動機
- Pythonを書いたことない
- Pythonの勉強がしたい
- Youtubeチャンネル「ぷらそにか」にハマっている
- 友達にオススメしている
- タイトルへ進む
AWS
毎朝動かしたかったので、LambdaのトリガーにCloudWatch Eventsを設定しました。
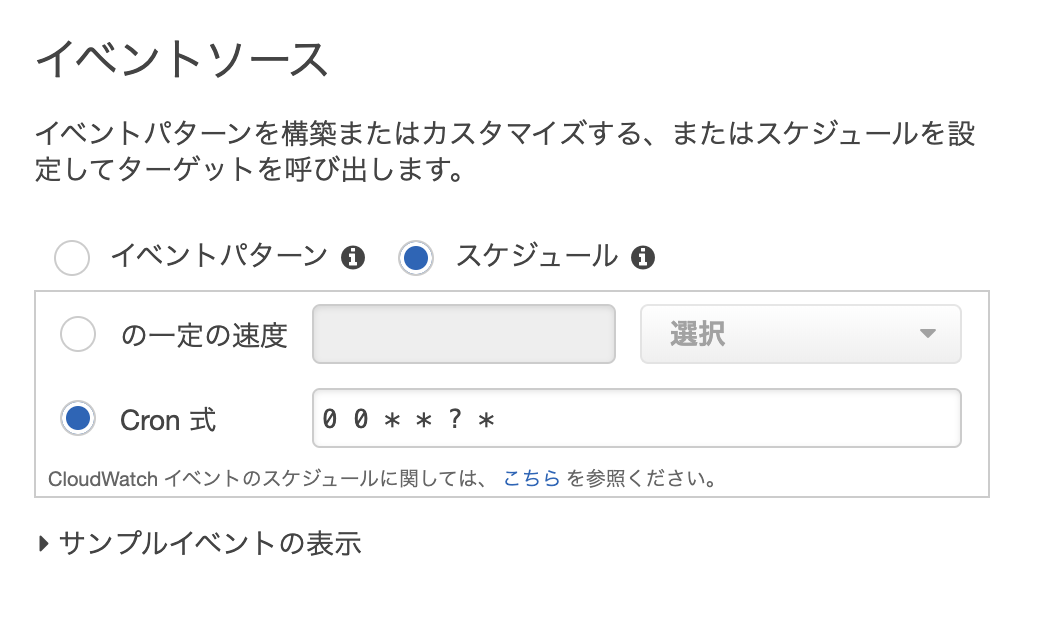
↑日本時間で朝9時
とりあえず全文
# !/usr/bin/python
import os
import sys
sys.path.append(os.path.join(os.path.dirname(__file__), "packages"))
from oauth2client.tools import argparser
from apiclient.errors import HttpError
from apiclient.discovery import build
import re
import requests
import random
import json
DEVELOPER_KEY = os.environ["DEVELOPER_KEY"]
YOUTUBE_API_SERVICE_NAME = "youtube"
YOUTUBE_API_VERSION = "v3"
CHANNEL_ID = "UCZx7esGXyW6JXn98byfKEIA"
WEBHOOK_URL = os.environ["WEBHOOK_URL"]
youtube = build(YOUTUBE_API_SERVICE_NAME,
YOUTUBE_API_VERSION,
developerKey=DEVELOPER_KEY)
VIDEOS = []
def get_random_video(page_token):
# チャンネルの情報を取得
response = (youtube.search().list(part="snippet",
channelId=CHANNEL_ID,
maxResults=50,
pageToken=page_token).execute())
# 結果から動画IDを配列に格納
for result in response.get("items", []):
if result["id"]["kind"] == "youtube#video":
VIDEOS.append(result["id"]["videoId"])
# nextPageTokenがある時は再帰的に実行
try:
next_page_token = response["nextPageToken"]
get_random_video(next_page_token)
except:
print("VIDEOS:", VIDEOS)
# ランダムで動画を選択して、IDを返す
video_id = random.choice(VIDEOS)
print("CHOICE_VIDEO_ID:", video_id)
return get_video_info(video_id)
def get_video_info(video_id):
# 動画の情報を取得
response = youtube.videos().list(part="snippet, statistics",
id=video_id).execute()
print("RESPONSE:", response)
return create_message(response)
def create_message(response):
snippet = response["items"][0]["snippet"]
statistics = response["items"][0]["statistics"]
# メッセージ作成に必要な値を取得
video_id = response["items"][0]["id"]
title = snippet["title"]
day = snippet["publishedAt"]
day = day[0:10]
description = snippet["description"]
member = re.findall(r"(.*?)\n【Twitter】", description)
member = list(map(lambda x: ({"value": x, "short": True}), member))
view = "{:,}".format(int(statistics["viewCount"]))
rate = [statistics["likeCount"], statistics["dislikeCount"]]
url = "https://www.youtube.com/watch?v=" + video_id
image = snippet["thumbnails"]["maxres"]["url"]
# メッセージ作成
json = {
"attachments": [
{
"pretext": "今日のおすすめ",
"title": title,
"title_link": url,
"text": url,
"color": "#7CD197",
"image_url": image,
},
{
"title": "Member",
"fields": member,
"color": "#764FA5"
},
{
"fallback":
f"{title} {url}",
"text":
"",
"fields": [
{
"title": "投稿日",
"value": day,
"short": True
},
{
"title": "再生回数",
"value": view,
"short": True
},
{
"title": "高評価",
"value": rate[0],
"short": True
},
{
"title": "低評価",
"value": rate[1],
"short": True
},
],
},
]
}
print("MESSAGE:", json)
return post_slack(json)
