はじめに
こちらの参考書の第三章、Compressed Sensingより圧縮センシングの導入と二音信号を用いた実例を備忘として記録
圧縮センシングの概要
自然データにみられる固有の構造は、データがある適当な座標系でスパースに表現できる。つまり多くの場合、自然データは基底を上手く選んであげれば、少ない重要なパラメータで表現できる、ということである。例えば、画像データをフーリエ変換やウェーブレット変換などで基底変換すると、多くの係数がゼロまたは非常に小さくなる一方で、重要な情報は少数の大きな係数に集約される。
このような圧縮技術はかなりの成功を収めているが、これは元のデータの全体、つまり高解像度や高次元のデータを全て観測/取得できることが必須条件となる。ところが近年は、凸アルゴリズムを用いて原信号を高い確率で再構成する数学的なフレームが確立され、圧縮センシングが工学/応用科学の分野で広く採用されるようになってきた。
スパース性と圧縮
圧縮可能信号$\boldsymbol{x}\in\mathbb{R}^n$がスパース表現行列$\boldsymbol{\Psi}\in\mathbb{R}^{n\times n}$とスパースベクトル$\boldsymbol{s}\in\mathbb{R}^n$で表現できる時、
\begin{align}
\boldsymbol{x}=\boldsymbol{\Psi s}\tag{1}
\end{align}
画像や音声データは高い圧縮性を持つが、これらのデータにフーリエ変換やウェーブレット変換を適用した時に、スパースベクトル$\boldsymbol{s}$ほとんどの要素は小さな値となるので、これらをゼロに置換しても質の低下はほぼ無視できる。
圧縮センシング
圧縮センシングは非常に少ない測定値から原信号を再構成するために、一般的な基底における信号のスパース性を利用する。
原信号$\boldsymbol{x}$($n$個の測定値)がスパース表現行列$\boldsymbol{\Psi}$において、$K$-スパースである場合、$\boldsymbol{x}$全体を直接測定せず、ランダム選択ないし圧縮した測定値を収集して、変換後の座標系で$\boldsymbol{s}$の非ゼロ要素を解くことができる。
測定値を$\boldsymbol{y}\in\mathbb{R}^p,\ K<p\ll n$として、
\begin{align}
\boldsymbol{y}=\boldsymbol{Cx}
\end{align}
ここで、センシング行列$\boldsymbol{C}\in\mathbb{R}^{p\times n}$は原信号$\boldsymbol{x}$に関する$p$個の線形測定の集合を表す。
劣決定性とスパースベクトルの求解
スパースベクトル$\boldsymbol{s}$があれば、式$(1)$から原信号$\boldsymbol{x}$を復元できるので、測定値$\boldsymbol{y}$、スパース表現行列$\boldsymbol{\Psi}$、センシング行列$\boldsymbol{C}$からスパースベクトル$\boldsymbol{s}$を見つけることを目指す。
\begin{align}
\boldsymbol{y}
=\boldsymbol{Cx}
=\boldsymbol{C\Psi s}
=\boldsymbol{\Theta s}
\end{align}
この上式は劣決定性、つまり$p\ll n$であり、無限の解$\boldsymbol{s}$が存在する。ここで、最も疎な解$\hat{\boldsymbol{s}}$は以下の最適化問題を満足する。
\begin{align}
\begin{cases}
{\rm 目的関数:}\quad&\hat{\boldsymbol{s}}
=\mathop{\rm arg~min}\limits_{\boldsymbol{s}}\|\boldsymbol{s}\|_0 \\
{\rm 制約条件:}\quad&\boldsymbol{y}
=\boldsymbol{C\Psi s}
\end{cases}
\end{align}
$|\cdot|_0$は$\ell_0$-擬似ノルムであり、次のように定義される。
\begin{align}
\|\boldsymbol{s}\|_0
=\sum_{i=1}^n\boldsymbol{1}(s_i\neq0)
\end{align}
