はじめに
2021年12月18日にNumerai Meetup Japan 2021が開催された(Numeraiについては過去記事「Numeraiトーナメント~伝統的クオンツと機械学習の融合~」を参照のこと)。このMeetupにて筆者も「Machine Learning for Advancing Traditional Quantitative Approach」と題してプレゼンを行った。
このプレゼン内容をベースとして文字起こししたので「機械学習による株価予測」シリーズいろはの"は"の章の代わりとさせていただく。
なお本記事はNumerai Advent Calendar 2021の24日目の記事とさせて頂いている。
参考:前回記事
機械学習による株価予測 いろはの”い”
機械学習による株価予測 いろはの”ろ”
本記事の目的
機械学習による株価予測は世界中で様々な研究が行われており、毎年の学会では最新の研究内容を聴講することができる。ファイナンスにおけるAIの適用事例について取りまとめられた文献も多く存在する[1][2]。またここ数年では[3]、[4]のような書籍も出版されており、より一般に広く認知されてきていると言ってよいだろう。
一方で、従来のクオンツではBARRAモデルに代表されるリスクモデルが採用されてきた。これらは線形回帰のような古典的な統計学がベースとなっているが、ここから一足飛びで機械学習による予測へ移行するためにはいろいろと障害が多い。
本記事では、従来のクオンツにおいてどの部分にどのように機械学習を適用することで収益機会を拡張できるのか、従来の体系に沿ったリターン分類を元に考察する。最終的に、従来のクオンツを発展させるための機械学習モデリングのフレームワークの一例を導出する。
それでは順を追ってみていこう。
株式市場の一日がどのように動いているか
さて、読者の皆様はご自身で株式投資を行っているだろうか?もしも株式投資を行っていないのであれば、それは「株式投資はハイリスクで資産を失う可能性がある危険なもの」という悪いイメージを持っているかもしれない。
まず一般の方が株式投資を行う場合、どのような手法があるだろうか考えてみよう。例えばモニターに張り付いて短期売買を繰り返すデイトレや、決算や不祥事などのイベントに乗じる手法、またはそのとき市場が注目しているテーマ株に対して集中投資するような方法が考えられる。もう少し長い目線でみると、配当や株主優待を目的として現物を保有したり、インデックスETFやロボアドの積み立てを行う方法もある。
このような個人投資家はどのような相場情報を活用しているのだろうか。例えば当日の出来高や上昇率のランキングで注目銘柄を探してみたり、マクロ情勢を背景とした各業種へのマネーフローを観察したり、ニュースが飛び込んできた銘柄のチャートを即座に目で追ったりするだろう。モニターに張り付くような専業投資家であれば、連れ高・連れ安銘柄を睨みながらアルゴリズムで板に流入する指値の変化を凝視している方もいるだろう。
一方で、クオンツの目線はこれらとは全く異なる。
