気になったこと
ethereumをプライベートブロックチェーンとして使用する場合にデータ量が増えるとgeth(go-ethereum)内で使われているlevelDBへのデータ登録に時間がかかるようになるという記事を見つけた。
そんなことあるんだー。と思って実際に計測してみた
やったこと
Keyは処理番号、Valueに適当なデータという適当すぎるデータを100万件登録する。
100件毎に要した処理時間を計測し、処理時間が増加しているか確認した。
levelDBだけでなく、ついでにmongoDBでもやってみた
levelDBの処理時間
以下のコードでデータを登録
measurement_leveldb.py
import time
import leveldb
# テストデータ:750バイト
inputData = '{"_id" : "ObjectId(\5e3b4dd825755df3f15a2d17\")","coediting" : False,"comments_count" : 0,"created_at" : "2020-02-05T20:20:10+09:00","group" : None,"id" : "6ed1eec1d6fba127a863","likes_count" : 0,"private" : False,"reactions_count" : 0,"tags" : [{"name" : "Python","versions" : [ ]},{"name" : "MongoDB","versions" : [ ]},{"name" : "Python3","versions" : [ ]},{"name" : "pymongo","versions" : [ ]}],"title" : "PythonでmongoDBを操作する~その6:aggregate編~","updated_at" : "2020-02-05T20:20:10+09:00","url" : "https://qiita.com/bc_yuuuuuki/items/6ed1eec1d6fba127a863","page_views_count" : 96,"tag1" : "Python","tag2" : "MongoDB","tag3" : "Python3","tag4" : "pymongo","tag5" : "","tag_list" : ["Python","MongoDB","Python3","pymongo"],"stocks_count" : 0}'
start = time.time()
db = leveldb.LevelDB("measurement_test")
start = time.time()
for i in range(1,1000001):
db.Put(i.to_bytes(4, 'little'), inputData.encode('utf-8'))
if i % 100 == 0:
end = time.time()
print("{0}:{1}".format(i,end-start))
start = end
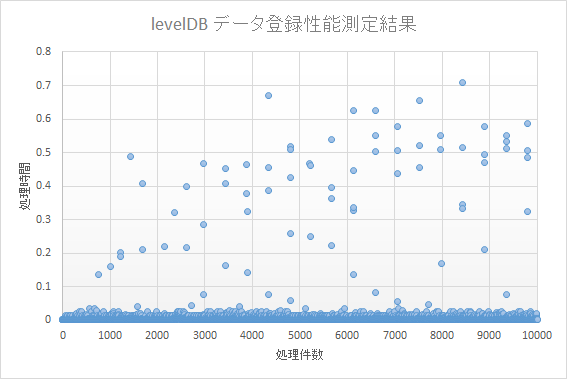
処理結果
mongoDBの処理時間
以下のコードで測定
measurement_mongodb.py
from mongo_sample import MongoSample
import time
mongo = MongoSample("db","measurement")
# テストデータ:750バイト
inputData = '{"_id" : "ObjectId(\5e3b4dd825755df3f15a2d17\")","coediting" : False,"comments_count" : 0,"created_at" : "2020-02-05T20:20:10+09:00","group" : None,"id" : "6ed1eec1d6fba127a863","likes_count" : 0,"private" : False,"reactions_count" : 0,"tags" : [{"name" : "Python","versions" : [ ]},{"name" : "MongoDB","versions" : [ ]},{"name" : "Python3","versions" : [ ]},{"name" : "pymongo","versions" : [ ]}],"title" : "PythonでmongoDBを操作する~その6:aggregate編~","updated_at" : "2020-02-05T20:20:10+09:00","url" : "https://qiita.com/bc_yuuuuuki/items/6ed1eec1d6fba127a863","page_views_count" : 96,"tag1" : "Python","tag2" : "MongoDB","tag3" : "Python3","tag4" : "pymongo","tag5" : "","tag_list" : ["Python","MongoDB","Python3","pymongo"],"stocks_count" : 0}'
start = time.time()
path = "measurement.txt"
with open(path, "w") as out:
for i in range(1,1000001):
mongo.insert_one({str(i):inputData})
if i % 100 == 0:
end = time.time()
out.write("{0}:{1}\n".format(i,end-start))
start = time.time()
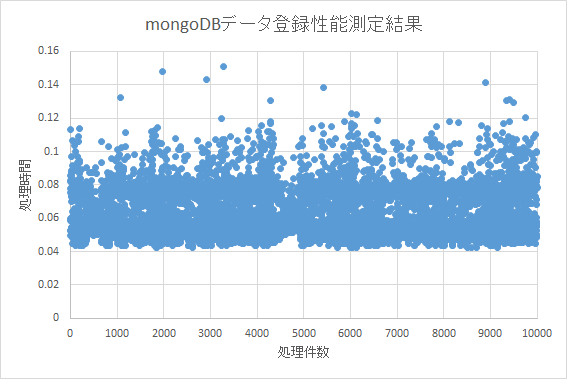
処理結果
検証結果
処理結果の分布を見ると、levelDB、mongoDB共に一定の処理時間帯に概ね分布している。
突出して処理時間を要しているものもあるが、数件程度であるため、書き込み速度が劣化しているとは言えない。
データ量に応じて書き込み速度が遅くなる場合は、右肩上がり もしくは 右上に向かって曲線を描くような分布になるが、今回の検証ではこのような分布にはならなかった。
感想
読んだ記事の詳細な環境やデータ量が不明だったので、参考にした記事の内容が事実かどうかまでは不明のままです。
また、gethは当然go言語ですし、私はgoの環境を作るのがめんどくさかったのでpythonでやってみました。
このあたりも影響があるのかもしれないので引き続き調べてみようかなと思います。
levelDBについて少しだけですが知識を得れたので良かったです。