こんにちは。
お久しぶりです。yuchoです。
最近は、AWSのレガシーなDBからの移行をしていて、認証ゲートウエイを開発していたりしています。
.NET使いとしては、クラウド=Azureのイメージが強いでしょうけど、色々なニュースありきで、AWSも悪くないです。
最近の開発プロセスをまとめたかったので記事にします。
ちょっとした日記です。普段使っている言語がC#でなくても参考になる部分があると思うので、興味があったら盗んでください。
キーワードは「 エラーが起きてもめげない受け入れる受容力 」です。
はじめに
皆さん、AI使ってますか。
使いまくってますよね、きっと。
僕もclaudeをよく使ってます。
本格的なクラスアーキテクチャ設計をするときは、opus 4.1を使うことも多いですけどね。
最近は、sonnet 4.5を使ったハック術を極めています。
安価モデルでありコード生成性能もそこそこコスパよしだが、複雑な問題を解かせるにはちょっと性能が足りてない印象はありますよね。
しかし、彼は私のプロジェクトでAIコーダとして、その安価さとパフォーマンスを発揮し、期待に応えてくれます。
上手く使うと、既存のアーキテクチャの作業、2週間くらいかかっていたのを、1日に、しかも高品質にコードライティングしてくれるようになりますね。
面白い。
そもそもTDD的プロセスとAIと何が関係があるのか
通常、多くのプログラマは実現したいコードを仕様ベースでまとめてプロンプトでAIに指示する方向性をとると思います。
これは理には適っていますが、結局コードの良しあしや挙動、仕様決定の判断が、客観的でなく、人間に委ねられることが個人的に気になります。
私は、これとても問題だと思います。
???言うて、人間の判断って、主観的じゃないですか???
これを気持ち悪くないって思う人は多いですが、私は大問題だと思います。
そうなのです、私は過去こんな記事を書いています。
テスト駆動開発は、「テストを先に書くことで」プロセスを数量的に評価できます。
しかし、そこで私はTDDはとにかく設計工数がかかることという問題を言っていました。
この設計工数は、AIによって大幅に削減し、TDD的思考を人間が持ち、AIがコードドライバになる解決策を生み出すことができます。
そんな実現方法を、紹介しましょう。
想定している環境
- 開発環境: Visual Studio 2022
- コード解析をやってもらうため、開発者ツールを使ってclaude codeを連携させます。
- claude codeの導入方法は公式URL参照
- ランタイム:.NET 8.0
- 今年末に.NET 10.0になり、AWS Lambdaは来年.NET 8をサポートしなくなるので、この対応が出来るかも注目ポイント。これは来年検討する。
C#の静的型付けと名前空間の分離
C#の最大の特徴の一つ。
パッケージは名前空間で分離が可能なことです。
会社のソースコードを開示するわけにはいかないのでコードスニペットで今回は表現したいですが、
例えば、こんな形で、名前空間を丁寧に分離すると、AIは認識してくれやすいです。
実際はこんな感じで複雑なデータアーキテクチャになっています。
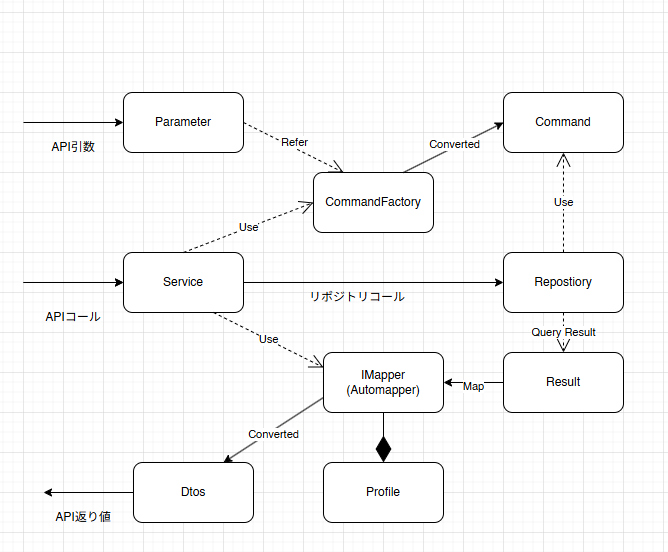
architecute.mdを作る
ここからが本題です。

こういった複雑な構成においても、まずはarchitecture.md、archiecture_rules.yamlを読ませることを先行して作業します。
このarchitecture.mdにはこんな内容が書いてます
# Architecture Rules for C# (Authv3MysqlTransaction)
## 1. Runtime Architecture
### 1.1 Overview
- **Managed by:** `Authv3MysqlTransaction` project
- **Purpose:** Provides RDBMS implementation with a structured Service–Repository–Command–ORM architecture.