ここでは一例として、モメンタム(直近1年間の騰落率)を用いて各銘柄の値動きを観察してみたい。まず株式市場の2000超の銘柄についてそれぞれのモメンタムを計算しランキングする。ランキング値が2000を超えるような高い銘柄はこの1年間で上昇率が大きい銘柄、反対にランキング値が低い銘柄はこの1年で大きく下落したような銘柄である。これらを横軸にずらりと並べ、縦軸には当日の株価の上昇率をプロットした。
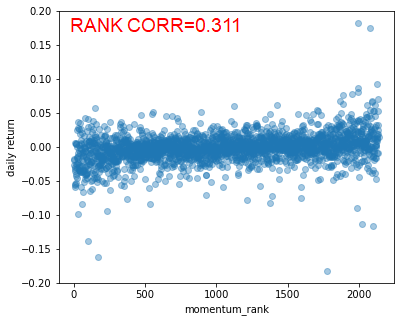
(図:ある一日の株式市場の値動き)
するとどうだろう。モメンタムのランキングに対してきれいに右肩上がりの特性が見て取れる。この日は、過去1年間で上昇していた銘柄がさらに買われ、下落していた銘柄は売られるという「モメンタム・デイ」であるのだ。ニュースや決算などの個別な事情に依らず、市場全体でこのような特性が具現化している。これはとても大きな力である。
市場にはこのように大きな力が働くにも関わらず、これに言及する者は殆どいない。相場に関する一般書籍は数多く存在するが、このような現象に触れたものは見たことがない。これは非常に残念なことである。
クオンツモデル
このようにある指標(ファクターと呼ぶ)によって市場全体の価格が動くことで発生する収益機会をファクターリターンと呼ぶ。ファクターリターンは、以下の単純な線形回帰の回帰係数$f$で表すことができる。
r_{i,t}=f_t \times x_{i,t}+u_{i,t}
ここで$r_{i,t}$は時刻tにおける銘柄iのリターン、$x_{i,t}$は銘柄iが取るファクターの値であり、これをファクターエクスポージャーと呼ぶ(銘柄iがそのファクターに対してどれだけ曝されているか、ということを意味する)。この式を$t=0$から$t=T$まで各々によって計算し、得られたファクターリターン$f_t$を時系列に積み上げていくと、以下のような図を得ることができる。この曲線が上下どちらか一方に顕著に推移するものは、市場はそのファクターに対して安定した特性が具現化するということである。
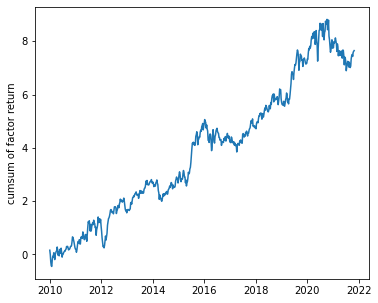
(図:モメンタムファクターリターンの推移)
実際のクオンツでは、上記の単回帰式を重回帰に拡張し、それぞれのファクターリターンの期待値や互いの共分散をもとにポートフォリオを決めていくことになる。
伝統的なクオンツと機械学習の対応
さて、ここで伝統的なクオンツと機械学習の比較してみよう。
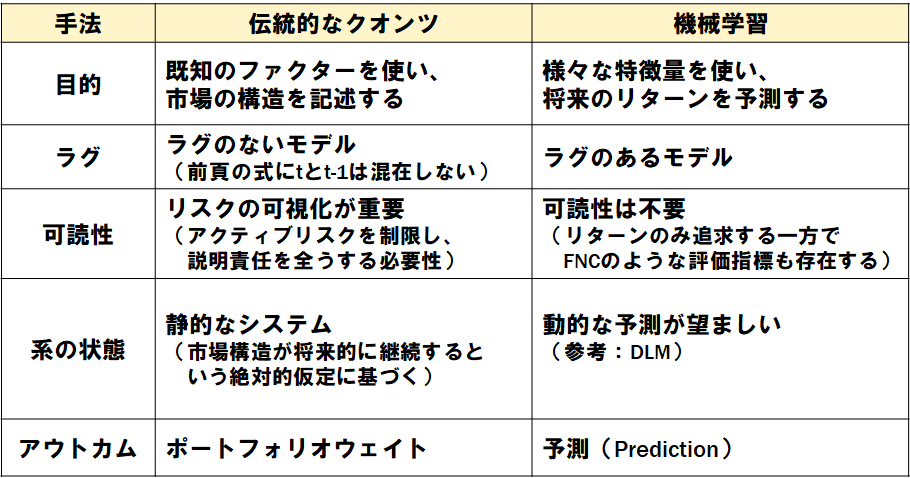
伝統的なクオンツの目的は既知のリスクファクターを用いて市場の構造を記述することにある。この結果からポートフォリオがそれらのリスクファクターに対して、どれくらいリスクを孕んでいるか定量化することができる。当然ではあるが、実際のファンドの運用ではリターンだけを追求するわけにはいかない。リターンを得る過程でどの程度のリスクが存在するか把握し、リスクの量を制限し、顧客に対して説明する義務があるのだ。このため、当然運用モデルには可読性が求められるのである。
