本記事の目的
機械学習の推論web APIの典型的な構成を紹介します。必ずしもWEBの知識や機械学習の知識はなくても読める内容だと思います。(実装例は除く)
紹介する構成は、業務でいくつかの機械学習モデルの推論web APIをたてた経験からきていますが、あくまでも個人的見解なので、こっちのほうがいいよーってのがあればコメントで教えていただけると幸いです。
実装例ではweb frameworkは非同期処理の扱いやすさ、実装のシンプルさの観点からFastAPIを使います。
目次
- 機械学習の推論web APIの構成
- 実装例
1. 機械学習の推論web APIの構成
本記事では、2つのパターンを紹介します。
注) まず、共通部分の説明をします。機械学習の知見が必要なのは基本的に共通部分だけです。もし、機械学習に詳しくない or webに詳しくない場合は、共通部分と後述の部分で役割を分担できるので、そんなもんかと流してもらってもかまいません。
推論API (共通部分)
学習させたモデルに推論させる場合、一般的に以下のような機械学習モデルの推論APIを構築すると思います。
ローカルPCやJupyter Notebook上での開発しかしていない場合でもこのようなAPI (パイプライン) は作ると思います。
詳細は割愛しますが、負荷分散やモデル管理の便利さのためにクラウド上のサーバに機械学習モデルを使うAPIだけ切り出してもいいと思います (参考: GCP AI platform Prediction)。 負荷だけではなく、推論にもGPUを使わないとパフォーマンスに問題がでるような重いモデルの場合、よくあるWEBアプリ用のサーバーでは対応できないので、切り分けできるようにしたほうが柔軟だと思います。
また、学習済みモデルを用いた外部サービスを用いる場合も同じ構成になると思います。
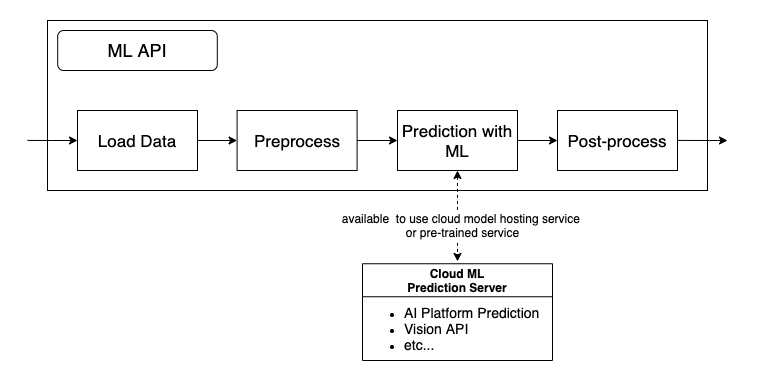
データ量が大きくなってくると前処理などをGoogle Cloud Dataflowのような大規模データ処理エンジンに置き換えるなどの工夫が必要になると思います。
上記のようなローカルPCやJupyter Notebook上で開発した推論APIをベースにしてweb APIをたてる際、主に2種類のパターンが考えられます。これらは、入出力データの扱いが異なります。
- 1.1. オンライン予測(HTTP予測とも呼ばれる)
- 1.2. バッチ予測
(GCPのAI platformで使われている名称を用いています。参考: オンライン予測 vs バッチ予測)
1.1. オンライン予測
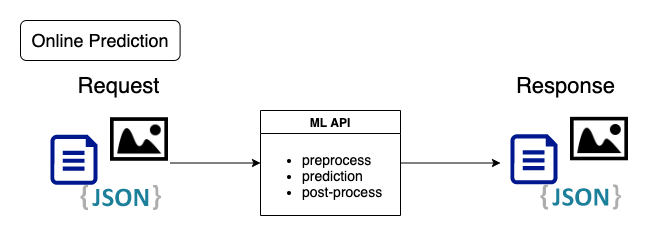
http requestが来たらMLの関数を動かして、outputをhttp responseで即時返すというシンプルな構成です。サーバーの起動時に一度だけ重みをloadしておきます。重みのload時に、cloudのstorage(google storageなど)から重みを取得するようにしておくとモデルの変更がしやすくなります。
利点
- ローカルで動かすような推論用の関数をweb frameworkの中に移すだけでだいたい動く
- 1つのAPIを叩くだけで推論結果が返るのでたたきやすいAPIになる
- モデルが小さく、データが少ない場合は、レスポンスが速い
欠点
- web APIは、負荷分散の観点から数十秒から数分でタイムアウトするように設定されることが多いので、推論に時間が長時間かかると処理が失敗してしまいます。なので、重いモデルや一度に大量のデータをさばくのには適していないです。
1.2. バッチ予測
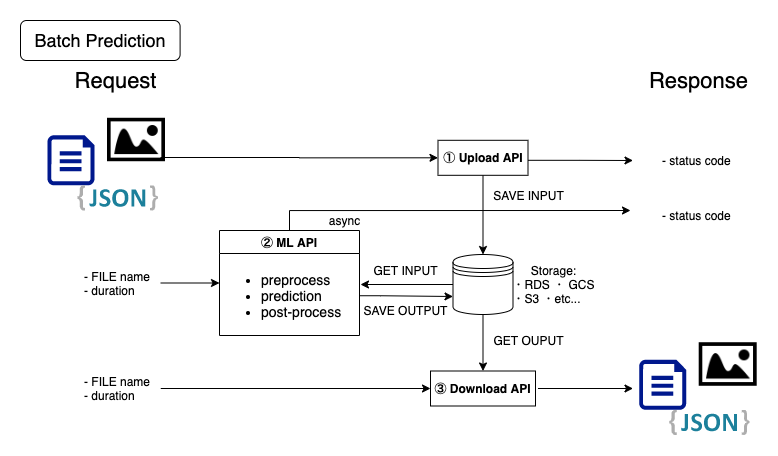
