1. はじめに
ディープニューラルネットワーク(DNNs)は、音声認識や視覚的物体認識といった難しい学習タスクで優れた性能を発揮してきました。しかし、その強力さにもかかわらず、DNN には長年の大きな制限がありました。それは、入力と出力の次元が固定されている必要がある ということです。
この制限は、機械翻訳(Machine Translation, MT)や音声認識、質疑応答(質問を表す単語の系列を、回答を表す単語の系列にマッピングする)のように、入力と出力がそれぞれ長さの異なる「可変長シーケンス(系列)」である問題を扱う上で大きな壁となっていました。
本記事で解説する Google の研究者による論文 「Sequence to Sequence Learning with Neural Networks」(2014年) は、この壁を LSTM(Long Short-Term Memory) という強力なツールを使って打ち破った記念碑的な論文です。
この記事を読むことで、以下のことが分かります。
- 可変長系列の学習における従来の課題と、なぜ LSTM が自然な選択肢だったのか
- シンプルな「Encoder-Decoder」構造の仕組みと、その成功の鍵となった 入力系列の「逆順化」というトリック
- 大規模な英仏機械翻訳タスクで、純粋なニューラルネットが統計的機械翻訳(SMT)ベースラインの BLEU スコア(33.30)を上回る 34.81 を達成したという歴史的背景
系列学習の新しい扉を開いた「Seq2Seq」の基礎を、見ていきましょう!
2. 目次
本記事は、機械学習の知識を前提としつつも、数式や専門用語は極力直感的に理解できるよう解説していきます。
- 1・2:導入と構成
- 3:背景・課題
- 4:提案モデル(Encoder-Decoder)
- 5:トリック(入力系列の逆順化)
- 6:実験結果と分析(表・図の解説付き)
- 7:まとめ
3. なぜ Seq2Seq が必要なのか?:可変長シーケンスの課題
DNN の強力さと系列タスクの重要性
ディープニューラルネットワーク(DNNs)は、大規模なラベル付き訓練データがあれば、複雑な関数を学習し、優れた結果を出すことができます。しかし、その柔軟性と力強さにもかかわらず、DNN は 入力とターゲットが固定次元のベクトルで表現できる問題にしか適用できません。
一方で、機械翻訳、音声認識、質疑応答といった重要なタスクは、入力系列(例:英語文)と出力系列(例:フランス語文)の長さが事前にわからず、可変長になっています。この「系列の長さが変わる」という性質が、従来の DNN にとって大きなハードルでした。
従来の RNN によるアプローチの難しさ
RNN(Recurrent Neural Network, 再帰型ニューラルネットワーク)は、系列を扱う自然な拡張です。ただし、
- 入出力の系列長が異なり
- 対応関係(アライメント)が複雑で非単調
