要約・文脈更新をトリガーする。このトークンは単なる情報想起にとどまらず、学習した報酬信号に基づき、記憶すべき内容・更新タイミング・記憶の活用方法をエージェントが決定する支援を行う。
専用データセット
このデータセット(548GB超)は、チームの前製品であるインタラクティブストーリープラットフォーム「MidReal」における数百万件のユーザーインタラクションから収集され、RLによるモデル訓練を通じて、より魅力的な体験の提供、潜在的なユーザーニーズの推論、強固な信頼関係の構築を研究するために使用されました。
これらのインタラクションの上位5%に相当する高品質サブセットを厳選することで、記憶保持、ツール活用、複雑な対話スキルにおけるモデルの能力をさらに強化することを目的としています。
Serverless
Macaronが生成するガジェットはすべてServerlessコンピューティングで駆動され、典型的なミニアプリシナリオと言えます。WeChatやAlipayとは異なり、企業がミニアプリを作成するのではなく、Macaronの「ミニアプリ」はCエンドユーザーが自然言語で作成するガジェットであり、規模が大きくトラフィックが予測不可能です。そのためServerlessコンピューティングはコスト面で大きな優位性があります。
つまり、組み込みツールやミニアプリがパーソナルエージェントのような製品形態の標準装備となれば、サーバーレスはAIインフラにおいてより重要な役割を担うことになる。
2つのユースケースで検証するMacaron AI
Macaron登録後、「理想的な週末の過ごし方は?」といった質問に回答する必要がある。これらはMacaronが会話を始めるきっかけとなる。
ユースケース1:ランニングアシスタント
オンボーディング時に「理想的な週末の過ごし方は?」という質問で「アウトドア」を選択したため、Macaronは最初からアウトドア関連の話題を持ち出し、非常に積極的にツール作成へ誘導してきました。これはMacaronがRL(強化学習)された結果であり、汎用エージェントとは異なる性格・能力、そしてツール作成というタスク指向性が付与されたためと考えられます。
そこで私は「ランニングアシスタント」ツールの作成を提案し、走行距離・時間・ペースを記録するよう要求。Keepとの計測精度比較が目的で、特にキロ数計算機能において、単純なフロントエンド操作やローカル計算を超えたプログラミング能力を検証したかった。
左がKeep、右がMacaron:
ランニング時間:スマートフォンの時間データを直接呼び出しているため、差は小さい。
走行距離:環境認識が必要で、GPS精度問題・センサーノイズ・デバイス差異などの課題に直面し、正確な表示には継続的な適応が必要。そのため両者の差は大きい。
ペース:ランニング時間と走行距離を基に計算。走行距離の偏差によりペースの偏差も大きくなる。
データ精度はKeepに大きく劣るものの、インターフェースが明確で機能が充実しており、良好な出来栄えです。基盤モデルのプログラム能力が向上するにつれ、データ精度はさらに高まるでしょう。
ユースケース2:高温天気ランキング
本ユースケースは、Macaronのネットワーク検索能力および外部システム・データ呼び出し能力を検証するものです。
プロンプト:
- 中国の省都・直轄市を網羅すること。
- 特定日付の気温ランキングを閲覧可能とすること。
- 当日の最高気温に基づきTOP50都市を表示すること。
- インターネット検索またはサードパーティ天気APIの呼び出しのいずれかを使用し、いずれの場合もランキングの正確性を保証すること。
Macaronには生成時間が設定されており、通常15~20分かかる。この間も対話を継続する。対話とウィジェット生成が非同期で動作し、別々の大規模モデルサービスを使用していることがわかる。対話はRL(強化学習)を適用、ウィジェット生成は基盤モデルのエンコーディング能力を活用。基盤の演算リソースはServerless形態である可能性が高く、ユーザーコマンドで起動するタスクはServerlessに最適化されている。
結果は以下の通り:
長所:
ウィジェットのアイコンが「マカロン」らしい。
インタフェースには一定の品質基準が保たれ、配色に違和感なく、画面が窮屈でない。
上位3都市とその他の都市で色分けされている。
MacaronはLoRA(低次元適応学習)を活用し、ウィジェットのインタフェースとアイコンを強化することで、安定した視覚的統一性を実現している可能性がある。
欠点:
対象都市の選択ミス。プロンプトでは省都と市轄市を要求したが、ランキングに他の都市が混在。
Apple標準天気アプリや墨迹天気と比較し、気温データに誤差あり。例:十堰・瀘州の最高気温はそれぞれ37℃・35℃だが、最高気温38℃の杭州がランキングから漏れている。
Macaronのウィジェット生成能力は、基盤となる大規模モデルのネイティブ機能であり、強化や最適化は施されていない可能性がある(事実と異なる場合はご指摘ください)。技術ブログでも関連情報は公開されていない。
二つのユースケースを通じて、Macaronの製品能力を概ね把握できた。対話能力は非常に特徴的で、これは「記憶を中核製品ロジックとする」アプローチによる成果である。ユーザーが継続的に対話を続ける忍耐力を持てば、さらなる小さな驚きを得られるだろう。ウィジェットの効果、特に大規模モデルのネット検索という基本能力の強化には、まだ多くの改善余地がある。
提案
全体として、Macaronは非常に革新的なエージェントであり、新たな使用方法を提供していると感じます。Macaronとのやり取りが頻繁で長ければ長いほど、得られる価値は増し、ユーザー定着率も高まります。ここで2つの提案をいたします。
ゲートウェイのアップグレード
翌日ランニングアシスタントを開いた際、以下のエラーが発生しました。バックエンドサービスチェーンのいずれかのレイヤーで404が返された可能性があります。例:
Nginxリバースプロキシ設定エラー:フロントエンド操作によりlocationパスが一致しない、またはアップストリームアドレス転送が誤り、Nginxがバックエンドサービスを見つけられない。
バックエンドAPIサービスが起動していない/停止中:Nginx設定は正しいが、対応サービスがリスニングせず404を返す。
ゲートウェイ/ロードバランシング層の異常:ゲートウェイルートが有効化されていない、またはPodが登録されていないため、Nginxがターゲットを見つけられない。
静的リソースパス問題:ミニアプリが特定の静的ファイル(JS/CSS/画像)を要求したが、Nginxに対応するディレクトリやマッピングがなく、404を返す。
いずれの場合も、本質的にはトラフィック入口となるゲートウェイが十分なサービス可用性を保証できていない。バックエンド全体がK8s上にデプロイされている場合、Higressまたはその商用版への移行を検討できる。ヘルスチェック、リトライ/サーキットブレーカー/フォールバック、グレーリリース/マルチバージョン管理、可観測性において強化されたサービスを提供する。
より成熟したプログラミング機能の導入
ウィジェット作成はMacaronの2大中核機能の一つ(もう一つはRLベースの長期記憶機能)である。したがって、ウィジェットの効果がユーザーの定着率と製品拡散を大きく左右する。より成熟した安定したプログラミング機能を導入すれば、Macaronの製品体験が大幅に向上する。
[1] https://macaron.im/ai-relationships-not-just-productivity
[2] https://macaron.im/efficient-on-policy-reinforcement-learning