この記事で紹介する大まかなフロー
・声優さんの名前と性別のリストをスクレイピングして取得
・リストに含まれる声優さんのWikipediaのテキスト情報をmecabで分かち書きしてword2vecで学習
・word2vecで学習したモデルを使って単語分析で遊んでみる
次回紹介する解析の大まかなフロー
・女性声優ネットワークを構築して可視化
・ネットワーク情報を使って似ている声優さん同士をクラスタリングしてカテゴリ化してみる
初めまして、bamboo-novaと申します。Qiitaでは主にネタ解析を放り込む予定です。真面目な話や解析などは「hatena blog」で書いてるので、そちらを参照してください。あと、NLPは全く専門ではないので、稚拙なコードだと思いますが温かい目で見守ってください...!
初回の投稿ですが、第一回目のネタ解析として声優ネットワーク分析をしてみました。
今回は、声優さんのWikipediaの記事を持ってきて、そこの文章情報から似ているor関連している声優同士のネットワークを作って、さらにそこから細かくクラスタリングすることにしました。
今回は、10~30代の女性声優に限定して学習モデルを作って解析をします。
追記)
今までの一連の手順をまとめたソースコードをGithubに置いたので、もし良かったら参考にしてください!
bamboo-nova/seiyu_network
まず、女性声優さんのリストを取得する。
以下のサイトをスクレイピングして、声優さんの名前のリストを取得します。年齢が公開されていない声優さんについてはどうやらこのサイトのリストに含まれないので、有名だったとしても解析で表示されない方もいると思います。
まず、必要なモジュールを呼び出します。
import MeCab
import codecs
import urllib
import urllib.parse as parser
import urllib.request as request
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
from gensim.models import word2vec
import re
# .parseToNodeする方としない方で分けました。
mecab = MeCab.Tagger('-Owakati -d /usr/local/mecab/lib/mecab/dic/mecab-ipadic-neologd')
title = MeCab.Tagger('-d /usr/local/mecab/lib/mecab/dic/mecab-ipadic-neologd')
指定したURLの情報を取得します。
url = "http://lain.gr.jp/voicedb/individual/age/avg/10"
response = requests.get(url)
response.encoding = response.apparent_encoding
soup10 = BeautifulSoup(response.text, 'html.parser')
url = "http://lain.gr.jp/voicedb/individual/age/avg/20"
response = requests.get(url)
response.encoding = response.apparent_encoding
soup20 = BeautifulSoup(response.text, 'html.parser')
url = "http://lain.gr.jp/voicedb/individual/age/avg/30"
response = requests.get(url)
response.encoding = response.apparent_encoding
soup30 = BeautifulSoup(response.text, 'html.parser')
まず、声優さんの名前を取得します。今回は、上記のソースコードのURLの中で、”voicedb/profile”を含むhref属性を持っているタグを10~30代の声優さんですべて取得します。下の画像は実際に上記のソースコードのURLの一つをChromeで検証した時のものですが、実際に”voicedb/profile”を含むhref属性の中に声優さんの名前がリスト形式で格納されていることが確認できるかと思います。
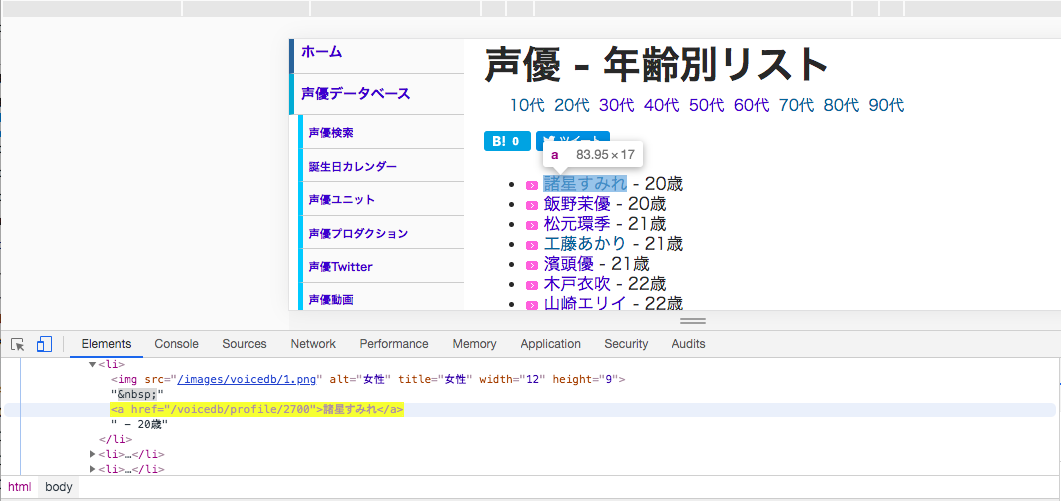
以下、名前を取得するソースコード
corpus=[]
name10 = soup10.find_all(href=re.compile("voicedb/profile"))
name20 = soup20.find_all(href=re.compile("voicedb/profile"))
name30 = soup30.find_all(href=re.compile("voicedb/profile"))
for p in name10:
corpus.append(p.text)
for p in name20:
corpus.append(p.text)
for p in name30:
corpus.append(p.text)
次に、性別を取得します。これも上記の検証した画像を見ると、imgタグ内のsrcとaltを取得すれば大丈夫そうなので、以下のようにして取得します。ちなみに、alt=img.attrs.get('alt', 'N')の部分ですが、alt 属性が存在する場合はその値、存在しない場合は 'N' が設定されます。
data = []
for img in soup10.find_all('img'):
data.append(dict(src=img['src'],
alt=img.attrs.get('alt', 'N')))
for img in soup20.find_all('img'):
data.append(dict(src=img['src'],
alt=img.attrs.get('alt', 'N')))
for img in soup30.find_all('img'):
data.append(dict(src=img['src'],
alt=img.attrs.get('alt', 'N')))
gender = []
for res in data:
for k, v in res.items():
