- ポケモン×データサイエンス(1) - ポケモン剣盾のランクバトルデータを解析してTableau上で可視化してみた
- 【今回】ポケモン×データサイエンス(2) - ポケモン剣盾のパーティ構築をネットワーク分析から考える 試行編
- ポケモン×データサイエンス(3) - ポケモン剣盾のパーティ構築をネットワーク分析から考える ネットワークの中心はどこ編
こんにちは、前回の記事に引き続きポケモンの可視化についてです。
ポケモンの対戦環境においては、いかにしてパーティを構築するかが鍵であり、それによって勝敗が決まるといっても過言ではありません。
今回はそのパーティ構築を考える上で、ポケモン同士がどのような関係性にあるのかを把握するため、ネットワークの力を借りたいと思います。
コード全文はこちらから
データインポート
データは前回の記事で作成したデータの内、一緒に採用されているランキングALL_SEASON_TEMOTI_POKEMON.csvを使用します。
(※こちらのmain.pyを実行すると自動で作成されます。)
このデータへのパスを
file_path = 'ALL_SEASON_TEMOTI_POKEMON.csvへのパス'
としたうえで、以下の関数を定義して
import pandas as pd
def make_edge_list(file_path):
df = pd.read_csv(file_path, encoding='utf-8')
df = df.groupby(['Pokemon','併用率の高いポケモン'])['Rank_併用率の高いポケモン'].mean()
df = pd.DataFrame(df).reset_index()
df.columns = ['From', 'To', 'Weight']
df['Weight'] = 10-df['Weight']
return df
実行!
network = make_edge_list(file_path)
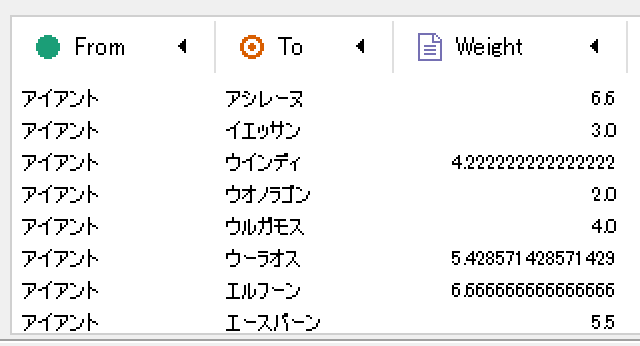
以下の様なデータが得られていれば成功です。
有向グラフ(エッジに向きがある)を描画するのでノードの始点と終点、エッジの重みが最低限必要になります。
今回はあるポケモンをエッジの始点(From)、一緒に採用されることが多いポケモンをエッジの終点(To)、エッジの重み(Weight)を平均順位の逆数としました。
| From | To | Weights |
|---|---|---|
| アイアント | アシレーヌ | 6.60 |
| アイアント | イエッサン | 3.00 |
| アイアント | ウインディ | 4.22 |
| ... | ... | ... |
| 35732 rows × 3 columns |
データの加工
こちらのデータをそのままネットワークに放り込んでしまうと、ノードとエッジが多すぎて大変なことになる(計算時間も去ることながら可視化が極めて困難になる)ので、データの絞り込みをします。
取り急ぎ以下のコードでシーズン12における採用率ランキングをcsvとして保存します。
