はじめに
ユーザがS3にファイルをアップロードした際にそのS3イベントをトリガーとして何らかの変換処理を実施し、DWH/DataLakeに格納する、といった簡易システムのニーズは多い。
今回はLambdaでは処理出来ないような重い処理、かつ不定期な利用頻度である場合にECS Fargateを用いてコスパ良く対処するアーキテクチャの開発を実施するので、備忘として記録する。
今回は前編として、S3 Object CreatedをトリガーとしてECSでコンテナを起動する所までを実装する。後編では、コンテナ内のpythonを用いてRDS for MySQLへのインサートを実装する。
概要
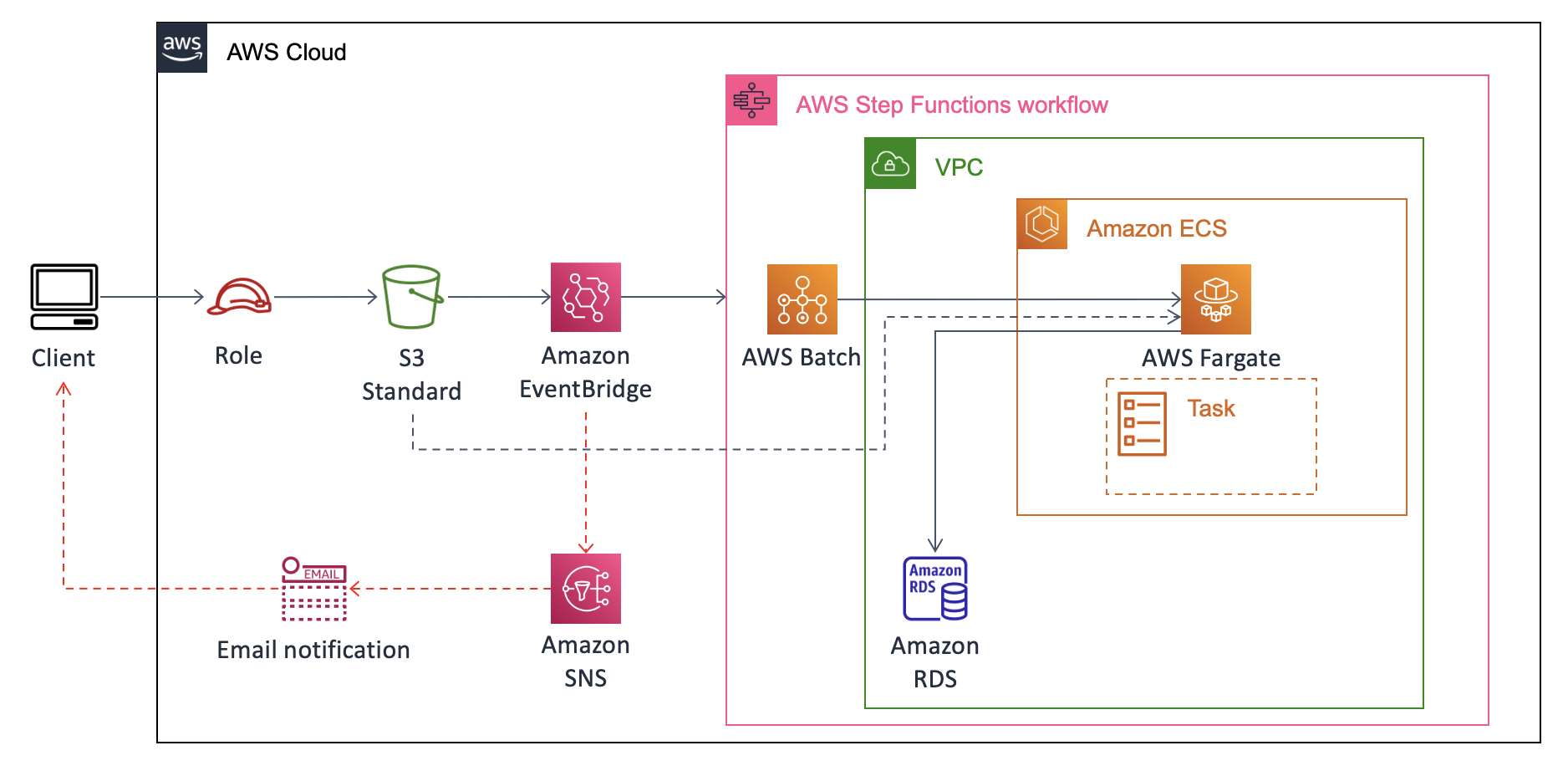
このように、S3のObject CreatedイベントからEventBridgeを噛んでStepFunctionsを起動する。ECSはFargateで済む様であればその方がよく、EC2を使う必要があれば状況に応じて変更すれば良い。
本稿では、バケットへのダミーcsvファイルのアップロードをトリガーにRDSに変換済みデータを格納する処理を実装する。ユーザへのロール付与やUIの実装などはスコープ外とした。
また、S3イベント→Amazon EventBridgeの呼び出し確認としてSNSでのE-mail通知も要件外であるが、おまけで実装する。
開発環境
EC2にLinux環境(t3.midium & EBS32G)を立ち上げてコンテナイメージの作成を行った。
環境構築手順
- S3バケットの作成
- SNSトピックの作成
- Amazon EventBridgeルールの作成
- ECRへのイメージ登録
- AWS Batchの設定
- StepFunctionsの設定
- 作成したEventBridgeへルールの追加
- デモンストレーション
S3バケットの作成
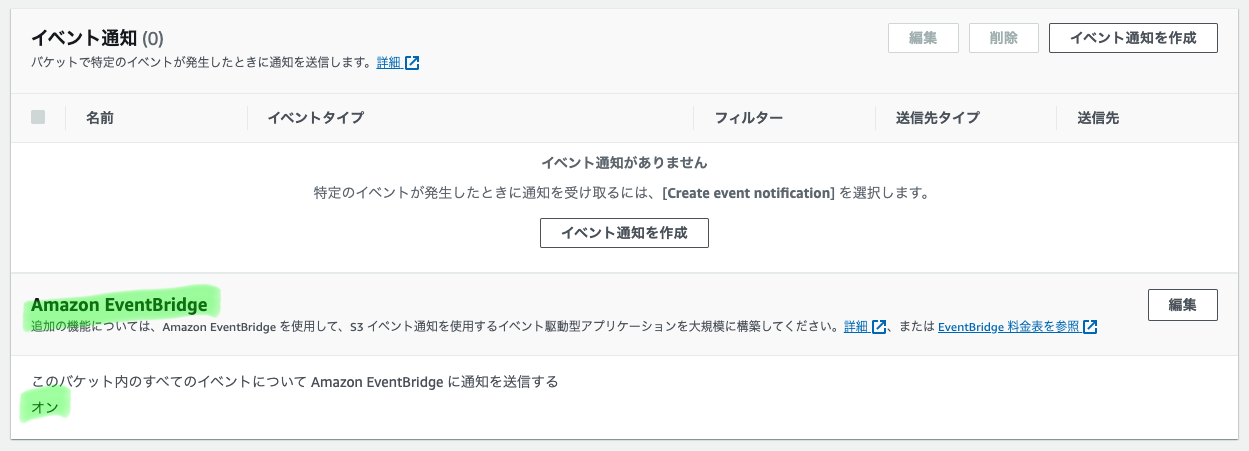