if v == '女性' or v == '男性':
gender.append(v)
そして、名前と性別を統合したデータフレームをcsv形式で保存します。
name = pd.DataFrame(corpus)
gen = pd.DataFrame(gender)
res = pd.concat([name, gen],axis=1)
res.columns = ['Name','Gender']
res.to_csv('seiyu.csv')
取得したリストに含まれる女性声優さんのWikipediaのプロフィール情報を取得する。
では、保存したデータフレームの中から女性声優だけを選んで、Wikipediaで対象の声優さんのプロフィール情報を取得します。取得した情報は、pwiki.txtとして保存します。
df = pd.read_csv('seiyu.csv')
# Wikipediaのリンク
link = "https://ja.wikipedia.org/wiki/"
# 女性声優のみに対象を絞る
df_women = df[df.Gender=='女性']
keyword = df_women.Name
keyword = list(keyword)
corpus = []
for word in keyword:
# 声優の記事をダウンロード
try:
with request.urlopen(link + parser.quote_plus(word)) as response:
# responseはhtmlのformatになっている
html = response.read().decode('utf-8')
soup = BeautifulSoup(html, "lxml")
# <p>タグを取得
p_tags = soup.find_all('p')
for p in p_tags:
corpus.append(p.text.strip())
except urllib.error.HTTPError as err:
# Wikipediaに載っていない声優さんなどについてはエラーが出るので例外処理を加えています。
if err.code == 404:
continue
else:
raise
with codecs.open("pwiki.txt", "w", "utf-8") as f:
f.write("\n".join(corpus))
実際にテキストファイルを分かち書きして、word2vecとして学習モデルを保存する。
では、実際に取得したテキストデータを分かち書きします。今回はアニメの名前なども多いので、固有名詞に対してもちゃんと分かち書きされるように対応しています(例えば、ハイスクール・フリートとかだと固有名詞、組織の扱いになるので普通にparseToNodeすると*になってしまいます)。また、下の例のように、何故かmecab+neologdで「プリキュア」を分かち書きすると英語に変換されるみたいなので、こちらに関してもif文の条件分岐で対応して、英語に反応するようにしました(プリキュアに出演したことをステータスとしてプロフィールに載せている声優さんが非常に多かったので、特徴量の情報として無視できなかったのでこちらはちゃんと分かち書きが反映されるようにしました)。
node = title.parse('プリキュア')
node.split(",")[6]
# 出力結果: 'PulCheR'
以下、実際のソースコードです。まずは、テキストデータの前処理を行います。
fi = codecs.open('pwiki.txt')
result = []
fo = open('try.csv', 'w')
lines = fi.readlines()
for line in lines:
line = re.sub('[\n\r]',"",line)
line = re.sub('[ ]'," ",line) #全角スペースを半角に変換しないと、一部の名詞が複合名詞として抽出できない
line = re.sub('(年|月|日)',"",line)
line = re.sub('[0-9_]',"",line)
line = re.sub('[#]',"",line)
line = re.sub('[!]',"",line)
line = re.sub('[*]',"",line)
fo.write(line + '\n')
fi.close()
fo.close()
そして、前処理されたテキストデータを実際に分かち書きして、word2vecで学習します。今回はデフォルトのパラメータで学習しました。word2vecの説明についてはここでは省略させていただきますので、仕組みなどは以下のURLを参考にしてください。
Word2Vec:発明した本人も驚く単語ベクトルの驚異的な力
fi = open('try.csv', 'r')
fo = open('res.csv', 'w')
# line = fi.readline()
lines = fi.readlines()
result=[]
mecab.parse("")
for line in lines:
node = mecab.parseToNode(line)
node_org = title.parse(line)
while node:
hinshi = node.feature.split(",")[0]
if hinshi == '形容詞' or hinshi == '名詞' or hinshi == '副詞' or (len(node.feature.split(",")[6])>1):
fo.write(node.feature.split(",")[6] + ' ')
if node_org != 'EOS\n' and node_org.split(",")[1] == '固有名詞':
fo.write(node_org.split(",")[6] + ' ')
if node_org != 'EOS\n' and node_org.split(",")[1] == '固有名詞' and node_org.split(",")[6].isalpha()==True:
fo.write(node_org.split(",")[7] + ' ')
node = node.next
fi.close()
fo.close()
print('Wakati phase completed!')
