背景・目的
本業でKubeflow Pipelinesを使ったMLOps基盤を構築しています。Kubeflow Pipelinesは最先端のOSSであり、その仕様も日々更新されています。導入に於いて、嵌るポイントがいくつかあったので備忘録として残します。
Kubeflow Pipelinesとは?
Kubeflow Pipelines は、Kubernetes 上で動作する機械学習ワークフローのための拡張可能なプラットフォームです。再現性が高く、コンポーネント化された ML ワークフローを構築・デプロイするためのオープンソースプラットフォームとして開発されています。
主な特徴
- パイプラインの定義: Python SDK または UI を使用して ML ワークフローを定義できます
- 再現性: 各実験とそのパラメータを追跡し、同じ結果を得るために再実行できます
- コンポーネント化: 再利用可能なコンポーネントを作成し共有できます
- UI ダッシュボード: パイプラインの作成、モニタリング、分析のための直感的なインターフェース
- Kubernetes ネイティブ: コンテナ化された環境で実行され、スケーラビリティを確保
ユースケース
- データ前処理
- モデルトレーニング
- ハイパーパラメータチューニング
- モデルデプロイ
- CI/CD パイプラインの自動化
参照リンク
Kubeflow 公式ドキュメント
GitHub リポジトリ
Kubeflow Pipelines SDK ドキュメント
PytorchJobをKubeflow Pipelinesで実行する手順
1.実行環境
2.KFPインストール作業と注意点
3.Kubeflow Pipelines実行方法と注意点
1.実行環境
WSL上からEKSクラスタに接続。
pipelinesのコンパイルはWindowsから実施。
| 項目 | 内容 |
|---|---|
| Windows | OS 名: Microsoft Windows 11 Enterprise; OS バージョン: 10.0.22631 N/A ビルド 22631 |
| WSL | WSL バージョン: 2.0.14.0; カーネル バージョン: 5.15.133.1-1; WSL バージョン: 1.0.59; MSRDC バージョン: 1.2.4677; Direct3D バージョン: 1.611.1-81528511; DXCore バージョン: 10.0.25131.1002-220531-1700.rs-onecore-base2-hyp; Windows バージョン: 10.0.22631.4460; Linux/5.15.133.1-microsoft-standard-WSL2 exe/x86_64.ubuntu.24 |
| AWS CLI | 2.19.0 |
| EKS クラスタ | k8s Ver:1.31※HyperPod Clusterでは未検証です |
| kubectl | Client Version: v1.31.2; Kustomize Version: v5.4.2; Server Version: v1.29.9-eks-ce1d5eb |
| Kubeflow Pipelines | 2.3.0 |
| Python | 3.12.7 |
| Python Package | venvで仮想環境を作って、その中でPytorchJobをpipelinesにコンパイルした |
2.KFPインストール作業と注意点
詳細手順
- EKSクラスタにKFPをインストールする
- training-operatorをインストールする
- Kueueをインストールする
- Python Packageをインストールする
- Kubeflow Pipelinesのコンパイル
- Kubeflow Pipelinesの実行
1.EKSクラスタにKFPをインストールする
-
方法
Installation | Kubeflow
2.3.0を入れる -
注意点
EKSクラスタにEBSドライバーを導入して以下の手順でロールを作成、割り当てる必要がある。Amazon EBS で Kubernetes ボリュームを保存する - アマゾン EKS
AWS Identity and Access Management IAM OpenID Connect (OIDC) プロバイダーが既に存在している場合、
ステップ 1: IAM ロールを作成するから実施すれば良い。
上記手順で作成したroleを当該EKSクラスターのIAMロールに設定する
また、
EKSクラスタのIAMロールと実行ロールにAmazonEC2FullAccess及び、AmazonEBSCSIDriverPolicyを設定する必要がある。
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8081:80
の様に任意のport(8081)にポートフォワードして、ブラウザからhttp://localhost:8081にアクセスするとUIが開く。
2024/11/22時点ではこれで接続できる。繋がらない場合は、
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8081:3000 を試す。
さらに、
環境変数DISABLE_GKE_METADATAを'true'に設定する必要がある。
これにより、GKEクラスタ以外では利用できないGKEメタデータのフェッチが無効になる。
具体的には、以下ソース内のDISABLE_GKE_METADATAをTrueに変更する必要がある。
https://github.com/kubeflow/pipelines/blob/master/frontend/server/configs.ts
以下を実行
kubectl set env deployment/ml-pipeline-ui --namespace kubeflow DISABLE_GKE_METADATA="true"
尚、minio-pvcとmysql-pv-claimのpvcがpendingのまま起動しないことがあります。gp2 Storageclassがdefault(gp2でなくとも良い)に設定されていないと、pvcがセットされず起動しません。
2.training-operatorをインストールする
-
方法
kubectl apply -k "http://github.com/kubeflow/training-operator.git/manifests/overlays/standalone?ref=v1.8.1" -
注意点
kubeflow pipline は、内部のリースを消すとkubeflow pipline自体が消される。例えば、training operatorを消すとkubeflow pipline 自体が消える。
trainig operatorは安定の1.81を使うこと。latest(master)だと上手く動かない。
3.Kueueをインストールする
-
方法
kubectl apply --server-side -f https://github.com/kubernetes-sigs/kueue/releases/download/v0.8.1/manifests.yaml -
注意点
最新版は怖いため、0.8.1を使う。以下を参照のこと
Installation
4.KFP SDKをインストールする
-
方法
pip install kfp[kubernetes]
参照:KFP SDK kfp-kubernetes API Reference
Successfully installed kfp-2.9.0 kfp-kubernetes-1.3.0と表示されればOK -
注意点
EKSクラスタへのインストールではなく、pipelinesをコンパイルする環境(上記の表のvenv)で実施すること
5.Kubeflow Pipelinesのコンパイル
- 実行方法
python pipeline_train.py
同ディレクトリに
trainjobstart.yaml というファイルができる。これがKubeflow Pipelines本体。
# this is kubeflow pipeline
from time import sleep
import kfp
import kfp.dsl as dsl
from kubernetes import client, config, utils
from pprint import pprint
packages_to_install = \
['kfp==2.9.0',
'kfp-server-api==2.3.0',
'kfp-pipeline-spec==0.4.0',
'kfp-kubernetes==1.3.0',
'kubernetes==25.3.0',
'PyYAML==6.0.2',
'python-dateutil==2.9.0.post0']
@kfp.dsl.component(base_image="python:3.10", packages_to_install=packages_to_install)
def mainlogic(nodeCount: int, namespace: str, experimentsname:str, epoch:int,
workflow_name: str = "{{workflow.name}}",
workflow_creationTimestamp: str = "{{workflow.creationTimestamp}}",) -> dict:
from time import sleep
import kfp
from kubernetes import client, config, utils
import datetime
from dateutil import parser
from yaml import safe_load
from pprint import pprint
import json
print(f"workflow_name: {workflow_name}")
print(f"workflow_creationTimestamp: {workflow_creationTimestamp}")
# create datetime from workflow_createTimestamp str
workflow_time = parser.parse(workflow_creationTimestamp)
jobname = f"{namespace}-{workflow_time.strftime('%Y%m%d%H%M%S')}"
print(f"jobname: {jobname}")
templateYaml = '''
