はじめに
ユーザがS3にファイルをアップロードした際にそのS3イベントをトリガーとして何らかの変換処理を実施し、DWH/DataLakeに格納する、といった簡易システムのニーズは多い。
今回はLambdaでは処理出来ないような重い処理、かつ不定期な利用頻度である場合にECS Fargateを用いてコスパ良く対処するアーキテクチャの開発を実施するので、備忘として記録する。
本稿は後編である。前編ではS3 Object CreatedをトリガーとしてECSでコンテナを起動する所までを実装した。後編では、コンテナ内のpythonを用いてRDS for MySQLへのインサートを実装する。
概要
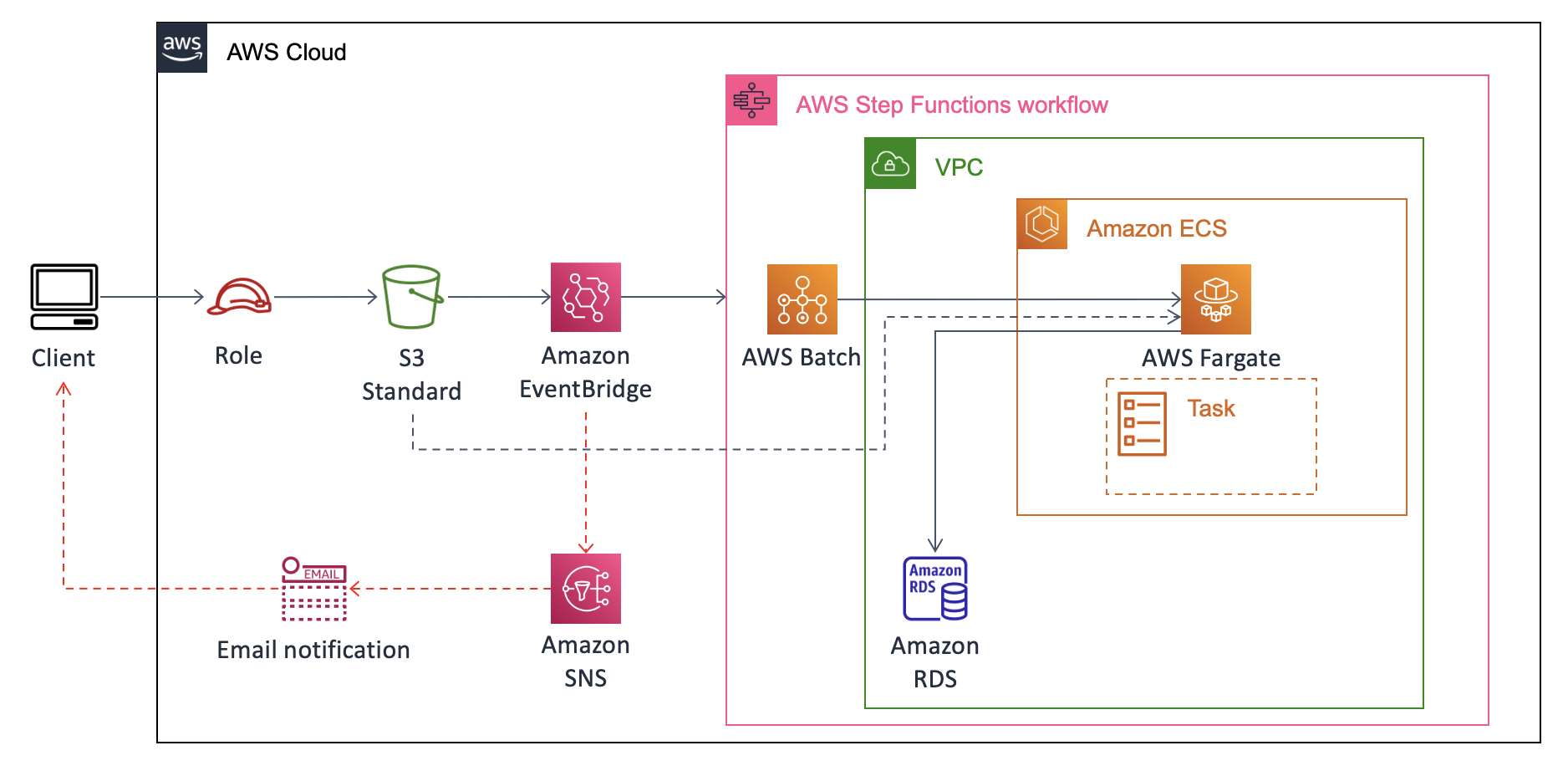
このように、S3のObject CreatedイベントからEventBridgeを噛んでStepFunctionsを起動する。ECSはFargateで済む様であればその方がよく、EC2を使う必要があれば状況に応じて変更すれば良い。
本稿では、バケットへのダミーcsvファイルのアップロードをトリガーにRDSに変換済みデータを格納する処理を実装する。ユーザへのロール付与やUIの実装などはスコープ外とした。
前編までで、コンテナの起動までは実装できているので、RDSへのデータ格納の実装について記述していく。
開発環境
EC2にLinux環境(t3.midium & EBS+32G)を立ち上げてコンテナイメージの作成を行った。
ただし、開発環境のEC2にMySQLがインストールされている事を前提とする。
$ mysql --version
mysql Ver 8.0.34 for Linux on x86_64 (MySQL Community Server - GPL)
環境構築手順
- サブネットグループの作成
- DBセキュリティグループの作成
- RDS for MySQLの作成
- EC2からRDSへ接続確認
- RDSへデータインサートするPythonコードの作成