適当なリージョンにバケットを作成し、作成後プロパティ→Amazon EventBridge→編集→通知を送信を"オン"に設定する。
SNSトピックの作成
Amazon SNSからスタンダードタイプでトピックを作成します。
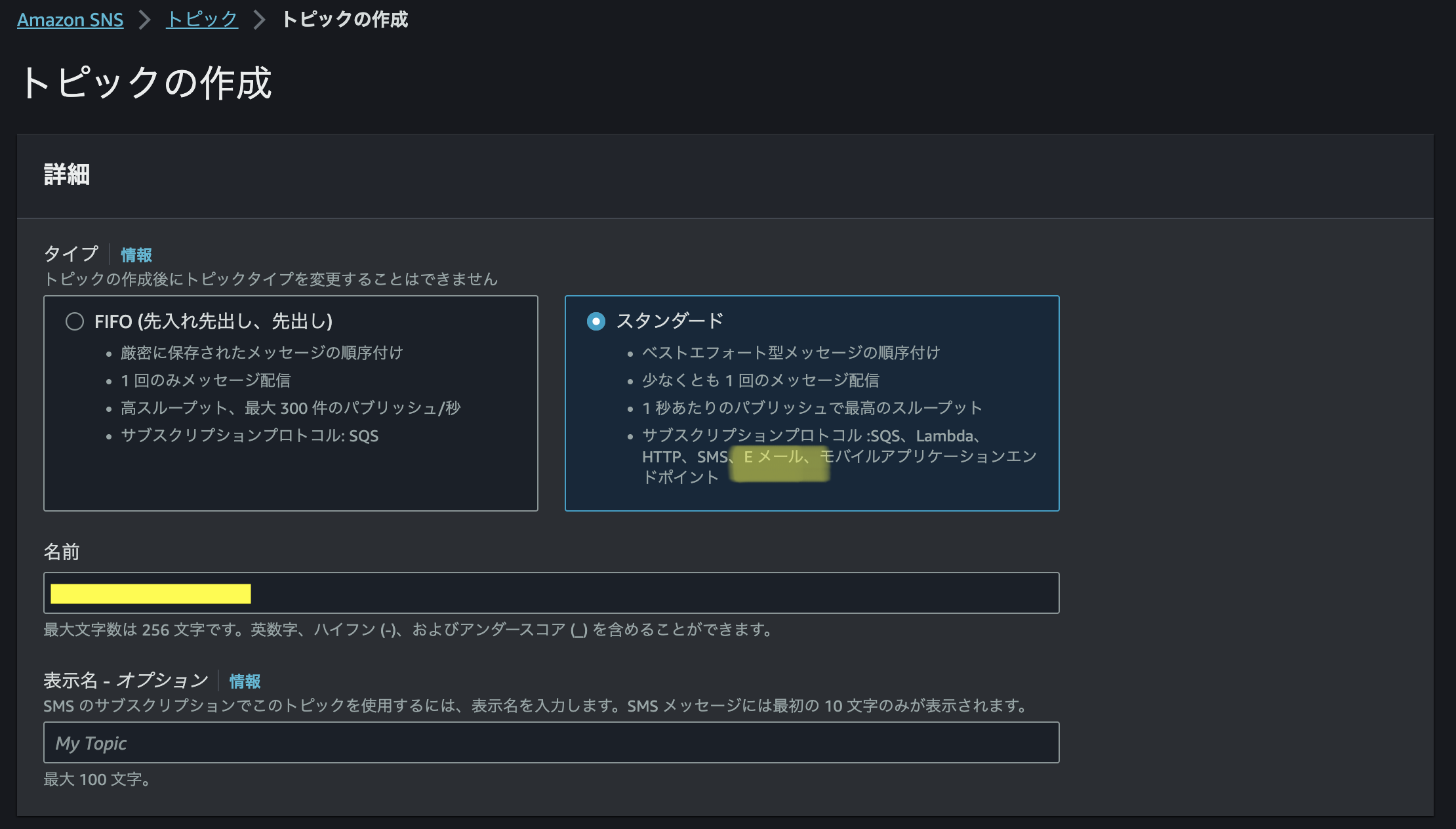
今回は開発途中で私だけが通知を受け取れるようにしたいだけなので、アクセスポリシー→ベーシックタイプを選択→発行者と購読者に自身のAWSアカウントを指定、と設定を進めてトピックを作成します。
トピックが作成されたら、詳細設定からサブスクリプションの作成を行う。ARNには作成したトピックが示されています。
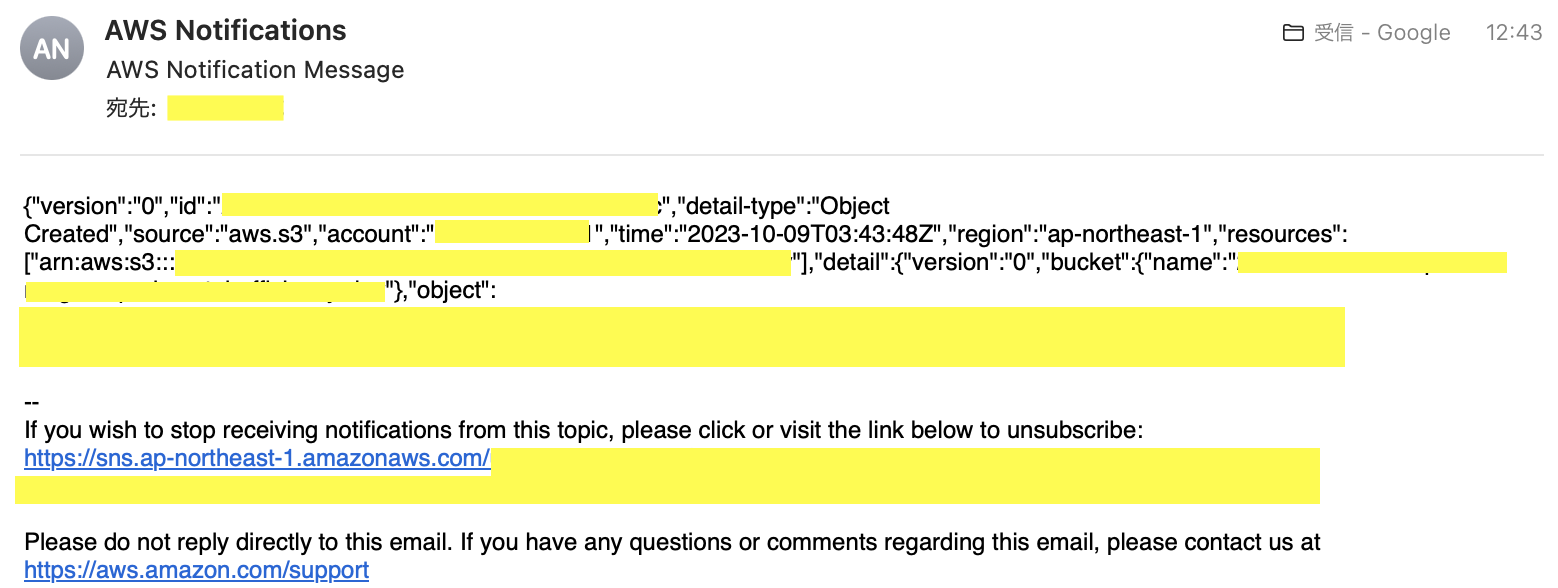
すると、下記の様な購読確認メールが届くので、購読の確認を押下する。
再度、SNSトピック側でサブスクリプションの詳細を確認するとステータスが確認済みになっていることが分かる。
Amazon EventBridgeルールの作成
Amazon EventBridge→ルールを作成、からイベントに基づくルールを作成する。
イベントパターンでは、S3 Object Createdを指定する。バケット名を指定できるので、S3バケットの作成の節で作成したバケット名を入力する。(プリフィックスを指定する際はjsonを適宜変更)
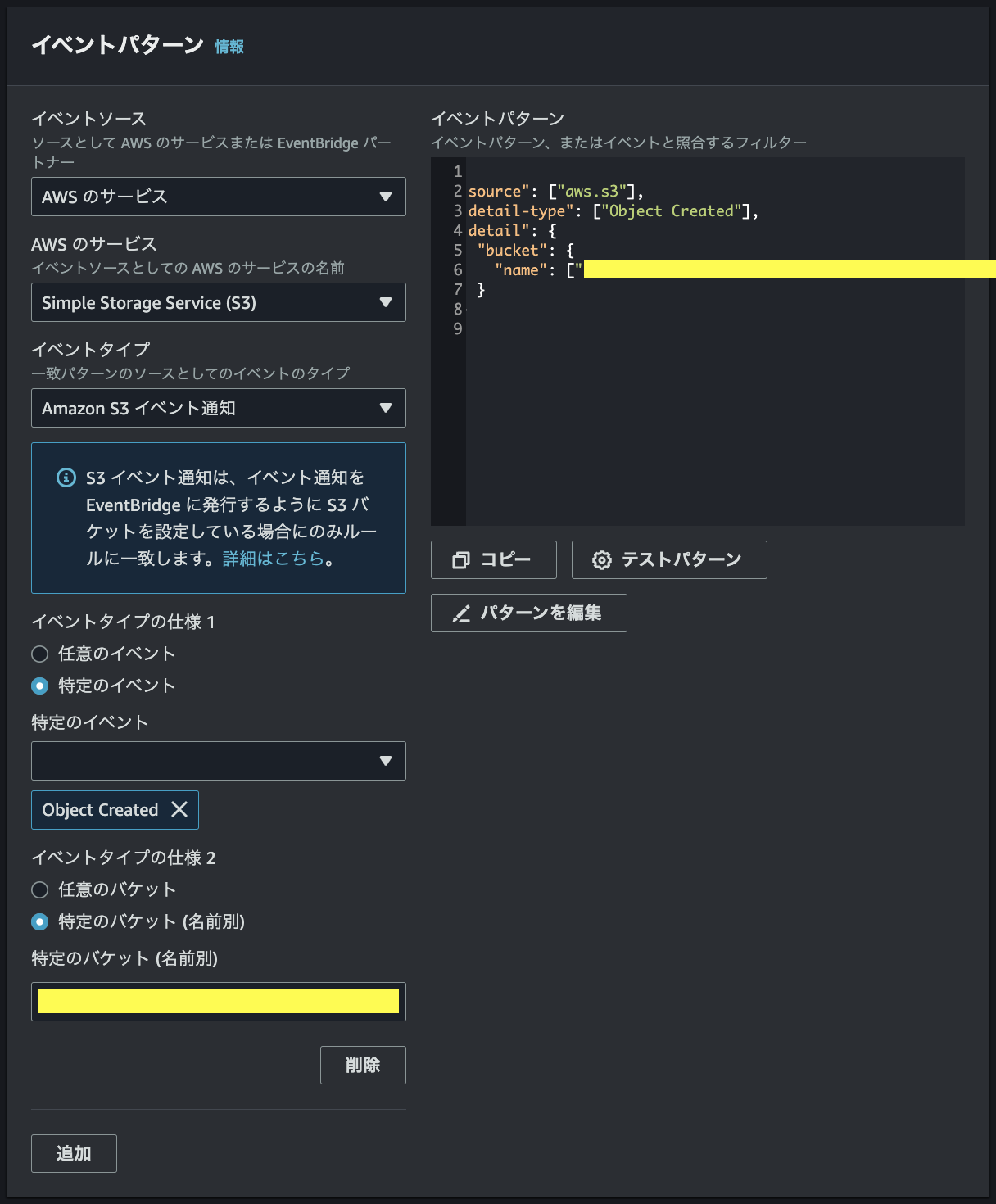
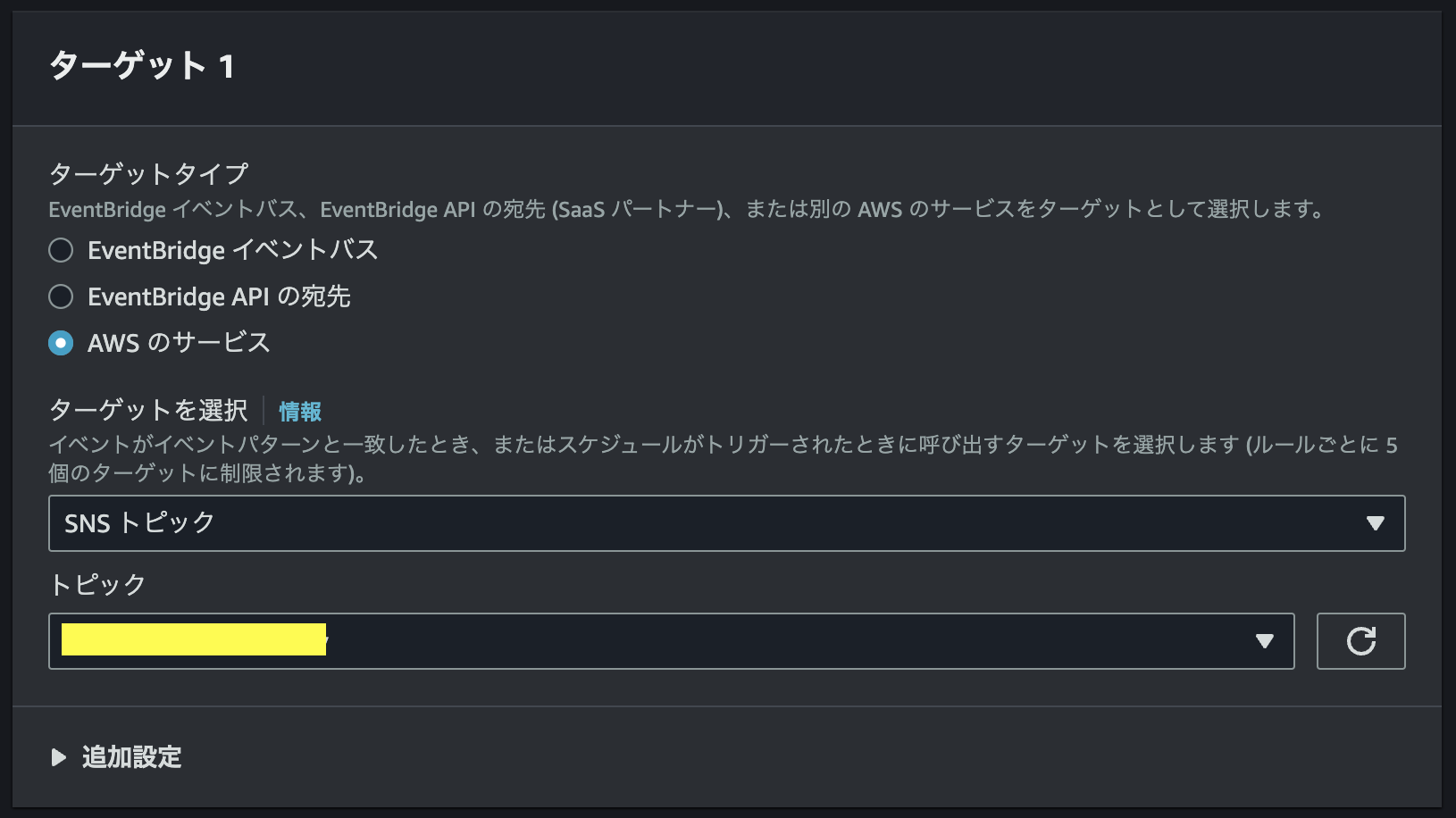
最後にイベントのターゲットにSNSトピックを指定する。
ここで、実際にS3に適当なファイルをアップロードするとEメール通知が届くことが確認できた。
ECRへのイメージ登録
前述の通り、EC2のLinux環境を使ってDockerイメージを作成し、ECRへリポジトリ登録を実施していく。
今回はS3 Create Object→ストレージに保存するコンテナ(Python3)とストレージに保存したファイル→RDSに格納するコンテナ(SQL)の2つを作成する。