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:
name: --job_name--
namespace: --owner_ns--
labels:
kueue.x-k8s.io/queue-name: user-queue-test
spec:
runPolicy:
suspend: true
elasticPolicy:
rdzvBackend: c10d
maxRestarts: 0
minReplicas: 1 # ノード数を指定します。8GPUの時は1、16GPUの時は2、32の時は4を設定します。
maxReplicas: 1 # ノード数を指定します。8GPUの時は1、16GPUの時は2、32の時は4を設定します。
pytorchReplicaSpecs:
Worker:
replicas: --workerReplicas-- # ノード数を指定します。8GPUの時は1、16GPUの時は2、32の時は4を設定します。
restartPolicy: Never
template:
spec:
serviceAccountName: mlflow-service-account # 11/19 ここにSA追加 namespaceごとに作成必要
volumes:
- name: dshm
hostPath:
path: /dev/shm
- name: fsx-pv
persistentVolumeClaim:
claimName: fsx-claim-3 # namespaceごとに作成必要
containers:
- name: pytorch
image: {{workflow_name}}:latest # ここはMNISTのdockerイメージを指定します。dockerhubやECRにpushしておく必要があります。
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- >
NUM_GPUS=$((${PET_NNODES#*:}*16));
bash
/aws/jobscript.sh
resources:
limits:
nvidia.com/gpu: 4
#vpc.amazonaws.com/efa: 32
requests:
nvidia.com/gpu: 4
#vpc.amazonaws.com/efa: 32
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: fsx-pv
mountPath: /group
env:
- name: K8S_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: K8S_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: K8S_JOB_NAME
valueFrom:
fieldRef:
fieldPath: metadata.labels['training.kubeflow.org/job-name']
- name: K8S_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
'''
# create yaml from template
# template replace mark
templateYaml = templateYaml.replace("--job_name--",jobname)\
.replace("--owner_ns--",namespace)\
.replace("--experimentsname--",experimentsname)\
.replace("--epochs--",str(epoch))\
.replace("--workerReplicas--",str(nodeCount-1)) # master 1 node
print(f"this pipeline creating job -> namespace:{namespace}, name:{jobname}") # これでpipline runのUIのログに書かれるはず
# kubectl create from yaml
config.load_incluster_config()
k8s_client = client.ApiClient()
api_instance = client.CustomObjectsApi(k8s_client)
body = safe_load(templateYaml)
api_response = api_instance.create_namespaced_custom_object("kubeflow.org", "v1", namespace, "pytorchjobs", body)
# pytorch jobは動作できない・・・・
#utils.create_from_yaml(k8s_client,yamlfilepath,verbose=True)
print(f"this pipeline created job! -> namespace:{namespace}, name:{jobname}") # これでpipline runのUIのログに書かれるはず
# batch_v1 = client.BatchV1Api()
job_completed = False
while not job_completed:
# ジョブステータスの取得
api_response = api_instance.get_namespaced_custom_object_status("kubeflow.org", "v1", namespace, "pytorchjobs", jobname)
# print(json.dumps(api_response, indent=2))
if("status" not in api_response):
print("status is not found ....") # 作成直後はstatusが取れない
sleep(1)
continue
status = api_response["status"]["conditions"][-1]["type"]
print(f"status='{status}'")
if(status == "Succeeded" or status == "Failed"):
job_completed = True
sleep(1)
return {"complete. jobname":jobname, "owner":namespace} # jobname, namespace
@kfp.dsl.component(base_image="python:3.10", packages_to_install=packages_to_install)
def jobCheckAndDelete(namespace:str,
workflow_name: str = "{{workflow.name}}",
workflow_creationTimestamp: str = "{{workflow.creationTimestamp}}") -> None:
print(f"workflow_name: {workflow_name}")
print(f"workflow_creationTimestamp: {workflow_creationTimestamp}")
from time import sleep
import kfp
from kubernetes import client, config, utils
import datetime
from dateutil import parser
# create datetime from workflow_createTimestamp str
workflow_time = parser.parse(workflow_creationTimestamp)
jobname = f"{namespace}-{workflow_time.strftime('%Y%m%d%H%M%S')}"
print(f"jobname: {jobname}")
# kubectl yaml
config.load_incluster_config()
k8s_client = client.ApiClient()
api_instance = client.CustomObjectsApi(k8s_client)
# ジョブステータスの取得
api_response = api_instance.get_namespaced_custom_object_status("kubeflow.org", "v1", namespace, "pytorchjobs", jobname)
if("status" not in api_response):
print("status is not found ....") # 作成直後はstatusが取れない
status = "create now"
else:
status = api_response["status"]["conditions"][-1]["type"]
print(f"status='{status}'")
job_completed = False
if(status == "Succeeded" or status == "Failed"):
job_completed = True
if(job_completed == False):
print(f"Job deleteting....namespace:{namespace}, name:{jobname}")
# k8s delete job from namespace and name
group = "kubeflow.org"
version = "v1"
plural = "pytorchjobs"
api_response = api_instance.delete_namespaced_custom_object(group, version, namespace, plural, jobname) # TBD: 必要に応じてdeleteのoptionを設定する
print(f"Job deleteted")
if(status == "Failed"):
raise Exception("train has faild") # raise exceptionするとエラーになると思う・・・
@kfp.dsl.pipeline(name='Train Pipeline', description='A pipeline to train model using PyTorch.')