即時にレスポンスを返せない or 返す必要がない場合には以下のようにML APIの推論結果を直接レスポンスせずに、何らかのstorageに格納します。以下の様に、処理を3段階に分けて考えることができます。(2と3が分かれていればいいです。upload APIはML APIに統合してもいいです)
- upload API: 入力用のデータをStorage (Databaseやcloud storageなど) に貯める
- ML API(非同期で実行): Storageからデータを取得、MLの関数を動かし、結果をStorageに保存。ただし、処理が終わるより先にレスポンスを返しておく
- download API: Storageから結果を取得し、返す
それぞれのAPIは疎結合にできます。なので、upload APIとdownload APIの実装はかなり自由度が高いです。
使い方は以下の様に様々です。
- 入力データをに一定期間ためて、1日の終りに一気に推論
- タイムアウトしてしまうような複雑なモデルを用いて推論
- 推論結果をキャッシュして、同じ入力に対して繰り返し推論を行わない
- など
また、uploadとdownload APIの実装はPython以外の言語でも何の問題もないですし、同じstorageに読み書きできれば、異なるサーバーにAPIがたっていてもいいです。APIを経由せずStorageにフロントエンドから直接読み書きしてもいいです。特に入出力が画像の場合はcloud storageを直接扱うほうが簡潔なフローになります。
利点
- タイムアウトで失敗することがなくなる
- 自由度が高い
- 学習用のAPIも同様な構成で実装できる
欠点
- オンライン予測よりも構成が複雑なので、使いにくい
- オンライン予測よりも処理に時間がかかる
2. 実装例
online予測とbatch予測のAPIをFastAPIで実装してみます。
以下の例を見ると、ローカルで推論のパイプラインをちゃんと関数化しておけばweb APIにするのは結構ハードルが低いなと感じてもらえるのではないかと思っています。
やらないこと
本記事では以下は扱いません。
- security
- deploy
FastAPIとは
PythonのWeb frameworkで、Flaskのようなマイクロフレームワークにあたります。
パフォーマンスの高さ、書きやすさ、本番運用を強く意識した設計、モダンな機能などが強みです。
特に、非同期処理が扱いやすいです。
以下、FastAPIの基本知識を前提としています。
もし細かいことが知りたい場合は、適宜以下などを参照して下さい。
推論API (共通部分)
汎用性をもたせるために、非常にざっくりとしたmockを定義します。
特に意味はないですが簡単のため、自然言語処理の感情分析のタスクということにします。
必要な機能は、以下のようになります。ただし、モデルだけ別サーバーに切り出されている場合は、loadとモデルの保持は要りません。
- 重みのloadやjoblib, pickleなどを用いたmodel instanseの読み込み
- モデルの保持
- 推論パイプライン
今回は、predictでランダムな感情を返すモデルとします。処理時間はリアルにしたいのでload時に20秒間フリーズし、predict時に10秒間フリーズするようにしています。
from random import choice
from time import sleep
class MockMLAPI:
def __init__(self):
# model instanse
self.model = None
def load(self, filepath=''):
"""
when server is activated, load weight or use joblib or pickle for performance improvement.
then, assign pretrained model instance to self.model.
