今回紹介する解析の大まかなフロー
・女性声優ネットワークを構築して可視化
・ネットワーク情報を使って似ている声優さんをクラスタリングしてカテゴリ化してみる
・カテゴリ化した結果をCytoscapeで可視化する
どうも、bamboo-novaです。Qiitaでは主にネタ解析を放り込んでいきます。
私の真面目な話や解析などについて気になる方は、こちらを参考にしてください(避難場所)
また、今までの一連の手順をまとめたソースコードをGithubに置いたので、もし良かったら参考にしてください!
前回は、声優ネットワーク解析を行う前段階として、声優さんの名前と性別リストをスクレイピングして、リストに載っている声優さんのWikipediaテキスト情報からword2vecで学習モデルを作成しました。
似ている声優同士をネットワーク分析で可視化してクラスタリングする(1/2)
今回は、実際に学習したモデルを用いて声優同士のネットワークを作って、さらにそこから細かく声優さんをカテゴリ化します。ネットワークの可視化とクラスタリングは、本記事では20代の女性声優のみの関係性を解析してますが、10~30代の声優さんを含めてまとめて解析することもできるので、興味がある人は試してみてください!
また、学習モデル自体は10~30代の女性声優のプロフィール情報を元に作成しましたが、最初は20代の女性声優のネットワークを可視化してカテゴリ化してみたいと思います。
女性声優ネットワークを構築して可視化
まず初めに、必要なモジュールを読み込んで、前回の記事の中でword2vecで学習されたモデルを読み込みます。
# 必要なモジュールを読み込む
import numpy as np
import pandas as pd
import pickle
import networkx as nx
import matplotlib.pyplot as plt
%matplotlib inline
# 前回word2vecを用いて作成した学習モデルを読み込む
with open('mecab_word2vec_seiyu.dump', mode='rb') as f:
model = pickle.load(f)
# ネットワークの表示のさせ方を工夫する
plt.style.use('seaborn')
# 日本語が豆腐になる文字化け対策
plt.rcParams['font.family'] = 'IPAexGothic'
上記の部分で書いてある文字化け対策については、以下のサイトに対応方法が載っているので、下記のURLを参考にして文字化け対策を行って見てください(ちなみに、私が回答しております)。
次に、前回の記事の中でスクレイピングで取得したseiyu20.csvを読み込んで、20代の女性声優さんの名前のリストを取り出します。
df = pd.read_csv('seiyu20.csv')
name = df[df.Gender=='女性']
white_list = name.Name
そして、各声優さんの名前の対応するword2vecの単語ベクトルを抽出して、全ての声優さん同士の組み合わせについて単語ベクトルの相関係数を算出します。
output = []
label = []
for name in white_list:
try:
vector = model.wv[name]
output.append(vector)
label.append(name)
except:
continue
res = np.corrcoef(output)
これで、各声優さん同士の相関行列が完成しました。
では、ついに声優ネットワークを可視化します。
# networkxに引き渡すエッジリストを準備
edge_lists = []
df = pd.DataFrame(res)
edge_name = label
df.index = df.columns = edge_name
# 相関係数DFより右上の三角行列およびに 0.05以下のデータをマスク
tmp_df = df.mask(np.triu(np.ones(df.shape)).astype(bool) | (df < 0.05))
# エッジリストを生成
edge_lists = tmp_df.stack().reset_index().apply(tuple, axis=1).values
G = nx.Graph()
G.add_weighted_edges_from(edge_lists)
# 描画の準備
plt.figure(figsize=(8,8)) #描画対象に合わせて設定する
pos = nx.circular_layout(G)
line_width = [d['weight']*10 for u,v,d in G.edges(data=True)]
nx.draw_networkx(G, pos=pos, font_size=10, node_color='gray', width=line_width, font_family='IPAexGothic')
plt.savefig('netres.png')
出力結果:

似ている声優同士(相関係数が高い声優同士)ほどエッジが太くなるように可視化していますが、よくみると太いところがはっきりしているところがちらほらあるので、何かしら関係性がありそうですから、ランダムではなさそうですね!