まずはPython3の方のDockerイメージの作成&ECR登録について説明した後、同じ手順に沿ってSQL側も作成していく(説明略)。
ディレクトリ構造は下記の通り。ただし、(※)付のファイルは認証情報をコンテナに引き渡すためのファイル。詳細はこちら。
.
└── home
└── ec2-user
├── Dockerfile
├── env.list
├── docker-compose.yml (※)
├── .env (※)
└── input
├── main.py
├── requirements.txt
└── run.sh
Pythonファイルの作成
今回はconvert処理内容は問わないので、とりあえずReadしたデータをそのまま掃き出すコードを記述する。データセットはIris.csvとし、名前をinput.csvにして保存しておく(後述のシェルスクリプトにて処理)。
import pandas as pd
def read_csv(filename='../input.csv'):
df = pd.read_csv(filename)
return df
def convert(df):
return df
def save(df, outfilename='../output.csv'):
df.to_csv(outfilename)
def main():
df = read_csv()
converted = convert(df)
save(converted)
if __name__=='__main__':
main()
requirements.txtの作成
このファイルはpythonファイルの実行にインストールが必要な外部ライブラリをリスト化した物である。後のrun.sh内にてpip3による一括インストールを実施する。例として、取り敢えずnumpyとpandasを指定
numpy
pandas
シェルスクリプトの作成
Dockerfileでこのシェルを実行する事でタスクの挙動を設計する。初めに、S3からアップロードされたinput.csvをコピーし、先ほどのpythonファイルを実行させるコマンドを記述する。