- **Top Interface:** `IService` (implemented by each domain-specific service, e.g., `UserService`)
---
### 1.2 Layer Composition
```text
Service → CommandFactory → Command → Repository → OrmEntity
↘︎ Dto
↘︎ State
| Layer | Description | Depends on |
| ------------------ | --------------------------------------------- | ----------------------------------------------- |
| **Service** | Transactional logic orchestrator. | IRdbmsScope, IEntityRepositoryRegistry, IMapper |
| **CommandFactory** | Validates Parameters and constructs Commands. | Parameter |
| **Command** | Encapsulates single-use-case logic. | Repository |
| **Repository** | Abstracts CRUD operations. | OrmEntity |
| **OrmEntity** | Data persistence representation. | DB Driver / ORM |
---
....
複雑な内容に見えますが、要はどのような実装が行なわれているかの設計書を書いておくのです。
最初の内は日本語でも良いでしょうし、ある程度練度が出ていればこれ自体をAIで作るのも良いでしょう。このドキュメントを生成するのはGeminiの方が得意な気がする。
細かい点:Automapper
今回はRDBMSの結果をDtoに変換するときに、利用しています。
細かい点:DI注入
DI注入については技術ブログに詳しい記事が大量にあるので、ここではあまり紹介しませんが、利用するServiceやProfileやCommandFactoryを以下のように事前登録しておき、そのサービスのデータ構造を外から定義できるようにする仕組みです。
そうすると例えば、ユニットテストの場合と、開発版と、プロダクトコードで実装を切り替えて使えるサービスを切り替えるみたいな実装が出来たり、サーバレスFunction系の実装におけるコールドスタートにおいてプログラム領域の圧縮をしたりと言った運用が可能になります。
public static class DiProvider
{
private static Abstractions.Services.IServiceProvider? _provider;
private static void AddAutoMapper(ServerlessServiceDescriptorCollection provider)
{
/** AutoMapperの一覧登録をする **/
var mc = new MapperConfiguration(config =>
{
config.AddProfile(new AutomapperUserProfile());
config.AddProfile(new AutomapperErrorProfile());
...
});
provider.AddSingleton(mc.CreateMapper());
}
public static Abstractions.Services.IServiceProvider GenerateDi(
ITestOutputHelper output,
IRdbmsScope setupAdapter)
{
/*** サービス層やCommandFactotryの一覧を与える **/
var integrators = new DiIntegrator[]
{
new DiMetadataIntegrator(),
new DiUserIntegrator(),
...
};
_provider = new SimpleServiceProvider(provider =>
{
/** IOutputHelper(ロガー)の設定をする **/
provider.AddSingleton(output);
/** Rdbmsの設定をする **/
provider.AddSingleton<IRdbmsScope>(p =>
{
return setupAdapter;
});
/** Automapperの設定をする **/
AddAutoMapper(provider);
/** 定義されたサービスやCommandfactoryを登録する **/
foreach(var integrator in integrators)
{
integrator.IntegrateDiService(provider);
}
/** Rdmbsのパラメータの与え方を登録する **/
provider.AddScoped(p =>
{
var registry = new RdbmsEntityRepositoryRegistry();
foreach (var integrator in integrators)
{
integrator.IntegrateDiRegistry(registry);
}
return registry;
});
});
return _provider;
}
}
こういう風に書くことで、providerという一つのクラスに必要なリソースをすべて集約が可能になります。
これ自体がAIの提案なのですが、ASP.NET以外でも、このようなメソッドをAIで事前生成することで、providerを柔軟に設定が出来るようになります。
対話式でAIに働いてもらう
そしてここまでいくと、AIが自然と働いてもらえる環境が出来ます。
claude codeは自動でbashを実行してくれる関係で、

こんな感じで指示をしてくれると、Visual StudioにXUnitのテストルールを自動生成してくれます。
この起点が大事で、サービス層やリポジトリ層のような実実装コードではなく、テストコードから生成して、という風に指示を出します。ここでも、
TestにSqsEnqueueをTest内部の他のフォルダ同様に作成します
と書いてある時点で、AIはあくまでテスト環境のセットアップを担当します。
あとはアーキテクチャ通りに人間が修正を加えていき、次のステップに行きます。
人間が加える工程、結構大事。 誰でも使えるようにするための次のアプローチの範囲をちゃんとカバーすることがポイントです.