sentences = word2vec.LineSentence('res.csv')
model = word2vec.Word2Vec(sentences,
sg=1,
size=200,
min_count=5,
window=5,
hs=1,
iter=100,
negative=0)
# pickleで保存
import pickle
with open('mecab_word2vec_seiyu.dump', mode='wb') as f:
pickle.dump(model, f)
word2vecのモデル結果を試して見る
実際にword2vecで学習したモデルを使って単語分析で遊んでみます。試しに、アイドル売りしてなさそうな声優さんでも出してみます。
ret = model.wv.most_similar(negative=['アイドル'],topn=1000)
for item in ret:
if len(item[0])>2 and (item[0] in list(df.Name)):
print(item[0],item[1])
出力結果
寿美菜子 0.13453319668769836
蒼井翔太 0.1175239235162735
豊崎愛生 0.1002458706498146
田村知佳 0.08929911255836487
山口茜 0.05830669403076172
森綾香 0.056574173271656036
藤田咲 0.05241834372282028
鹿野優以 0.051871318370103836
早見沙織 0.04932212829589844
菊地美香 0.04044754058122635
鈴木杏 0.034879475831985474
逢坂良太 0.029612917453050613
井口裕香 0.02767171896994114
悠木碧 0.02525651454925537
樋口智恵子 0.022603293880820274
次に、アイドル色が強そうな声優さんを取り出してみます。
ret = model.wv.most_similar(positive=['アイドル'],topn=300)
for item in ret:
if len(item[0])>2 and (item[0] in list(df.Name)):
print(item[0],item[1])
出力結果
Machico 0.1847614347934723
福原香織 0.1714700609445572
三澤紗千香 0.1615515947341919
中原麻衣 0.15694507956504822
小倉唯 0.1562490165233612
中川翔子 0.1536223590373993
東山奈央 0.15278896689414978
榊原ゆい 0.14662891626358032
清水愛 0.14592087268829346
石原夏織 0.14554426074028015
次に、「アワード」と縁がありそうな声優さんを抽出してみます。
ret = model.wv.most_similar(positive=['アワード'],topn=500)
for item in ret:
if len(item[0])>2 and (item[0] in list(df.Name)):
print(item[0],item[1])
出力結果
木戸衣吹 0.19377963244915009
福原香織 0.16889861226081848
津田美波 0.16868139803409576
内田真礼 0.1677364706993103
名塚佳織 0.1669023633003235
茅野愛衣 0.16403883695602417
坂本真綾 0.16285887360572815
牧野由依 0.14633819460868835
山崎エリイ 0.1392231583595276
喜多村英梨 0.13390754163265228
阿澄佳奈 0.13131362199783325
能登有沙 0.13084736466407776
大橋彩香 0.1297467052936554
逢坂良太 0.12972146272659302
あー、なんだろ、、、めっちゃそれっぽいような気がします(ちなみに「結婚」とやっても出てきた笑)。
まとめ
今回は声優さんのWikipediaの情報を取得して、取得したテキスト情報を用いてword2vecで学習モデルを保存して実際にモデルを動かすところまでやって見ました。ウィキペディアにあるプロフィールのテキスト情報だけだと詳細な情報がないため限界があるので、実際に本格的に解析するには大量のデータやモデリング等の検証が必要です。しかし、ここで投稿するのはあくまでネタ解析なのでそこら辺は許してください。実際、テキストデータの量が少ないこともあり、word2vecのパラメータ依存で結果が多少変わってしまいますので、ブログの結果とおりになるとは限りません。大筋の結果自体はそこまで劇的に変化しないですが...汗
次は、実際に学習したモデルを用いてネットワークとして可視化して、実際にネットワークをクラスタリングして似ている声優さん同士をカテゴリ化するところまでやっていきます。