はじめに
AWS では、いろいろなサーバーレスで構築したシステムから共通した部分を抜き出し、 "サーバーレスパターン" としてサービスの組み合わせを紹介しています。表題の「 Kinesis Data Streams のストリーミングデータを Lambda で処理する」という処理は、 "サーバーレスパターン" で "流入データの連続処理" として紹介されているものです。パターンの学習はやりたいことを実現するためのヒントとなり、共同作業をする人との共通意識となり作業のスピードを高める効果があります。
今回はこの "流入データの連続処理" としてあらわされている Kinesis Data Streams と Lambda の処理を組んでみたいと思います。以下の説明では 東京 (ap-northeast-1) リージョンを使用します。
「流入データの連続処理」パターンの概要
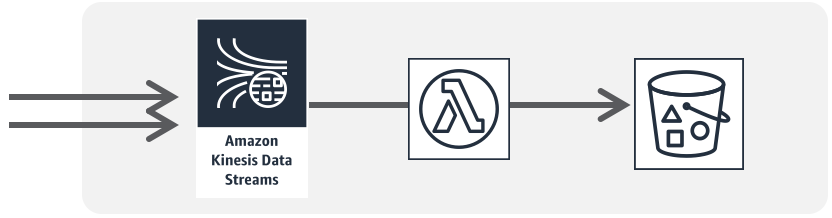
- プロデューサーから受け取ったデータを "Amazon Kinesis Data Streams" (以下、Kinesis と記載します) がストリーミングデータにする。
- Kinesis にデータを送信するアプリケーションのことを "プロデューサー" と呼びます。
- Lambda は Kinesis からストリーミングデータを取り出し加工した後、加工したデータを S3 に保存する。
- Kinesis からデータを取得して処理をするアプリケーションは "コンシューマー" と呼びます。
Kinesis を準備する
- Amazon Kinesis コンソールのデーターストリームページから、"データーストリームの作成" を選択してください。
- データストリームの作成ページで以下のプロパティを入力して "データストリームの作成" を選択してください。
- データストリーム欄:データストリーム名 -
MyDataStreams - データストリームの容量欄:
- シャドーエスティメーター デフォルトのまま
- 開いているシャードの数 -
1
- データストリーム欄:データストリーム名 -
S3 を準備する
- Amazon S3 コンソールを開きます。バケットページで "バケットを作成" を選択します。
- "バケットを作成" ページにて以下のプロパティを入力して "バケットを作成" を選択してください。
- 一般的な設定欄:
- バケット名 -
mydatastreams-bucket - リージョン -
アジアパシフィック(東京)ap-northeast-1
- バケット名 -
- 他の値はすべてデフォルトとします
- 一般的な設定欄:
実行ロールを準備する
- IAM コンソールで、ロールページを開き、"ロールの作成" を選択します。
- 次のプロパティでロールを作成します。
- 信頼されたエンティティ -
AWS サービス - ユースケース -
Lambda - Attach アクセス権限ポリシー -
AWSLambdaExecute、およびAWSLambdaKinesisExecutionRole - ロール名 -
my-datastreams-role - ロールの説明 -
Allows Lambda functions to read data records and create data in the bucket.
