Waifu-DiffusionをWindowsローカル環境で試す

上の画像は試行錯誤をしながら300枚同じpromptで出力し、その中から厳選した一番好みのイラストです。
名前の通りですが、まずは実際どのくらいの精度で出力されるかを示します。
出力結果を見てみましょう。
prompt = "1girl, red hair, open mouth, green background, looking at viewer, simple background, long hair, red eyes, white t-shirt"
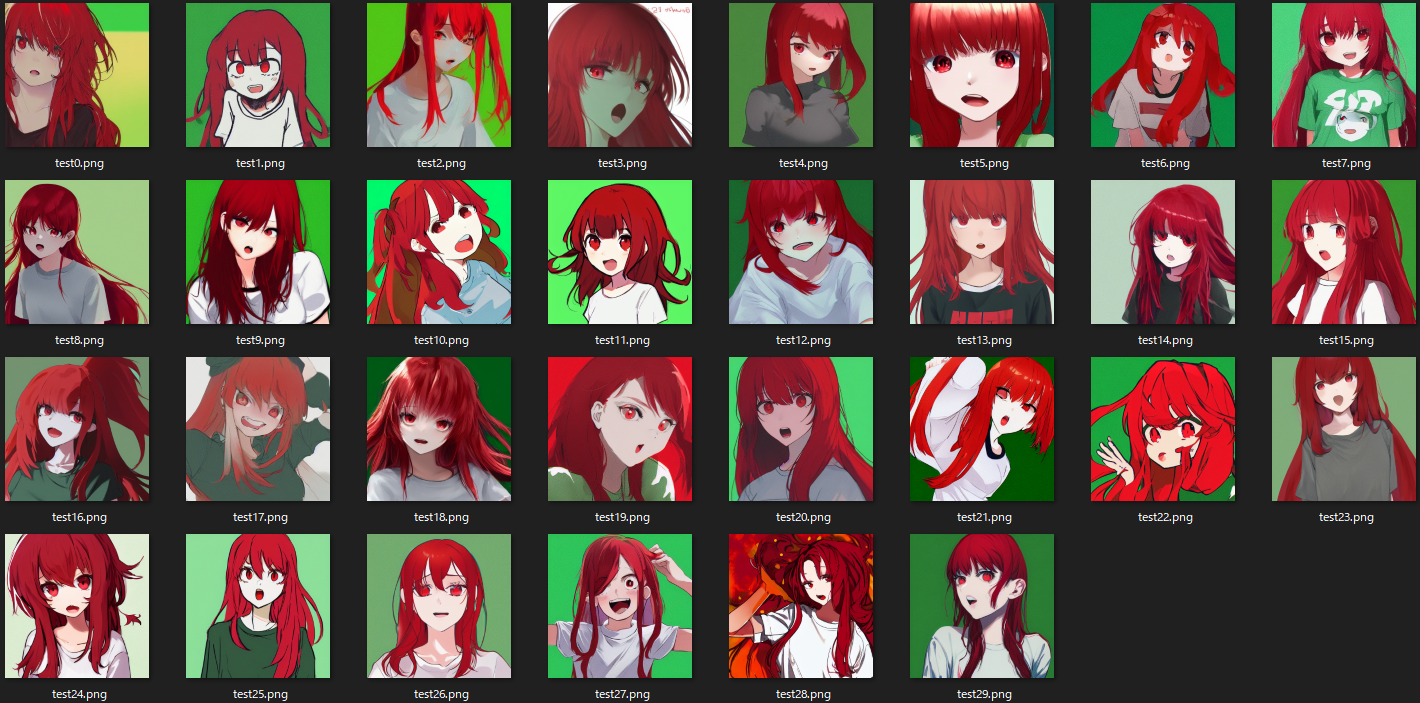
下の画像が、同じprompt(上記)で30回繰り返し出力した結果になります。

30枚のうちprompt通りの出力は何枚か、をまとめるとこのようになります。
| word | 正解数 | 正解率 | NG |
|---|---|---|---|
| 1girl | 30/30 | 100% | - |
| red hair | 29/30 | 97% | 17.png |
| open mouth | 30/30 | 100% | - |
| green background | 26/30 | 87% | 08.png & 17.png & 21.png & 23.png |
| looking at viewer | 30/30 | 100% | - |
| simple background | 30/30 | 100% | 20.png & 24.png |
| long hair | 29/30 | 97% | 03.png |
| red eyes | 30/30 | 100% | - |
| white t-shirt | 23/30 | 77% | 05-07.png & 16.png & 22.png & 28-29.png |
画風の統一が無いこと、指の描写が全滅なことがあげられますが、
30回出力してあからさまに崩壊していると言えるのが2枚(12.png、14.png)なので
精度としてはかなりのものと考えます。
(余談ですが個人的な好みでいくと26.pngは好きです。)