"""
sleep(20)
pass
def predict(self, x):
"""implement followings
- Load data
- Preprocess
- Prediction using self.model
- Post-process
"""
sleep(10)
preds = [choice(['happy', 'sad', 'angry']) for i in range(len(x))]
out = [{'text': t.text, 'sentiment': s} for t, s in zip(x, preds)]
return out
リクエスト・レスポンスのデータ形式
リクエストデータの形式を定義します。
以下の様に、複数入力に対応できるようにしてみます。
{
"data": [
{"text": "hogehoge"},
{"text": "fugafuga"}
]
}
レスポンスデータは、入力に推論結果を加えて返すような形式にします。
{
"prediction": [
{"text": "hogehoge", "sentiment": "angry"},
{"text": "fugafuga", "sentiment": "sad"}
]
}
なので、以下の様にSchemaを定義します。
from pydantic import BaseModel
from typing import List
# request
class Text(BaseModel):
text: str
class Data(BaseModel):
data: List[Text]
# response
class Output(Text):
sentiment: str
class Pred(BaseModel):
prediction: List[Output]
2.1. オンライン予測
上述の共通部分を使ってオンライン予測を行うweb APIを実装します。
必要なのは、
- サーバーの起動時に学習済み機械学習モデルを読み込む
- データの受け取り、ML APIで推論、結果を返す
です。以下の様に実装すると最低限のAPIが完成します。
from fastapi import FastAPI
from ml_api import schemas
from ml_api.ml import MockMLAPI
app = FastAPI()
ml = MockMLAPI()
ml.load() # load weight or model instanse using joblib or pickle
@app.post('/prediction/online', response_model=schemas.Pred)
async def online_prediction(data: schemas.Data):
preds = ml.predict(data.data)
return {"prediction": preds}
動作確認
ローカルで動作確認します。
CuRLでsampleの入力をpostします。すると、想定していた出力が返ってくることが確認できます。
また、レスポンスが返ってくるまでにかかった時間は10秒なので、ほぼpredictの処理時間だけしかかかっていないことも確認できます。
$ curl -X POST "http://localhost:8000/prediction/online" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"data\":[{\"text\":\"hogehoge\"},{\"text\":\"fugafuga\"}]}" -w "\nelapsed time: %{time_starttransfer} s\n"
{"prediction":[{"text":"hogehoge","sentiment":"angry"},{"text":"fugafuga","sentiment":"happy"}]}
elapsed time: 10.012029 s
2.1. バッチ予測
上述の共通部分を使ってバッチ予測を行うweb APIを実装します。
- upload API: 入力用のデータをStorage (Databaseやcloud storageなど) に貯める
- ML API(非同期で実行): Storageからデータを取得、MLの関数を動かし、結果をStorageに保存。ただし、処理が終わるより先にレスポンスを返しておく
- download API: Storageから結果を取得し、返す
Input/Output
本来であれば、cloudのstorageやDBにデータを保存すべきですが、簡単のため、本記事ではローカルのストレージにcsv形式でデータを保存します。
まず、読み書きのための関数を定義します。入力データの保存時にランダムな文字列でファイル名を作成し、そのランダムな文字列をapiでやりとりすることで一連のバッチ予測を行います。
実装が長く感じるかもしれないですが、実際は、以下の3つの処理しかないです。
- csvの読み書き
- fileのpathを調整
- ランダムな文字列の生成
import os
import csv
from random import choice
import string
from typing import List
from ml_api import schemas
storage = os.path.join(os.path.dirname(__file__), 'local_storage')
def save_csv(data, filepath: str, fieldnames=None):
with open(filepath, 'w') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for f in data:
writer.writerow(f)
def load_csv(filepath: str):
with open(filepath, 'r') as f:
reader = csv.DictReader(f)
out = list(reader)
return out
def save_inputs(data: schemas.Data, length=8):
letters = string.ascii_lowercase
filename = ''.join(choice(letters) for i in range(length)) + '.csv'
filepath = os.path.join(storage, 'inputs', filename)
save_csv(data=data.dict()['data'], filepath=filepath, fieldnames=['text'])
return filename
def load_inputs(filename: str):