def trainjobstart(
nodeCount: int = 2,
owner: str = 'todo:yourname',
experimentsname: str = 'todo:experimentsname',
epoch: int = 1
):
handler = jobCheckAndDelete(namespace=owner)
# Exit handler
# ここでexit handlerを設定する
with dsl.ExitHandler(handler):
mainTask = mainlogic(nodeCount=nodeCount, namespace=owner, experimentsname=experimentsname,epoch=epoch)
pass
# Compile your pipeline.
client = kfp.Client()
kfp.compiler.Compiler().compile(trainjobstart, package_path='trainjobstart.yaml')
6.Kubeflow Pipelinesの実行
6-1.既存のPiplineを更新する場合:ユーザーの利用を想定
既に登録されているPipelineがあるとする
手順1の方法でブラウザからUIに接続。
左の列のPipelinesをクリック。登録されているpipeline nameをクリック。
※複数のpipelineを登録しておき、ユースケースに合わせて使っていただくことを想定。
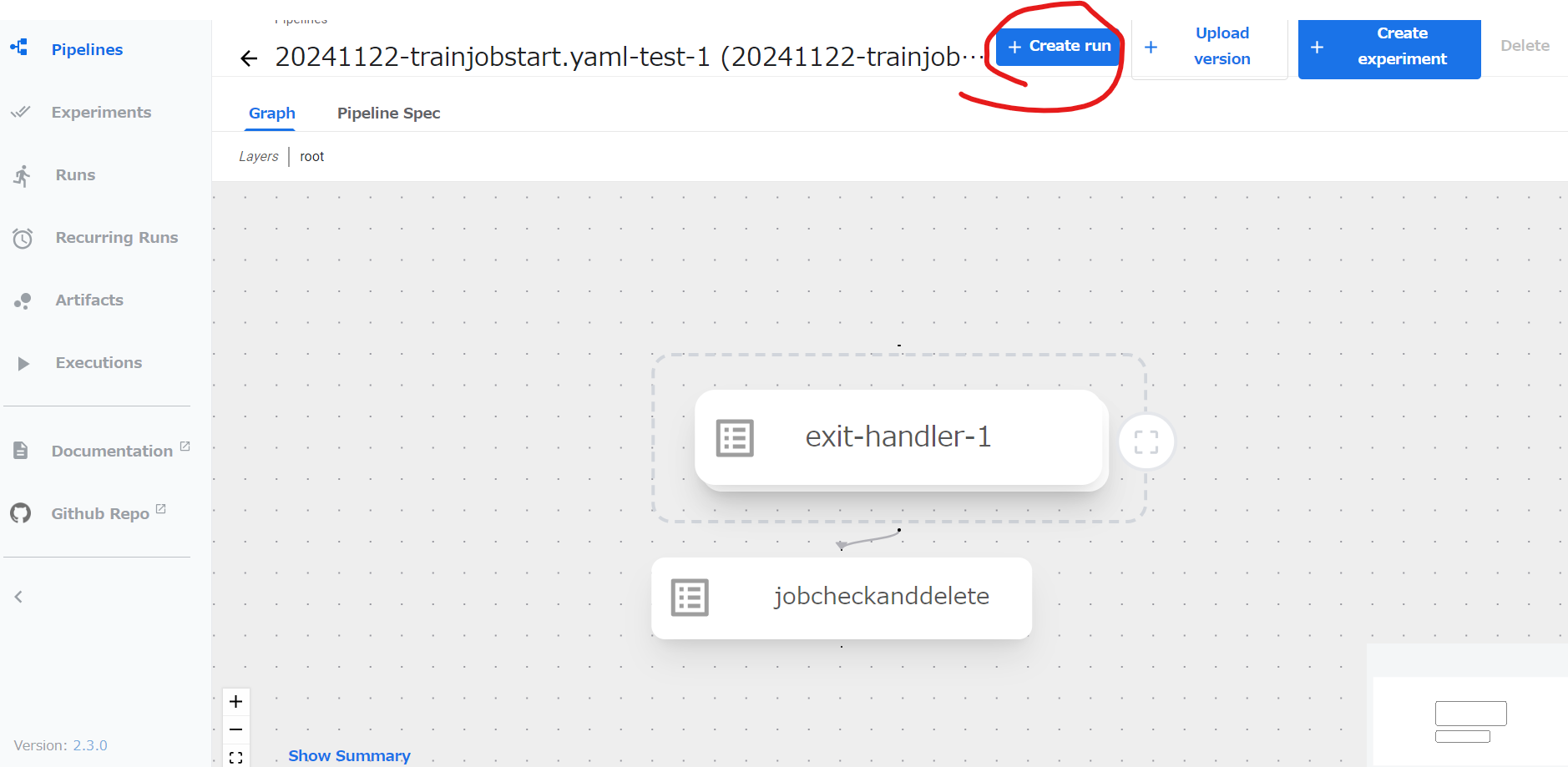
Create runを押す
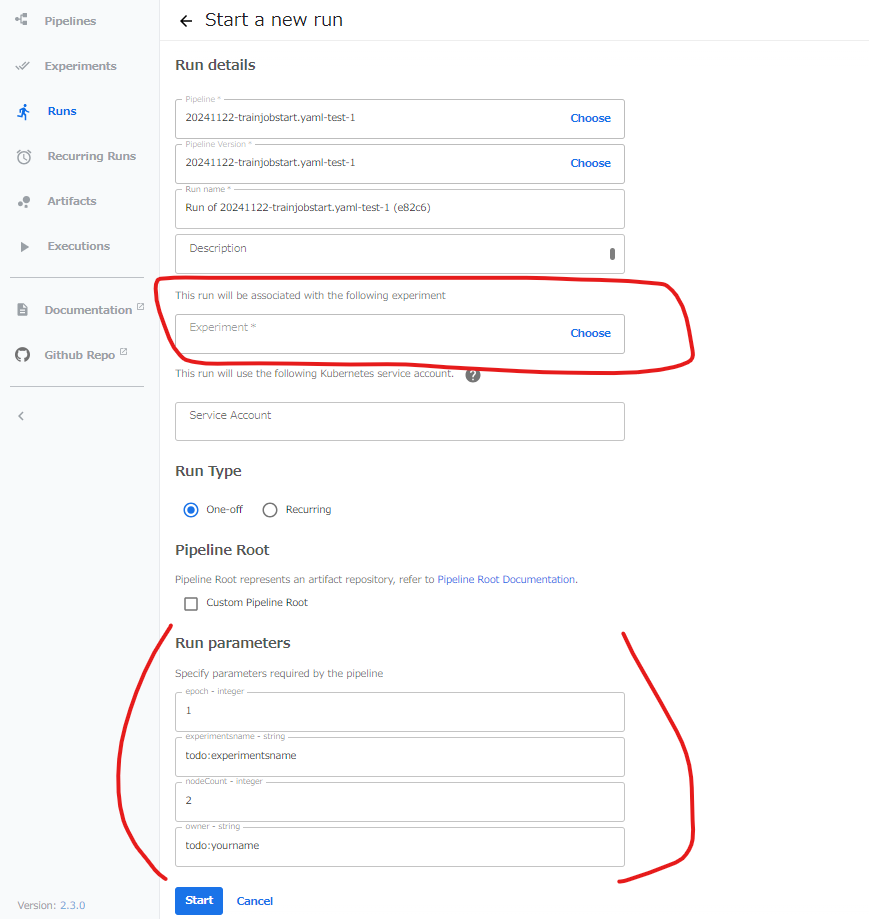
PipelineのExperiments名を入力する。(赤枠内)※設定しなくても可
Run ParametersにJOBのパラメータを入れる。
- epoch :学習のepoch
- experimentsname:MLFlowの実験名
