はじめに
Atari 2600 Gamesの攻略を発端として有名となった強化学習ですが,ここ数年で
プレイヤーが複数人いるゲームのための強化学習の研究も盛んに行われています.Self-Play Reinforcement Learning (Self-Play RL) はマルチプレイのゲームの学習にしばしば用いられる学習方法であり,囲碁やDota 2のAI開発に使われたことで注目を浴びました.
今回は,Unityによる自作の対戦ゲームのAIをSelf-Play RLによって作成してみようと思います.
Self-Play Reinforcement Learning
Self-Play RLはエージェント (プレイヤ) が複数人いるゲームの戦略を学習させるために用いられる学習方法の1つです.
Self-Play RLでは,以下の図のように自分自身の戦略のコピーを作成し,それを相手として学習をすすめることを繰り返します.
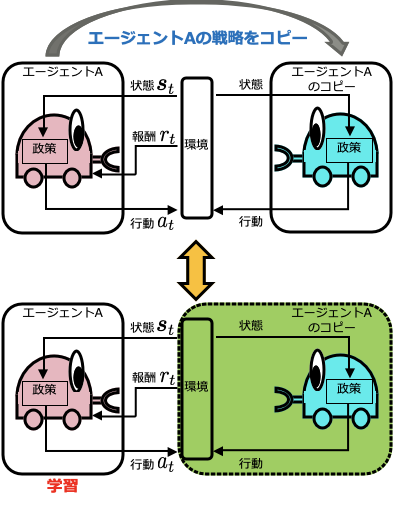
囲碁などのように対称性があるようなゲームの場合,この方法を用いることで学習する戦略のモデルは1つだけでよくなるのですが,対称性がないゲームの場合 (例えば人狼ゲームのように役割がわかれているゲーム),自分自身のコピーを相手に学習することはできません.その場合,以下の図のようにエージェントの数だけ戦略のモデルを学習させることで同じようなことが実現できます.
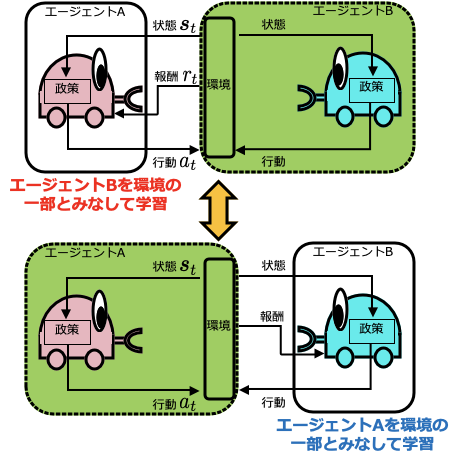
Self-Play RLでは全エージェントの戦略を学習させることになるので,事前に対戦相手の戦略に関する情報が得られている必要はなく,ゼロから学習が可能であるという点が大きなメリットの1つです.また,徐々に強いエージェントを相手に学習するようになるため,最初から強いエージェントを相手にするよりも学習がスムーズに進みやすいというメリットもあります.
Self-Play RLを学習に利用した例で有名なものとして,AlphGo[1,2]やOpenAI Five[3]が挙げられます.個人的には,大乱闘スマッシュブラザーズDXにおいてトップランカーに匹敵するようなAIの学習に成功した研究[4]がお気に入りです.
自作対戦ゲーム
今回は以下のようなインベーダーゲームを2人対戦にしたようなゲームをUnityによって作成しました.

このゲームでは,各プレイヤーは画面上,もしくは画面下にいるキャラクターを操作します.互いに弾丸を打ち合って相手を倒した方が勝ちという設定にしているので,インベーダーゲームと言うよりはシューティングゲームに近いかもしれません.
画面中央付近にいるコウモリはプレイヤに向かって弾丸を打ってくるモブ敵です.モブ敵がすべて倒された場合,より速いスピードのモブ敵が登場するため,ゲームが長引くにつれて生き残るのが難しいようなゲームとなっています.
ML-Agents
Unity Machine Learning Agents Toolkit (ML-Agents) は,Unityで作成したゲームやシミュレータを,強化学習の学習環境として利用できるようにするオープンソースのUnityプラグインです.
ML-Agentsには強化学習や模倣学習などのためのアルゴリズムがいくつか内包されているため,作成したゲームの戦略のモデル作成をML-Agentsひとつで行うことができます.Self-Play RLによる学習も行うことができ,今回のゲームの2つのエージェント両方の学習もML-AgentsのSelf-Play RLを用いて行いました.
ML-Agentsは比較的頻繁にアップデートが行われていて,仕様が変更されることも多いので,本記事ではML-Agentsの詳細や使い方については触れないでおこうと思います.
強化学習環境としての定義
作成したゲームをSelf-Play RLによって学習させるためには,強化学習環境として以下の要素を定義する必要があります.
- 環境から観測する状態
- エージェントが行うことができる行動
- エージェントに与えられる報酬
- エピソードの終了条件
今回はそれぞれの要素を以下のように設定しました.
状態
各エージェントが観測できる状態は以下の10次元の要素としました.
- エージェントに1番目,2番目,3番目に近い (y軸方向で見て) 敵エージェントからの弾丸の座標
- エージェントに1番近い (y軸方向で見て) モブ敵からの弾丸の座標
- エージェントのx座標
- 敵エージェントのx座標
Atari 2600 Gamesのように画面情報を画像として入力することも試しましたが,学習に時間がかかりそうだったのでボツとしました.