- IAM DB認証用のポリシーの作成とアタッチ
- デモンストレーション
- おわりに
サブネットグループの作成
先んじて、DBに付与するサブネットグループを作成する。RDSインスタンスは同一リージョンに少なくとも2つのサブネットにデプロイされる(Multi-AZでのStandbyの作成など)ので、RDSに接続するコンテナが展開されるVPCと同じものを選択し、その中で複数subnetを選択する。
[AWS Bacth→コンピューティング環境→詳細]
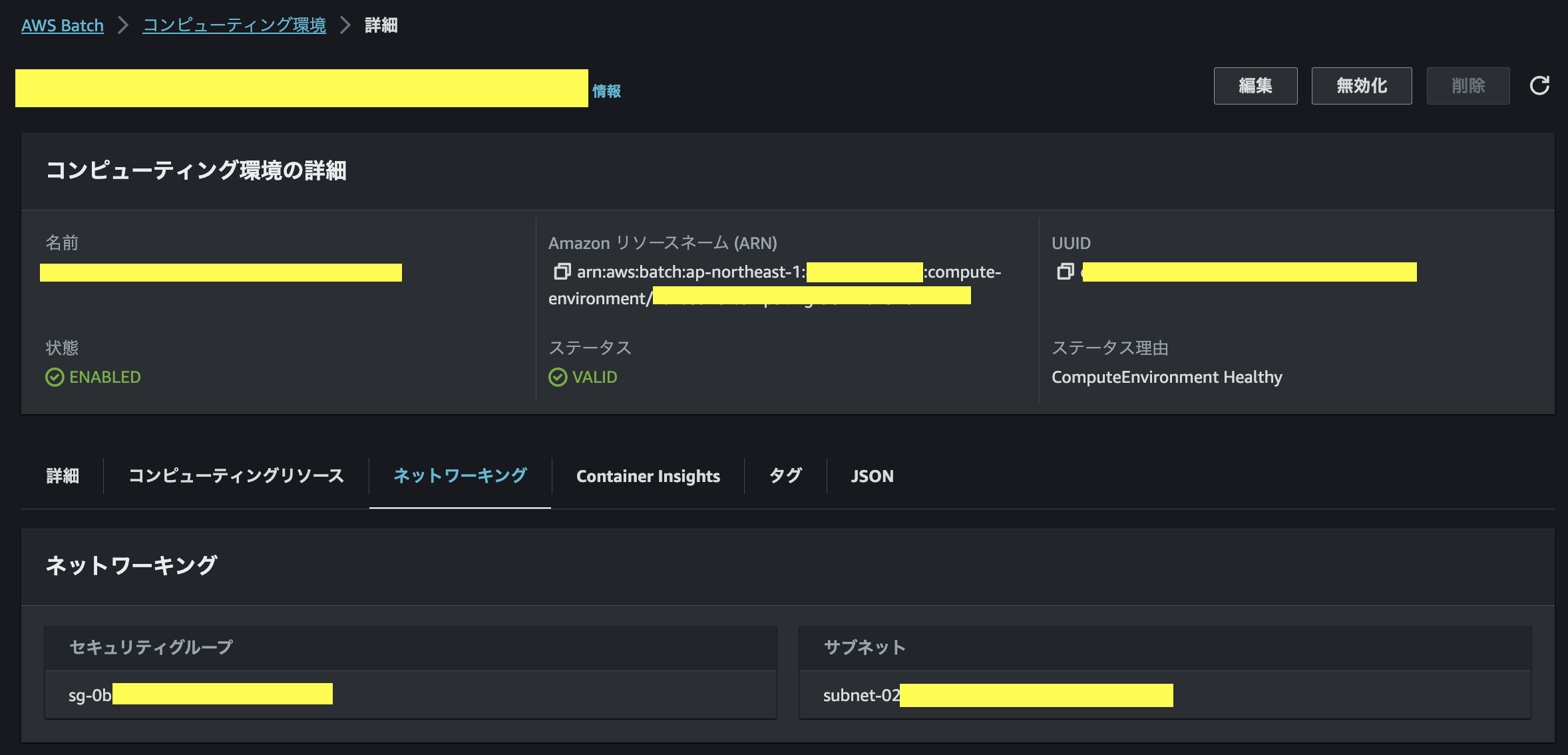
[RDSサブネットグループ]
※スクショはDB作成後に詳細画面から取得。
ECRとRDS共に同じサブネットsubnet-02...を含有している点に着目
DBセキュリティグループの作成
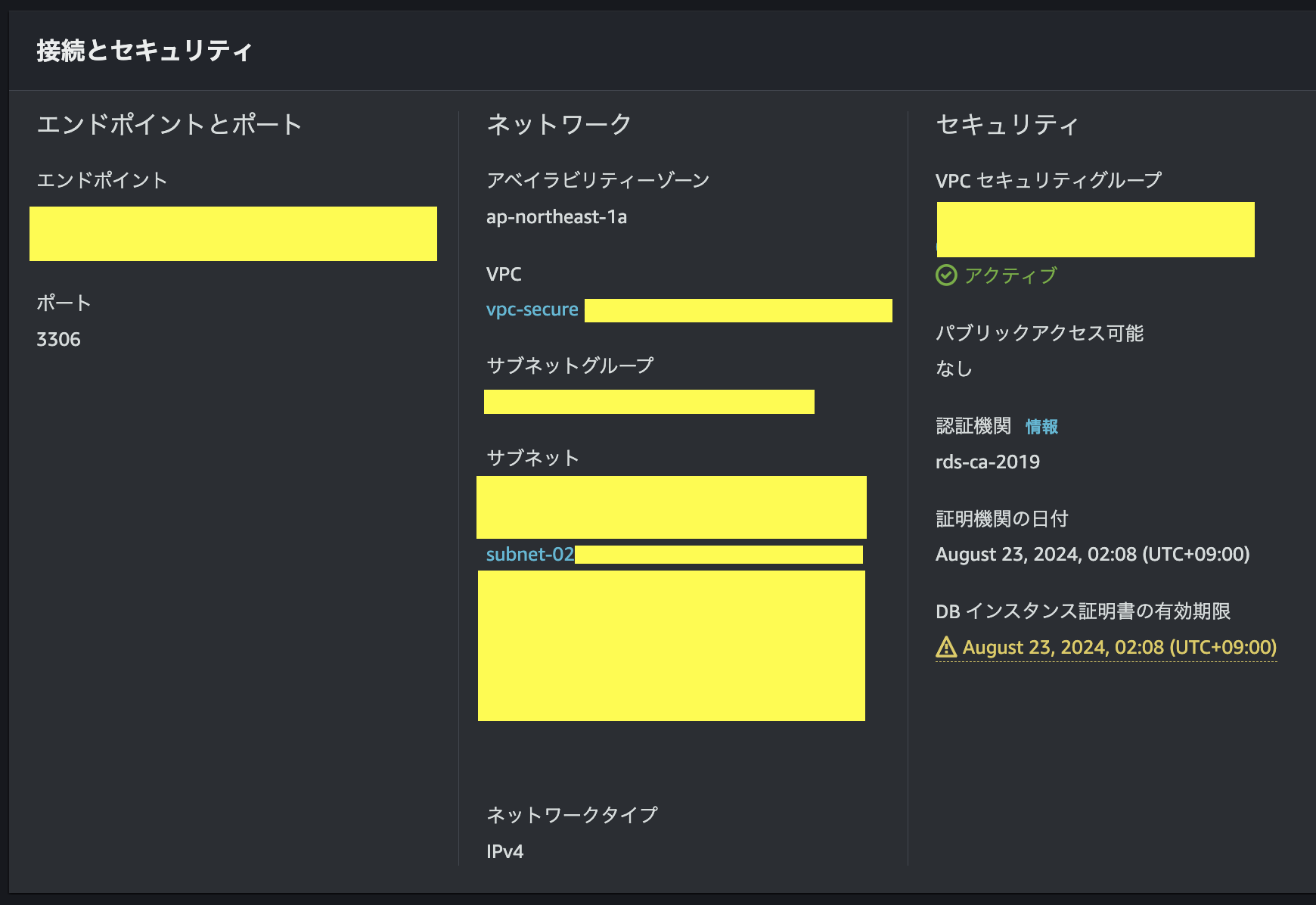
続いて、DB用のセキュリティグループの作成を行う。
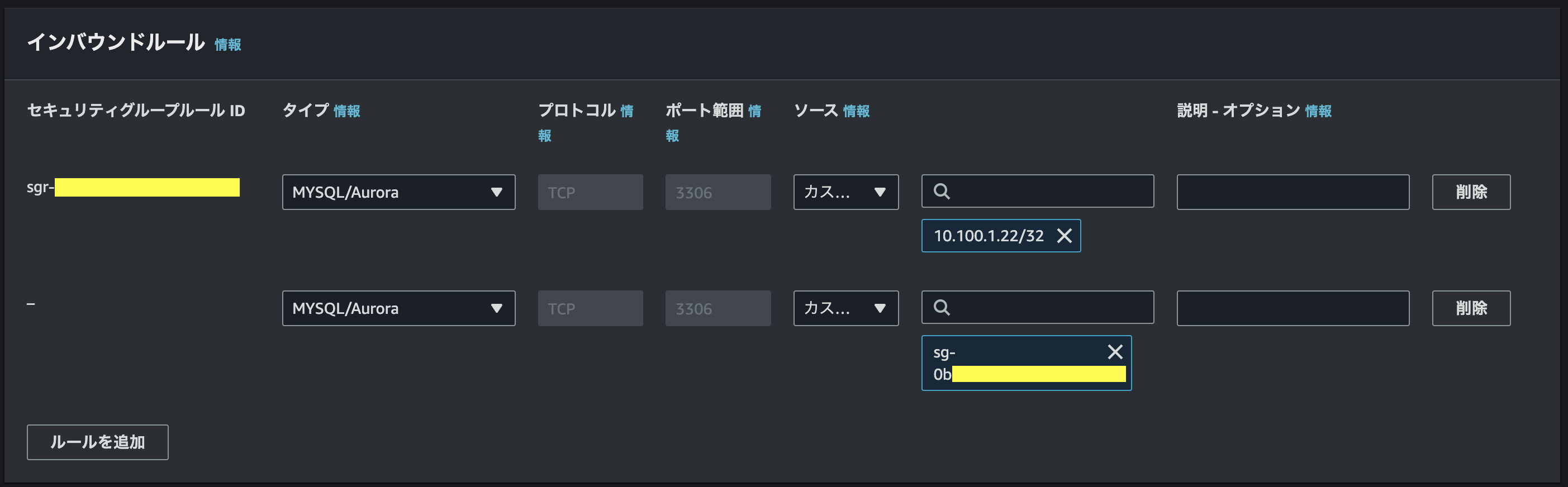
筆者のEC2はプライベート環境下にあるので、RDSのセキュリティグループはインバウンドルールにTCPプロトコルのポート3306(タイプ=MySQL/Aurora)を許可し、そのターゲットに1.ECSのセキュリティグループ、2.開発用EC2のプライベートIP(同じSGなら不要)を指定する。
RDS for MySQLの作成
RDSのコンソール画面、左側サイドメニューからデータベース(以下、DB)を選択。左上のオレンジのボタンでデータベースの作成、とあるのでそちらを押下し、手順に沿ってDBを作成する。
主な設定内容は下記の通り。
- エンジンタイプ:MySQL Community
- インスタンスクラス:db.t3.micro
- ストレージ:20GiB
- データベース認証:パスワード認証
- VPC:ECS/開発用EC2と同じVPN
- サブネットグループ:先ほど作成したサブネットグループ