- nodeCount:EKSクラスタのnode数
- owner:ユーザー名
最下段のStartを押すとPipelineの実行が開始する。
Pipelineが完了すると以下の様に、各コンポーネントに緑チェックマークが付く。
失敗すると赤チェックマークが付く。
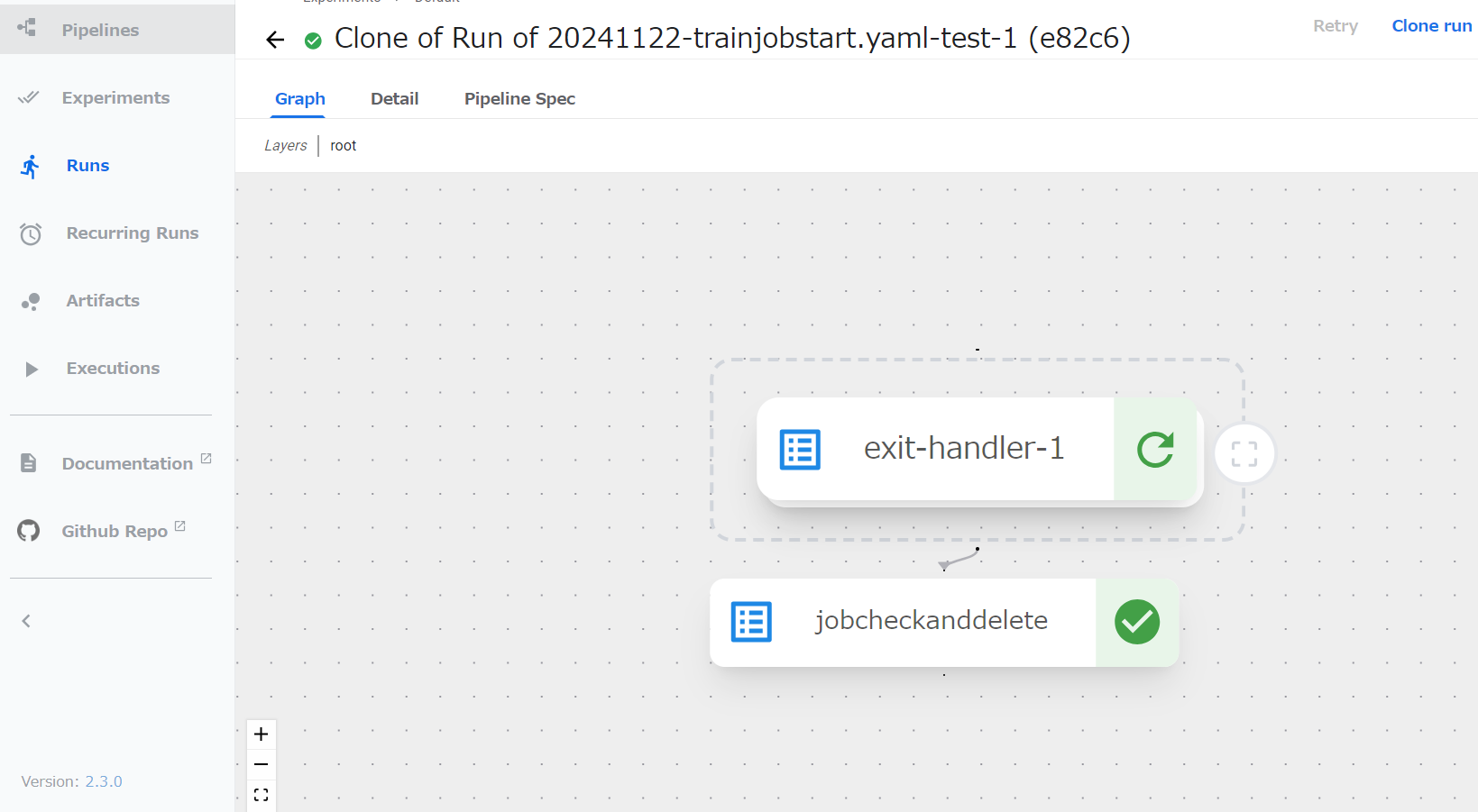
以下のマークを押すことでExit-handler内のコンポーネントを確認できる。
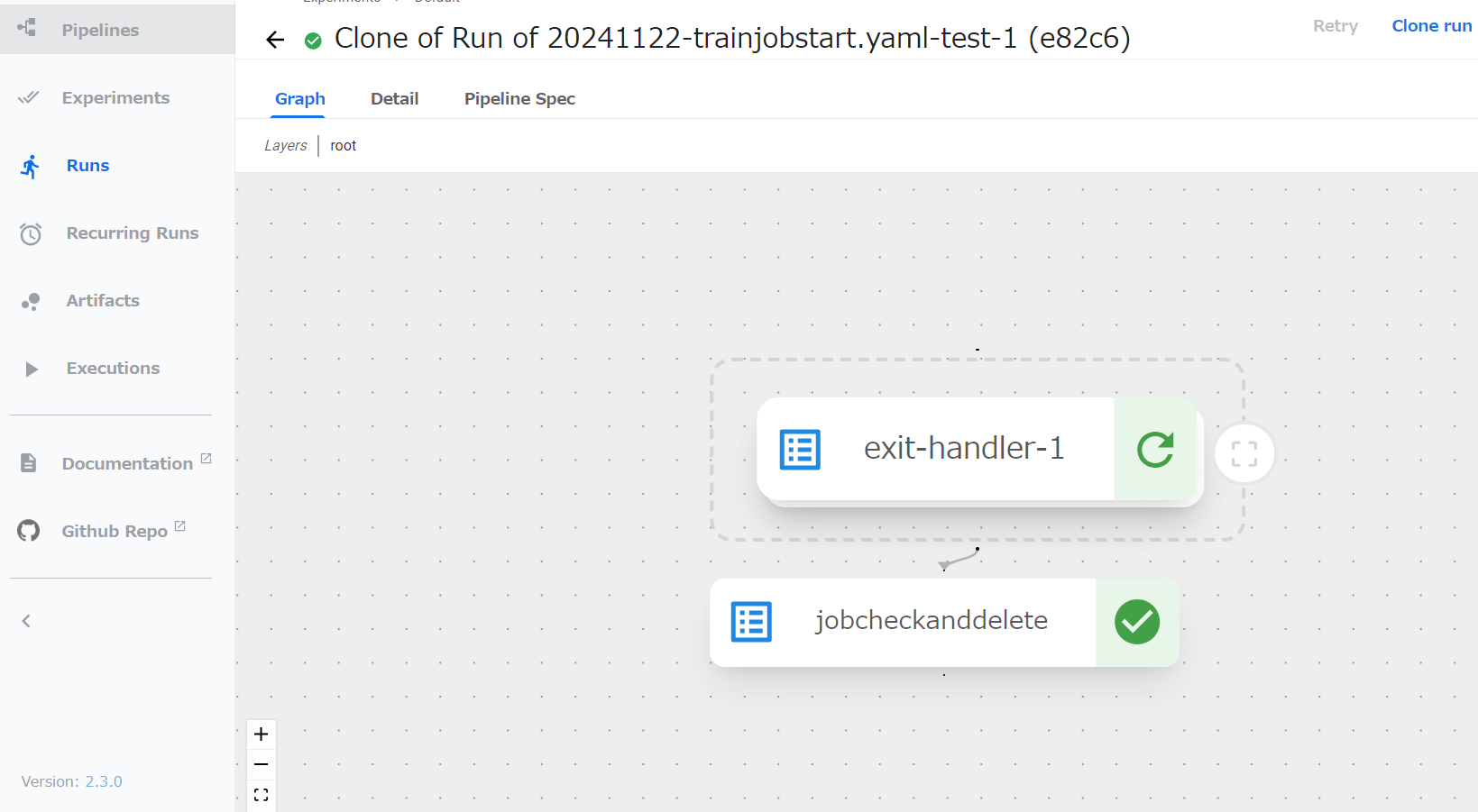
更に、Open Sub-DAGをクリック
