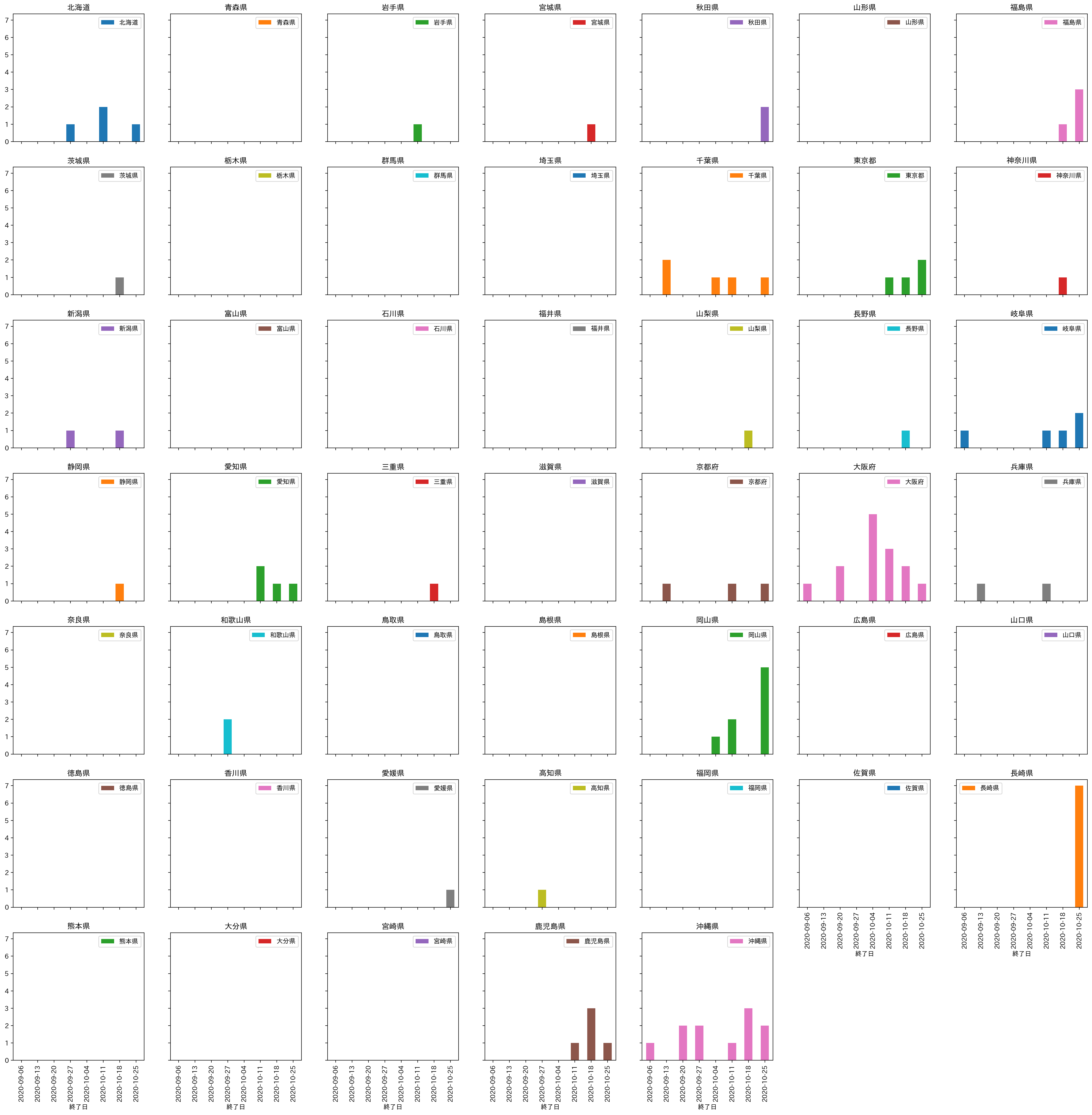
import csv
import datetime
import pathlib
import re
from urllib.parse import urljoin
import camelot
import pandas as pd
import requests
from bs4 import BeautifulSoup
from pdfminer.high_level import extract_text
def fetch_file(url, dir="."):
r = requests.get(url)
r.raise_for_status()
p = pathlib.Path(dir, pathlib.PurePath(url).name)
p.parent.mkdir(parents=True, exist_ok=True)
with p.open(mode="wb") as fw:
fw.write(r.content)
return p
url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/kenkou_iryou/kenkou/kekkaku-kansenshou01/houdou_00008.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
r = requests.get(url, headers=headers)
r.raise_for_status()
soup = BeautifulSoup(r.content, "html.parser")
d1 = []
d2 = []
for i in soup.select('ul.m-listLink > li > a[href$=".pdf"]')[::-1]:
text = i.get_text(strip=True)
t = re.match("(\d{4})年(\d{1,2})月(\d{1,2})日", text)
# 報道発表日
if t:
year, month, day = map(int, t.groups())
dt_date = datetime.date(year, month, day)
else:
dt_date = datetime.date.today()
# PDFファイル
link = urljoin(url, i.get("href"))
p = fetch_file(link)
s = extract_text(p, page_numbers=[1])
m = re.search("(\d{4})年(\d{1,2})週\((\d{1,2})月(\d{1,2})日~(\d{1,2})月(\d{1,2})日\)", s)
if m:
s_year, s_week, s_month, s_day, e_month, e_day = map(int, m.groups())
dt_start = datetime.date(s_year, s_month, s_day)
dt_end = datetime.date(s_year, e_month, e_day)
if dt_start > dt_end:
dt_end = datetime.date(s_year + 1, e_month, e_day)
tables = camelot.read_pdf(
link, pages="2", split_text=True, strip_text=" ,\n", line_scale=40
)
df_tmp = pd.DataFrame(
tables[0].data[2:], columns=["都道府県", "報告数", "定点当たり"]
).set_index("都道府県")