- セキュリティグループ:先ほど作成したSG
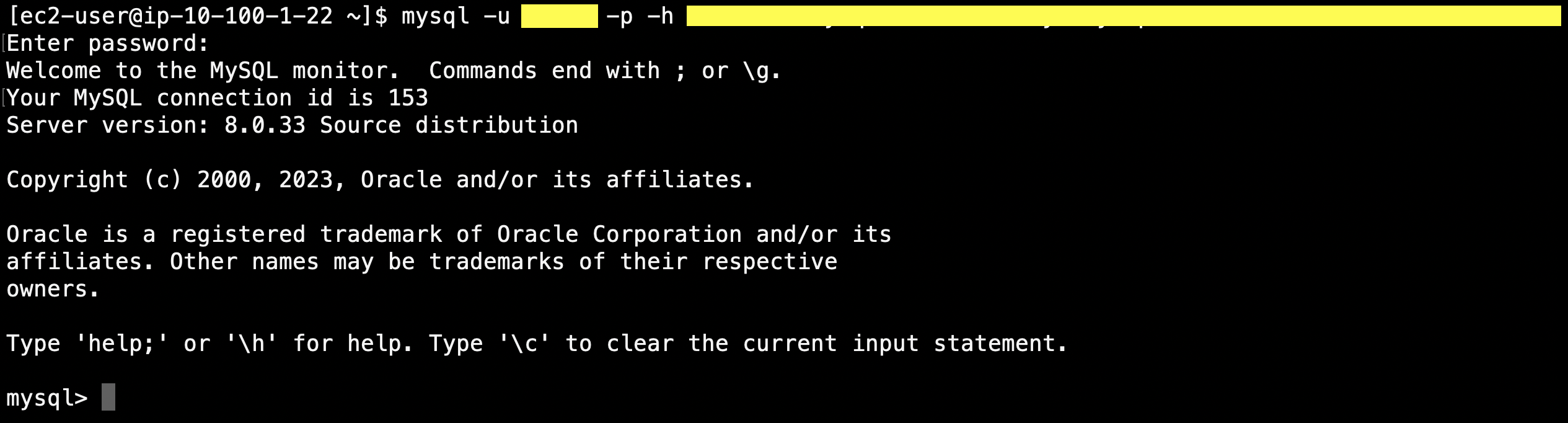
EC2からRDSへ接続確認
作成されたDBの詳細画面を開くと、エンドポイントがあるのでそれをコピーし以下のコマンドを実行
$ mysql -u "マスターユーザー名" -p -h "エンドポイント"
パスワード入力を要求されるので、設定したパスワードを入力すると下記の様に作成したRDSインスタンスへアクセスできる。
RDSへデータインサートするPythonコードの作成
ここで一旦、前編で作成したDockerイメージ内の何もしないPythonコードを改修し、RDSへインサートするにする。
改めて、ディレクトリ配置を整理する。(※)が付くファイルが本稿で新たに追加ないし変更されるファイルである。
.
└── home
└── ec2-user
├── Dockerfile
├── env.list
├── docker-compose.yml
├── .env
└── input
├── main.py (※)
├── db_access_info.json (※)
├── requirements.txt (※)
└── run.sh
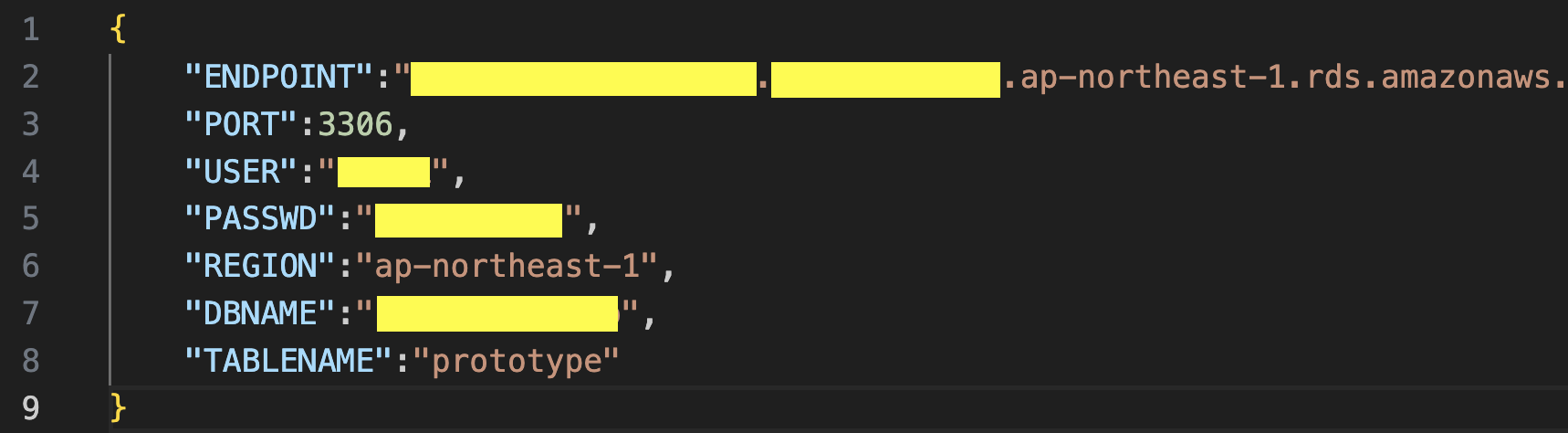
DB接続情報ファイルの作成
DB接続情報を記したJSONファイルを作成する。
以下の様に、
- エンドポイント
- ポート番号
- ユーザ名
- パスワード
- リージョン
- DB名
- テーブル名
を記述する。
Pythonファイルの改修
前編で作成したpythonファイルは読み込んだinput.csvを何の処理もせずにoutput.csvとして出力するだけであった。
ここでは読み込んだinput.csvをRDS for MySQLにpushする様に書き換える。また、元々Irisデータセットなので、Id列をインデックスとするだけの微細な変換処理を挟んでみる。(関数convert内)