のような問題に対して、どう RNN を適用すればよいか は明確ではありませんでした。
一つのアイデアとして、
- エンコーダRNN:入力系列全体を固定サイズのベクトルにマッピングし、
- デコーダRNN:そのベクトルからターゲット系列を生成する
という方法があります。原理的には正しいのですが、ここで問題になるのが 長期依存性 です。入力の最初の単語(例:A)と、対応する出力単語(例:W)の間に、エンコードとデコードの全ステップが挟まる ため、「最初の入力」と「最初の出力」のあいだの距離がとても長くなります。 このような長期依存性は、標準的な RNN の学習を非常に難しくします。
この課題を解決するため、本論文では、長期の時系列依存性をうまく学習できることで知られる LSTM(Long Short-Term Memory) を採用しています。
4. 提案モデル:Encoder-Decoder としての深層 LSTM
4.1 可変長を固定ベクトルに「圧縮・復元」する
Seq2Seq アプローチの核となるアイデアは次の 2 ステップです。
-
エンコーダ(Encoder)
可変長の入力系列を読み込み、その情報を凝縮した 固定次元のベクトル表現 を作る。 -
デコーダ(Decoder)
その固定ベクトルを起点として、ターゲットとなる出力系列を 1 単語ずつ生成する。
「可変長 → 固定長 → 可変長」という流れです。
ここで、両方に LSTM を使うことで、長い依存関係も扱えるようにしています。
4.2 エンコーダ LSTM とデコーダ LSTM
記号を整理します。
-
入力系列:
$$\mathbf{x} = (x_1, x_2, \dots, x_T)$$
-
出力系列:
$$\mathbf{y} = (y_1, y_2, \dots, y_{T'})$$
ここで、両系列の長さ $T$ と $T'$ は一般に異なる(可変長)。また、各文の末尾には特別な終端トークン $\mathrm{EOS}$ を必ず付ける
このとき、提案モデルは以下のように動きます。
-
エンコーダ LSTM
- 入力系列 $\mathbf{x}$ を先頭から 1 単語ずつ読み込み、隠れ状態を更新していく。
- 最後の隠れ状態を$\mathbf{v}$とし、これを「文全体の意味を持つ固定長ベクトル」とみなす。
-
デコーダ LSTM
-
初期隠れ状態に $\mathbf{v}$ をセットする。
-
開始トークンとして $\mathrm{EOS}$(あるいは専用の開始トークン)からスタートし、
$$y_1, y_2, \dots, y_{T'}, \mathrm{EOS}$$
を 1 単語ずつ生成していく。
-
デコーダは「$\mathbf{v}$ に条件付けられた言語モデル」のように振る舞う。
-
実際には、著者らは入力系列用と出力系列用で 別々の LSTM を使い階層を 4 層に深くした LSTM を採用することで、浅い LSTM よりも有意に性能が向上することを示しています。
