これは何か
Kyash Advent Calender 2019 の20日目の記事です。
Kyashには2019/5/20にサーバサイドエンジニアとして入社し、本日12/20でちょうど7か月となります。
普段はWalletチーム(Kyashアプリを開発しているチーム)のサーバサイドを担当しています。
すでに導入してあるDatadogとNewRelicをDatadog一本にすることになり、その際の移行のついでにちゃんとやれてない部分や新しいマイクロサービスへの導入を行った時に想定外に大ハマりしたのでその共有を3つに絞ってしたいと思います。
テーマからして万人ウケするタイプではないですが、世の中にDatadog関連の情報が少ないこともあり、これから導入しようとしている人に参考になればと思います。
そもそもDatadogとはを簡単に
Datadogとは何?
というのを簡単に説明しとこうと思います。
一言で表現するのは難しいのですが、「サーバ、アプリケーション等システム全体の状態をモニタリングするプラットフォーム」と言えると思います。
- サービスをまたがってアプリケーションのパフォーマンスを分析するAPM(トレース)
- サーバーから送られてくるCPU使用率などのほか、ユーザが自由に送ることもできるMetrics
- それらのDashboard
- メトリクスなどからメール、SNSなどに通知するMonitor
- ログを収集するLog Collector
等があり、かつそれらがお互いに協調してます。例えばAPMを使うと自動的にそのspanに応じたメトリクスが作成され、そのメトリクスをダッシュボードにして視覚化しつつ、メトリクスの値を元に閾値をMonitorに登録しSNSに通知できるようにするといった具合です。さらに、ちょっとした工夫(traceID等を出力する)をするだけでAPMの画面上でtraceに紐づくログが確認できたりもします。
特に、Kyashでは10以上のマイクロサービスが動いており、高負荷時の調査などの場合にどのマイクロサービスのどの処理が遅延していて、そのときのホストの状態はどうだったのかがAPMで見ると大変わかりやすく視覚化でき、感動しました。やっぱりグラフが綺麗ですよね!
参考までに以下は実際のAPMのトレースの一つをスクリーンショットです。
それぞれの区間(spanという)は親子関係を持つことができ、なおかつサービスをまたがって保持することができます。
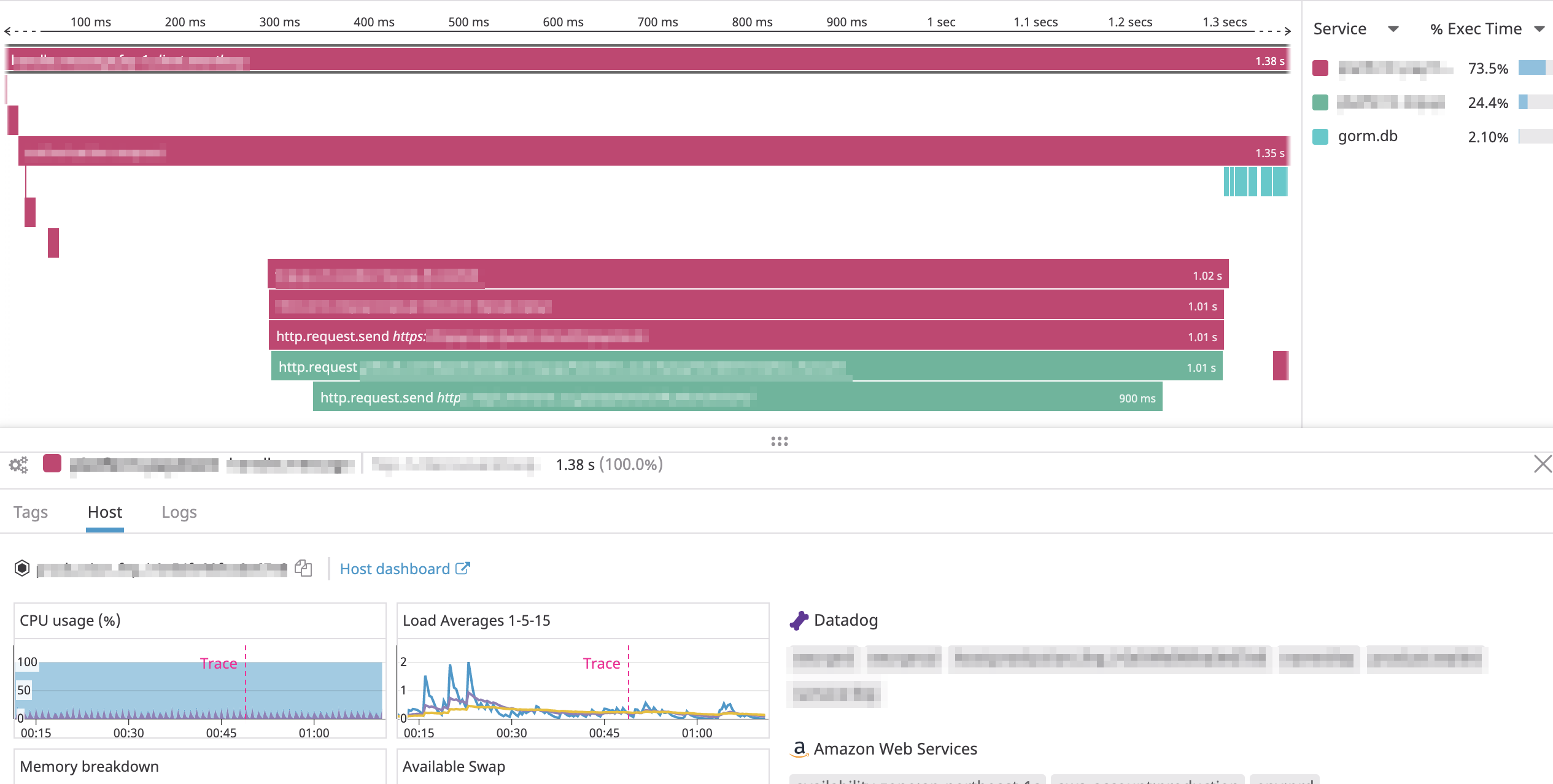
ではハマったことを次章から紹介していきます
Traceできなくてハマった
元々検証できる環境がなかったため、ローカルのdocker環境で検証できる様にしたのですが、全くtraceが表示されず、これだけで半日つぶしました。
原因はわかってしまえば単純なのですが、APMではデフォルトだとサンプリングされ、全てtraceされるわけではなかったのでした。本番環境等ではリクエストが多いので気づきませんでしたが、検証するときには必ずtraceできるようにして欲しいですよね。
サンプリングの挙動はこちらのドキュメントにもちゃんと説明されてますが、目立たないところにあり気づかなかった方もいるのでは。
簡単にまとめると
- リクエスト数、エラー数、レイテンシなどの統計値はサンプリングに関係なく、保持される
-