import argparse
import json
import boto3
import pandas as pd
from sqlalchemy import create_engine
def read_csv(args):
df = pd.read_csv(args.i)
return df
def convert(df):
converted = df.set_index('Id')
return converted
def get_db_access_info(args):
### read access information json file
with open(args.db_access_info, 'r') as json_file:
db_access_info = json.load(json_file)
return db_access_info
def get_token(db_access_info, args):
### gets the credentials from .aws/credentials
session = boto3.Session(profile_name = args.profile_name)
client = session.client(service_name = 'rds', region_name=db_access_info['REGION'])
token = client.generate_db_auth_token(
DBHostname = db_access_info['ENDPOINT'],
Port = db_access_info['PORT'],
DBUsername = db_access_info['USER'],
Region = db_access_info['REGION'])
return token
def push(df, args):
db_access_info = get_db_access_info(args)
try:
connection_str = f'mysql+pymysql://{db_access_info['USER']}:{db_access_info['PASSWD']}@{db_access_info['ENDPOINT']}/{db_access_info['DBNAME']}'
engine = create_engine(connection_str)
df.to_sql(db_access_info['TABLENAME'], engine, index=False, if_exists='append')
print(len(df), 'rows were inserted to', db_access_info['TABLENAME'])
except Exception as e:
print('Database connection failed due to {}'.format(e))
def main(args):
df = read_csv(args)
converted = convert(df)
push(converted, args)
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-i', default='./input.csv')
parser.add_argument('--db_access_info', default='./db_access_info.json')
args = parser.parse_args()
main(args)
requirements.txtファイルの改修
上記main.pyで必要な外部ライブラリを記述する。
boto3
pandas
pymysql
sqlalchemy==1.4.46
IAM DB認証用のポリシーの作成とアタッチ