つまり、$\ell_0$-擬似ノルムはベクトル$\boldsymbol{s}$の非ゼロ成分の数を計測し、スパース性を測定していることになる。
最適化問題の困難性
先述した、$\hat{\boldsymbol{s}}$が満足する最適化問題は非凸であり、最適解を見つけるには$n$と$K$の組み合わせを全探索しなければならない。特に、空間$\mathbb{R}^n$で取り得る$K$-スパースなベクトルを探査しなければならず、$K$の正確なスパースレベルが不明な場合、探索はさらに広範囲になってしまうため、現実的な解法ではない。
復元信号$\hat{\boldsymbol{x}}$を回帰問題$\hat{\boldsymbol{x}}=\mathop{\rm arg~min}\limits_{x}|\boldsymbol{Cx}-\boldsymbol{y}|_{2}^{2}$によって求めること考えると、$\ell_{2}$-ノルムが最小となる解は$\hat{\boldsymbol{x}}=C^{+}\boldsymbol{y}$となる。これと正則化項付きRidge回帰、Lasso回帰による復元例を以下に示す。
$M=100$、$N=200$として$N$次元単位超球上のベクトルを一様に独立に選んだあるセンシング行列$\boldsymbol{C}$を用いて観測信号$\boldsymbol{y}=\boldsymbol{Cx}_{0}$を得た場合を考える。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
# Constants
M = 100
N = 200
sparsity_level = 10
lambda_reg = 0.1
lambda_lasso = 0.001
# Function to generate a vector on an N-dimensional unit hypersphere
def generate_random_unit_vector(n):
vec = np.random.randn(n)
return vec / np.linalg.norm(vec)
# Generate a sparse signal x_0
def generate_sparse_signal(N, sparsity_level):
x_0 = np.zeros(N)
x_0[np.random.choice(N, sparsity_level, replace=False)] = np.random.randn(sparsity_level)
return x_0
# Compute the Moore-Penrose pseudo-inverse of matrix A
def pseudo_inverse(A):
return np.dot(A.T, np.linalg.inv(np.dot(A, A.T)))
# Generate observation matrix A and sparse signal x_0
A = np.array([generate_random_unit_vector(N) for _ in range(M)])
x_0 = generate_sparse_signal(N, sparsity_level)
y = np.dot(A, x_0)
# Recover x_0 using pseudo-inverse
x_0_recovered = np.dot(pseudo_inverse(A), y)
# Recover x_0 using regularized least-squares
A_T_A, lambda_I = np.dot(A.T, A), lambda_reg * np.eye(N)
x_hat = np.dot(np.linalg.inv(A_T_A + lambda_I), np.dot(A.T, y))
# Recover x_0 using Lasso regression
lasso = Lasso(alpha=lambda_lasso, fit_intercept=False, max_iter=1000)
lasso.fit(A, y)
x_hat_lasso = lasso.coef_
# Plot the results
plt.figure(figsize=(16, 9))