テストシナリオの作成
現在のコードスニペットはこんな感じだった。
こちらはFargate Workerを自動で実行するためのサービスのテストコード。
[Theory]
[ClassData(typeof(PositiveTest.ProcessScenarios))]
[ClassData(typeof(PositiveTest.FinalizeScenarios))]
public async Task Test_FargateWorkerService_PositiveTest(TestScenarioDefinition scenario)
{
// Arrange & Act
using var tester = await GenerateServiceTesterAsQueueDi<FargateWorkerServiceTester>();
// Assert
await ExecuteScenario(tester, scenario);
}
Theoryを使ってテスト用のパラメータに変換します。
そのときに、テストシナリオはBuilderパターンで構築し、DIとの連携をします。
例えば、
public class ProcessScenarios : FargateWorkerTestScenariosBase, IEnumerable<object[]>
{
private readonly List<TestScenarioDefinition> _scenarios = new();
public ProcessScenarios()
{
// Standard message processing scenario (StartWorker phase only)
_scenarios.Add(
new FargateWorkerScenarioBuilder(this)
.WithDependency(TestScenarioDefinition.DependencyType.MinimumSetup)
.WithDescription("Standard message processing with StepChain execution (StartWorker phase)")
.WithStandardProcessingAssertions()
.WithStepChainExecutionAssertions()
.Build());
// Message processing with S3 payload retrieval (StartWorker phase only)
_scenarios.Add(
new FargateWorkerScenarioBuilder(this)
.WithDependency(TestScenarioDefinition.DependencyType.MinimumSetup)
.WithDescription("Process message with S3 payload retrieval (StartWorker phase)")
.WithStandardProcessingAssertions()
.WithStepChainExecutionAssertions()
.WithS3PayloadRetrievalAssertions()
.Build());
...
}
public IEnumerator<object[]> GetEnumerator()
{
return GetScenarios().GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
として、GetEnumeratorを明示的に書くことで、ProcessScenariosはXUnitと同等に扱えるObject型として展開できるので、Builderパターンを使ってテストを設計出来ます。
こうした一元管理されたテスト環境を使うと、テスト履歴ごとシリアライズして管理できるので、テスト環境の管理に有意義です。
またこういう風にすると、AIが書いたコードを客観的指標で評価するプロセスが作れます。
例えば、AIが何となく書いてくれたコードだとしても、Builderの中身を見て、「このコードは直感的に仕様がおかしいのではないか」と感じたら、その部分をインタラクティブに指摘しながらコードレビューをしたり出来ますね。
TDDによるIDE補完
通常設計していると、パラメータ抜けをどう考えるかという問題が発生しますが、TDD + C#では型定義を厳密に定義してくれます。
したがって、パラメータ抜けは常時ビルドにおいてエラーとなり検出してくれます。
この当たり前のことを、TDDでは当たり前のエラーを常に記述することで
コード不整合を検出するアプローチでコードリファクタリングを一瞬で実施することが出来ます。
TDDでポイントは エラーを意図的に起こすコードを受け入れる ことです.
.NETは厳密性が高いことから、ちょっと間違えると必ずIntellisenseが型定義をチェックしてくれて、同時に検出できます。
設計哲学として受け入れることが大事です。
テストが先に実装された場合、通常サービス層やパラメータなどの本当のプロダクトコードは実装されないまま、ビルドエラーになるという感じになります。
この空気感が超大事です!!! エラーが起きているから問題なんだじゃなく
あーエラー起きてるなあ。当たり前だなって言う感じになってから、修正する作業に取り掛かるのがポイントです。マインドの変化が重要。
エラーを自分から起こすマインド! これが大事!
なお、AIはこのIDEによるエラー検出があまり得意ではない傾向があります。
IDEの機能を使う場合は、AIによる自動コード変更を止める工夫は必要です。