4.3 Figure 1:モデル全体像
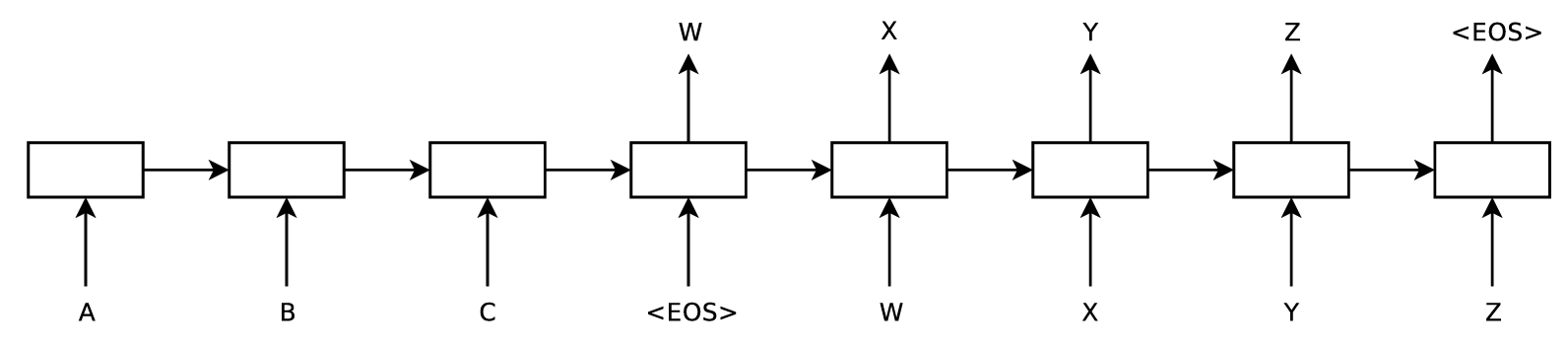
(Figure 1:Seq2Seq モデルの概要)
Figure 1は、モデルが入力文を読み込み出力文を生成する一連の流れを示しています。
-
左側(エンコード)
LSTM が入力単語(例:C, B, A)を順番に読み込み、最終的にベクトル表現 $\mathbf{v}$を得ます。 -
右側(デコード)
別の LSTM が $\mathbf{v}$ を初期状態として、出力単語(W, X, Y, Z)を 1 つずつ生成します。 -
停止条件
特別な終端トークンEOSを生成した時点で出力を止めることで、任意長の系列に対応します。
ここで重要なのは、入力文「ABC」を逆順(C, B, A)で読むようにしている 点です。
この「逆順化」が、後で述べる性能向上の鍵になっています。
4.4 条件付き確率の定義
ここからは、モデルの確率的な定式化を整理します。
(1) 目標:条件付き確率を学習する
モデルのゴールは、入力系列 $\mathbf{x}$ が与えられたときの、出力系列 $\mathbf{y}$ の条件付き確率
$$
p(\mathbf{y} \mid \mathbf{x})
= p(y_1, \dots, y_{T'} \mid x_1, \dots, x_T)
$$
をうまく近似することです。
(2) 連鎖律による分解
この確率は、連鎖律(chain rule) によって、
$$
p(\mathbf{y} \mid \mathbf{x})
= \prod_{t=1}^{T'} p\bigl( y_t \mid \mathbf{x}, y_1, \dots, y_{t-1} \bigr)
$$
と分解できます。
直感的には、「これまでの出力単語と入力文が分かっているときに、次の単語が何になるか」の確率を掛け合わせたものです。
(3) LSTM による具体的な表現
Seq2Seq では、入力文全体の情報はベクトル $\mathbf{v}$ に集約されているので、
$$
p(\mathbf{y} \mid \mathbf{x})
= \prod_{t=1}^{T'} p\bigl( y_t \mid \mathbf{v}, y_1, \dots, y_{t-1} \bigr)
\tag{1}
$$
と書き換えられます。
- 各 $p(y_t \mid \dots)$ は、「単語語彙全体」に対する Softmax 分布として表現されます。
- $\mathrm{EOS}$ を出力できるようにしておくことで、任意長の系列に対する確率分布 を定義できます。
(4) 学習とデコードの式
学習時には、パラメータ $\theta$ をもつモデル $p_\theta(\mathbf{y} \mid \mathbf{x})$ に対し、訓練データ集合 $\mathcal{D}$ に対する対数尤度を最大化します。
$$
\max_\theta