行動
エージェントが行うことができる行動は,「左右方向への移動」と「弾丸の発射」の二種類としました.「左右方向への移動」は「左に移動」,「右に移動」,「移動しない」のいずれかを選択します.一方で,「弾丸の発射」は発射するかどうかを選択します.つまり,エージェントは各stepで$6(=3\times 2)$つの行動の中から1つを選択することになります.
報酬
エージェントに与えられる報酬は,以下の3つの報酬の和によって定義しました.
- 敵エージェントの近さに対して与えられる正の報酬
- 敵エージェントを倒したときに与えられる正の報酬
- 倒されたときに与えられる負の報酬
1つ目の報酬は敵エージェントに近いほど高い報酬が与えられるように設計しました.2つ目の報酬は,モブ敵の弾丸でなく自分の弾丸によって敵エージェントを倒した場合,より高い報酬が得られるようにしました.また,早く敵エージェントを倒すように学習が進むことを狙って,エピソードが開始してからの時間が経過するほどこれらの正の報酬が減少するようにしました.
エピソードの終了条件
以下の2つのどちらかを満たした場合,エピソードが終了するようにしました.
- いずれかのエージェントが倒された
- エピソードが開始してから250 stepが経過
学習結果
学習アルゴリズムはSoft Actor-Critic (SAC) [5]を用いました.SACはoff-policyアルゴリズムの1つで,Replay Bufferを用いることができるためProximal Policy Optimization (PPO) などのアルゴリズムよりサンプル効率が良いことが実験的に示されています.
100万step分学習を行った際のエージェントの挙動を以下の動画に示します (こちらで実際に遊ぶこともできます).
自作の対戦ゲームのAIをself-play RLで学習させてみました.
— ばかなおうじ(あべけんし) (@bakanaouji) December 29, 2019
上が学習済みエージェントで下が私(派手に負けました) pic.twitter.com/kRReWweZSC
下のプレイヤーを操作しているのは私ですが,ひたすらに攻撃が避けられまくっていることがわかります.なかなかのクソゲーに仕上がってしまったようです...正直まともに倒せる気がしないのでイライラします\(^o^)/
おまけ
実は上の動画のエージェントを学習させるために何回か設定を変えて学習をやり直しています.というのも,最初の学習では「ステージの右または左端にへばりついてまともに勝負をしようとしない」という偏った動きをするようにモデルが学習してしまい,人間が対戦するには全くおもしろくない挙動となってしまったからです.
本来目指していたのはよりアグレッシブに攻撃をしかけてくるような挙動でしたので,色々と工夫を導入してそのような挙動を学習するように何回か学習をやり直しました.具体的には,以下のような工夫を入れることで学習がうまくいったような感じがします.
- 各エージェントの初期x座標をランダムに決定
- 敵エージェントに近づくことに正の報酬を与える
- エピソードが開始してから250 stepが経過したらエピソードをリセット
- Replay Bufferのバッファサイズを大きめに設定
1つ目の工夫は,様々な位置関係に関して学習を行うために導入しました.これによって,毎回端っこに寄るようなワンパターンな挙動を学習しにくくなることが期待されます.
2つ目の工夫は,エージェント同士が近づくように学習が進み,ギリギリの打ち合いを多く経験することを期待したために導入しました.
3つ目の工夫では,エージェントは早々に決着をつけないと敵エージェントを倒すことによる報酬がもらえなくなるので,よりアグレッシブに攻撃をしかけるように学習することが期待されます.ただし,完全にゲームをリセットすると速度が上がった状態のモブ敵に対応できなくなると思われるので,モブ敵はリセットせず,各エージェントの位置だけランダムにリセットするようにしました.
最後4つ目はSACのアルゴリズムのパラメータに関する工夫です.Replay Bufferは学習に用いるミニバッチのサンプルを行うバッファのことで,このバッファサイズが大きいほど,より過去の経験データも学習データとして用いることになります.今回の工夫のようにバッファサイズを大きくすることは過去のモデルによる対戦ログも用いて学習するということを意味しているため,直感的には1つのモデルを相手にして学習を行うより偏った行動を取るように学習しにくくなると考えました.
おわりに
今回作成したゲームはこちらに公開しています.相手は学習済みのエージェントとなっていて,スコアを競うことができるランキング機能も拙いながら実装していますので,よかったら遊んでみてください.
また,今回の実験を通してマルチプレイヤのゲームで極端な挙動へ学習が進んでしまうことを防ぐことはやはり難しい問題であると感じました.AlphaGoなどは最新のモデルだけでなく過去のモデルとも対戦させることで対処を行っており,今回の実験だとReplay Bufferのバッファサイズを増やしたことが似たような対処法となっていると考えられます.
ICLR 2020では相手が合理的でない行動をしてきた場合にエージェントが混乱して性能が著しく劣化する,ということを実証した研究 (論文リンク) がacceptされており,多様な相手に対するロバストさやエージェントの均衡についてはまだ研究の余地がありそうです.このあたりに興味ある方がいたら@bakanaoujiまでご連絡ください.
参考文献
[1] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, Vol. 529, No. 7587, p. 484, 2016.
[2] David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature, Vol. 550, No. 7676, pp. 354–359, 2017.
[3] Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Debiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning. arXiv preprint, 2019.
[4] Vlad Firoiu, William F Whitney, and Joshua B Tenenbaum. Beating the world’s best at super smash bros. melee with deep reinforcement learning. arXiv preprint, 2017.
[5] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint, 2018.