動作させた環境
| Name | Version |
|---|---|
| Anaconda Navigator | 1.10.0 |
| CPU | Ryzen Threadripper 1950X |
| RAM | 32GB |
| VGA | GeForce RTX 3060 12GB |
では環境構築に入りましょう
-
まず Anaconda Prompt を管理者として実行します。
-
次に下記サイトを参考に3まで実施します。
(私の場合このサイトの通りでは動作しませんでした。)
- 追加で下記サイト記載の通り、diffusersのバージョンを指定します。
pip install --upgrade diffusers==0.4.1 transformers scipy
ここまででエラーが出ていなければ環境構築は完了しているはずです。
動かしてみる
- 実際に動作させるPythonコードは、huggingface(下記サイト)に掲載されているサンプルコードで良いかと思います。
上記のサンプルコードを sample.py という名前で waifu-diffusion フォルダに置いておきます。
- Anaconda Prompt を起動して仮想環境 ldm に入ります。
conda activate ldm
- 下記を実行します。
python sample.py
VRAMはフルで使います。
NSFWエラーについて
場合によっては下記エラーとなり、NSFWで出力が真っ黒の画像になるかもしれません。
これは、生成された画像がNSFWに該当するので黒塗りしました。という事になります。
Potential NSFW content was detected in one or more image. A black image will be returned instead.
Try again with a different prompt and/or seed.
対処としては2つあり、
- 同じpromptで再度トライ(意図していなくても、何度もNSFWになることもあります。)
- NSFWになっても生成エラーにしないコードとする
があります。
私の場合は、上に記載した huggingface のサンプルコードでさえ、9回中6回がNSFWで黒塗り出力になりました。
どのようなロジックでNSFWの判断をしているかを理解できるレベルではないので、
詳しい方の説明を探してみてください。
生成エラーにしないコードとする時は、ご自身で検索をお願いします。
(そのような使い方を推奨する意図は全く無い為)
10枚連続生成するコードに書き換え
# huggingface にあるサンプルコードの prompt = "" 以降を下記に変更
for i in range(10):
with autocast("cuda"):
image = pipe(prompt, guidance_scale=6)["sample"][0]
image.save("test" + str(i) + ".png")
生成枚数を10枚以上にしたい/もう少し減らしたい場合は、
for i in range(10):
の数字を変えて対応できます。
パラメータを変えたらどうなるか?
VRAMの消費量がおよそ半減した状態で生成できます。
torch_dtype=torch.float32
torch_dtype=torch.float16
生成中のVRAM消費量
生成された画像

guidance_scale=4
image = pipe(prompt, guidance_scale=4)["sample"][0]
生成された画像

guidance_scale=6
image = pipe(prompt, guidance_scale=6)["sample"][0]
生成された画像(※再掲…記事冒頭と同一条件の為)
guidance_scale=8
image = pipe(prompt, guidance_scale=8)["sample"][0]
生成された画像

guidance_scale=10
image = pipe(prompt, guidance_scale=10)["sample"][0]
生成された画像

guidance_scale 変更の結果(30枚のうちprompt通りの出力は何枚か)
| word | 4 | 6 | 8 | 10 |
|---|---|---|---|---|
| 1girl | 30/30 | 30/30 | 30/30 | 30/30 |
| red hair | 30/30 | 29/30 | 30/30 | 30/30 |
| open mouth | 30/30 | 30/30 | 30/30 | 30/30 |
| green background | 26/30 | 26/30 | 26/30 | 26/30 |
| looking at viewer | 30/30 | 30/30 | 30/30 | 30/30 |
| simple background | 26/30 | 30/30 | 29/30 | 30/30 |
| long hair | 30/30 | 29/30 | 28/30 | 30/30 |
| red eyes | 30/30 | 30/30 | 30/30 | 30/30 |
| white t-shirt | 20/30 | 23/30 | 21/30 | 25/30 |
num_inference_steps=15
image = pipe(prompt, guidance_scale=6, num_inference_steps=15)["sample"][0]
生成された画像
num_inference_steps=50
image = pipe(prompt, guidance_scale=6, num_inference_steps=50)["sample"][0]
生成された画像(※再掲…記事冒頭と同一条件の為)
num_inference_steps=100
image = pipe(prompt, guidance_scale=6, num_inference_steps=100)["sample"][0]
生成された画像

num_inference_steps=200 & guidance_scale=10
image = pipe(prompt, guidance_scale=10, num_inference_steps=200)["sample"][0]
生成された画像

num_inference_steps 変更の結果(30枚のうちprompt通りの出力は何枚か)
| word | 15 | 50 | 100 | 200 |
|---|---|---|---|---|
| 1girl | 30/30 | 30/30 | 30/30 | 29/30 |
| red hair | 30/30 | 29/30 | 29/30 | 30/30 |
| open mouth | 30/30 | 30/30 | 30/30 | 30/30 |
| green background | 25/30 | 26/30 | 27/30 | 28/30 |
| looking at viewer | 30/30 | 30/30 | 30/30 | 30/30 |
| simple background | 28/30 | 30/30 | 29/30 | 30/30 |
| long hair | 30/30 | 29/30 | 30/30 | 30/30 |
| red eyes | 30/30 | 30/30 | 30/30 | 30/30 |
| white t-shirt | 16/30 | 23/30 | 16/30 | 25/30 |
所感
- 服装の指定が通りにくいのはpromptの順番も関係しているかも。
- looking at viewerが100%なのは、イラストの多くが閲覧者に目線を向けているものが大多数だからと推定。
-
guidance_scaleの値を上げると、狙い通りのイラストがそこそこの精度で出力されるが、
背反としてどれも似通ったイラストが多くなる。
逆にこれの値を下げるとバラエティ豊かになるが精度が犠牲になる。 -
num_inference_stepsの値を下げると出力が早くなるが精度が下がる
逆に上げると出力に時間がかかる。精度は劇的には変わらないが向上している。
そして当たり品(?)の精度は上がっているような気がする。 - 結局生成ガチャなので、パラメータ調整に力を入れるより、
ある程度のパラメータで繰り返し出力して当たりを探す方がより素敵なイラストに出会えるように感じる。 - 出力精度的にガチャ感が強いので、ひたすら同じpromptで出力し続けて厳選をするのは想像より時間がかかりました。
(体感的に1/50でそこそこ良いイラスト、1/150でなかなか良いイラスト)