ここで、バケット名(BUCKET_NAME)とオブジェクトキー(OBJECT_KEY)を環境変数として記述してあるが、これは開発時にはコンテナを実行する際に環境変数の受け渡しを行い、本番環境ではStepFunctionsで指定する。
#!/bin/sh
aws s3 cp s3://$BUCKET_NAME/$OBJECT_KEY /home/input.csv
python3 /home/input/main.py
Dockerfileの作成
### use Amazon Linux 2-based Docker images
FROM amazonlinux:2
USER root
### install the required packages
RUN yum -y update && \
yum -y install python3-pip && \
pip3 install awscli
### start bash shell when container is started
COPY input/ /home/input/
RUN pip3 install --user -r /home/input/requirements.txt
CMD ["sh", "/home/input/run.sh"]
Dockerイメージの作成
ここで、開発環境下でビルドと実行確認を行う。
$ docker build . -t aws-cli-container
これでaws-cli-containerというDockerイメージが作成される。
続いて開発環境であるEC2にS3にアクセスするIAMロールをアタッチする。AWSコンソールからIAM→ロールの作成→エンティティでAWSサービス→ユースケースでEC2を選択、と進みAmazonS3ReadOnlyAccessポリシーを選択する。今回はAllowEC2toReadS3という名前でロールを作成した。
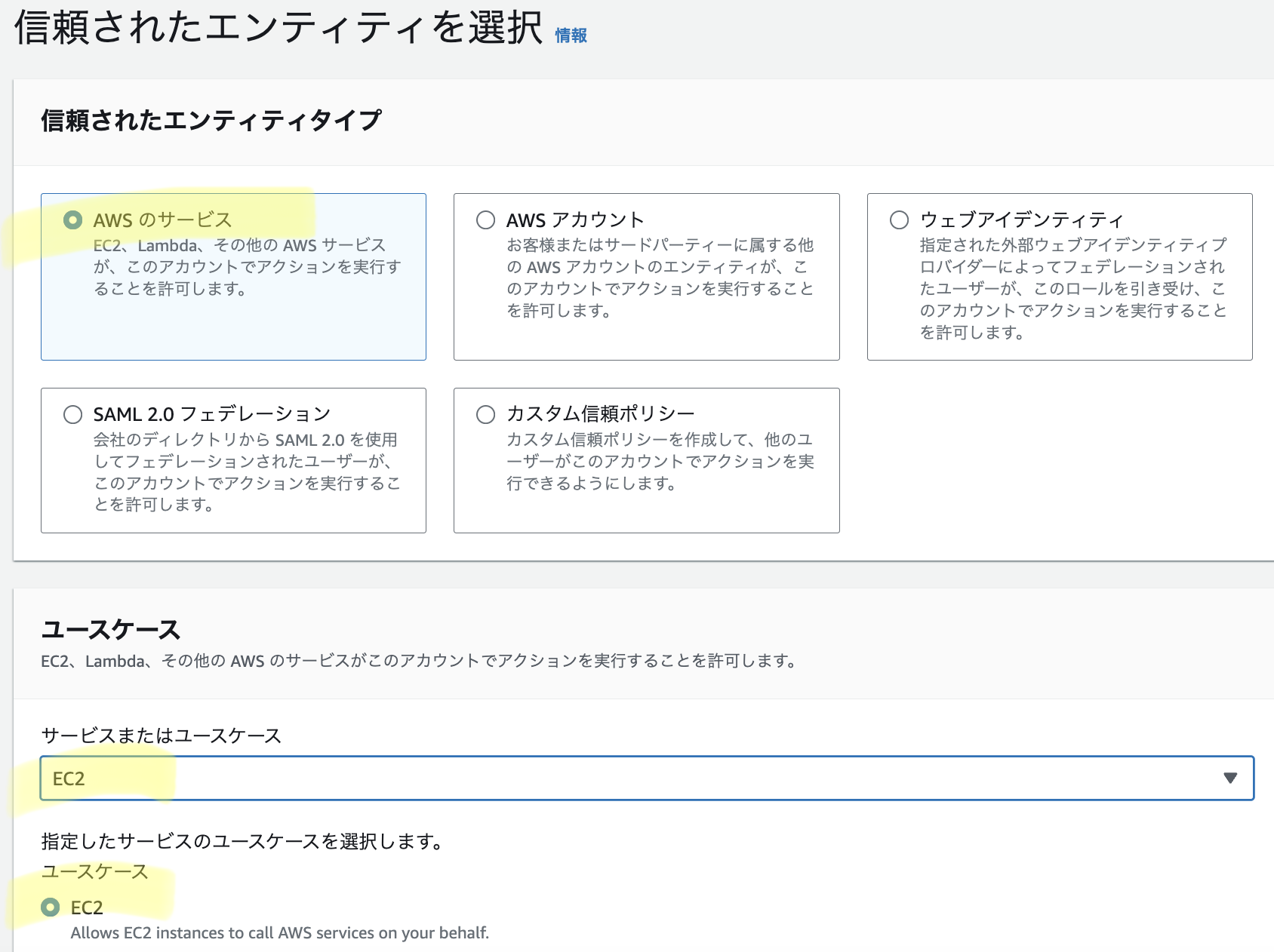