上記のソースコードの途中でtmp_df = df.mask(np.triu(np.ones(df.shape)).astype(bool) | (df < 0.05))のようにして、相関係数の閾値でフィルタリングをしています。これは、ネットワークのクラスタリング係数を元に調整しました。
クラスタリング係数(0~1の間を取る係数)とは、各ノードについて(あるノードと隣接するノード同士のリンクの数) / v(v-1) /2の関係式を算出して、それらを全ノードで平均したものになります。このクラスタリング係数が高いほどネットワークの密度が高いことを示しています。クラスタリング係数は、以下のWikipediaの説明などをみると、現実世界のネットワークで確認されているクラスタリング係数は0.1~0.7くらいと言われています(複雑ネットワーク
)。ただ、今回はネットワークのノードの数もそこまで多くないのと元々のテキストデータの量が少ないこともあるので、0.4~0.7くらいに調整した方がうまくいくと思います。私も実際にネットワーク分析をするときはクラスタリング係数を元に閾値などをチューニングして出力することが多いです。
今回は、以下のクラスタリング係数で調整しています。
print(nx.average_clustering(G))
0.610103228782055
せっかくネットワークとして可視化できましたし、PageRank解析でもやってみます。テキストデータをword2vecで学習させたものを適用しているので、やっていることはPageRank解析というよりもLexRankアルゴリズムに近いと思います。解釈としては、可視化したネットワークを要約している(構成の上で欠かせない)女性声優さんほど高い値を持っていることになると思います。
LexRankの仕組みについては以下のURLに詳しく載っているので、よければ参考にしてみてください。
Python: LexRankで日本語の記事を要約する
pr = nx.pagerank(G)
pos1 = nx.spring_layout(G)
# 可視化
plt.figure(figsize=(30, 30))
nx.draw_networkx_edges(G, pos1)
nx.draw_networkx_nodes(G, pos=pos1, node_color=list(pr.values()), cmap=plt.cm.Reds, font_family='IPAexGothic', node_size=[100000*v for v in pr.values()])
nx.draw_networkx_labels(G,pos1,font_size=20, font_family='IPAexGothic')
plt.axis('off')
plt.show()
# PageRank値が高かった上位10名の声優さんを表示してみる。
score_sorted = sorted(pr.items(), key=lambda x:-x[1])
print(score_sorted[0:20])
出力結果:
PageRankの値が高かった声優さん上位20名
[('大橋彩香', 0.04555164528689211),
('山崎エリイ', 0.039995796742290854),
('木戸衣吹', 0.03944625539215552),
('東山奈央', 0.03748530983574666),
('小倉唯', 0.036855264907774486),
('夏川椎菜', 0.03677562557911518),
('麻倉もも', 0.034883881713288184),
('三澤紗千香', 0.03461691295075832),
('田所あずさ', 0.03458330057908542),
('内田真礼', 0.034217274567621005),
('豊田萌絵', 0.033018028594089754),
('寿美菜子', 0.03235768418454441),
('石原夏織', 0.03065891275211937),
('雨宮天', 0.030072491383579297),
('上坂すみれ', 0.02920698033366847),
('Machico', 0.028396698868023),
('愛美', 0.02759156041213482),
('水瀬いのり', 0.027163302263303015),
('伊藤美来', 0.026500204152951186),
('山崎はるか', 0.02511585403440591)]
ネットワーク情報を使って似ている声優さん同士をクラスタリングしてカテゴリ化してみる
最後に、声優さんのカテゴリ化を行います。今回は、Louvainと呼ばれるクラスタリング手法を使用します。Louvainはmodularityに基づいたクラスタリング手法で、「ネットワークの結合度合い」を表す値を定義して、それを最適化するための手法です。実際には局所的な最適化を求めるための手法となっていて、式: クラスタ内のエッジの割合-クラスタ間のエッジの割合を計算することによって実現しています。
ネットワークの指標やクラスタリングなどの手法は、東大の松尾研究室のGithubの説明に大まかに載っているので良かったらこちらを参考にしてみてください。
Louvainの解析についてはcommunityをpipでインストールすれば簡単に解析することが可能なので、このモジュールを使用してLouvainによるネットワーククラスタリングを行います。また、クラスタリングした結果を.graphmlの形で保存して、cytoscapeで綺麗に可視化したいと思います。
まずは、Louvainでクラスタリングを実行します。
import community
partition = community.best_partition(G)
size = float(len(set(partition.values())))
pos = nx.spring_layout(G)
count = 0.
