これは何か
Kyash Advent Calendar 2020 の16日目の記事です。
Kyashには2019/5/20にサーバサイドエンジニアとして入社し、約1年半ほど在籍しています。
入社してしばらくは全てのマイクロサービスを担当し、保守と開発をしてましたが、組織が急成長しバックエンドエンジニアも数倍以上に増えたことで組織編成され、ここ半年ほどはFundsチームというチームに所属しています。
Fundsチームは外部と連携してお金が移動する処理を行うマイクロサービスを担当してます。
クレカでチャージする部分や銀行と連携して口座登録、入金、出金する部分や、面白い部分だとATMと連携する部分も担当していたりします。
Kyashではマイクロサービスを採用していることもあり、障害やレスポンス悪化による影響を最小限にするよう普段から考慮する必要があることが多いですが、特に外部サービスと連携する部分に関してはより一層注意をする必要があります。
今回はその取り組みの一つとして、Datadog Monitorsを利用した汎用的なCircuit Breakerを作ってみた話を書きたいと思います。
マイクロサービスでシステム障害を受け入れる
Circuit Breakerについて書くまえに、そもそもの目的や他の選択肢がないかを整理しましょう。
マイクロサービスアーキテクチャという本の11章を参考にしながら簡単に紹介します。
(雑談ですがチーム発足時から輪読会を開催し、この本を最初に選びました。いい本です)。
サービスが複雑化している現代では障害を防ぐのではなく、障害が発生する前提でどのように復旧するかを考えるのが主流になりつつあります。
特にマイクロサービスでは正常なサービスもあるし、そうでないサービスもあるという状況が想定される中で、安全に機能低下し、復旧につれて安全に回復していくシステムが求められます。
本で紹介されたわかりやすい例を紹介します。ECサイトをマイクロサービスで運営しているとして、在庫、商品一覧、カート機能などのサービスがあるとします。この時カート機能のサービスだけが障害で落ちていた場合にWebページが全く表示されないのは好ましくなく、たとえばカート表示部分に「すぐに復旧します」といったアイコンや注文用の電話番号を表示することが好ましいはずです。
では、どのようにして障害のサービス全体への影響を最小限にすればよいでしょうか。
まず一番に対応すべきはタイムアウトの設定です。
タイムアウトが長すぎるとシステム全体の遅延を引き起こしますが、短すぎると正しく機能していたものを失敗とみなしてしまいます。
どのくらい待てば実質的にダウンしているとみなせるかを状況ごとに考える必要があります。
Kyashでいうと、決済の電文に対して承認 or 拒否を返却する処理の中で発生する他のマイクロサービスへのリクエスト時にタイムアウト10秒を指定するのは明らかに長すぎます。
必ずタイムアウトは設定するようにしており、外部ベンダーと連携する際には推薦するタイムアウト値を最初に質問するようにしています。
ただ、連携先の中には様々な事情によりタイムアウトが1分以上といった大きな値にしなければならないところもあり、その場合はタイムアウト以外の方法で影響を小さくする工夫をする必要があります。
隔壁も検討すべきです。あまり聞き慣れない言葉ですが、
「被害が最小限になるようにサービス間に壁を設けるような仕組みや設定等」
をさします。
本では、例として、呼び出すサービスごとにクライアントの接続プールを分離することが推奨されてました。
httpの接続プールにおいて考慮した場合、例えばGoなら、MaxConnsPerHostにてホストごとのクライアントの接続上限を指定でき、デフォルトは0で無制限となっています。
このあたりの挙動はあまり自信がなく、ソースを読みながら別記事で実際に検証してみたいと思います。
http以外では、例えばSQS等キュー基盤を利用した非同期通信において、キューを適度に分けて影響を限定化するのも効果がありそうです。所属するFundsチームでは設計方針を考える際、実際にこの観点も含めてキューを分けるべきかチームで議論することがあります。
最後にこの記事のテーマでもあるCircuit Breakerです。
自宅で誰もが経験したことある電流が急上昇するのを防ぐためにブレーカーが落ち、電化製品を守ってくれる仕組みと同じです。
具体的には以下のフローです。
- 他サービスへの呼び出しが失敗し始める(タイムアウトも含む)
- 閾値に達し、Circuit Breakerが落ちる。呼び出しを行わず、すぐに失敗として処理する
- 健全性チェックを定期的に行う
- 健全性閾値に達するとCircuit Breakerをリセットし再開
今回自分が作ったのは1~4のフローを容易にできる仕組みです。