import urllib.request
import json
import datetime
def make_pokemon_rank(ids):
for season_number in ids['list'].keys():
for season_id in ids['list'][season_number].keys():
rst = ids['list'][season_number][season_id]['rst']
ts2 = ids['list'][season_number][season_id]['ts2']
url = f'https://resource.pokemon-home.com/battledata/ranking/{season_id}/{rst}/{ts2}/pokemon'
file_name = f'Season{season_number}_{"Single" if season_id[4]=="1" else "Double"}_採用率ランキング.json'
if get_response_pokemon_rank(url, file_name):
with open('log', 'a') as f:
print(f'{datetime.datetime.now()} | Generated: {file_name}', file=f)
def get_response_pokemon_rank(url, file_name):
try:
with urllib.request.urlopen(url) as response:
body = json.loads(response.read())
with open(f'{file_name}', 'w') as f:
json.dump(body, f, indent=4)
return True
except urllib.error.URLError as e:
print(e.reason)
return False
def translate_pokemion_name(num, form):
if num == 876:
if form == 0:
name = "イエッサン♂"
else:
name = "イエッサン♀"
elif num == 479:
if form == 0:
name = "ロトム(デフォ)"
elif form == 1:
name = "ロトム(火)"
elif form == 2:
name = "ロトム(水)"
elif form == 3:
name = "ロトム(氷)"
elif form == 4:
name = "ロトム(飛行)"
elif form == 5:
name = "ロトム(草)"
else:
name = pokedex['poke'][int(num) -1]
return name
こちらのリポジトリのdatachunk\IDs.jsonとdatachunk\bundle.jsonを読み込みます。
ids = "";