client->trace agent->Datadog server-> と3箇所でサンプリングされる - デフォルトだとサンプリングされるが、100%保持 or 削除するように設定可能
- サンプリングされたものは6時間は閲覧可能だが、次の日には25%、1週間後には10%しか残らない
のようです。
今回は、ローカル環境でのみspan.SetTag(ext.ManualKeep, true)により必ずtraceするようにすることで解決しました。
また、確証はないですが、自分の観測範囲では以下でした。
- デフォルトのサンプリングでは1割ほどしかtraceされない
-
span.SetTag(ext.ManualKeep, true)によりspanの子孫のコントロールはできるが、先祖についてはコントロールできない
リクエストにクエリがひもづかなくてハマった
元々クエリ単体のtraceはできていたのですが、それにリクエストが紐づいておらず、一連の処理の中でどのSQLにどのくらい時間がかかっているかわからない状態でした。
Walletチーム(Kyashアプリを開発しているチーム)ではORMライブラリにGORMを利用しているのですが、GORMのtraceのドキュメントにある例を参考にしてもよくわかりません。
困っていて調べていたところ、現在は他社で活躍している入社時のメンターの記事をたまたま発見し、こちらを参考に以下のように解決することができました。記事ではリクエストにクエリが紐づき、それとは別にクエリのみが紐づく問題の対処方法でしたが、そもそもクエリをリクエストに紐づける場合にはgormtrace.WithContextを呼ぶ必要があります。
GORM以外のライブラリもだいたい同じようなライブラリを呼ぶことになると思います。
// 一度だけ呼びます
func newConnection() (db *gorm.DB) {
// WithCallbacks registers callbacks to the gorm.DB for tracing.
// It should be called once, after opening the db.
// The callbacks are triggered by Create, Update, Delete,
// Query and RowQuery operations.
db, _ := gorm.Open("postgres", connStr)
db = gormtrace.WithCallbacks(db)
return db
}
// リクエストのコンテキストを引数に渡し、dbと紐付けます
func DBWithContext(ctx context.Context) *gorm.DB {
db := database.Connection()
// WithContext attaches the specified context to the given db. The context will
// be used as a basis for creating new spans. An example use case is providing
// a context which contains a span to be used as a parent.