\sum_{(\mathbf{x}, \mathbf{y}) \in \mathcal{D}}
\log p_\theta(\mathbf{y} \mid \mathbf{x})
$$
予測(翻訳)時には、入力文 $\mathbf{x}$ が与えられたときに、最も確からしい出力系列 $\hat{\mathbf{y}}$ を
$$
\hat{\mathbf{y}}
= \arg\max_{\mathbf{y}} \log p_\theta(\mathbf{y} \mid \mathbf{x})
\tag{2}
$$
として求めます。
実際には、すべての文候補を総当たりすることはできないので、後述するビームサーチで近似的に探索します。
5. 性能を劇的に向上させた「たった一つのトリック」
この Seq2Seq モデルが、これまでの研究者たちが苦戦していた
- 長い文の翻訳
- RNN の訓練の難しさ
を克服できた大きな理由は、入力文の単語順序を逆にする という、非常にシンプルな工夫にあります。
5.1 長期依存性の課題再訪
Figure 1の構造からも分かるように、入力文を固定ベクトルに圧縮し、そこから出力を生成する場合、入力の最初の単語(例:A)と対応する出力の最初の単語(例:W)の間には、エンコードとデコードの全ステップが挟まるため、非常に長い距離が生じます。
これは、最小時間差(minimal time lag) が大きい状態と見ることができます。
5.2 解決策:入力文の単語順序を逆にする
著者らは、訓練データ・テストデータの両方において、
- ソース文(入力側)だけ の単語順序を逆にする
- ターゲット文(出力側)はそのまま
という前処理を行いました。
例:
- 通常:
a, b, c → α, β, γ - 逆転後:
c, b, a → α, β, γ(α, β, γ は a, b, c の翻訳)
5.3 この工夫がもたらす効果
このような単純な操作が効く理由として、以下の3つが挙げられます。
-
短期依存性の導入
逆順にすることで、ソース文の先頭単語がターゲット文の先頭単語の近くに現れるようになり、短期的な依存関係 が増えます。 -
最小時間差の短縮
元々遠く離れていた「対応する単語同士」が、時間的に近接する頻度が増えるため、最小時間差 が大きく減少します。 -
最適化の容易化
その結果、SGD が「入力と出力の対応関係」を見つけやすくなり、勾配伝播が有効に働く ようになります。
実際、このトリックを入れることで、
- テスト時のパープレキシティ:5.8 → 4.7 に大きく改善
- BLEU スコア:25.9 → 30.6 に向上
と、かなり大きな差が出ています。
6. WMT'14 機械翻訳タスクでの結果
ここからは、論文に出てくる実験結果を見ていきます。
6.1 実験設定と評価指標(BLEU スコア)
-
データセット:WMT'14 英語 → フランス語
- 1200 万文(約 3.48 億フランス語語、約 3.04 億英語語)