plt.subplot(2, 2, 1); plt.stem(x_0); plt.title('Original Sparse Signal x_0'); plt.xlabel('Index'); plt.ylabel('Value'); plt.grid(True)
plt.subplot(2, 2, 2); plt.stem(x_0_recovered); plt.title('Recovered Signal x_0'); plt.xlabel('Index'); plt.ylabel('Value'); plt.grid(True)
plt.subplot(2, 2, 3); plt.stem(x_hat); plt.title('Recovered Signal x_hat (Regularized)'); plt.xlabel('Index'); plt.ylabel('Value'); plt.grid(True)
plt.subplot(2, 2, 4); plt.stem(x_hat_lasso); plt.title('Recovered Signal x_hat (Lasso)'); plt.xlabel('Index'); plt.ylabel('Value'); plt.grid(True)
plt.tight_layout(); plt.show()
出力結果は以下の通り。
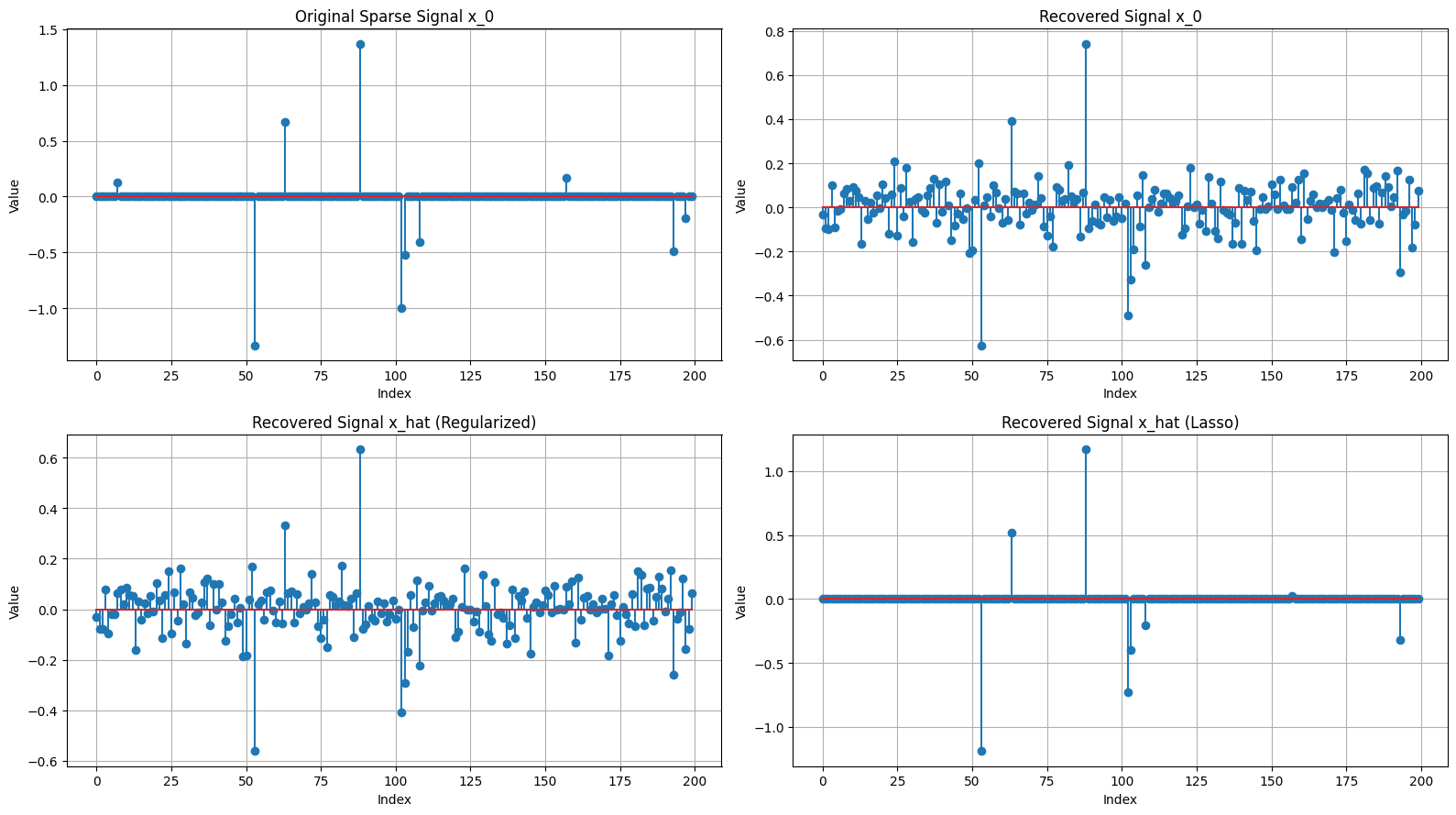
この結果から、擬似逆行列を用いた復元方法とRigde回帰による復元方法では復元信号がスパースになっていないことが観察できる。その一方で、$\ell_1$-正規化項を導入したLasso回帰では、スパースな解を得ることが出来ている。
この例が示すように、ある特定の条件下では$\ell_0$-最適化問題を凸$\ell_1$-最小化問題へと緩和することができる。
\begin{align}
\begin{cases}
{\rm 目的関数:}\quad&\hat{\boldsymbol{s}}
=\mathop{\rm arg~min}\limits_{\boldsymbol{s}}\|\boldsymbol{s}\|_1 \\
{\rm 制約条件:}\quad&\boldsymbol{y}
=\boldsymbol{C\Psi s}
\end{cases}
\end{align}
$\ell_1$-ノルム$|\cdot|_0$、あるいはマンハッタン距離と呼ばれる距離関数は次のように定義される。
\begin{align}
\|\boldsymbol{s}\|_1=\sum_{k=1}^n|s_k|
\end{align}
$(6)$の$\ell_1$-最適解が高確率で$(4)$の$\ell_0$-最適化問題の最も疎な解に収束するためには、以下の2つの条件を満足する必要がある。
-
非コヒーレンス性、つまり行列$\boldsymbol{C\Psi}:=\boldsymbol{A}$と見なした場合、行列$\boldsymbol{A}$の列同士の相関が低いこと。
\begin{align} \mu\left(\boldsymbol{A}\right) &=\max_{i,j,i<j} { \cfrac{ |\langle\boldsymbol{a}_i,\boldsymbol{a}_j\rangle| } { \|\boldsymbol{a}_i\|_2\|\boldsymbol{a}_j\|_2 } } \end{align}このように正しい原信号が$\ell_p$-ノルム最小化により再構成されることを完全再構成と呼ぶ。完全再構成か否か調べるには、1.零空間特性、2.制限等長性、3.非コヒーレンス、などがあるが、この非コヒーレンスの評価が簡単かつ重要な意味を持つ(らしい)。参考はこちら。
特に、ベルヌーイ/ガウシアンランダム行列は一般的なスパース表現行列と制限等長性を満足する確率が高いことが知られている。
-
測定数$p$は以下のオーダーで十分に大きい。
\begin{align} p\approx\mathcal{O}(K\log{(n/K)})\approx k_1K\log{(n/K)}\tag{2} \end{align}係数$k_1$は行列$\boldsymbol{C}\boldsymbol{\Psi}$がどの程度非コヒーレントであるかに依存し、経験的に決定される。
二音オーディオ信号の復元
圧縮センシングの例として、ランダム測定値のスパース集合から高次元信号を復元する。以下のような二音信号を考える。