これに対して機械学習の目的は、様々な特徴量を用いてリターンを予測することに重点がおかれる。各特徴量はターゲットとなるリターンに対して時系列でラグを設けなければならない(そうしないとリークになってしまう)。近年では機械学習の可読性を向上させる研究もなされているが、可読性は不要と割り切ってしまうことが多い。
次に系の状態に着目すると、従来のクオンツは静的な系である。これは、市場構造が将来的に継続する(すなわちじ自己相関を持つ)という絶対的な仮定に基づいたものである。これに対して機械学習では、刻々と変化する情勢に合わせて動的に柔軟に予測を変化させることが望まれるだろう。
最後にアウトカム(成果物)であるが、従来のクオンツではポートフォリオウェイトがアウトカムとなる。従来のクオンツでは個別銘柄のウェイト上限や業種別のウェイト上限に加え、それぞれのリスクファクターに対してもエクスポージャーを制限して最終的なポートフォリオウェイトを算出する。リスク管理が第一であるためだ。
一方で機械学習のアウトカムとしては予測が重視される。この予測は最終的にはポートフォリオウェイトに変換されるものであるが、機械学習では何よりも予測が当たるか外れるかその精度が重視されるのだ。
これらの手法のどちらが良いかという議論には意味がない。当然、両者にメリットとデメリットは存在し、最終的には顧客が満足する方を選べばよいだけの話である。しかし両者の是非はともかく、今後機械学習へのシフトが起こる可能性は十分にあると考える。
リターンの分解
さて、それでは従来のクオンツに対して機械学習をどのように適用していくべきか、議論を始める。
まずすべきことは、従来のクオンツが収益源をどのように捉えているか理解することである。
以下の図は、従来のクオンツ、特にアクティブファンドのリターンの分類を示す。アクティブリターンには、市場要因に起因するシステマティックな部分と、市場の値動きに依存しないレジデュアルな部分に分けることができる。前者がベータで後者がアルファだ。
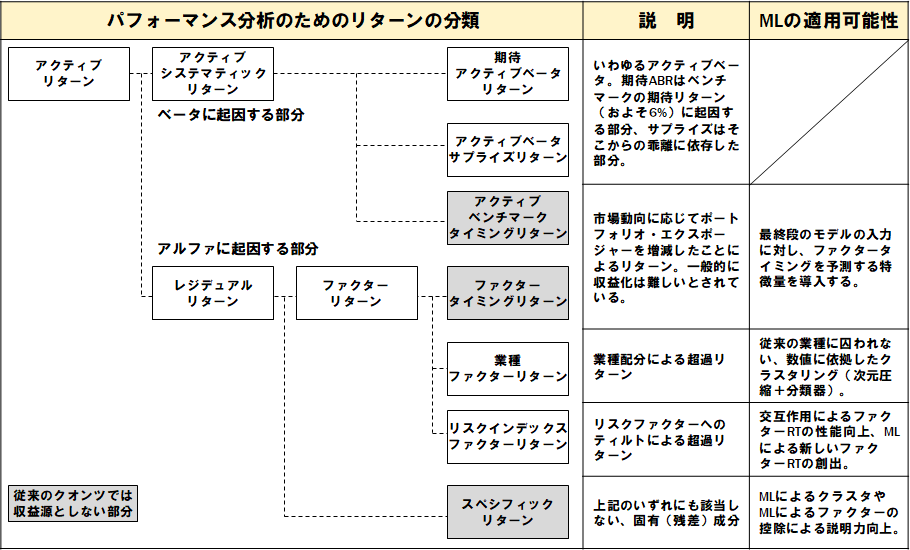
まずはアクティブベータについて。ポートフォリオが完全にベータ・ニュートラルになっている場合、市場の上昇下落に伴うポートフォリオの損益は発生しない。しかし、例えばポートフォリオがハイベータ株を選好してリスクテイクしている場合もあれば、逆にローベータな銘柄のウェイトが高くディフェンシブになっている場合もあるだろう。アクティブベータを取っている場合は当然ながら市場動向によって損益が発生する。
次にタイミングリターンである。これはベータタイミングによるものとファクタータイミングによるものがある。タイミングリターンとは、市場動向に応じてポートフォリオ・エクスポージャーを増減したことに起因するリターンである。市場が上がりそうだと感じたら、グッとハイベータ株のウェイトを上げるのだ。上手くタイミングが合えばリターンに結びつく。しかし、諸所の文献ではこのタイミングリターンは収益化が難しいとされており、従来のクオンツでもこれを狙うようなモデルにはなっていない。