with open('.//datachunk//IDs.json', 'r', encoding='utf-8') as json_open:
ids = json.load(json_open)
pokedex = "";
with open('.//datachunk//bundle.json', 'r', encoding='utf-8') as json_open:
pokedex = json.load(json_open)
以下を実行してシーズン1から12までのランキングデータを取得します。
make_pokemon_rank(ids)
採用率ランキングをjsonからcsvに変形します。
season_num = 12
rule = 'Single'
with open(f'Season{season_num}_{rule}_採用率ランキング.json', 'r', encoding='utf-8') as json_open:
data = json.load(json_open)
seasons = []
rules = []
pokemons = []
ranks = []
for index, pokemon in enumerate(data):
seasons += [season_num]
rules += [rule]
pokemons += [translate_pokemion_name(pokemon['id'], pokemon['form'])]
ranks += [index+1]
df_a = pd.DataFrame(data=[seasons, rules, pokemons, ranks]).T
df_a.columns = ['Season', 'Rule', 'Pokemon', 'Rank']
df_a.to_csv(f'Season{season_num}_{rule}_Ado_Rank.csv', index=False)
あとはこのデータを読み込んでシーズン12時点で採用率ランキング上位150位に絞り込みをします。
top150_list = list(df_a['Pokemon'])
network_top150 = network[network['From'].isin(top150_list[:150])]
network_top150 = network_top150[network_top150['To'].isin(top150_list[:150])]
Networkxによる可視化
NetworkxのPythonでの操作方法についてはこちらをご参照ください。
import matplotlib.pyplot as plt
import networkx as nx
plt.rcParams['font.family'] = 'IPAexGothic'
network_np = network_top150.values
G = nx.DiGraph()
G.add_weighted_edges_from(network_np)
pos=nx.spring_layout(G)
