最近生成 AI 流行ってますね
そんな中 Dify と ComfyUI 組み合わせると超絶楽かつ無料で画像生成できることを発見したので書きます
Dify の公式ツールを使えば以下のことができます
- CivitAI と HuggingFace からモデルをダウンロードしそのまま画像生成
- 4倍アップスケール
- 深度推定
- Wan 2.1 や LTXV, Mochi, Hunyuan, Stable Video Diffusion で動画生成
完全無料ですしローカル画像生成なので R18 もいけますが、倫理や著作権系には注意を
0. Docker インストール
CUDA が使える Docker をインストールしてください
Windows ならば Docker をインストールするだけで自動的に CUDA も使えます
参考: https://docs.docker.com/desktop/features/gpu/
Ubuntu などの Linux の場合はDocker 公式サイトを参考にドライバー等インストールしてください
私は Linux ユーザーなのでこれ以降は Linux で使うときの表記で書きます。とはいえやることは Windows でも同じです。
1. ComfyUI 起動
Docker があればこれ一行でイメージを起動できます
docker run --gpus all -p 8188:8188 l125/comfyui-for-dify:v0.2.0
モデルは1つ普通に数 GB 保存容量食うので別フォルダに保存したければ以下のを実行してください。この場合 models/ 以下のディレクトリを再現しないとバグるため、必ず mkdir /mnt/hdd/models/checkpoints などしておいてください。
docker run -v /mnt/hdd/models:/ComfyUI/models --gpus all -p 8188:8188 l125/comfyui-for-dify:v0.2.0
起動すると http://localhost:8188 と Web ブラウザに入力するだけで ComfyUI が見れるはずです(以下図)
この状態ではまだモデルがダウンロードされていないので画像生成できません
2. Dify 起動
まずレポジトリからダウンロードします
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
以前 .env の FILES_URL を自分の IP アドレスに指定しないと生成された画像がチャットに表示されないことがあったので設定します
FILES_URL=http://192.168.0.5
そして起動
docker-compose up -d
3. Dify と ComfyUI の連携
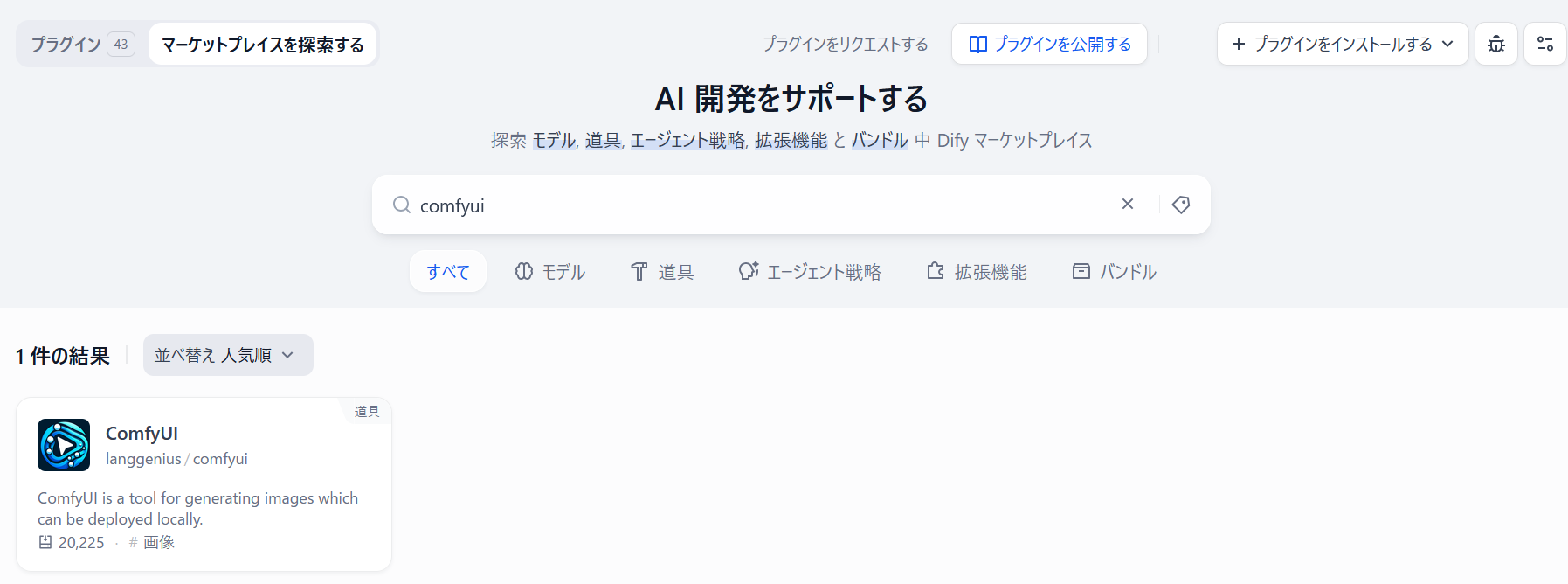
Dify で管理者設定をしてメイン画面に来たら右上の「プラグイン」をクリックします。
そして「マーケットプレイスを探索する」をクリックして ComfyUI ツールをインストールします
プラグイン画面に戻り ComfyUI ツールの設定を以下図のようにします
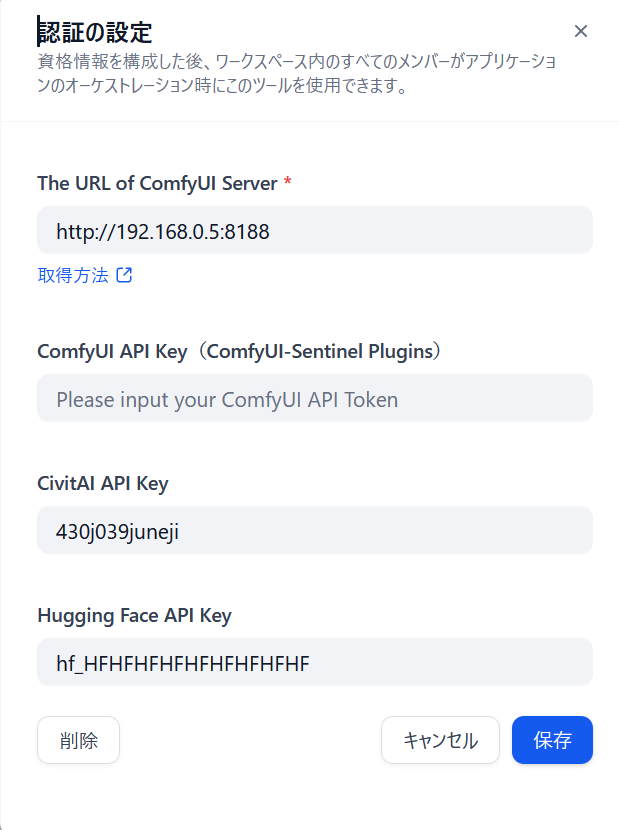
上から ComfyUI のサーバー(ポート指定付き)、ComfyUI-Sentinel(今回不要)、CivitAI の API キー、Hugging Face の API キーを入力します。
4. 画像生成してみる
適当にチャットフローを作って以下のようにしてみます。
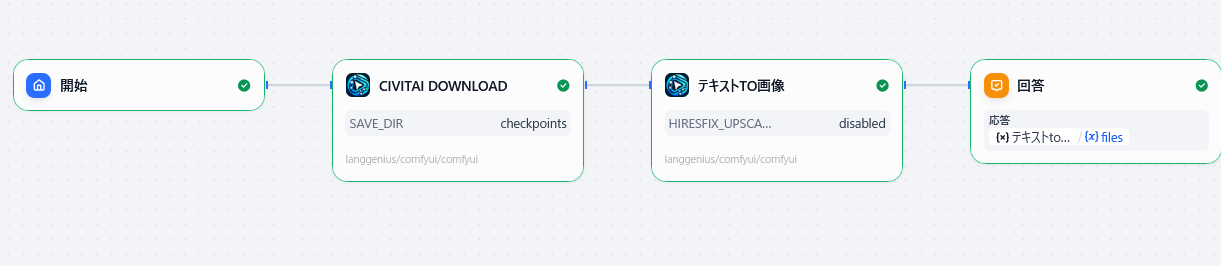
あとはプレビューで "cat" と入力するだけでモデルのダウンロードも画像生成も全自動でしてくれます。以下が結果です(再配布禁止)。