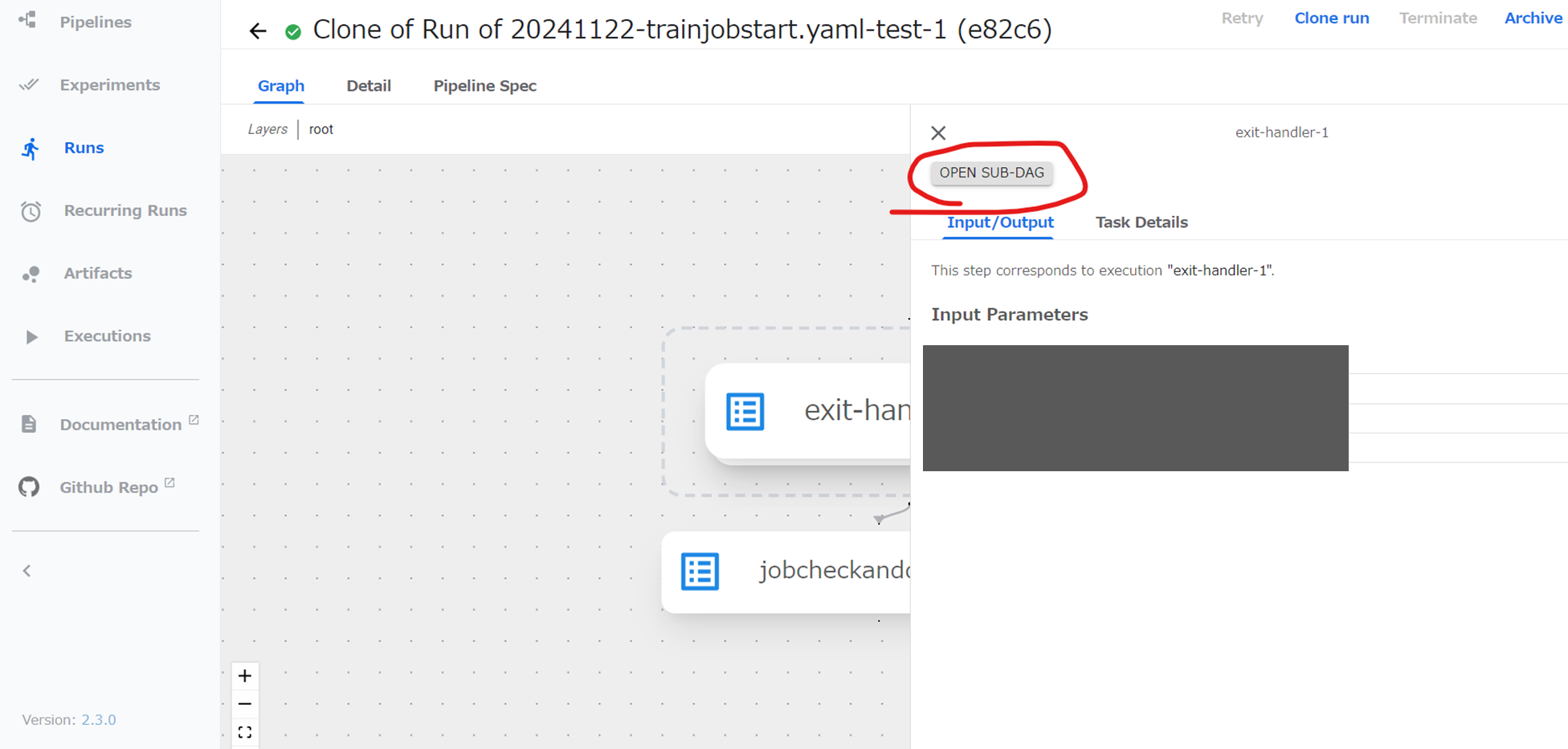
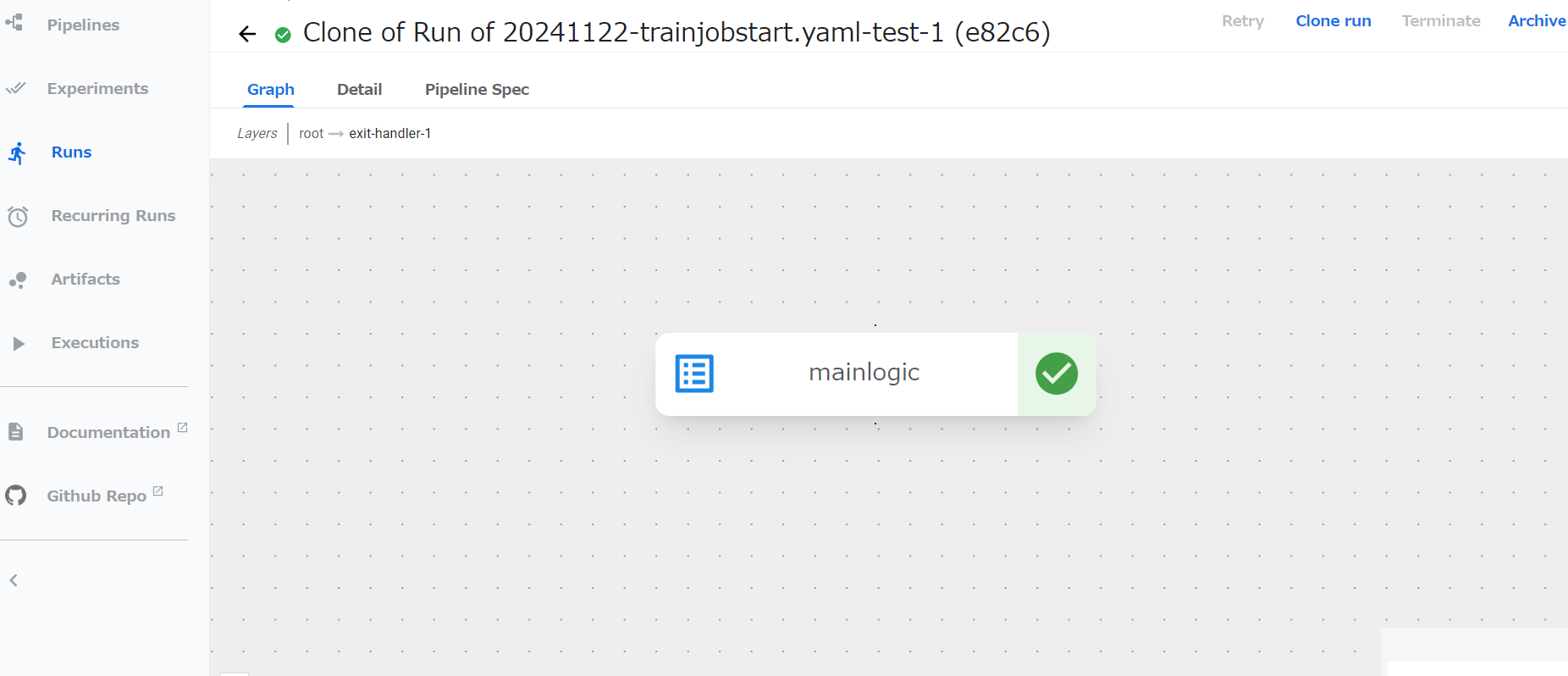
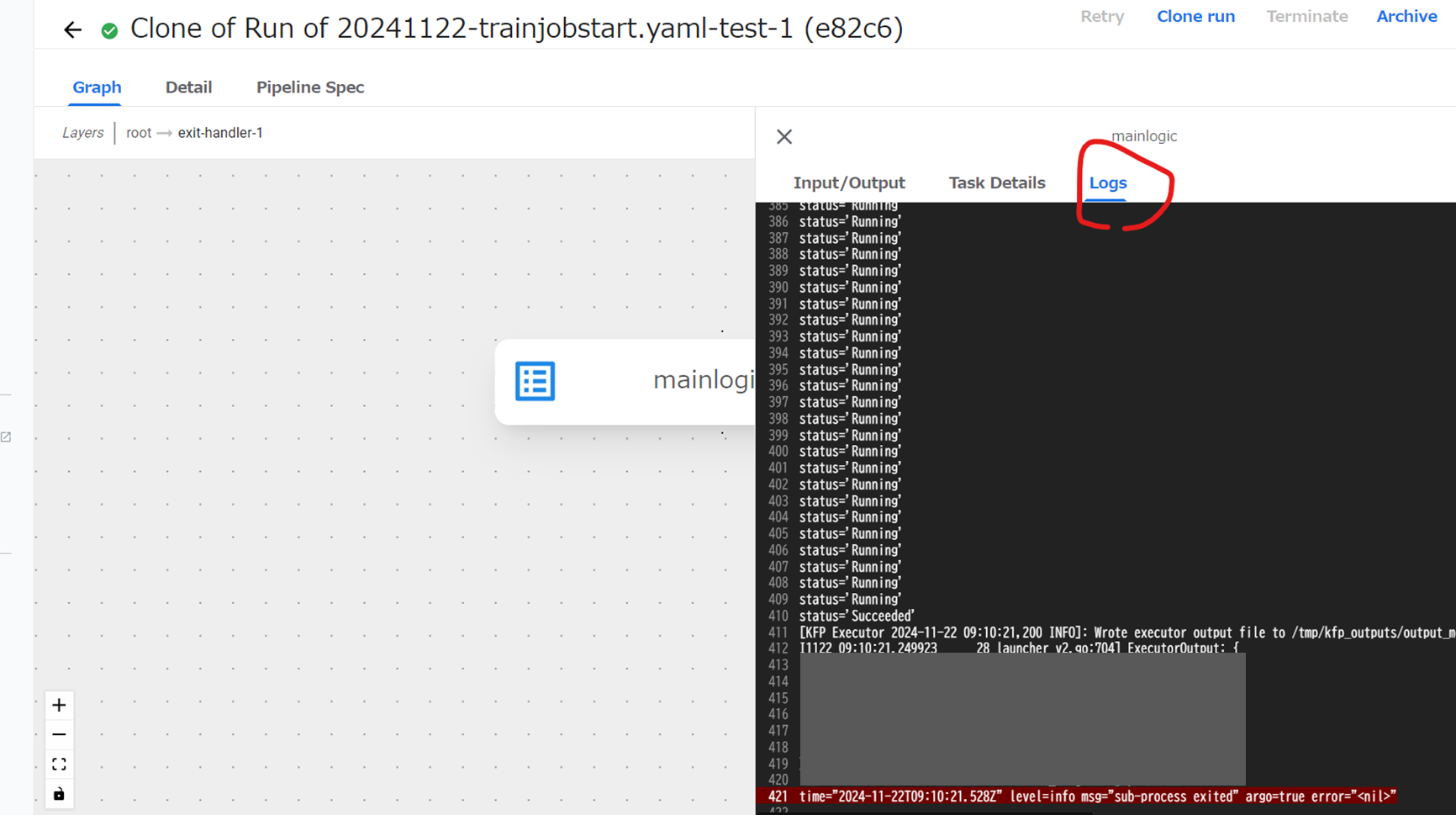
コンポーネントをクリックするとLog等のタブ等が現れる。
Logから実行Statusやエラーメッセージが確認できる。
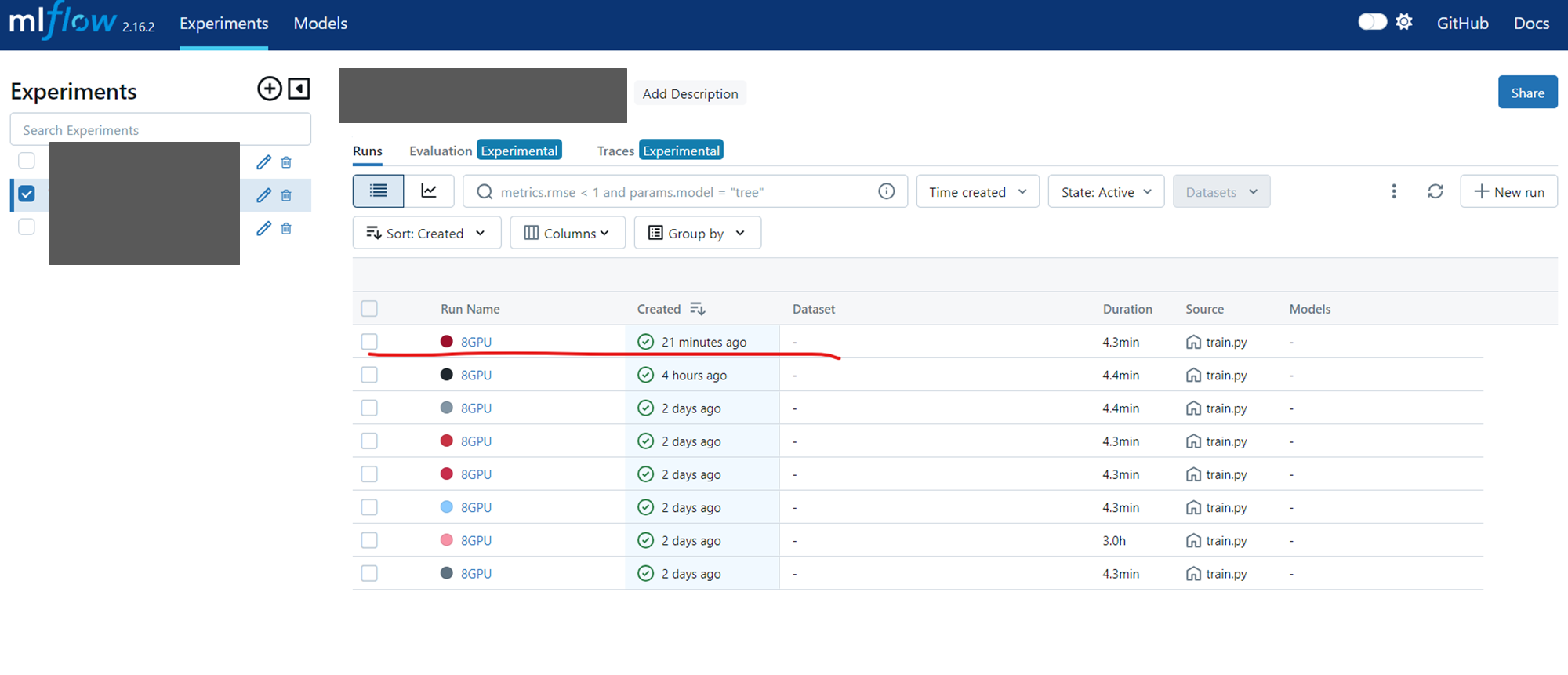
MLFlowを確認すると、experimentsnameで付けた実験名に該当するExperiments(無ければ、作成される)
以下にPipelineで実行したPytorchJobの結果が保存されている。