- 信頼されたエンティティ -
Lambda ( コンシューマー ) を準備する
Kinesis をイベントソースとして Lambda にデータをおくるイベントソースマッピングを作成します。
- Lambda コンソールの 関数ページを開き、"関数の作成" を選択します。
- 次のプロパティを設定し、"関数の作成" を選択します。
- 関数の作成 -
一から作成 - 関数名 -
myDatastreamsFunction - ランタイム -
Node.js 12.x - デフォルトの実行ロールの変更
- 実行ロール -
既存のロールを使用する - 既存のロール - 先ほど作成したロール
my-datastreams-roleを選びます。
- 実行ロール -
- 関数の作成 -
- デザイナーペインで "トリガーの追加" を選択します。
- トリガーを追加ページで、次のプロパティを設定し、"追加" を設定します。
- トリガーの設定 -
Kinesis - Kinesis ストリーム - 先に用意した
MyMyDataStreamsを選択する - コンシューマー -
コンシューマーなし(デフォルト) - バッチサイズ -
100(デフォルト) - バッチウィンドウ - オプション - なし
- 開始位置 -
最新(デフォルト) - トリガーの有効化 - チェック
- トリガーの設定 -
- 関数コードペインの index.js を次のように変更し、"Deploy" を選択します。
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
exports.handler = async (event) => {
let submits = [];
event.Records.forEach(record => {
// Kinesis data is base64 encoded so decode here
var payload = Buffer.from(record.kinesis.data, 'base64').toString('ascii');
console.log('Decoded payload:', payload);
let params = {
Bucket: 'mydatastreams-bucket',
Key: `${record.eventID}.json`,
Body: JSON.stringify({'key1': payload})
};
submits.push(s3.putObject(params).promise());
});
try {
await Promise.all(submits);
} catch (error) {
console.log(error);
return {
success: false,
errorMessage: error.message
};
}
return {
success: true
};
};
プロデューサー用のロールを準備する
今回は EC2 から Kinesis エージェント を利用して Kinesis へデータを送信します。EC2 へは Systems Manager によりインスタンスに接続します。ここでは EC2 に割り当てるロールを準備します。
まず、Kinesis へデータを書き込むためのポリシーを用意します。
- IAM コンソールで、ポリシーページを開き、"ポリシーの作成" を選択します。
- "JSON" タブを選択し、次の JSON を入力します。Amazon リソースネームの部分のフォーマットは
arn:aws:kinesis:region:account-id:stream/stream-nameになります。account-id部分 (下の111122223333部分) は自分のアカウント ID に置き換えてください。入力が終わったら "ポリシーの確認" を選択します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:PutRecords"
],
"Resource": [
"arn:aws:kinesis:ap-northeast-1:111122223333:stream/*"
]
}
]
}
- ポリシーの作成ページにて、以下のプロパティを入力して "ポリシーの作成" を選択します。
- 名前 -
MyDataStreamsPolicy - 説明 -