次にEC2のコンソールから開発環境のインスタンスにチェックを入れ、アクション→セキュリティ→IAMロールを変更、で作成したIAMロールをアタッチする。
ここで、テスト実行を行いたいので実際にS3バケットにinput.csv(元のIris.csv)をアップロードし、Dockerfileと同じディレクトリに環境変数ファイルを作成する。
BUCKET_NAME=#S3バケット名
OBJECT_KEY=input.csv
この上で、--env-fileオプションを使ってコンテナを実行する。
$ docker run -it --rm --env-file env.list aws-cli-container
[実行結果]

この様に、aws s3 cpが正常に動作していれば良い。
実際にDockerfileにbashコマンドの実行も追加して、home/input/を見に行くとpythonファイルが掃き出したoutput.csvが作成されている事も確認できる。
先に概要だけ述べているが、EC2上でコンテナへのawscliの利用はこちらの記事にまとめているので、参考にして頂ければと思います。
ECRへのDocker image登録
前章にてEC2環境下で作成したDockerイメージをECRに登録する。
初めに、Elastic Container Registryでリポジトリを作成する。Amazon Elastic Container Registryのコンソール画面からリポジトリの作成を押下。特に理由はないが、プライベートリポジトリを選択し、適当な名前を設定して作成
リポジトリが作成されると詳細画面の右上からプッシュコマンドの表示、というボタンがあるのでこれを参考にしてイメージのプッシュを行う。
[プッシュコマンド]
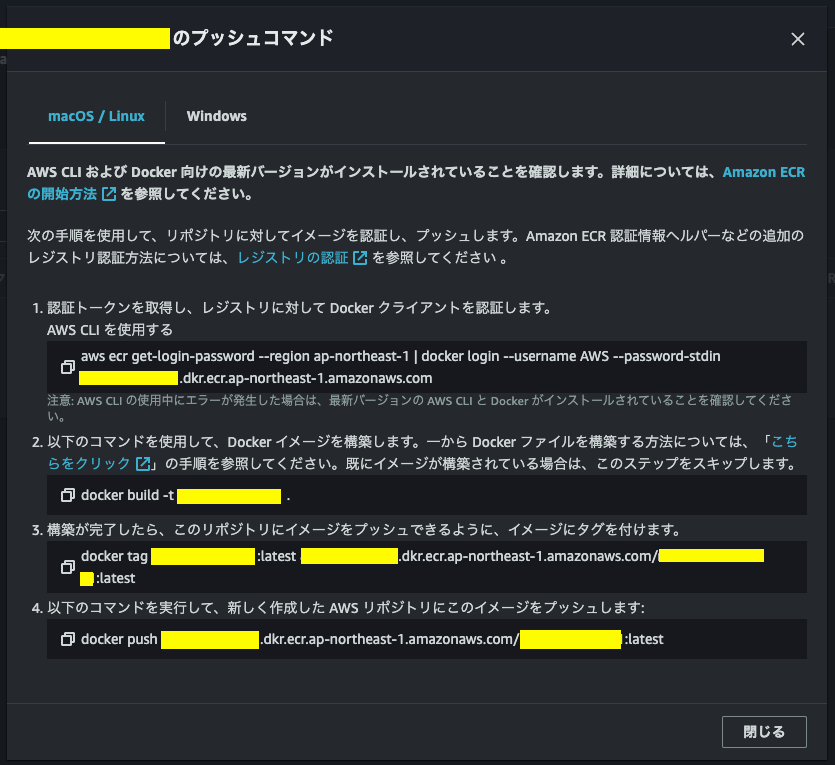
因みに、プッシュコマンドの手順を全て実施するとこの様な標準出力がなされる。

AWS Batchの設定