開発用EC2インスタンスとECSのジョブロールに下記のようなカスタマー管理ポリシーを追加する。ARNは適当に入れているので、適宜変更する。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"rds-db:connect"
],
"Resource": [
"arn:aws:rds-db:us-east-2:1234567890:dbuser:db-ABCDEFGHIJKL01234/db_user"
]
}
]
}
デモンストレーション
ここまで出来たところで、前編同様にDockerイメージをビルドしECRへPushする。
まず、S3 Object Createdを実施する前にMySQLで該当のtableが空である事を確認する。
mysql> select count(*) from prototype;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
実際にS3に.csvファイルをアップロードしてみて一連のフローが正しく動作するか確認する。
StepFunctions→ステートマシンの詳細画面から実行の成功が確認できたら、再度MySQLでテーブルの行数を取得する。
[MySQL実行結果]
mysql> select count(*) from prototype;
+----------+
| count(*) |
+----------+
| 150 |
+----------+
1 row in set (0.00 sec)
出来た。
今回アップロードしたテスト用のデータはIris.csvなので、150rowsで正しい。
おわりに
今回はmain.pyファイル内でデータを変換し、RDSにpushするという2つの処理を実装した。しかしながら、データ変換機能が複雑かつ計算時間が長くなったり、RDSの操作が複雑になった際はこれらのジョブは異なるタスクとして扱った方が運用の観点からは良さそうだ。
Multi stageのDockerやDocker内でMySQLを動作させるなど、色々アプローチがありそうなのでこれらを今後の展望としたい。