Allows producer to write data records.
- 名前 -
次にロールを用意します。
- IAM コンソールで、ロールページを開き、"ロールの作成" を選択します。
- 次のプロパティでロールを作成します。
- 信頼されたエンティティ -
AWS サービス - ユースケース - 一般的なユースケースから
EC2を選択して、"次のステップ:アクセス権限" を選択します。 - Attach アクセス権限ポリシー -
AmazonEC2RoleforSSMと先ほど作成したMyDataStreamsPolicy - ロール名 -
MyDataStreamsRole - ロールの説明 -
Allows EC2 instances to call Kinesis data streams on your behalf.
- 信頼されたエンティティ -
プロデューサーを準備する
- EC2 コンソールから、インスタンスページを開き、 "インスタンスを起動" を選択します。
- 次のプロパティで EC2 を起動します。
- Amazon マシンイメージ -
Amazon Linux 2 AMI (HVM), SSD Volume Type、64 ビット(x86) - インスタンスタイプの選択 - タイプ
t2.micro - インスタンスの詳細設定
- インスタンス数 -
1(デフォルト) - ネットワーク - デフォルトVPC
- サブネット - デフォルトサブネット
- IAM ロール -
MyDataStreamsRole - 他はすべてデフォルト設定
- インスタンス数 -
- セキュリティグループの設定
- セキュリティグループの割り当て -
新しいセキュリティグループを作成する - ルールは削除してください。
- セキュリティグループの割り当て -
- Amazon マシンイメージ -
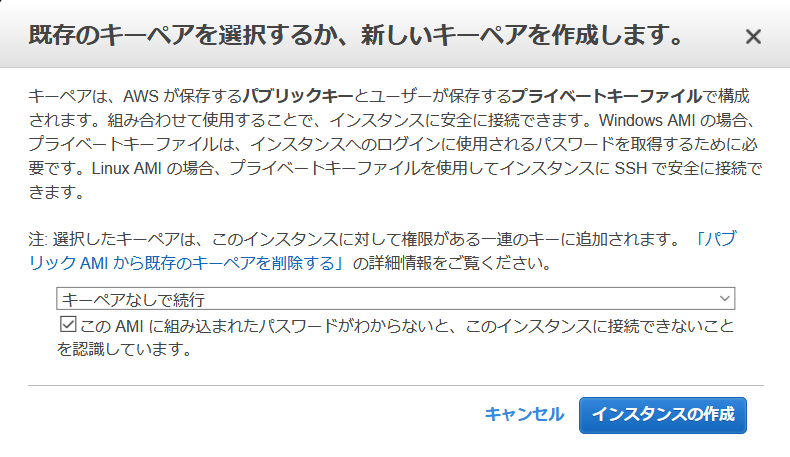
- インスタンス作成の確認ページにて "起動" を選択すると下のイメージにあるダイアログが現れます。ここでは
キーペアなしで続行を選択し、下のチェックボックスにチェックを入れ、"インスタンスの作成" を選択します。
- インスタンスID を確認し、インスタンスの状態が "実行中" に変わったら、Systems Manager コンソールを開きます。
- セッションマネージャーページで、"セッションの開始" を選択します。ターゲットインスタンスのリストから先ほど確認したインスタンス ID のラジオボタンをチェックして、"セッションを開始する" を選択します。
- 次のコマンドを使用してエージェントをインストールします。
sudo yum install –y aws-kinesis-agent
- 設定ファイル (
/etc/aws-kinesis/agent.json) を開き、編集します。
sudo vi /etc/aws-kinesis/agent.json
{
"cloudwatch.emitMetrics": false,
"kinesis.endpoint": "kinesis.ap-northeast-1.amazonaws.com",
"flows": [
{
"filePattern": "/tmp/app.log*",
"kinesisStream": "MyDataStreams"
}
]
}
- エージェントを開始します。
sudo service aws-kinesis-agent start
- データを作成して、エージェントに送信させます。うまくいかない場合は、こちら
/var/log/aws-kinesis-agent/aws-kinesis-agent.logにエージェントのログが出力されています。
echo "Hello, this is a test." > /tmp/app.log1
確認する
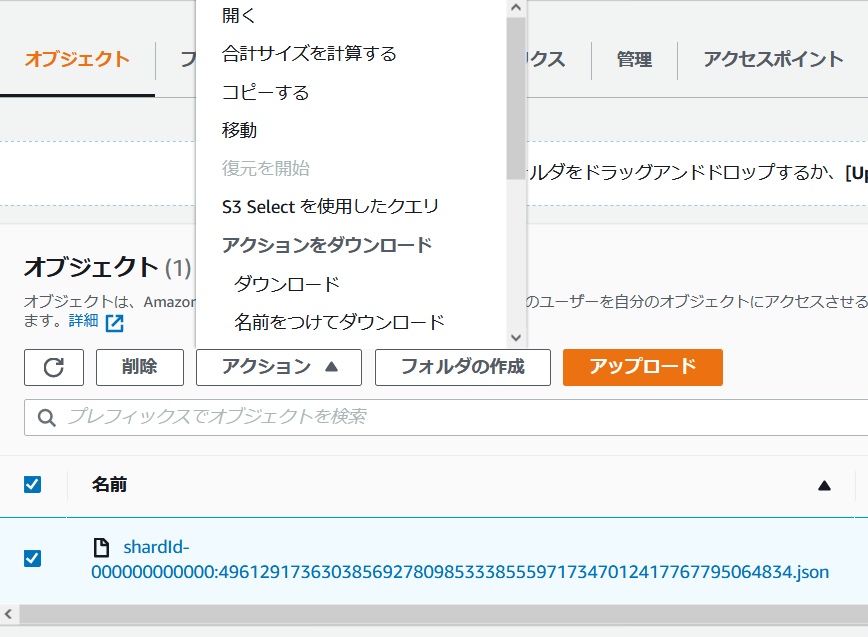
- S3 コンソールから、バケットページを開き、"mydatastreams-bucket" を選択します。
- オブジェクトペインに作成したファイルが格納されていると思います。オブジェクトにチェックを入れ、アクションから "ダウンロード" を選択するとファイルをダウンロードできます。
もし、ファイルが作成されていなかったら、 Kinesis エージェントのログや、Lambda のログを確認してみてください。以上です。