6-2.Piplineを1から作成する場合:開発者がPiplineを登録する際を想定
-
方法
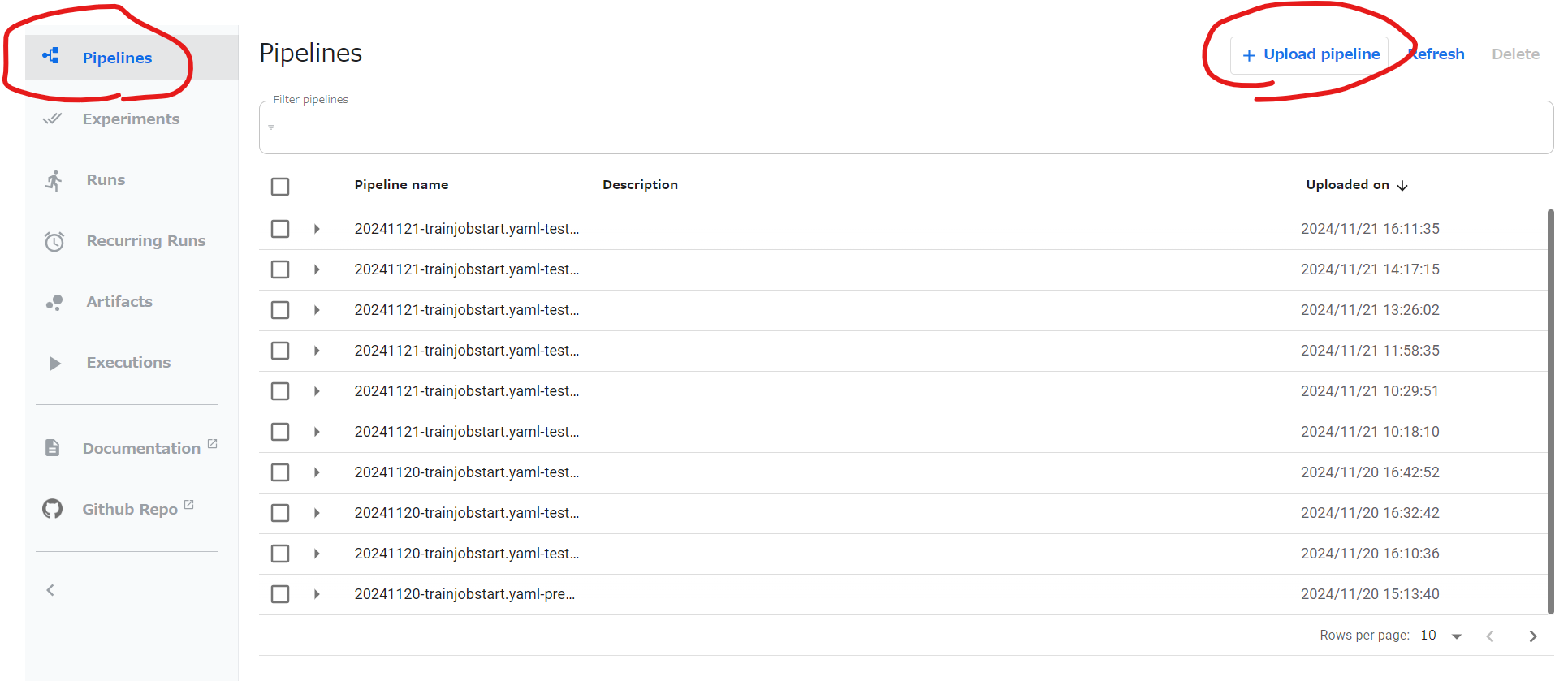
手順1の方法でブラウザからUIに接続。
左の列のPipelinesをクリック。右上のUpload pipelineをクリック。
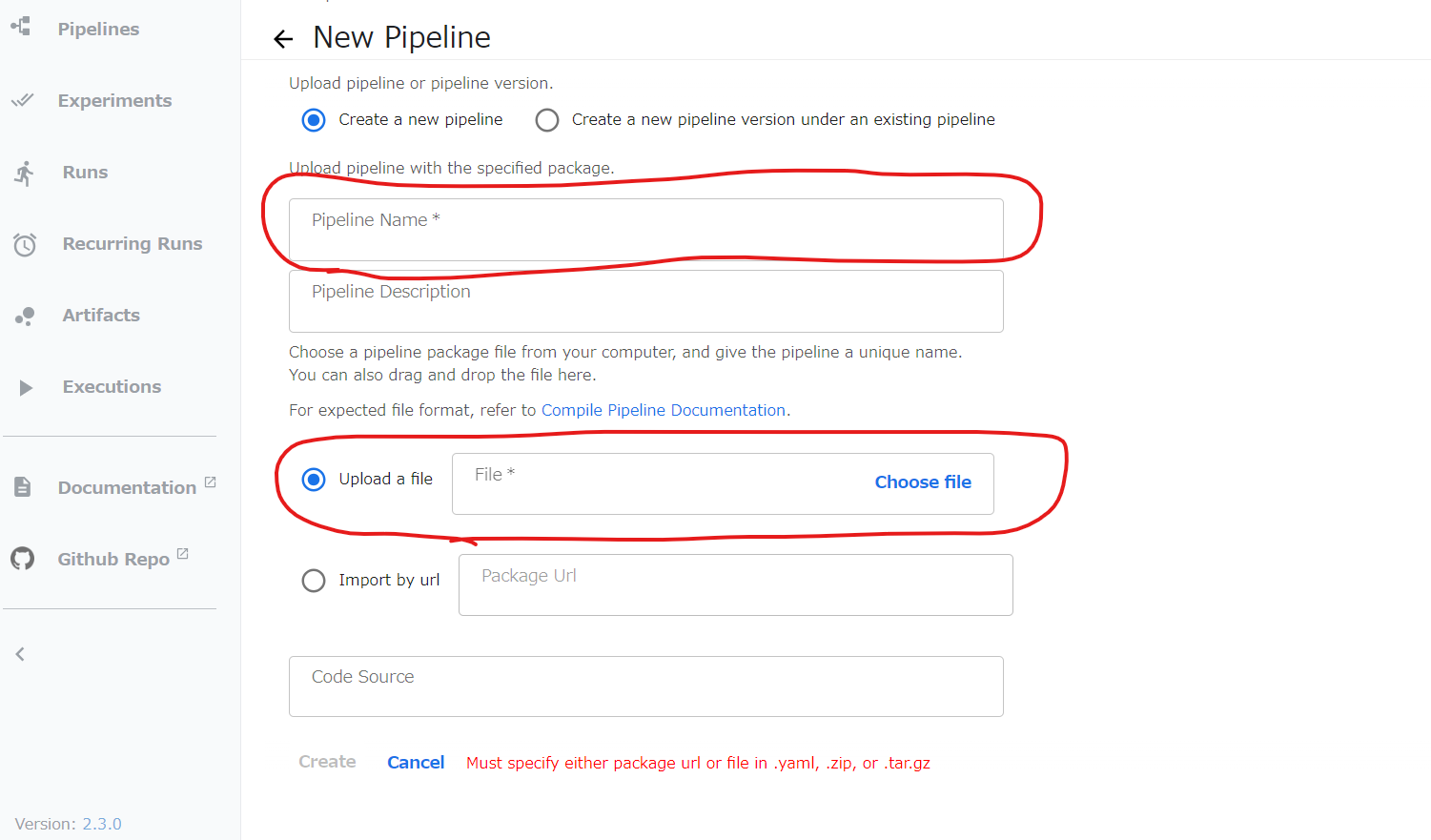
Pipelineの名前を入れて、手順5で作成したtrainjobstart.yaml をアップロードする。最下部のCreateボタンを押す。
以降、6-1の手順と同じ