続いてファクターリターンであるが、これは業種によるものとリスクファクターによるものに分類される。この部分に関しては本記事の前半で説明しているためここでは割愛する。
最後にスペシフィックリターンであるが、これは上記のいずれにも該当しない銘柄固有の残差成分である。
各所への機械学習の適用可能性
では、前節で述べた各リターンに対し、どのように機械学習が適用できるか考えてみる。
まずタイミングリターンであるが、これは単純に機械学習の入力にファクタータイミングを予測するための特徴量を導入することが挙げられる。ただし、機械学習がそれ自体でファクタータイミングの概念を学習するとは限らないため、これを明示的に示すために前段にファクタータイミングの予測モデルを備えることが適当であろう。
続いて業種ファクターリターンであるが、これは旧来の業種分類に捉われない、数値に依拠したクラスタリングが考えられる。わざわざ自身で業種分類をやり直す理由であるが、そもそも企業の主力事業は変化するし、経済産業界の変遷に伴って各業種の位置付も変わる。旧来から使われている業種分類は不適当である場合が多いためである。
次にリスクファクターであるが、これは機械学習を用いることによって、交互作用やファクターの持つ非線形性を考慮することでファクターリターンの性能を向上することができる。また、機械学習を使ってこれまでにない新しいリスクファクターを創出することも可能であろう。
最後にスペシフィックリターンであるが、そもそも従来のクオンツではスペシフィックリターンをファクターとしていないため、これは機械学習の特徴量として取り込む必要がある。また、機械学習で創出した新しいクラスタやファクターの情報を控除することで、スペシフィックリターンが持つ予測性能を向上できる可能性がある。
順不同となるが、以降でそれぞれについて説明する。
機械学習の適用について
(1)交互作用
交互作用とは、2つの因子が組み合わさることで現れる相乗効果のことである。交互作用の具体的な事例を観察するために、ここでは時価総額の大きい銘柄と小さい銘柄の区分に分けてファクターリターンの推移を観察してみる。
以下の図から分かるように、モメンタムファクターとボラティリティファクターは、特に小型銘柄でその特性が顕著に現れることが分かる。このように、株価予測における交互作用とは、ユニバースを限定することでファクターリターンの性能を向上させる効果があることが分かる。ここでいうユニバースとは、時価総額、リージョン、業種、バリューなどを指す。なお、様々なクオンツ関連の文献では、交互作用ではなく非線形性と称すことが多いように見受けられる。
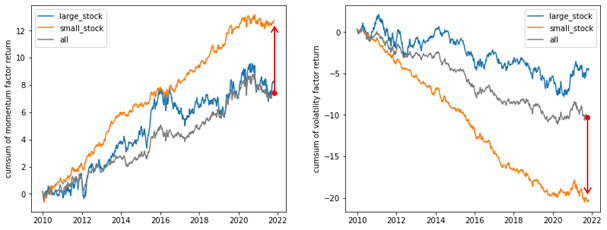
(図:モメンタムファクター及びボラティリティファクターにおける交互作用効果)
以下の図は機械学習によってモメンタムファクターとサイズファクターの交互作用の強さを図示したものである[5]。このように既存の機械学習手法の殆どは、明示的に与えなくとも交互作用を自動的に考慮してくれる。
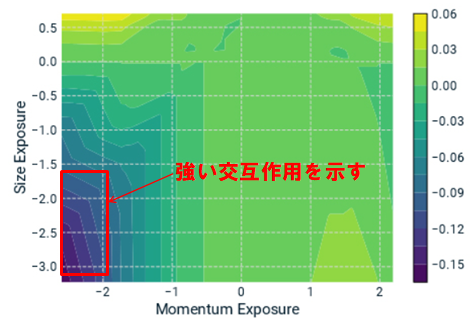