fig = plt.figure(figsize=(40, 40), dpi=100,facecolor='w', linewidth=0, edgecolor='w')
nx.draw_networkx(G,pos,font_size=16,font_family='IPAexGothic')
fig.show()

何も読み取れない...泣
ノード・エッジの多さが凄まじく、Networkxのグラフを"イイ感じ"にしてくれるspring_layout()が今回のデータセットと相性が悪そうです。
Networkxの描画に関係する属性をいじれば変わりそうですが、いずれにしてもpythonでネットワークの可視化を行うのは限界を感じたのでCytoscapeを試してみます。
Cytoscapeによる可視化
続いてCytoscapeを試してみます。
Cytoscapeの使い方についてはこちらの記事が大変詳しく書かれています。
まずデータを読み込みます。以下のコードを実行してファイルを出力します。
make_edge_list(file_path).to_csv("FILE-NAME.csv", index = False)
Cytoscapeを起動し、左上のfile > import > Network from Fileから、先ほど出力したcsvファイルをインポートします。
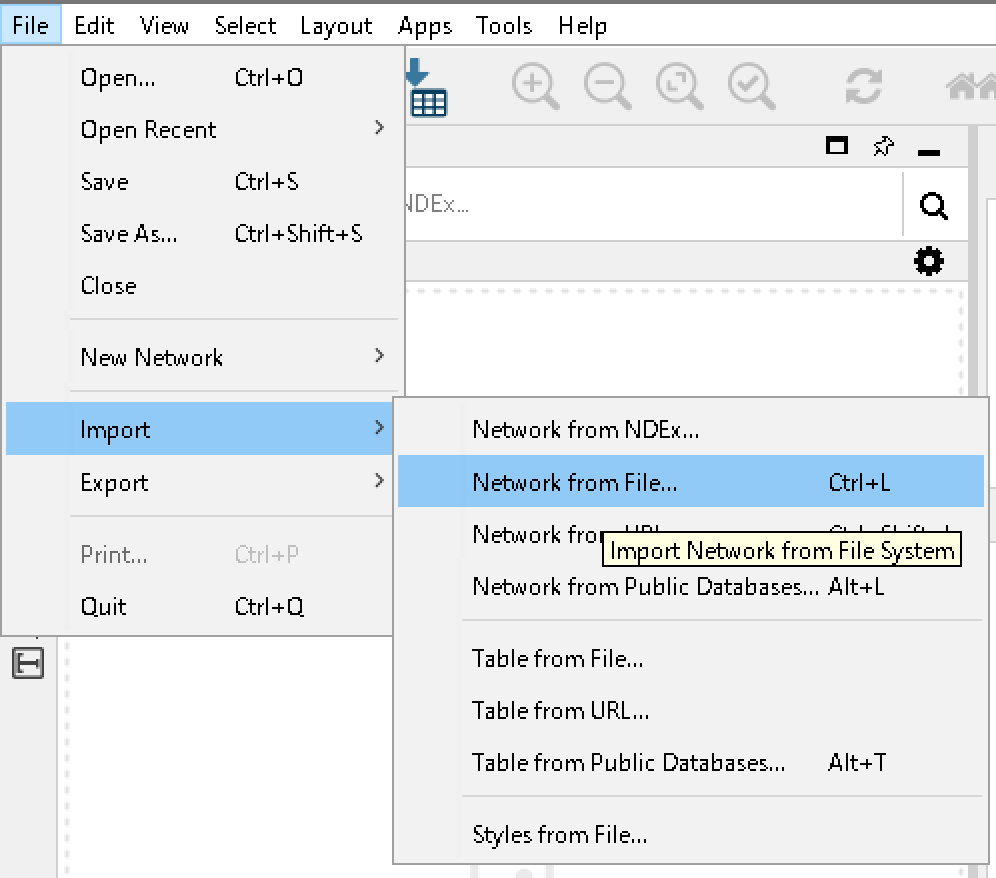
下図のような画面が出ると思います。今回は有向グラフなのでそれぞれのノードが何を意味するものなのかを指定してあげます。Fromはエッジの始点となるノードなのでSource Node、Toはエッジの終点となるノードなのでTarget Node、Weightはエッジの重みを表すのでEdge Attributeとします。
上部タブLayoutや左タブStyleを適当にいじってみると、かなり求めていたものに近いものが得られました。
対戦環境はグラフの中央付近にいて多数のエッジが伸ばされているエースバーン、パッチラゴン、ドラパルト、トゲキッスを中心に回っていることが分かります。
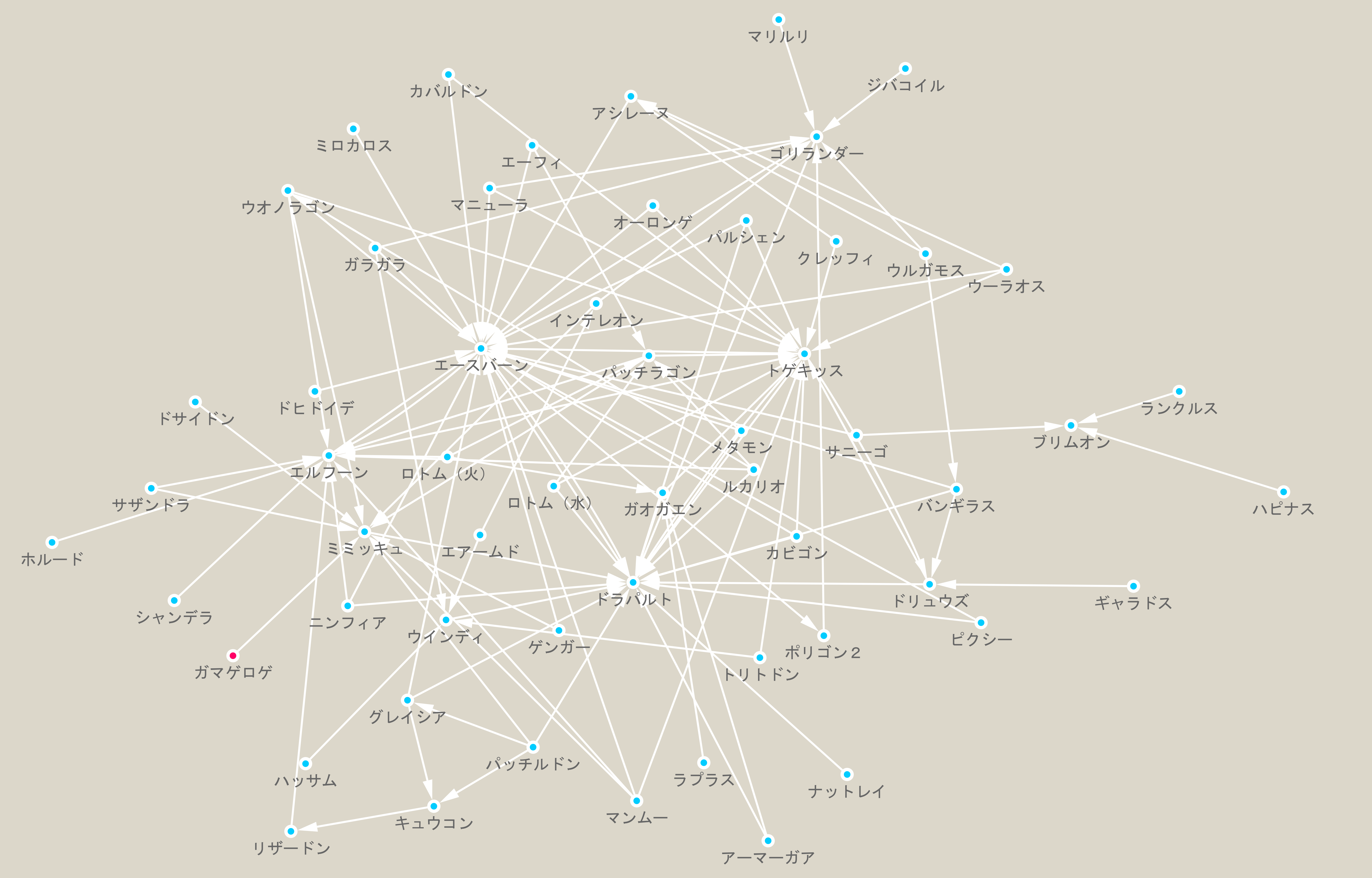
Cytoscapeはノードのドラッグによる移動などインタラクティブな操作に対応しており、スタイルを変更などの諸々の操作をGUI操作でできる点で直感的な試行錯誤ができて大変Goodです。
次回はこちらのネットワークを用いて分析をしていきたいと思います。
それではまた。
出典
- ポケモン剣盾のランクバトルデータを解析してTableau上で可視化してみた - Qiita
- 【Python】NetworkX 2.0の基礎的な使い方まとめ - Qiita
- 鉄道路線データをグラフとしてCytoscapeで可視化する 3
- Cytoscape.org
©2020 Pokémon ©1995-2020 Nintendo/Creatures Inc./GAME FREAK inc. ポケットモンスター・ポケモン・Pokémonは任天堂・クリーチャーズ・ゲームフリークの登録商標です。