-
モデル規模:
- 4 層の深層 LSTM
- 各層 1000 セル
- 単語埋め込み 1000 次元
⇒ 1 モデルあたり約 3 億 8400 万パラメータ
-
語彙サイズ:
- 入力側:16 万語
- 出力側:8 万語
- それ以外の単語は
UNKにまとめる
- 評価指標:BLEU スコア(multi-bleu.pl による標準的評価)
6.2 Table 1:LSTM 単体での翻訳性能
Table 1 では、LSTM を単体で翻訳器として用いたときの BLEU スコアを比較しています。

(Table 1:WMT'14 英仏翻訳(直接翻訳)の BLEU スコア)
ポイント:
- 逆転入力なしの LSTM(順方向)は SMT よりかなり弱い。
- 逆転入力+アンサンブル+ビームサーチにより、SMT ベースライン(33.30)を上回る 34.81 を達成。
6.3 Table 2:SMT の 1000-best を再スコアした場合
Table 2 では、既存 SMT の 1000-best を LSTM で再スコアした場合の性能をまとめています。

(Table 2:SMT と LSTM を組み合わせた場合の BLEU スコア)
ポイント:
- 純粋なニューラル翻訳(34.81)でも SMT を上回る
- SMT の 1000-best を LSTM で再スコアすることで 36.5 に達し、当時の最高結果 37.0 に肉薄した
6.4 Figure 3:文長/語彙頻度と性能の関係
Figure 3 では、文の長さや含まれる単語のレア度が変わったときに、翻訳性能(BLEU)がどう変わるかをまとめています。
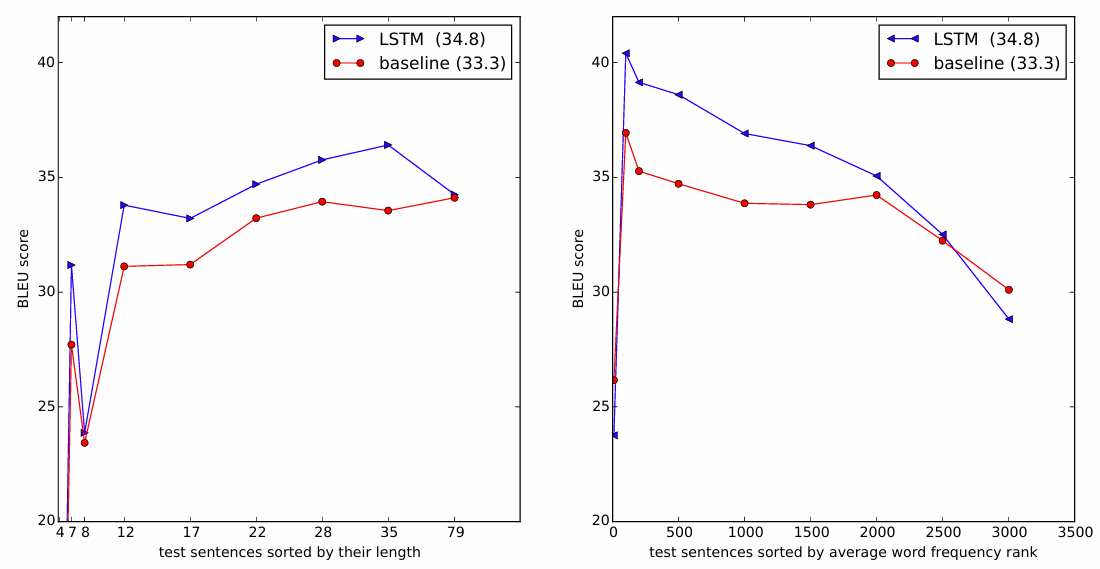
(Figure 3:文長および単語頻度に対する BLEU スコア)
ポイント:
-
左プロット(文長 vs BLEU)
- X 軸:テスト文を長さでソートしたインデックス(実際の単語数もマーキング)
- 結果:35 単語未満の文では性能低下がほとんどなく、最も長い文でもごくわずかな低下しかない。
-
右プロット(単語頻度 vs BLEU)
- X 軸:文中の単語の平均頻度順位でソートしたインデックス
- 結果:よりレアな単語を含む文で少しずつ性能が落ちるが、極端に悪化しているわけではない。
重要なのは、逆転入力+LSTM によって「長い文でもそこまで性能が落ちない」ことが明示的に示されている点です。
6.5 Table 3:長い翻訳例
Table 3 では、特に長い文の具体例を、LSTM による翻訳と正解翻訳を対比して示しています。
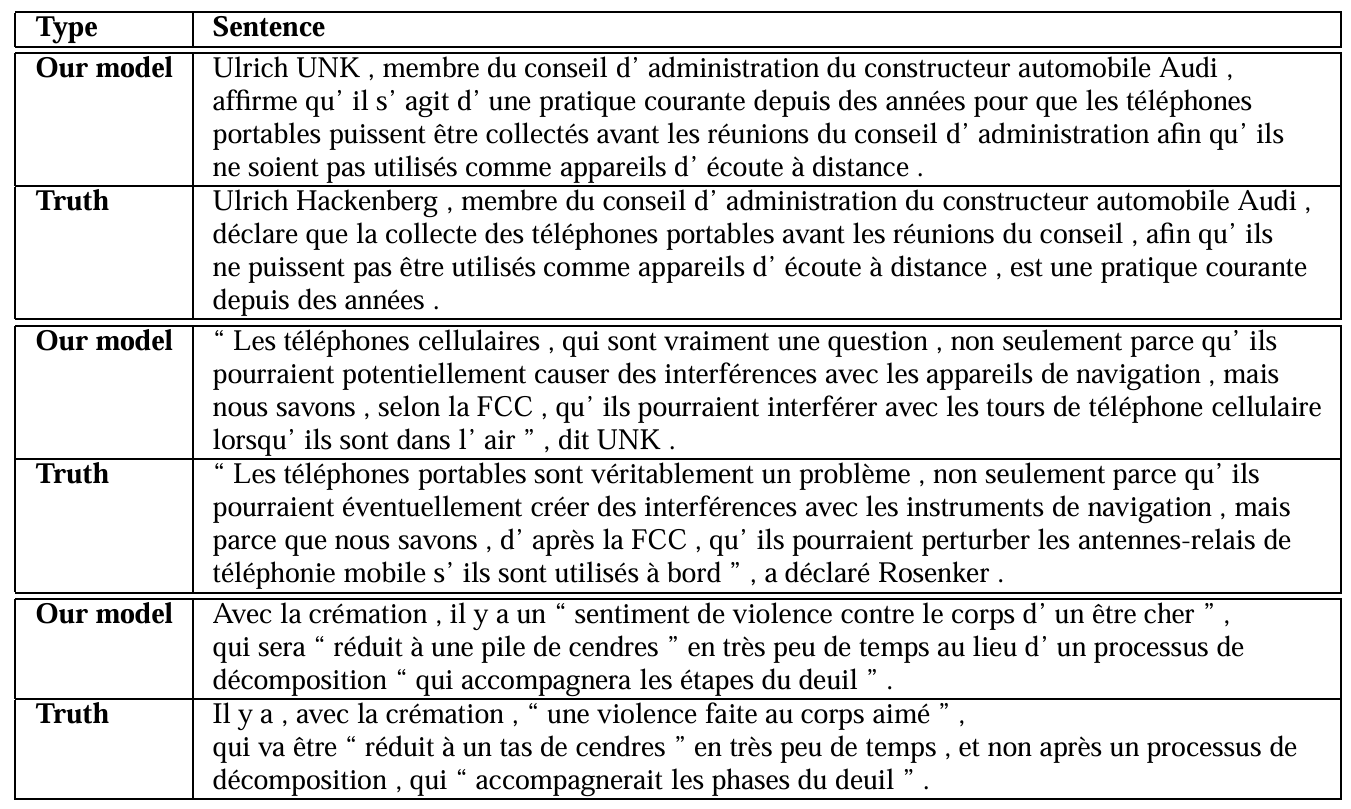
(Table 3:特に長い文におけるLSTMによる翻訳と正解翻訳の比較)
論文では、Google 翻訳で確認すれば、LSTM の訳もかなり自然であることが分かる とコメントされています。
6.6 学習された文ベクトルの可視化(PCA)