(図:モメンタムとサイズの交互作用の強度)文献[5]より引用
(2)ファクタータイミング
ファクタータイミングとは、前述のとおりアウトパフォームするファクターを見極める動的な戦略である。ファクタータイミングは、もともとレジームとしての意味合いが強く、例えばマクロ指標との関連付けとして、景気回復期はバリュー、景気後退期はクオリティがアウトパフォームするというリサーチもある。一般にファクタータイミングはコスト控除後のエッジが出にくいとされるが、機械学習では単一の戦略としてではなく特徴量としてこれを取り込むことでモデルの改善が見込まれる(ファクタータイミングについては文献[6]参照のこと)。
さて、ファクタータイミングは上記のような長期的な視点ではなく、もっと短期的な利用の仕方を考えることができる。以下は、マクロ市況で場合分けしたときの、ファクターリターンの挙動を示している。
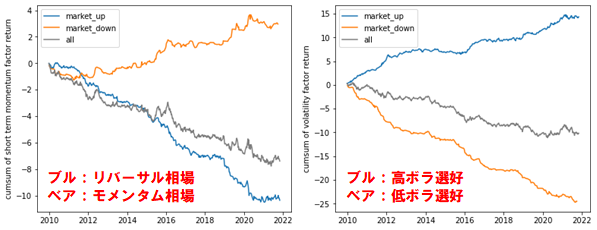
(図:モメンタムファクター及びボラティリティファクターにおけるファクタータイミング効果)
まず1つ目の事例であるが、ショートタームモメンタム(直近1ヶ月の騰落率)は、時系列通算で見ると負のファクターリターン(つまりリバーサルの特性)を示している。これを市場が上昇したときと下落したときに分けて観察すると、その挙動が全く異なることが分かる。市場が上昇した日はリバーサルの特性が強いが、逆に市場が下落した日はショートタームモメンタムの特性は正方向に推移するのだ。定性的に説明すると、市場が上昇している日は割安になった株が買い漁りされるが、市場が下落した日にはそのような銘柄は見向きもされず売り払われるということを意味する。
また、2つ目の事例としてボラティリティファクターを挙げる。ボラティリティファクターは、時系列通算で見ると負のファクターリターン(低ボラ銘柄が選好される低ボラ効果)が発生するが、市場の上昇日には正のファクターリターン(つまり高ボラ選好)になることが分かる。当然、市場の下落日にはリスクの低い低ボラ銘柄がさらに選好されることは言うまでもない。
これらのファクタータイミングを予測するために、マクロ指標を用いることが考えられる。一方で、ファクターには自己相関が働く(ファクターモメンタムと呼ぶ)ことがあり、決して説明力は高くないものの、ファクタータイミングを予測するための特徴量の1つとなりうる。
ファクタータイミングの予測はモデルに必ず加えるべきである。説明できるかどうかよりも、賭けの対象が増えることが大事なのである。
(3)業種クラスタリング
数値に依拠した業種クラスタリングは、次元圧縮と単純な分類器によって実現できる。次元圧縮の手法は線形であればPCA、非線形であればt-SNE、UMAPなどがメジャーな手法である。圧縮する元々のデータであるが、これは単純に時系列のリターンデータでよい。
業種クラスタリングでは、既存の業種では考慮されていない細かな分類や、業種を隔てたテーマでの分類も実現できる。以下は東証33業種にクラスタリングを適用した事例である[7]。一例として電気・ガス業に対して適用した場合を示す。このように電力会社とガス会社が分類されるのはもとより、同じ電力会社でも地域等に応じて分類されることが分かる。