続いて、リポジトリに登録したコンテナのスケーリングを制御するために、AWS Batchの設定を実施する。
本節はIAMロールの設定やネットワーク周りなど若干躓くポイントが多かったため、それぞれについて項を分けて記述する。
コンピューティング環境の作成
コンピューティング環境の作成を行う。
AWS Batchのコンソール画面から、コンピューティング環境→作成と遷移する。

筆者が担う案件では、重い処理が単発かつ不定期に発生する想定なので、Fargate Spotでリソースを定義する。
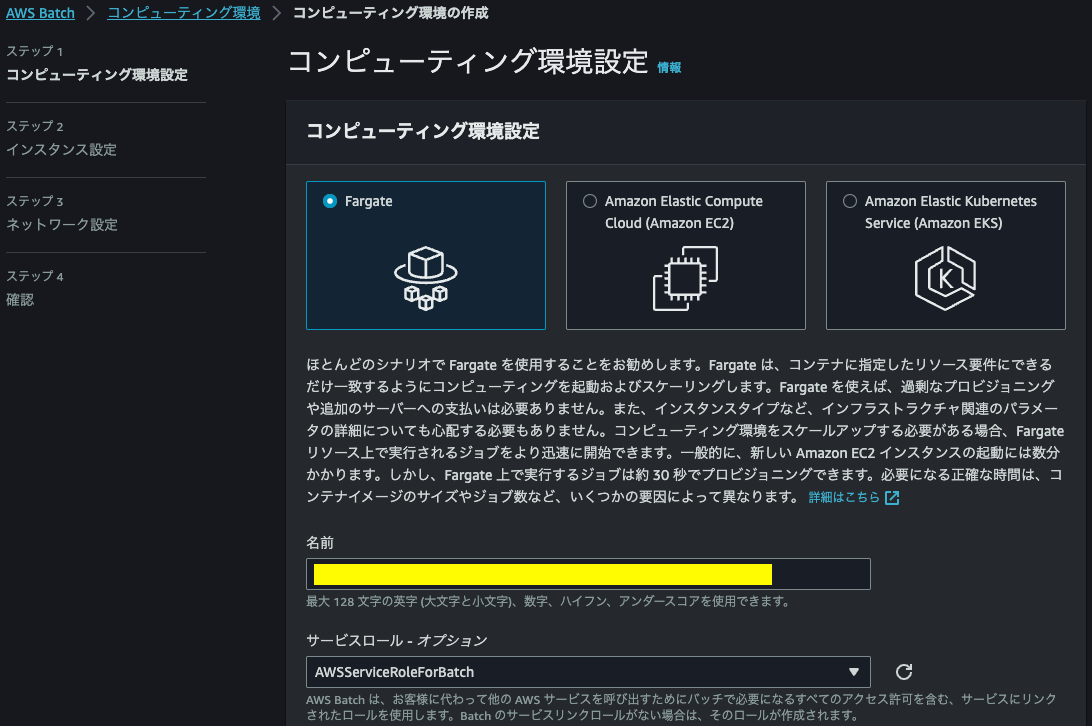
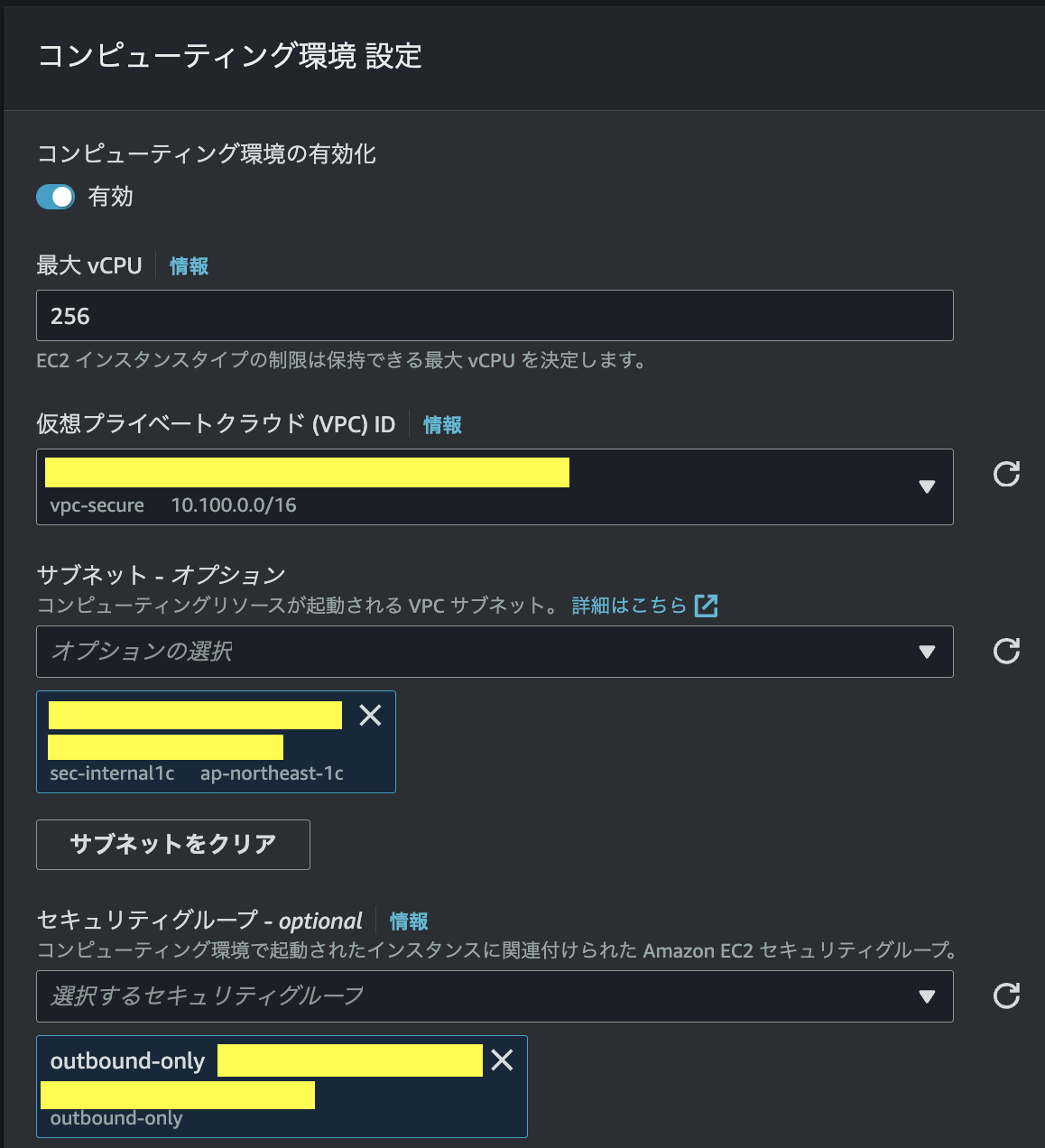
VPCおよびサブネットの設定
ここでネットワーク設定は、ECSタスクにインターネットへのアウトバウンドが許可されていないと、Dockerイメージをpull出来ない点に留意する。
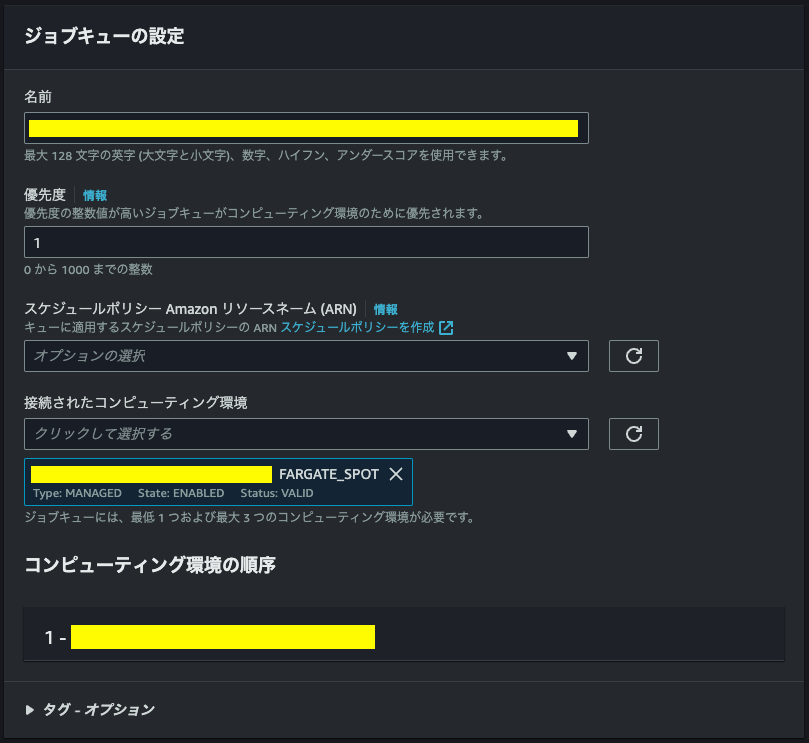
ジョブキューの作成
ジョブキューの名前を設定し、先ほど作成したコンピューティング環境を選択して作成
ジョブ定義の作成
最後にジョブ定義を作成する。
ジョブ定義の名前を設定し、オーケストレーションタイプにFargateを選択。
タスク実行ロール(Task Execution Role)には下記3つのポリシーを添付したロールをアタッチする。
- AmazonEC2ContainerRegistryReadOnly
- AmazonS3ReadOnlyAccess
- AmazonECSTaskExecutionRolePolicy (※)
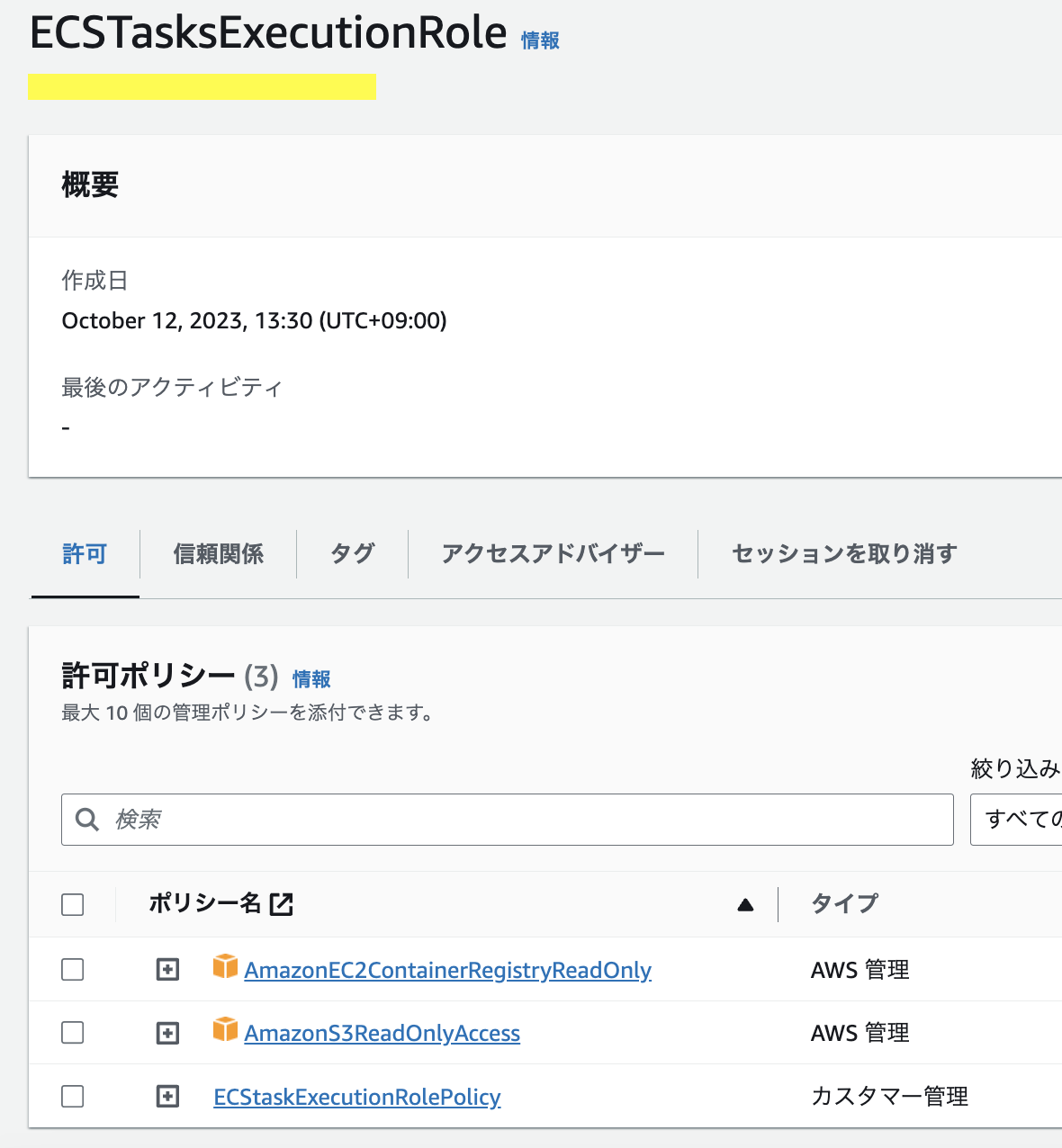
※AmazonECSTaskExecutionRolePolicyポリシーにはlogs:CreateLogGroupの許可が含まれないため、これをベースとしたカスタマー管理ポリシーECStaskExecutionRolePolicyを作成した。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