return gormtrace.WithContext(ctx, db)
}
メモリリークしまくってハマった
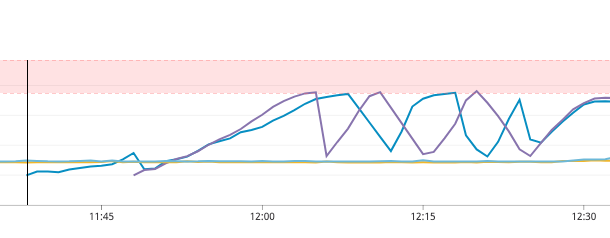
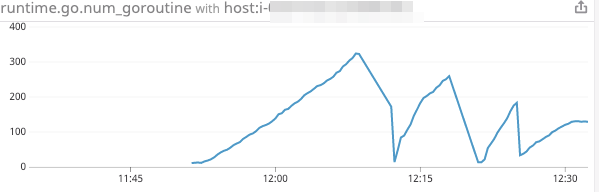
二つグラフをあげますが、なんのグラフでしょうか。
ローカルで動作確認できたし、次はstaging環境で確認するだけだ!
とおもったら最後にまたハマりました。
一つめはメモリ使用量のグラフです。(ホスト二つを別に表示してます) 笑ってしまうくらい綺麗に増加してますね。。
あるタイミングで急激に減ってるのはOOM Killerが走っているためです。
二つ目のグラフはGoルーチンの数のグラフです。今回ランタイムメトリクスを有効にしたのでせっかくだし載せてみました。
この二つから明らかにGoルーチンが回収されずにメモリがリークしているのがわかります。
複数のライブラリのバージョンを最新にしたり、色々な設定変更を行ったりを同時にしているため、何が原因なのかすぐにはわからず、しばらく単調増加/減少しているグラフを見ると拒否感を覚える日々が続きました。
が、様々な状況証拠からメトリクスを送ることができるライブラリ
https://github.com/DataDog/datadog-go
が怪しそうだと思ったので、ソースをじっくり読むことにしましたが、2000行もないくらいの量でしたので数時間でリークしている箇所を発見しました。
よし、PR送るぞ! と意気込んだ矢先、三日前に他の人がPRを送っており、先にソース読む前にPRを確認しろよと若干自分に苛立ちましたが、ライブラリの設計は参考になりそうなところも多く勉強になったのでいいことにします。
また、ソースを読んでみて気づいたのですが、アーキテクチャからしてリクエストのたびにopenするような設計ではなく、openしてからcloseされるまで最低4MBのメモリと3つのGoルーチンが消費されることに気づきました。
なので、この機会にアプリ起動時のみopenするようにしました。
ちなみにそれであれば今回のバグは踏まないはずです。
自分が確認する限りはアーキテクチャが一新され、パフォーマンスが劇的によくなった
https://github.com/DataDog/datadog-go/pull/91
の変更で混入したバグだったのでバグが発見され修正されるまで1か月半ほどかかったことになります。
スター数180なのでそこまでメジャーとは言えないライブラリなのでそういう場合は最新ではなくちょっと古いバージョンを選んだほうがいいのかなとか思ったりしましたが、難しいですね。。最新のbugfixを入れ込みたいですし。
最後に参考までに、どのようなバグだったのか極限まで簡潔にしたものを以下に載せておきます。
極限まで簡潔に書くとこんな感じのソース
type Client struct {
stop chan struct{} // 処理不要であることを通知するためのチャネル
}
func (c *Client) watch() {
ticker := time.NewTicker(c.flushTime)
for {
select {
case <-ticker.C:
// dosomething(4MB以上のメモリを辿れる)
case <-c.stop:
ticker.Stop()
return
}
}
}
func (c *Client) watch2() {
ticker := time.NewTicker(c.flushTime)
for {
select {
case <-ticker.C:
// dosomething(4MB以上のメモリを辿れる)
case <-c.stop:
ticker.Stop()
return
}
}
}
//アプリケーションからcloseされるときに呼ばれる
func (c *Client) Close() error {
select {
case c.stop <- struct{}{}:
default:
}
}
c:=client {}
c.stop=make(chan struct{}, 1)
go c.watch()
go c.watch2()
アプリケーションがcloseしても、goルーチンが一つ生き残ったままなので、確保したメモリがgcされておりません。
この簡単なケースでは、case c.stop <- struct{}{}:のところをclose(c.stop)にすればいいはずです。
最後に
今回datadogをいい感じにしようとしたところ、知識ゼロの状態から取り組んだため、想定外に時間がかかってしまいましたが、Kyash Advent Calender 2019 4日目の記事にある「日頃の開発ではできないことを行うクォーター中に1週間の期間」でこの課題に取り組むことができたため、腰をすえて取り組むことができました。通常のプロジェクトと並行してでは難しかったでしょう。
なお、プロジェクトでは、先日発表された新しいカードに初期から関わっており、このあたりの話を来年春あたりにKyash Meetupなどで話せたらなと思っているので興味ある人は是非!!