filepath = os.path.join(storage, 'inputs', filename)
texts = load_csv(filepath=filepath)
texts = [schemas.Text(**f) for f in texts]
return texts
def save_outputs(preds: List[str], filename):
filepath = os.path.join(storage, 'outputs', filename)
save_csv(data=preds, filepath=filepath, fieldnames=['text', 'sentiment'])
return filename
def load_outputs(filename: str):
filepath = os.path.join(storage, 'outputs', filename)
return load_csv(filepath=filepath)
def check_outputs(filename: str):
filepath = os.path.join(storage, 'outputs', filename)
return os.path.exists(filepath)
web API
upload、推論、downloadの3つのAPIをたてます。なお、バッチ推論では即時にレスポンスを返さないので、モデルのloadはAPIがたたかれる度に行います。
ここではFastAPIのBackgourndTasksを使ってモデルの推論を非同期処理させています。推論はバックグラウンドで処理を行い、終了を待たずに先にレスポンスを返すことができます。
from fastapi import FastAPI
from fastapi import BackgroundTasks
from fastapi import HTTPException
from ml_api import schemas, io
from ml_api.ml import MockBatchMLAPI
app = FastAPI()
@app.post('/upload')
async def upload(data: schemas.Data):
filename = io.save_inputs(data)
return {"filename": filename}
def batch_predict(filename: str):
"""batch predict method for background process"""
ml = MockMLAPI()
ml.load()
data = io.load_inputs(filename)
pred = ml.predict(data)
io.save_outputs(pred, filename)
print('finished prediction')
@app.get('/prediction/batch')
async def batch_prediction(filename: str, background_tasks: BackgroundTasks):
if io.check_outputs(filename):
raise HTTPException(status_code=404, detail="the result of prediction already exists")
background_tasks.add_task(ml.batch_predict, filename)
return {}
@app.get('/download', response_model=schemas.Pred)
async def download(filename: str):
if not io.check_outputs(filename):
raise HTTPException(status_code=404, detail="the result of prediction does not exist")
preds = io.load_outputs(filename)
return {"prediction": preds}
動作確認
オンライン予測と同様に動作確認します。
CuRLでsampleの入力をpostします。すると、想定していた出力が返ってくることが確認できます。
また、download APIをたたくまでに30秒待っています。しかし、それぞれのresponseは非常に早く返ってきていることがわかります。
$ curl -X POST "http://localhost:8000/upload" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"data\":[{\"text\":\"hogehoge\"},{\"text\":\"fugafuga\"}]}" -w "\nelapsed time: %{time_starttransfer} s\n"
{"filename":"fdlelteb.csv"}
elapsed time: 0.010242 s
$ curl -X GET "http://localhost:8000/prediction/batch?filename=fdlelteb.csv" -w "\nelapsed time: %{time_starttransfer} s\n"
{}
elapsed time: 0.007223 s
$ curl -X GET "http://localhost:8000/download?filename=fdlelteb.csv" -w "\nelapsed time: %{time_starttransfer} s\n" [12:58:27]
{"prediction":[{"text":"hogehoge","sentiment":"happy"},{"text":"fugafuga","sentiment":"sad"}]}
elapsed time: 0.008825 s
おわりに
機械学習の推論web APIの典型的な構成であるオンライン予測とバッチ予測の2つを紹介しました。
一般的なweb APIの構成から多少ひねりが必要となっていますが、FastAPIを使ってシンプルに構築する実装例も紹介しました。ローカルで推論のパイプラインをちゃんと関数化しておけばweb APIにするのはハードルが低いなと感じてもらえたら嬉しいです。
機械学習の盛り上がりは留まるところをしらないですが、web APIの構成などの情報は まだまだ少ないと感じています (結構ありそうです。リンク集を追加しました。)。本記事で紹介した構成も荒削りだと思います。改善点などあればコメントしていただけるとありがたいです!
関連リンク
推論だけでなく学習やMLシステム全体のアーキテクチャなど、本記事で扱いきれなかった内容を取り扱っているリンクです。