(図:電気・ガス業のクラスタリング)文献[7]より引用
そもそもクラスタリングはリターン予測を目的としない教師なし学習であるため、生成されたクラスタが直接リターンと関連することはないはずである。機械学習によってクラスタリングする目的は、既存のファクターとの交互作用によってその予測性能を向上させることであるが、必ずしもこの効果は得られなくとも良い。後述するようにスペシフィックリターンの情報控除の手段が増えることが重要である。
(4)機械学習によるファクター
機械学習によるファクターはそのアプローチから2つに大別される。
既存のファクターの合成
まず1つ目のアプローチは、既存のファクターから合成・抽出する方法である。この手法のエッジの根拠は、ファクターの持つ非線形性や交互作用だと考えられており、このことは様々な文献で言及される。
このアプローチのうち1つ目の事例では、大量のファクター間の非線形な関係を捉えるため、既存のファクター群に対して深層学習を用いてモデル構築している[8]。深層学習は線形モデルやその他の機械学習手法をアウトパフォームするという結果が得られている。
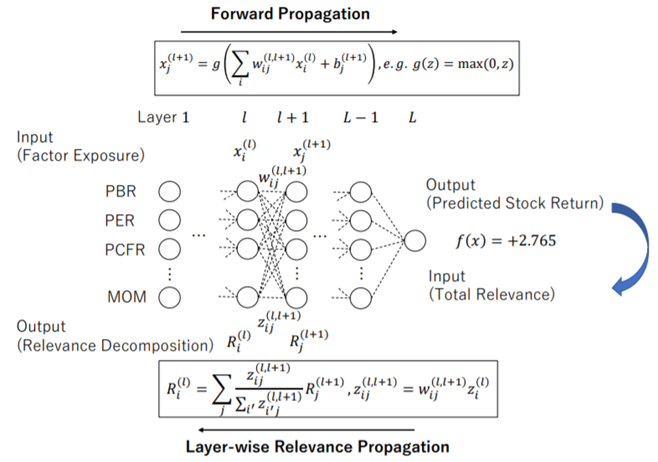
(図:ディープファクターモデル)文献[8]より引用
また2つ目の事例では、従来のクオンツ(ここではBARRAモデル)の残差成分を説明するために、従来のファクターエクスポージャーXに関する非線形関数Gを導入している。この非線形関数Gの出力はMLファクターと呼ばれており、非常に安定した良好なファクターリターンが得られることが確認されている[5]。
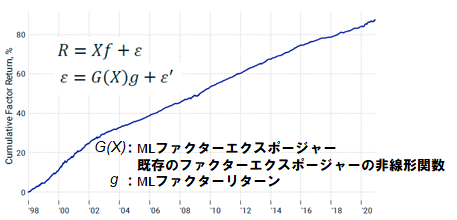
(図:MLファクターのファクターリターン)文献[5]より引用
このような非線形モデルや関数の出力を直接予測としてもよいが、非線形出力は後述するようにスペシフィックリターンの控除手段となるため、全体的なモデルとしては後段に学習器を備えることが推奨される。
オルタナティブデータ
2つ目のアプローチは、機械学習によってこれまで使われることがなかった情報ソースをデータ化することである。このようなデータはオルタナティブデータと呼ばれ、現在は様々なベンダーが多種多様なオルタナティブデータを提供している。オルタナティブデータのエッジの源泉はその収集コストの高さであり、定性的には「カバーしている人が少ない指標ほど効果的」であると言われる。
以下は、様々なオルタナティブデータをそのヒストリカルの入手性とカバーされている銘柄の広さでマッピングした図である[9]。例えばNumeraiでは15年以上にわたり5000を超える銘柄が予測ターゲットとされているが、オルタナティブデータでこれらをカバーするのは現時点では難しい。
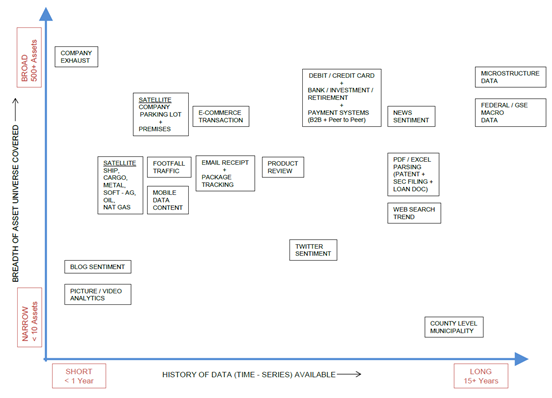
(図:オルタナティブデータのマッピング)文献[9]より引用