def post_slack(context):
payload = context
data = json.dumps(payload)
# slackに投稿
response = requests.post(WEBHOOK_URL, data)
if response.status_code == 200:
print("ooo投稿完了ooo")
else:
print("xxx投稿失敗xxx")
def lambda_handler(event, context):
try:
get_random_video(page_token="")
except HttpError as e:
print("An HTTP error %d occurred:\n%s" % (e.resp.status, e.content))
実行結果

部分的に
# nextPageTokenがある時は再帰的に実行
try:
next_page_token = response["nextPageToken"]
get_random_video(next_page_token)
except:
print("VIDEOS:", VIDEOS)
# ランダムで動画を選択して、IDを返す
video_id = random.choice(VIDEOS)
print("CHOICE_VIDEO_ID:", video_id)
return get_video_info(video_id)
チャンネルの動画取得が50件までしかできないので、responseのなかにnextPageToken があればもう一周という処理を書きたかった。あんまりわかってない部分(1)
snippet = response["items"][0]["snippet"]
statistics = response["items"][0]["statistics"]
# メッセージ作成に必要な値を取得
video_id = response["items"][0]["id"]
title = snippet["title"]
day = snippet["publishedAt"]
day = day[0:10]
description = snippet["description"]
member = re.findall(r"(.*?)\n【Twitter】", description)
member = list(map(lambda x: ({"value": x, "short": True}), member))
view = "{:,}".format(int(statistics["viewCount"]))
rate = [statistics["likeCount"], statistics["dislikeCount"]]
url = "https://www.youtube.com/watch?v=" + video_id
image = snippet["thumbnails"]["maxres"]["url"]
選ばれた動画からSlack投稿に必要な要素を取っていくところ。もっとスマートになるのかな?あんまりわかってない部分(2)
responseの概要欄の部分
歌:ぷらそにか
にしな (Vocal / Tambalin)
【Twitter】https://twitter.com/nishina1998
【HP】http://www.afterschool-music.com/nishina/
高村風太 (Vocal / Keyboards)
【Twitter】https://twitter.com/futavocabulary
【HP】http://www.afterschool-music.com/futa/
Foi (Vocal / Guitar)
【Twitter】https://twitter.com/Foi127
【HP】http://www.afterschool-music.com/foi/
てつと (Vocal / Cajón)
【Twitter】https://twitter.com/MusicandGraphic
【HP】http://www.afterschool-music.com/tetsuto/
早希 (Vocal)
【Twitter】https://twitter.com/singersing28
【HP】http://www.afterschool-music.com/saki/
suzu (Vocal / Organ)
【Twitter】https://twitter.com/suuuu_ttt
【HP】http://www.afterschool-music.com/suzu/
上野正明 (Vocal / Bass)
【Twitter】https://twitter.com/ueno_masaaki
【HP】http://www.afterschool-music.com/uenomasaaki/
幾田りら (Vocal / Cymbal)
【Twitter】https://twitter.com/ikutalilas
【HP】http://www.afterschool-music.com/lilas/
# ぷらそにか
# PLUSONICA
参加メンバーが週によって変わるので投稿に載せたかった。
member = re.findall(r"(.*?)\n【Twitter】", description)
member = list(map(lambda x: ({"value": x, "short": True}), member))
手助けをいただいて実装できた。あんまりわかってない部分(3)
感想
ぷらそにかその宣伝ができたら満足
[チャンネル概要欄]
それぞれ個々に活動しているシンガー・ソングライターたちによる、アコースティックセッションユニット。毎週金曜日にカバー動画をアップしています。
メンバーの加入と卒業がありながら約3年活動しているグループで、流行りの曲を中心にカバー曲を投稿しています。メンバーも個性たっぷりで、見れば見るほどハマっていきます。トーク回、新メンバー紹介回もおすすめ。
チャンネル登録お願いします!!!(?)
(python勉強します)