\begin{align}
x(t)=\cos{\left(2\pi\times97t\right)}
+\cos{\left(2\pi\times777t\right)}\tag{3}
\end{align}
この原信号$x(t)$は周波数領域で$97\ \text{Hz}$と$777\ \text{Hz}$とで、明らかに疎である。この信号を正確にデジタル化するために必要な最低限のサンプリング周波数(Nyquist sampling rate)は$777\times2=1554\ \text{Hz}$となる。
しかし、原信号の周波数が疎であることを利用するならば、たった$128\ \text{Hz}$のランダムサンプルで正確に復元することができる。
# Import libraries
import numpy as np
import matplotlib.pyplot as plt
from scipy.fft import dct, idct
plt.rcParams['figure.figsize'] = [12, 8]
plt.rcParams.update({'font.size': 12})
まずは式$(3)$で作成した原信号を生成し、フーリエ変換を施す。
# Generate signal, DCT of signal
n = 4096
t = np.linspace(0, 1, n)
x = np.cos(2 * 97 * np.pi * t) + np.cos(2 * 777 * np.pi * t)
xt = np.fft.fft(x)
# Power spectral density
PSD = xt * np.conj(xt) / n
次に、$128\ \text{Hz}$でランダムにデータを抽出
# Randomly sample signal
p = 128
perm = np.floor(np.random.rand(p) * n).astype(int)
y = x[perm]
今回はCoSaMPという貪欲アルゴリズムを用いて原信号を復元する。
CoSaMPコードでは、スパースレベル$K$を引数として求めているが、この量は事前に知ることは出来ない。
勿論、scipyなどを用いて$\ell_1$-最適化を解いても良いのだが、式$(2)$のように間接的に$K$に依存する測定数$p$を持つことを求められる。あと、計算に時間が掛かる。
# Define cosamp function from https://github.com/avirmaux/CoSaMP
def cosamp(phi, u, K, epsilon=1e-10, max_iter=1000):
"""
Return an `K`-sparse approximation of the target signal
Input:
- phi, sampling matrix
- u, noisy sample vector
- K, sparsity
"""
a = np.zeros(phi.shape[1])
v = u
it = 0 # count
halt = False
while not halt:
it += 1
print("Iteration {}\r".format(it), end="")
y = np.dot(np.transpose(phi), v)
omega = np.argsort(y)[-(2*K):] # large components
omega = np.union1d(omega, a.nonzero()[0]) # use set instead?
phiT = phi[:, omega]
b = np.zeros(phi.shape[1])
# Solve Least Square
b[omega], _, _, _ = np.linalg.lstsq(phiT, u, rcond=None)
# Get new estimate
b[np.argsort(b)[:-K]] = 0
a = b
# Halt criterion
v_old = v
v = u - np.dot(phi, a)
halt = (np.linalg.norm(v - v_old) < epsilon) or \
np.linalg.norm(v) < epsilon or \
it > max_iter