df_tmp = df_tmp.mask(df_tmp == "-").astype(float)
df_tmp["報告数"] = df_tmp["報告数"].astype("Int64")
df_tmp.loc["年"] = s_year
df_tmp.loc["週"] = s_week
df_tmp.loc["開始日"] = dt_start
df_tmp.loc["終了日"] = dt_end
s1 = df_tmp["報告数"]
s1.name = dt_date
d1.append(s1)
s2 = df_tmp["定点当たり"]
s2.name = dt_date
d2.append(s2)
df1 = pd.concat(d1, axis=1, sort=False).T.astype({"年": int, "週": int})
df2 = pd.concat(d2, axis=1, sort=False).T.astype({"年": int, "週": int})
df3 = df1.join(df2, rsuffix="(定点当たり)")
df = df3.reindex(
columns=[
"年",
"週",
"開始日",
"終了日",
"北海道",
"北海道(定点当たり)",
"青森県",
"青森県(定点当たり)",
"岩手県",
"岩手県(定点当たり)",
"宮城県",
"宮城県(定点当たり)",
"秋田県",
"秋田県(定点当たり)",
"山形県",
"山形県(定点当たり)",
"福島県",
"福島県(定点当たり)",
"茨城県",
"茨城県(定点当たり)",
"栃木県",
"栃木県(定点当たり)",
"群馬県",
"群馬県(定点当たり)",
"埼玉県",
"埼玉県(定点当たり)",
"千葉県",
"千葉県(定点当たり)",
"東京都",
"東京都(定点当たり)",
"神奈川県",
"神奈川県(定点当たり)",
"新潟県",
"新潟県(定点当たり)",
"富山県",
"富山県(定点当たり)",
"石川県",
"石川県(定点当たり)",
"福井県",
"福井県(定点当たり)",
"山梨県",
"山梨県(定点当たり)",
"長野県",
"長野県(定点当たり)",
"岐阜県",
"岐阜県(定点当たり)",
"静岡県",
"静岡県(定点当たり)",
"愛知県",
"愛知県(定点当たり)",
"三重県",
"三重県(定点当たり)",
"滋賀県",
"滋賀県(定点当たり)",
"京都府",
"京都府(定点当たり)",
"大阪府",
"大阪府(定点当たり)",
"兵庫県",
"兵庫県(定点当たり)",
"奈良県",
"奈良県(定点当たり)",
"和歌山県",
"和歌山県(定点当たり)",
"鳥取県",
"鳥取県(定点当たり)",
"島根県",
"島根県(定点当たり)",
"岡山県",
"岡山県(定点当たり)",
"広島県",
"広島県(定点当たり)",
"山口県",
"山口県(定点当たり)",
"徳島県",
"徳島県(定点当たり)",
"香川県",
"香川県(定点当たり)",
"愛媛県",
"愛媛県(定点当たり)",
"高知県",
"高知県(定点当たり)",
"福岡県",
"福岡県(定点当たり)",
"佐賀県",
"佐賀県(定点当たり)",
"長崎県",
"長崎県(定点当たり)",
"熊本県",
"熊本県(定点当たり)",
"大分県",
"大分県(定点当たり)",
"宮崎県",
"宮崎県(定点当たり)",
"鹿児島県",
"鹿児島県(定点当たり)",
"沖縄県",
"沖縄県(定点当たり)",
"総数",
"総数(定点当たり)",
"昨年同期(総数)",
"昨年同期(総数)(定点当たり)",
]
)
df.to_csv(
"influ_all.csv", index=False, quoting=csv.QUOTE_NONNUMERIC, encoding="utf_8_sig", na_rep="-",
)