最後に、Figure 2 です。これは、LSTM が学習した「固定長ベクトル表現」がどのような性質を持っているかを可視化した図です。
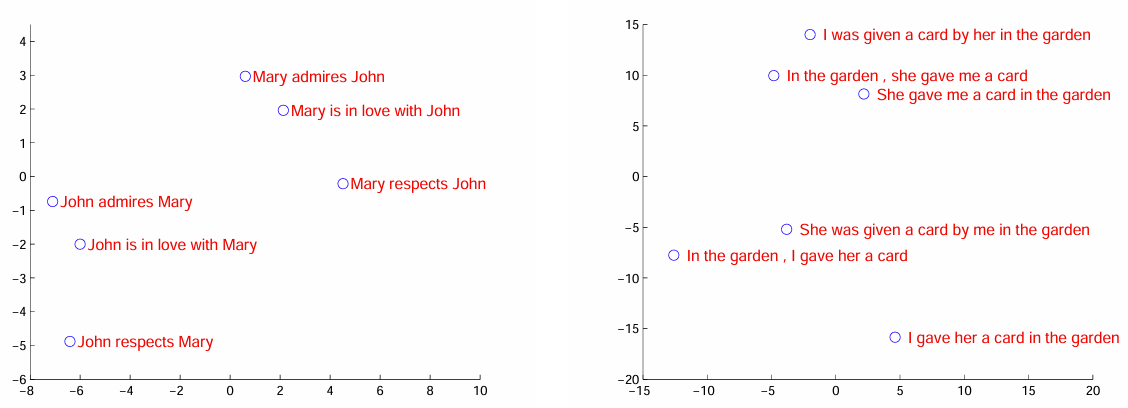
(Figure 2:学習された固定長ベクトル表現の可視化)
ポイント:
- 各点:あるフレーズを入力したときの 最終隠れ状態ベクトル を PCA で 2 次元に落としたもの
- 左側クラスタ例:
John respects MaryとMary respects Johnのように、「語順が違うと意味も変わる」ペア - 右側クラスタ例:能動態/受動態の違いを含む文ペア(意味はほぼ同じ)
この図から読み取れることは:
-
語順への感度:
語順が変わると、ベクトル位置もかなり変化する → Bag-of-Words 的な表現ではなく、構造を見ている。 -
態(Voice)に対する相対的不変性:
能動態と受動態の違いはある程度吸収されており、「意味」が近い文は近くに配置される。
つまり、LSTM が「文の意味」をそこそこうまく固定長ベクトルに押し込めている ことが分かります。
7. まとめ
-
Seq2Seq 構造:
LSTM ベースのエンコーダとデコーダを組み合わせ、可変長の入力系列を固定長ベクトルに圧縮し、そこから出力系列を生成するエンドツーエンド学習を実現。 -
深層 LSTM の採用:
4 層の深層 LSTM を用いることで、単層よりも大幅な性能向上。 -
決定的なトリック:入力逆転:
ソース文の単語順序を逆転させることで短期依存性を増やし、最適化を著しく簡単にし、パープレキシティと BLEU を大きく改善。 -
ベンチマーク突破:
5 つの逆転 LSTM のアンサンブルにより、WMT'14 英仏 MT タスクで SMT ベースライン(33.30)を上回る 34.81 の BLEU を達成。 -
長文に対する強さ:
Figure 3 に示されるように、35 語程度まではほぼ性能低下なし、非常に長い文でも緩やかな低下に留まる。 -
意味表現としての文ベクトル:
Figure 2 から、文ベクトルは語順には敏感で、能動/受動の違いには比較的ロバストであることが分かる。
8. おわりに
この論文が示したのは、
「比較的シンプルな Encoder-Decoder+LSTM という構成でも、データ変換(入力逆転)と大規模学習を組み合わせれば、大規模な機械翻訳タスクで SMT を上回れる」
という、当時としてはかなり衝撃的な事実でした。
特に、モデルの複雑化だけでなく入力系列のエンコーディング(前処理)の工夫が、学習のしやすさと最終性能に大きく影響する、というメッセージは非常に示唆的です。
この Seq2Seq の枠組みは、その後のAttention機構・Transformer・現在の大規模言語モデル(LLM)へと連なる流れの中で、「系列を系列にマップする」という問題をニューラルネットで解く標準の土台 となりました。