なお、実際に運用するにあたって3と4を自動でうまく行うのはかなり難しいと思っています。
ケースによってはもちろんうまく全自動で1~4を行うことも可能かと思いますが、むしろ少数派で、少なくとも慣れるまでは1,2を自動で行い、2のタイミングで高緊急度のAlertとしてslack通知してエンジニアが状況調査後手動復旧くらいが良いと思っています。
前提となるアーキテクチャ
実はKyashではCircuit Breakerの仕組みを一部ではすでに利用していました。
cronで数分ごとにjobを起動し、そのjobではNew Relic(Datadogと同様の監視ツール)の特定のメトリクス(レスポンスタイムの90パーセンタイルといったメトリクス)を参照し、閾値をもとにCircuit Breakerを発動するべきか判断し、フラグをRedisに保存。呼び出し側サービスではRedisを参照し、リクエストすべきか判断といったものです。
これを以下の図のように変更しました。(厳密にいうとこの変更案はすでに前任者が描いており、それに乗っかった感じです)
なぜDatadogを利用するかについては、Kyashではすでに一年以上利用している実績があり、監視、トレーシング、ログ検索ほぼ全てDatadogに集約しつつあり、流れにあわせただけです。
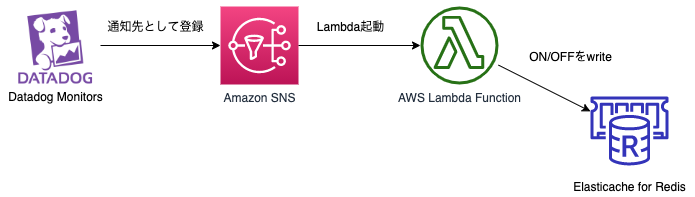
なので、今回紹介する汎用的なCircuit Breakerも
Datadog Monitors -> SNS -> Lambda
という流れであることを前提としますが、異なるアーキテクチャでもエッセンスは参考になると思います。
Datadog Monitorを利用した汎用的なCircuit Breaker
既存の移行
既存のCircuit Breakerの上記へのアーキテクチャへの移行についてはさほど大変なものではありませんでした。
DatadogのDocumentをみればわかるように、{{#is_alert}}ほげほげ{{/is_alert}}といった形で条件付きで通知本文を記載することができます。
また、DatadogをAWSとintegrationしているので、通知先に@sns-dd-circuit-breakerと指定すれば自然とSNSに通知されます。
以下は通知設定例です。SNSとSlackチャンネルに通知されます。SNSから呼ばれるLambdaではstatusを見てなんの通知か判断できます。
{{#is_alert}}
status = is_alert
{{/is_alert}}
{{#is_alert_recovery}}
status = is_alert_recovery
{{/is_alert_recovery}}
{{#is_warning}}
status = is_warning
{{/is_warning}}
@slack-tech-channel @sns-dd-circuit-breaker
問題点、解決したいこと
既存Circuit Breakerのアーキテクチャ変更を行う際に新規のCircuit Breakerも追加する想定だったのですが、ここで困ったことに。
新規のCircuit Breakerを作る時に
- Datadog Monitors設定
- SNS
- Lambda
のセットが新規に必要になります。これは都度作成するのは明らかに大変そうです。
では、SNS、Lambdaを共通化して利用して複数のCircuit Breakerで共有したらどうなるでしょう。
以下の問題が発生します。
- 新規のCircuit BreakerのためにLambdaにIAMを追加で付与する可能性が高い(例えばRDSを参照して判断する必要が生じるなど)
- ^の結果、Lambdaが様々なアクセス権限をもつことになり、好ましくない
- 様々なサービスのドメイン知識がLambdaに入り乱れる(そもそもドメイン知識がLambdaに漏れ出るのさえも避けたかったはず)
どちらの場合も辛そうですね。。
行き着いた仕組み
そこで自分が考えたアプローチはLambdaはMonitor通知のハブとなるだけで実際の処理は各マイクロサービスが行うというものです。
既にあるCircuit Breaker処理ではLambdaがRedisにアクセスしてましたがそれも不要です。
ただ、ここでもうひと工夫必要です。簡単に思いつくのはMonitor設定にLambdaが叩くエンドポイントを{{#is_alert}}circuit-breaker-callback: https://serciceA/dd_circuit_breaker/callback {{/is_alert}}のように設定し、Lambdaは特にパラメータを指定せずに単純にPOSTするという案です。