この様に作成したIAMロールをタスク実行ロールとして設定する。
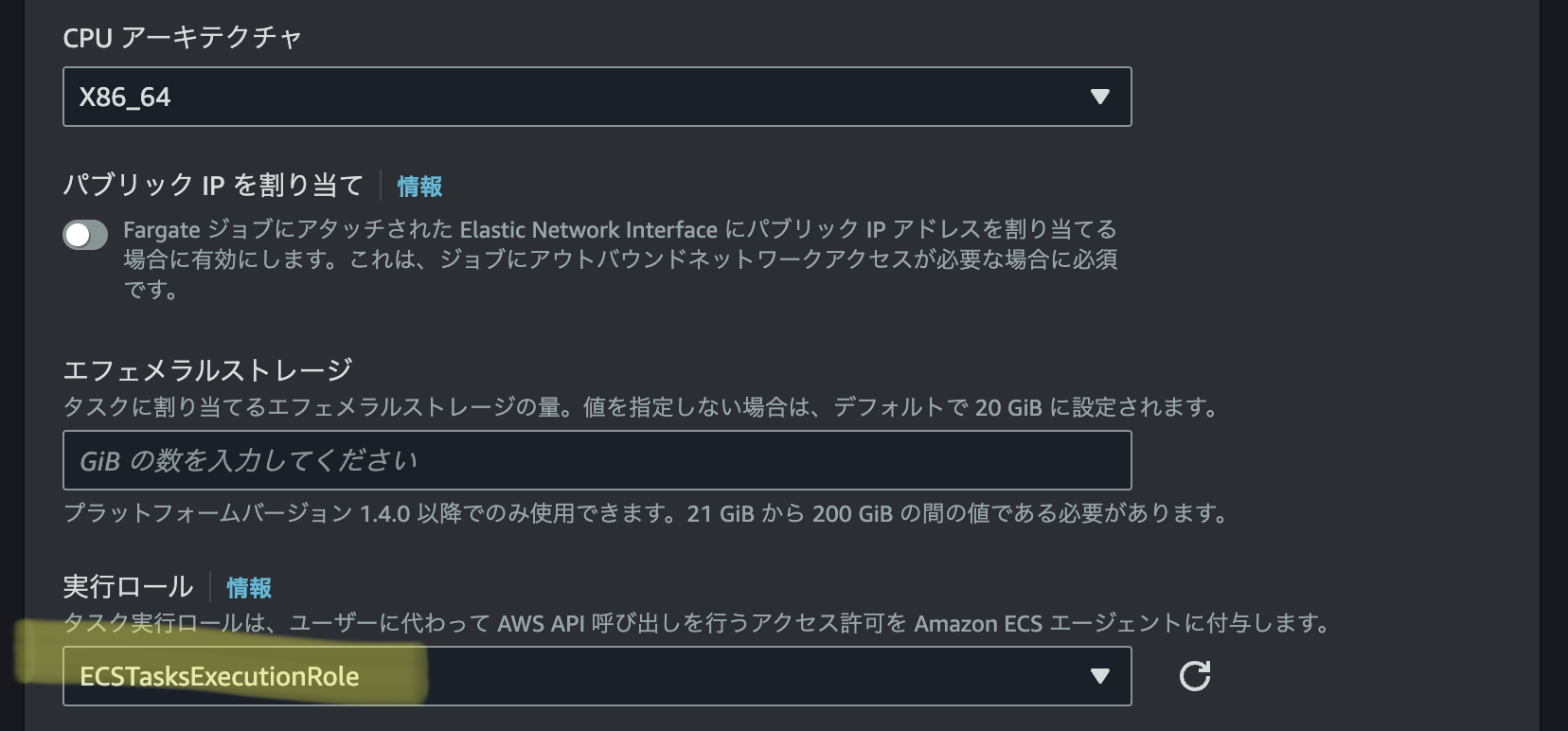
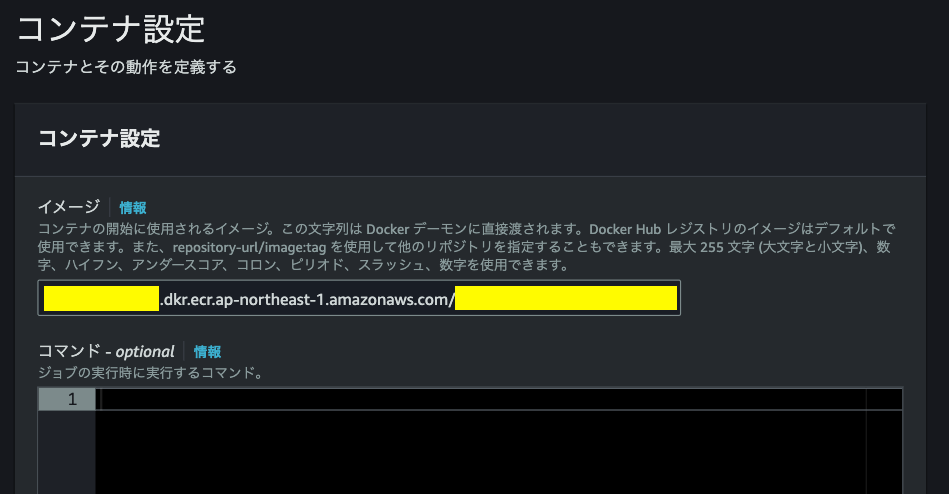
次の画面に遷移すると、コンテナ設定に移るのでECRに登録したイメージのURIをコピー&ペーストする。
また、コマンドはデフォルトでhello worldが出力されるようになっているが不要なので削除しても良い。
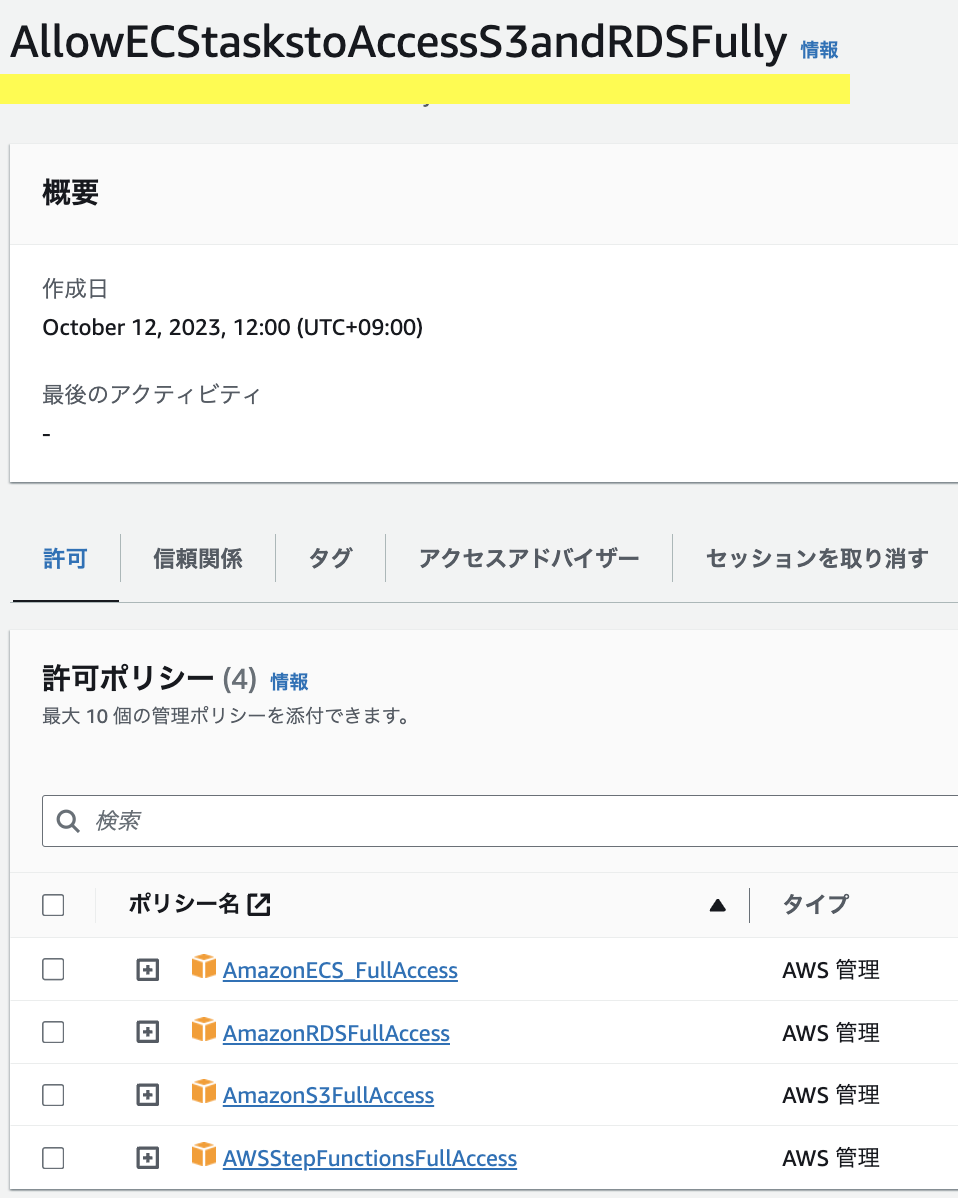
さらに画面下に遷移すると、ジョブロール(Task role)設定があるので、ここで利用するAWSリソースの権限を付けたIAMロールを選択する。今回のケースは下記の4つのポリシーを付けた。
- AmazonECS_FullAccess
- AmazonRDSFullAccess
- AmazonS3FullAccess
- AWSStepFunctionsFullAccess
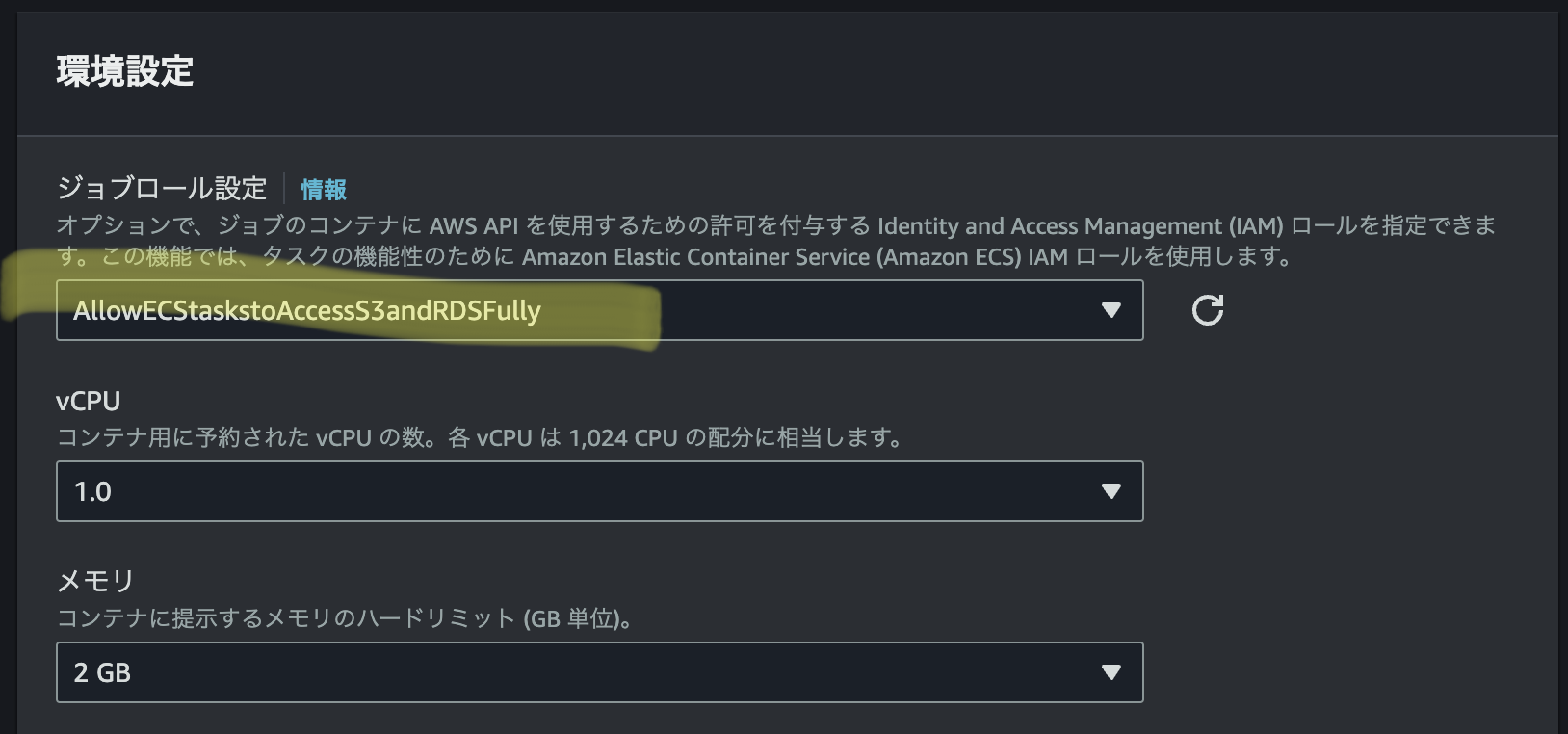
ロール名をAllowECStaskstoAccessS3andRDSFullyとし、ジョブロールに設定する。
StepFunctionsの設定
まずは、先ほどECRに登録したコンテナだけを動かすワークフローを作成する。
今後、同ワークフローにMySQLによる.csv→RDSの格納やユーザへのSNS通知、エラー処理などを組み込むことを想定している。
StepFunctionsのコンソール画面から、ステートマシンの作成→Blankを選択してSelectを押下
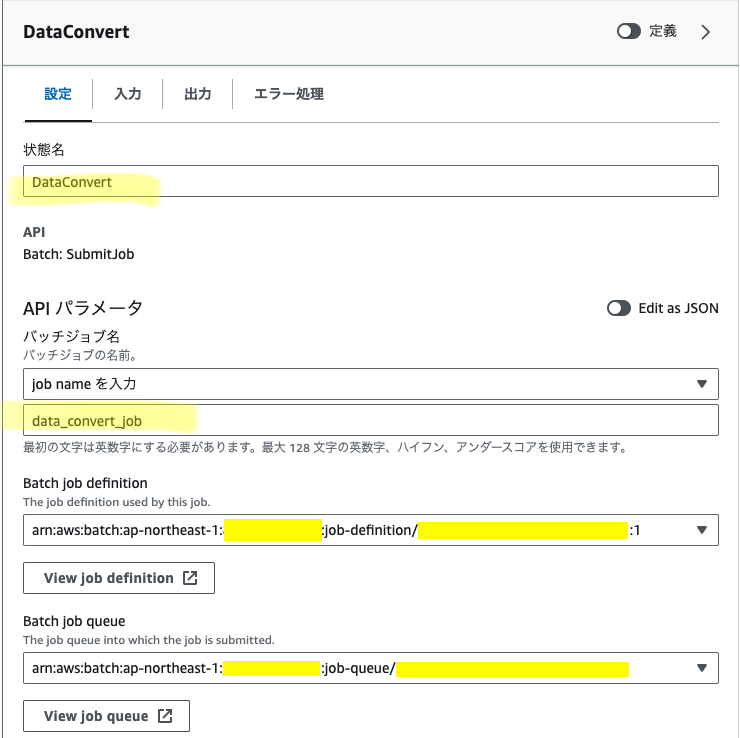
ワークフロー設計画面左側の検索窓から"AWS Batch SubmitJob"を選択&ワークフローに追加。状態名、ジョブ名を入力し、前章で作成したジョブ定義、ジョブキューを設定する。