そのような制約の中でもしもオルタナティブデータを使うのであれば、テキストデータが考えられる。テキストデータはソースが豊富にあり、また様々なアセットに対して共通に使うことができるからである。もしもオルタナティブデータを使うのであれば、スペシフィックリターンとの関係を観察すべきである。
(5)スペシフィックリターン
最後にスペシフィックリターンであるが、上記までに部分的な機械学習モデルの出力を含めて全ての特徴量が出揃ったら、それら全てを用いてリターンを直交化して独自のスペシフィックリターンを算出する。スペシフィックリターンは強いリバーサルの特性(ファクターリターンが負方向に推移する)を持つ場合が多く、原理的には情報を控除すればするほどその性能が向上する(はずである)。このため、控除対象として機械学習を用いたクラスタや非線形の情報を使うことは、この性能を向上する上で非常に重要である。下図は控除する情報を増やした場合、スペシフィックリターンの持つ予測性能がどのように向上していくか示している。
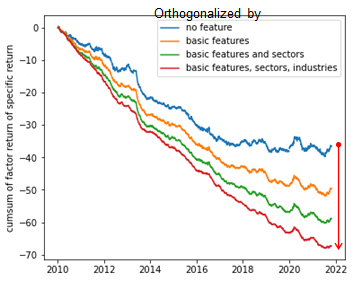
(図:様々な控除条件におけるスペシフィックリターンのリバーサル特性)
従来のクオンツを発展させる機械学習の適用手法
ここまでの内容を纏めると、モデリング図は以下のようになる。
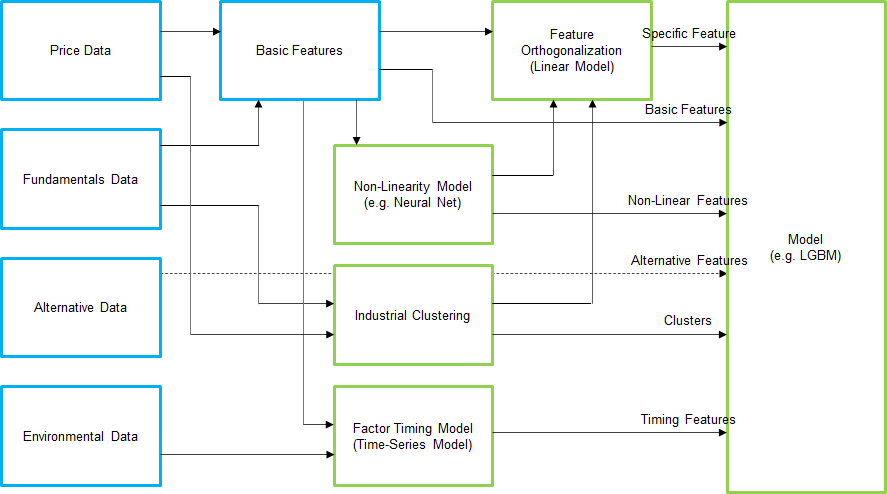
(図:従来のクオンツを発展させる機械学習モデリング)
価格データとファンダメンタルズデータにより作成された特徴量を最終段の学習器に入力するだけではなく、非線形モデル、クラスタリング、タイムシリーズのファクタータイミングモデル等を事前に個別モデル作成する。そして、これらのモデルにより得られた特徴量を使ってスペシフィックリターンを計算し、これも特徴量とする。このようなモデリングで、従来のクオンツでは収益源として考慮されていなかったリターンを獲得することを目指す。これは従来のクオンツを発展させるための機械学習適用のフレームワークの一例となりうる。
おわりに
「機械学習による株価予測」シリーズも本記事を持って終了となる。本記事に限ってはプレゼン内容をベースに文字起こししたため、幾分冗長な記事となってしまったことはご容赦頂きたい。ここまでの内容は、筆者自身が専業の投資家として独自に研究し蓄えてきた知見に準ずる。なぜこのような知見を公開しようと考えるに至ったか、自身の考えを説明して最後の締め括りとしたい。
この記事でこの国の行く末までを語るつもりは毛頭ないが、老後2000万円問題を始めとして資産形成は国民への社会的な要請となっている。体たらくな政権の在り方を正しく批判することも大切であるが、それよりもまず自己防衛を考えることを優先すべきである。
投資は一般の方が資産形成する上で避けては通れないが、一方でそれは非常に険しい道である。インデックス等の積み立てで資産形成できる、FIREもできるという話をよく聞くが、これから先の数十年の世界情勢は全く予想できるはずもなく、相応をリスクを孕んでいることをよく理解しなければならない。むしろしっかりと資産形成するためには、長期的な目線よりもこの先数年の短期間を見据えて適切な戦略を考えなければならないのである。しかし、ここでも巷に全く根拠のない投資手法が氾濫していることは非常に悲しいことである。