だが、この場合、汎用性がなく、すぐに使いものにならなくなります。例えば、Fundsチームでは連携する銀行単位での障害やレスポンス遅延に気づけるように以下のようなMonitor設定を行っておりますが、これをもとにCircuit Breakerを行いたいとなったときに「今発火しているイベントの対象はどの銀行か」を実際にハンドリング処理を行うサービスにパラメータとして渡す必要があります。
logs("~").rollup("count").by("@bank_code").last("15m") > 5
ただ、SNSメッセージをパースしてどの銀行かを判断する処理をLambdaに書いてしまうと汎用的に書くという夢が崩れ落ちます。。
ここでの解決策はDatadogが提供するREST APIを利用して各サービスがハンドリング処理に必要な情報(例でいうと銀行コード)を取得するというものです。イベント情報の取得にはeventID(イベント詳細画面URLのhttps://app.datadoghq.com/event/event?id=xxxxxxxxxxx のidと同じ)のみ必要なため、LambdaはSNSメッセージをパースしてeventIDを判断し、パラメータとして渡してあげるという流れになります。
なお、REST APIを利用するには、API Keyを発行する必要があるため、いままでtracing/monitor等の用途でしかDatadogを利用しておらず、REST APIを初めて使う場合は注意しましょう。Kyashでも初めての利用となるため発行してもらいました。
前置きが長くなりましたが、最終的なアーキテクチャは以下です。
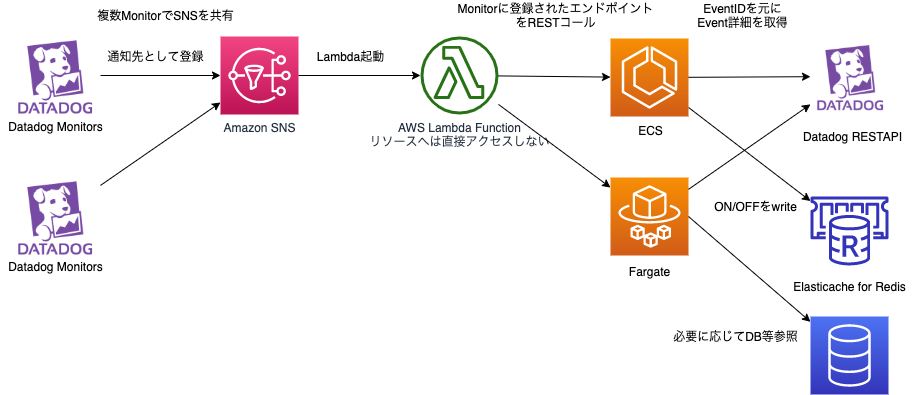
具体的にそれぞれ何をするのか細かくみていきましょう。
Datadog Monitors設定
ハンドリングを行うマイクロサービスのエンドポイントを設定します。
{{#is_alert}}といった条件は不要かもしれませんが、例えばwarningからのrecoveryはそもそも通知しないというケースにも対応できますし、設定しておいたほうが無難かもしれません。
{{#is_alert}}
circuit-breaker-callback: https://serciceA/dd_circuit_breaker/callback
{{/is_alert}}
{{#is_alert_recovery}}
circuit-breaker-callback: https://serciceA/dd_circuit_breaker/callback
{{/is_alert_recovery}}
{{#is_warning}}
circuit-breaker-callback: https://serciceA/dd_circuit_breaker/callback
{{/is_warning}}
@slack-tech-channel @sns-dd-circuit-breaker
SNS
SNSは特に何もおこないません。間にかませるだけです。
Lambda
LambdaはSNSのメッセージをパースします。circuit-breaker-callback: ~をみつけると、存在する場合はそのendpointを叩き、存在しなければ何も行わずに処理終了します。
endpointを叩く場合は、SNSのメッセージにDatadogが自動で含めるEventモニターURLからeventIDを取得し、それをPOSTするリクエストに含めます。
レスポンスの判定はできるだけ単純にするためにhttpステータスコードが200なら成功とみなし、それ以外ならエラーと判断します。
では、Lambda関数でエラー発生し、処理が失敗した時どうすべきでしょう。slack通知するロジックをLambda関数に書いたほうがいいでしょうか。
Lambda関数でのエラーハンドリングや再送は全てLambdaの仕組みに任せてしまった方が楽です。
このあたり詳しくなかったのですが、Lambdaのイベントの種類は大きく「同期型」、「非同期型」、「ストリーム型」に分けられ、タイプによって再送やエラーの扱いが異なります。
SNSの場合は、非同期タイプとなり、以下の特徴があります。詳細はAWSのドキュメントを確認ください。
- 再送回数は2回(デフォルト)で0~2まで設定可能
- 初回リクエスト~再送1回目まで間隔は1分、再送1回目~再送1回目の間隔は2分で変更不可
- デットレターキューを設定することで、再送上限にて失敗した時にenqueueされる
- 再送間隔はexponential backoffで行われ、最大6時間試行される
最後のみ補足すると、再送は最大で3分ほどで終わるのでは?と思ってしまいそうですが、Lambdaには同時実行数の制限があり、デフォルトだと同一アカウント同一リュージョン1000であり、このlimitに引っ掛かり、再送が延期された場合を想定しているようです。