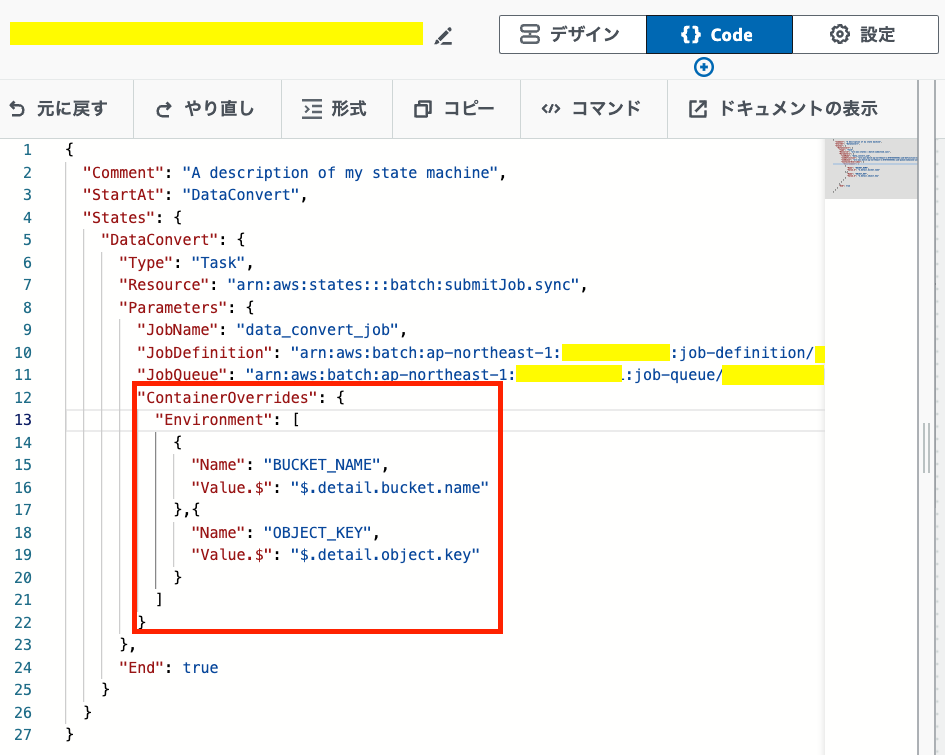
次にワークフロー設計画面から上部ボタンでデザイン→Codeに切り替えるとjson形式での定義が編集できる。ここで"Parameters"の下に"ContainerOverrides"を追記する事でコンテナ内のバケット名、オブジェクト名を参照可能に出来る。
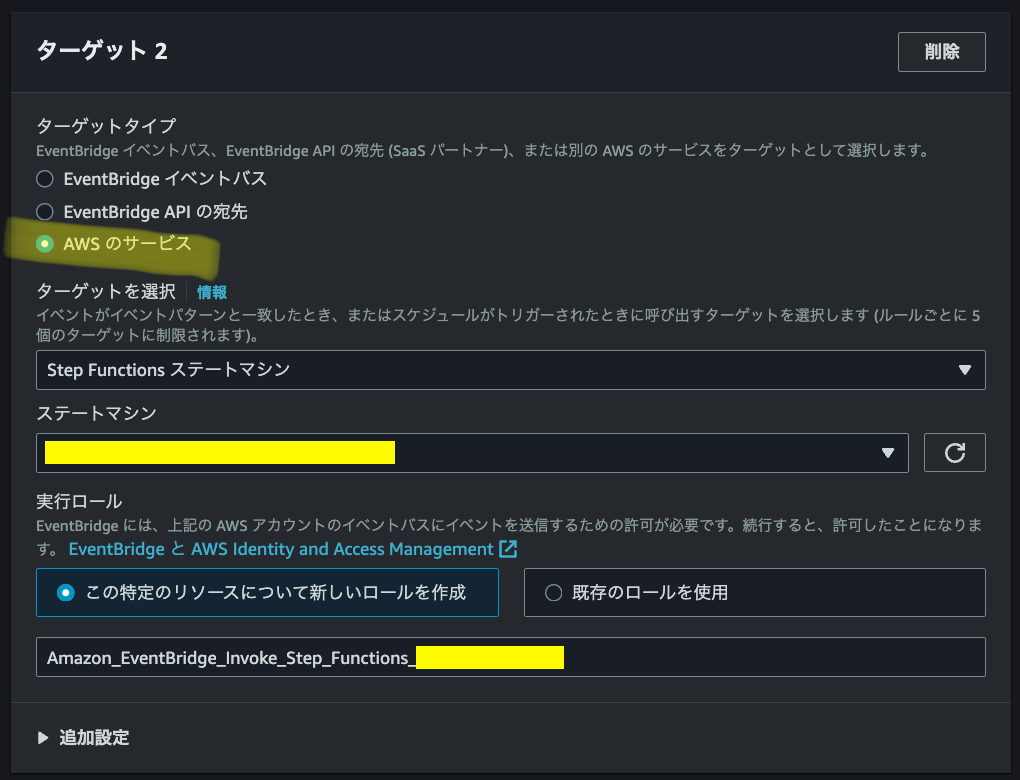
作成したEventBridgeへルールの追加
先に作成した同じEventBridgeのルールのターゲットにStepFunctionsのステートマシンを追加する。別のターゲットを追加、というボタンを押下。ルールを更新する。
デモンストレーション
さて、ここまで実装出来たところで実際にS3に.csvファイルをアップロードしてみて一連のフローが正しく動作するか確認する。
まずは、S3にinput.csvをアップロード
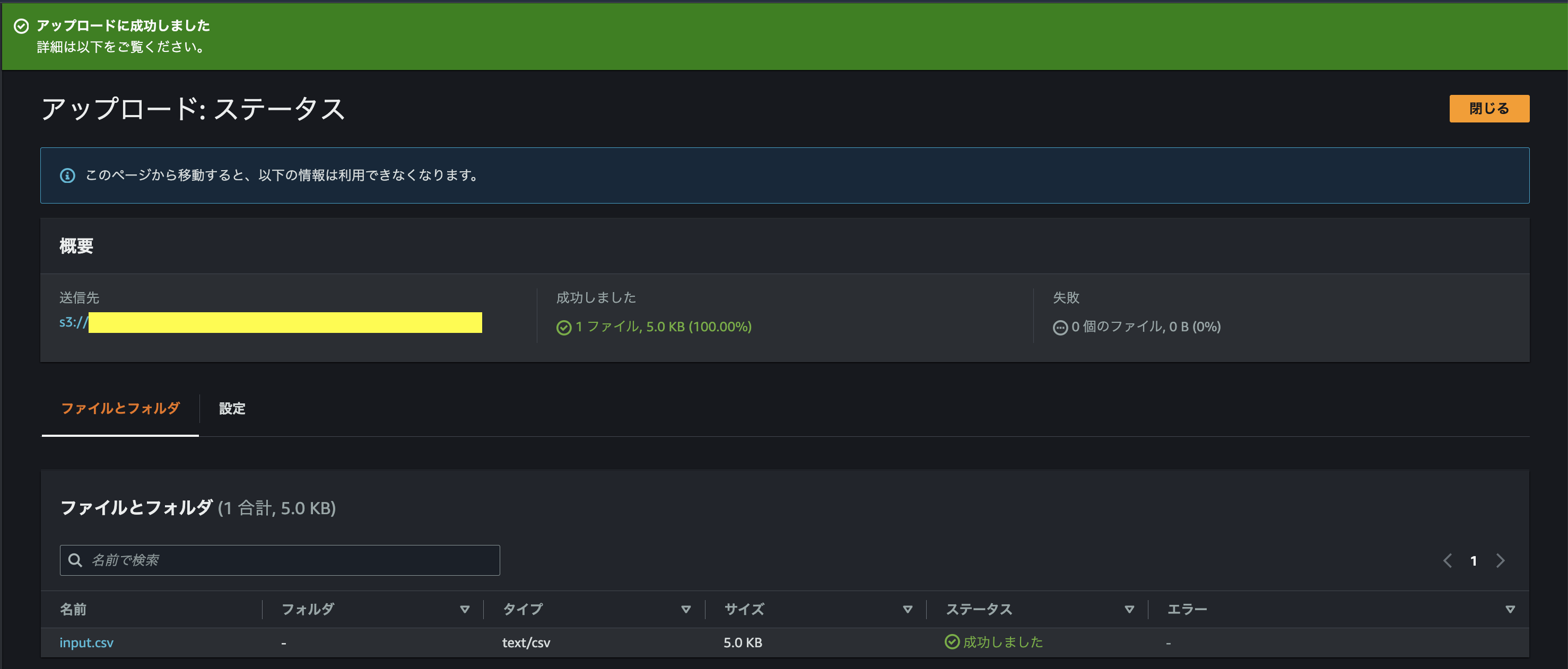
S3へのObject CreatedイベントはEventBridgeを介して、SNS通知とStepFunctionsへ配信されるはずなので、先ほど確認した様なSNS通知が来ていればトリガーは成功しており、StepFunctionsへもイベントがpushされている筈である。
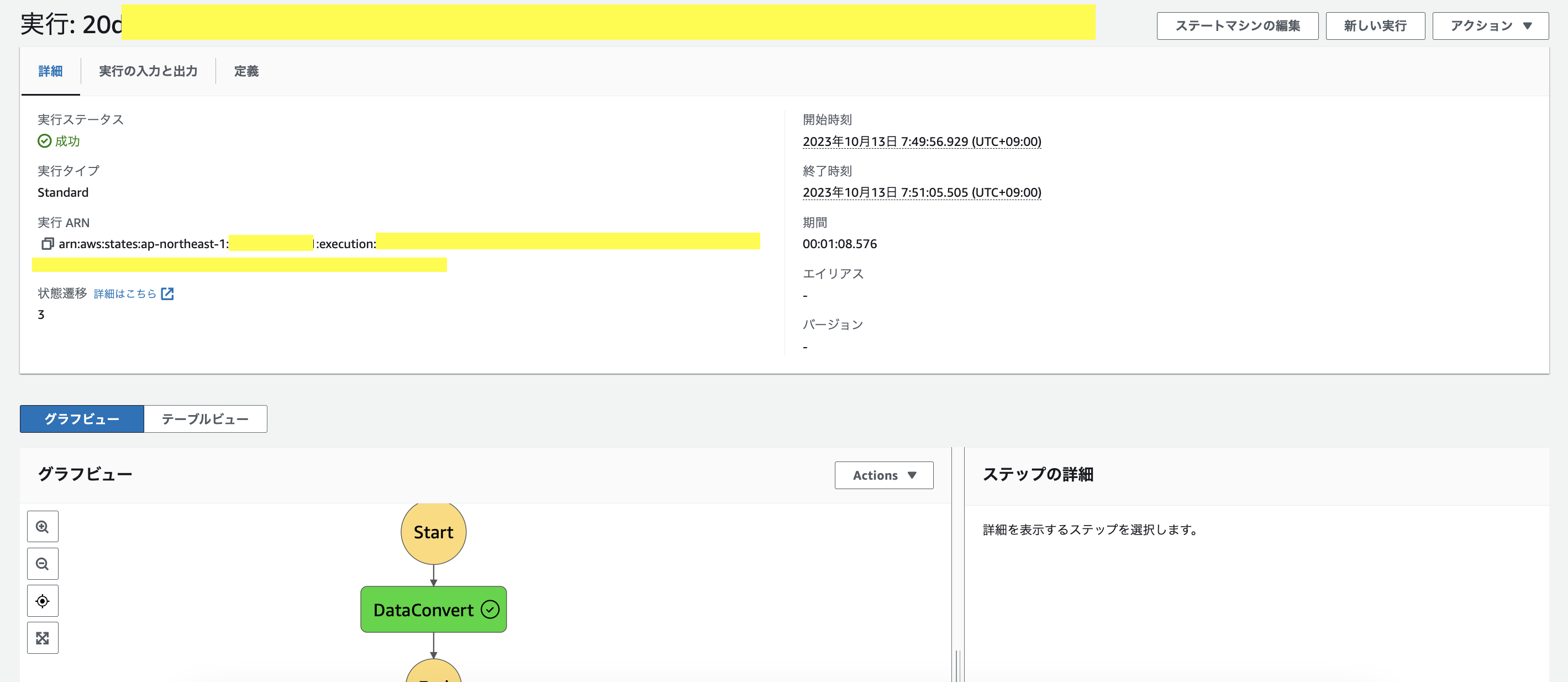
次にStepFunctionsのコンソール画面から作成したステートマシンの詳細を確認すると、このように過去のジョブの実行状況が確認できる。

さらにこの実行名をクリックすると、エラーが発生した場合にどこのフローで失敗したかJSON形式で詳細を確認する事ができる。
成功の場合は下記の通りになる。
おわりに
今回はS3 Object CreatedをトリガーとしてECS Farget Spotを起動するシステムの構築法を記した。
次回の後編では、ECSのコンテナ内のpythonでMySQLを叩いてRDSに格納するフローを実装する。