return a
上記の関数を用いて、圧縮センシングによる原信号の復元を実施
# Solve compressed sensing problem
Psi = dct(np.identity(n), norm='ortho')
Theta = Psi[perm, :]
# CS via matching pursuit
s = cosamp(Theta, y, 10, epsilon=1.e-10, max_iter=10)
xrecon = idct(s, norm='ortho')
ここで、Psi=dct(np.identity(n))は長さ$n$の離散コサイン変換(DCT)行列を生成している。公式ドキュメントによれば、type引数にはデフォルトでtype=2が指定されており、長さ$N$の入力$x$に対して、次のように定義されている。
\begin{align}
y_k = 2\sum_{n=0}^{N-1}
x_n
\cos{
\left(
\cfrac{
\pi k(2n+1)
}{
2N
}
\right)
}
\end{align}
このDTC-IIは、DFT同様に信号を時間領域から周波数領域に変換する。また、norm="ortho"とすることで、$1/\sqrt{2N}$を掛けて、ユニタリ変換のように(=エネルギー保存)なるようにスケーリングしてくれる。
上記コードでは、この入力に$n\times n$の単位行列を与えているので、結果となる$\Psi$には以下の値が格納される。
\begin{align}
\psi_{j,k}
&=
2\sum_{n=0}^{N-1}
\delta_{j,n}
\cos{
\left(
\cfrac{
\pi k(2n+1)
}{
2N
}
\right)
} \\
&=2\cos{
\left(
\cfrac{
\pi k(2j+1)
}{
2N
}
\right)
}
\end{align}
こうして得られた表現行列$\Psi$は入力ベクトル$x$に対してDTC-IIを適用させる。
# Plot
time_window = np.array([1024, 1280])/4096
freq = np.arange(n)
L = int(np.floor(n/2))
fig, axs = plt.subplots(2, 2)
axs = axs.reshape(-1)
axs[0].plot(t, x, color='k', linewidth=2)
axs[0].plot(perm/n, y, color='r', marker='x', linewidth=0, ms=12, mew=4)
axs[0].set_xlim(time_window[0], time_window[1])
axs[0].set_ylim(-2, 2)
axs[1].plot(freq[:L].real, PSD[:L].real, color='k', linewidth=2)
axs[1].set_xlim(0, 1024)
axs[1].set_ylim(0, 1200)
axs[2].plot(t, xrecon, color='r', linewidth=2)
axs[2].set_xlim(time_window[0], time_window[1])
axs[2].set_ylim(-2, 2)
# computes the (fast) discrete fourier transform
xtrecon = np.fft.fft(xrecon, n)
# Power spectrum (how much power in each freq)
PSDrecon = xtrecon * np.conj(xtrecon)/n
axs[3].plot(freq[:L].real, PSDrecon[:L].real, color='r', linewidth=2)
axs[3].set_xlim(0, 1024)
axs[3].set_ylim(0, 1200)
plt.show()
出力結果は以下の通り。
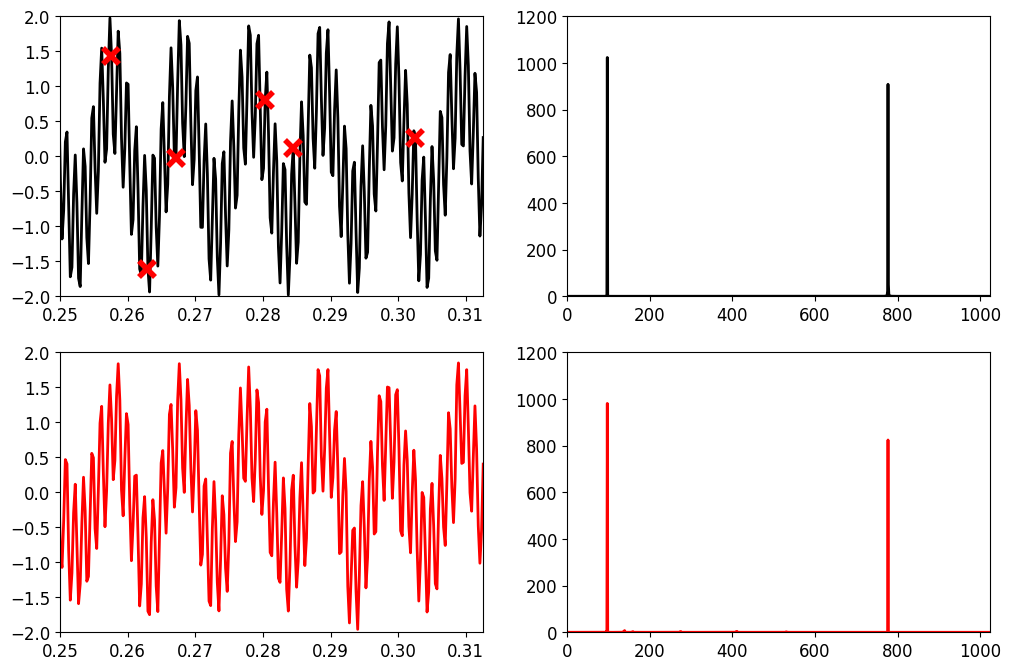
上段が原信号とそのPSDを示しており、下段が復元信号のそれを示している。
おわりに
本稿では、圧縮センシングの概念と簡単な例をPythonで実装した。
長くなってしまうので、次回はスパース表現についてもう少し掘り下げてみたいと思う。