正しい投資とはどのようなものか。この命題に対する答えが見つかることはないだろう。
ただし、もしもそのようなものがあるとすれば、少なくともそれはエビデンスに裏付けされたものであることは間違いない。そう、ここに我々はデータサイエンスを活用するしかないのである。そして私は自身の経験からも、株式投資はデータサイエンスできるものだということに全く疑いを持っていない。
当然ここにも参入障壁は存在する。コーディングの技術はもとより、機械学習を学ぶ上での数学的な素養も必要となる。だから私は「誰でも資産形成できる」などと言うつもりはない。投資の持つ不確実性を否定する気もない。しかし、正しく努力し正しくリスクテイクすることで切り拓ける可能性がここにあるということを周知したいのだ。
そのような正しい努力と正しいリスクテイクが報われる世の中であってほしい。
願わくばこの記事が読者の方の資産形成の一助となりますように。
2021年12月24日
UKI
関連記事
- 成功する投資:トレーディングのサイエンス
- J-Quants データ分析コンペティション表彰式(YouTube)
- トレーディングの統計モデリング
- トレーディングのバイアス対策技術の歴史と展望
- AI投資のススメ(Noteマガジン)
- シストレのススメ(Noteマガジン)
- 投資指標の探索要領
- これからのお金の話をしよう(ブログ)
参考文献
[1] Cao, "AI in Finance: Challenges and Opportunities", 2021
[2] Consoli, Recupero, Saisana, "Data Science for Economics and Finance", 2021
[3] プラド, "ファイナンス機械学習", 2019
[4] プラド, "アセットマネージャーのためのファイナンス機械学習", 2020
[5] Bonne, Wang, Zhang, "Machine Learning Factors: Capturing Nonlinearities in Linear Factor Models", 2021
[6] hippoasset, "ファクタータイミング戦略の有用性(リサーチ)", 2019
[7] 松井, 蔦木, 加藤, 後藤, "株価時系列に基づく企業クラスタリング", 2020
[8] Nakagawa, Uchida, "Deep Factor Model: Explaining deep learning decisions for forecasting stock returns with LRP", 2018
[9] Kolanovic, Krishnamachari, "Big Data and AI Strategies: Machine Learning and Alternative Data Approach to Investing", 2017