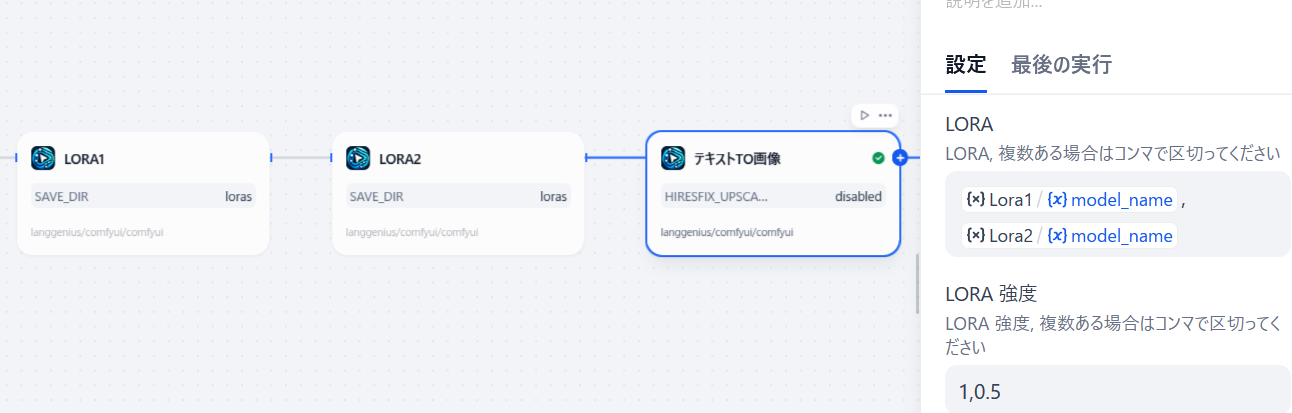
以下図のように Civit Download を LORA1, LORA2 と改名して繋げてあげて、「テキストto画像」ノードに入力してあげれば LORA も適用できます。
同じ要領で Hugging Face からもダウンロードできます。以下は今月公開されたNovelAI Diffusion Anime V2を動かすワークフローです

5. 4倍アップスケールと深度推定してみる
Image Edit ノードを使えば 4倍アップスケールと深度推定できます。
Upscale ESRGAN x4 を指定すれば入力画像を 4 倍にアップスケールしてくれます。

あとは Depth Pro を選択すれば以下のような画像が出ます。


まとめ
Dify を経由して ComfyUI を使えば、自動でモデルをダウンロードしてくれるので便利ですね。ComfyUI を直接いじるよりも楽かもしれないです。
動画生成もしましたがかなり生成時間がかかるのでまだ一般向けじゃなさそうですね。
とはいえ Wan 2.1 や LTXV, Mochi, Hunyuan, Stable Video Diffusion などを全部手軽に試せるのは良いですね。必要なモデルも全部自動でダウンロードしてくれますし
今後の ComfyUI ツールに期待です
興味がわいたらぜひご自身でやってみてください。Qiita 記事とかでやったことを共有してもらえるととてもうれしいです
では