上記のような特徴を利用することによって、エラーやタイムアウト(タイムアウトはデフォルト3秒で最大15分まで設定可能ですが15秒に設定しました)時の再送処理はLambdaの仕組みに任せてしまい、Lambda関数ではエラーをただ何も考えずにreturnするだけですみます。
再送2回行っても失敗した場合はデットレターキューに入るので、デットレターキューをDatadog Monitorsで監視してSlack通知するようにしていれば問題ないです。Kyashではもともと基本的にデットレターキューはDatadog MonitorsでSlack通知する運用でしたのでその点でも問題ないです。
結果的にはLambda関数の処理は、「SNSメッセージをパースして、callbackのURLやeventIDを取得しRESTコールし、200以外だった場合やどこかでエラーが起きた場合はエラーをreturnする」という処理だけ行えばよく、150行ほどのだいぶスッキリした処理となりました。
マイクロサービスRESTエンドポイント
eventIDを元にDatadogのAPIを叩き、ハンドリングに必要な情報を取得します。Datadog側でGoのクライアントライブラリを用意してあるのでかなり完結に記載することができ、実際20~30行ほどのコード量ですむと思います。
自分が目視で確認する限りは、DatadogのEvent詳細画面で確認できる情報の全てをAPIで取得可能なため、情報が足りないということはないかと思います。
誤ってAPIが叩かれるのは怖いので、「イベント発生時刻(APIにて取得可能)が〜分以内のもののみ処理する」「メッセージにTestという文字が含まれていたら無視する」などの制御を行いました。
一点、注意点があるとすれば、イベントが発生した直後にそのeventIDをもとにRESTAPIを叩いた場合NotFoundがレスポンスされる場合があります。
経験則では2分ほど経過時でもNotFoundがレスポンスされる場合がありました。これはおそらくDatadogの内部実装で結果整合性を採用しているためかと思います(Datadogが扱うデータ量を考えるとしょうがないかなと思います)。
この場合も、再送処理は既に書いたようにLambdaが面倒みてくれますので、何も考えずにエラーを返してしまって問題ありません。
最後に、再送されることが前提なので、エンドポイントは冪等性を担保しておきましょう。
振り返る
この仕組みを利用してCircuit Breakerを追加したい人は結局どのような作業が発生するのでしょう。追加作業は楽になったのでしょうか。
まずは、Circuit BreakerをON/OFFを判断するマイクロサービスにて、eventIDをリクエストパラメータとして受け取り、DatadogのREST APIをたたいて詳細情報を取得して、ON/OFF判定するエンドポイントを実装します。
その後、Datadog Monitors設定を作成し、「circuit-breaker-callback:」に続くかたちで作成したエンドポイントを記載します。
最後に、LambdaからマイクロサービスへHTTP/HTTPSでのネットワーク到達可能かを確認し、場合によってはセキュリティグループ設定などを追加します。
一番最初のDatadogのREST APIを叩くところだけ少し面倒そうと思われそうですが、既に書いた様にGoのクライアントライブラリが既に用意されており、かなり簡単に記述することが可能です。
インフラ面での変更は全くといっていいほど不要なので必要な作業がサーバサイドエンジニア内で完結しています。
また、マイクロサービス側にコード記述を行うので、複雑な判定処理を行う場合も既にあるコード資源(レポジトリやドメイン実装など)を利用でき、ドメイン知識の流出を防ぐこともできます。
おわりに
汎用的なCircuit Breakerの仕組みは以前から作りたいなーと思ってました。
Fundsチームだけでなく、他のチームでも使われると嬉しいなと密かに思ってます。
よくよく考えると、「Datadog Monitorsのイベントを各マイクロサービスでハンドリングする仕組み」なので、Circuit Breaker以外の用途でも使えるはずです。
去年のアドベントカレンダーネタもそうでしたが、Kyashでは日頃の開発ではできないことを行うクォーター中に1週間の期間があり、その期間を利用してうまく実現することができました。
やっぱりマイクロサービスって難しいなとつくづく思います。
お金を扱うこともあり、よりシビアな運用が求められることも多いですが、だからこそ楽しそう、興味あると思った方、こちらからエントリーいただければ幸いです。