for com in set(partition.values()):
count += 1.
list_nodes = [nodes for nodes in partition.keys() if partition[nodes] == com]
nx.draw_networkx_nodes(G, pos, list_nodes, node_size=20, node_color = str(count/size))
partition = community.best_partition(G)
labels = dict([(i, str(i)) for i in range(nx.number_of_nodes(G))])
nx.set_node_attributes(G, labels,'label')
nx.set_node_attributes(G, partition, 'community')
# nx.write_gml(G, "community.gml") 文字化けするので下記の形で保存します。
nx.write_graphml(G, "community.graphml", encoding='utf-8')
cytoscapeで表示する前に、ちょっとクラスタごとの声優さんをみてみましょう。
まず、一つ目のクラスタは...
# 一つ目のクラスタ
for k,v in partition.items():
if int(v)==0:
print(k)
# 出力結果:
山崎エリイ
木戸衣吹
大橋彩香
田所あずさ
Machico
M・A・O
見事にホリプロ声優+αで固まっていることが確認できました!
https://moca-news.net/article/20140226/2014022614590a_/01/
続いて、二つ目のクラスタをみてみます。
# 二つ目のクラスタ
for k,v in partition.items():
if int(v)==1:
print(k)
# 出力結果:
諸星すみれ
夏川椎菜
秋奈
麻倉もも
雨宮天
愛美
佐々木未来
倉口桃
森綾香
徳井青空
こちらは、TrySailやミルキィホームズで主に固まっている印象があります。
どうやら、クラスタリングはちゃんと機能しているっぽいです!!
では、最後にCytoscapeでカテゴリ化した声優ネットワークを綺麗に可視化してみたいと思います。
カテゴリ化した結果をCytoscapeで可視化する
まず、Cytoscapeをインストールします。
Cytoscapeはネットワーク可視化ツールで、主にバイオインフォマティクスを目的として作られたツール見たいですが、別にバイオインフォマティクス以外の目的にも十分活用できます。凄い自由が効くのでとても便利です。
インストールができたら、実際に開いて、ツールバーの[File->Import->Network->File]と進んで、先ほど保存したネットワークファイルを開きます。
上記の状態だと綺麗とは言えないので、まずはクラスタごとに色分けするところから始めます。
そこで、左側にある「Style」タブをクリックします。そして、そこにある「Fill Color」を開きます。すると、ColumnとMapping Typeが表示されるので、Columnについては「community」、Mapping Typeについては「Disctete Mapping」を選択します。
すると、以下のような画面が出てくると思うので、それぞれ色を指定していきます。
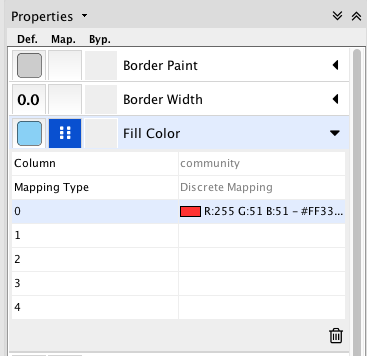
指定ができたら、今度は大まかにレイアウトを変えて見ましょう。ツールバーのLayout->yFiles Layoutsやそこにある他のオプションから様々なレイアウトを選択できるので、自分にとって見やすいレイアウトを選んで、あとはマウスでドラッグして移動させて調節してみてください。
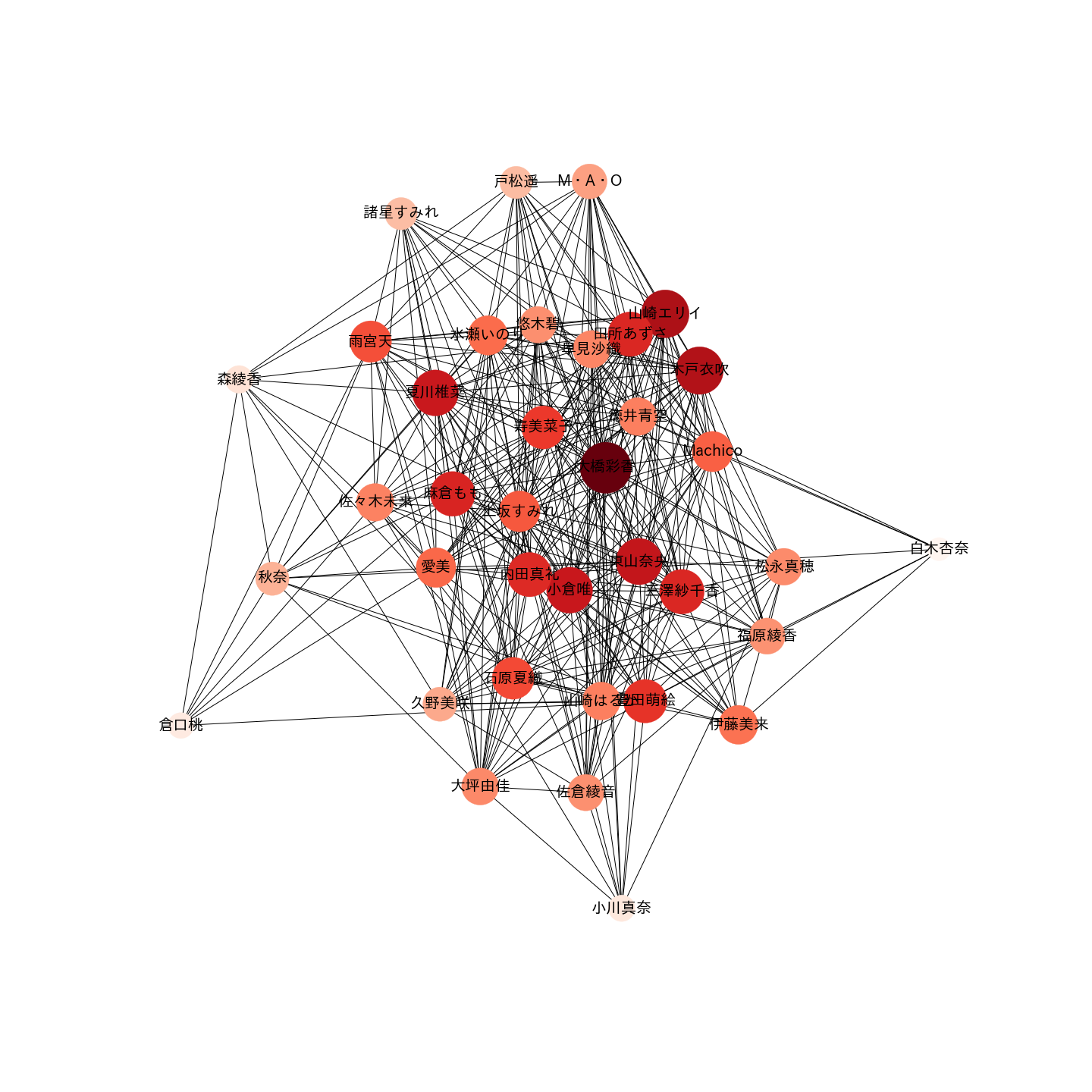
ちなみに、自分の声優ネットワークの結果はこんな感じです(前のは見づらかったとの要請があったので修正しました)。
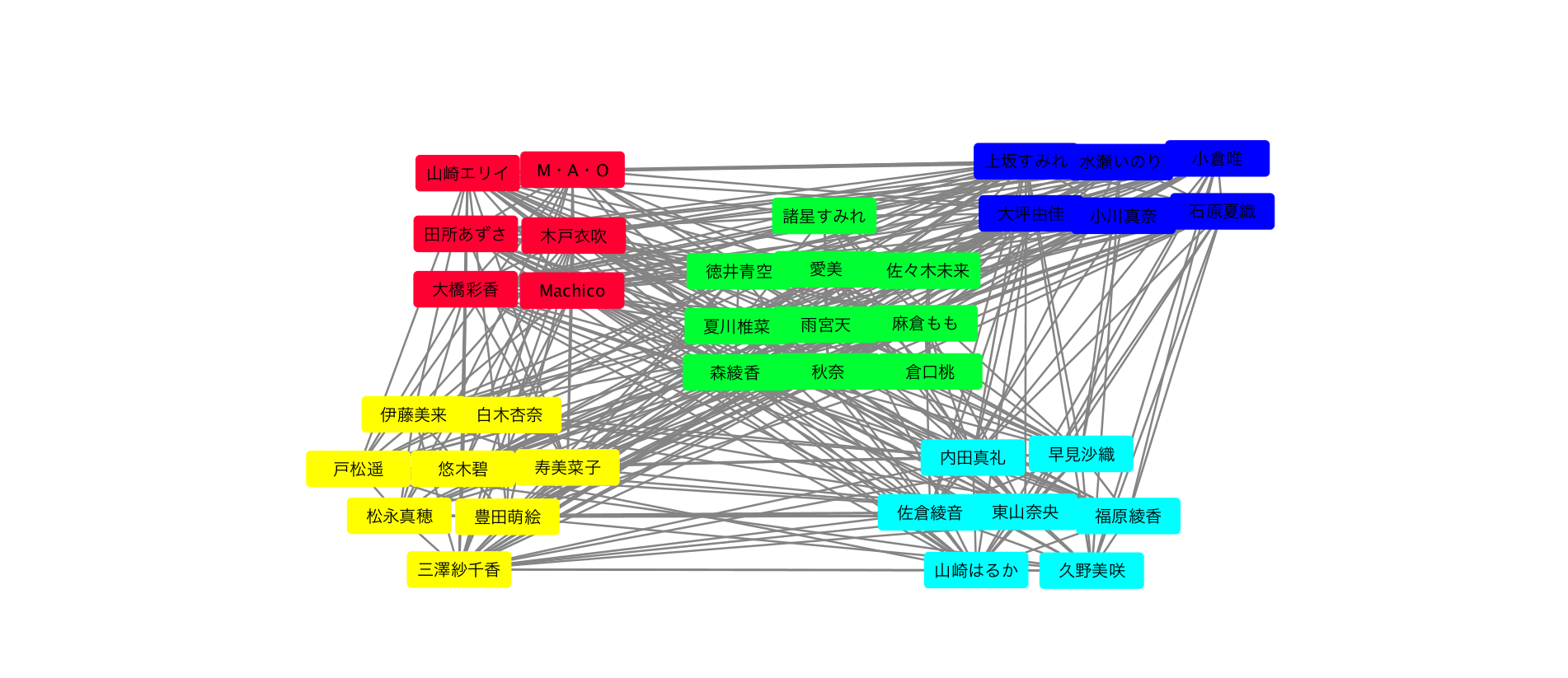
結果的に20代の女性声優は、Wikipediaのプロフィール情報を元にしてカテゴリ化すると、大きく5つのクラスタに分けられ、
・ホリプロ声優を中心としたクラスタ(大橋彩香さん、田所あずささんなど)
・TrySail,ミルキィホームズを中心としたクラスタ(雨宮天さん、愛美さんなど)
・キングレコードの三人組とその人たちと関係がある人で構成されたクラスタ(水瀬いのりさん、上坂すみれさんなど)
・実力派っぽい人で構成されたクラスタ?(早見沙織さん、東山奈央さんなど)
・アイドル色が強そうなクラスタ?(悠木碧さん、伊藤美来さんなど)
のような形で大別できたと思います。
まとめ
今回は、各声優さんのウィキペディアにあるプロフィール情報を元にして、20代女性声優さん同士の関係性をネットワーク分析で可視化しました。また、クラスタリングを行い、20代女性声優さんのカテゴリ化を実現し、Cytoscapeで結果を可視化しました。実際に趣味でデータを持ってきて解析するのは初めてなので不安でしたが、それっぽい結果が出てよかったです!
Qiitaではこのようなネタ解析を時間ができたときに投入していく予定なので、もし要望とかあればコメント頂ければと思います!
また、今後の励みにもなるので、面白かったと思ったら「いいね!」をよろしくお願い致します笑
その他の参考資料
python-louvainでクラスタリング
TwitterのフォロワーをNetworkX, Cytoscapeで可視化