はじめに
突然ですが、Adobe AcrobatにSDKがあることを知っていますか?
AcrobatをPDFビューワーやPDF作成で使っている人がほとんどだと思いますが、実はAcrobatはC++プラグインとJavaScriptによる拡張機能の仕組みを持っています。自分のコードをAcrobatのメニューに追加したり、PDF操作APIを直接呼び出したりできます。
この拡張性はAcrobatの大きな強みの1つです。ユーザー自身が最新の技術をAcrobatに組み込んで業務に活かせます。たとえばAIを使った文書解析や自動処理をAcrobat上で直接動かすことができれば、PDFを中心とした業務フローをそのままに、AIの恩恵を取り込むことができます。
「それを使えば、個人情報の自動墨消しも作れるんじゃないか?」
そう思い立って、ローカルLLMとAcrobat SDKを組み合わせた自動墨消しシステムを作ってみました。この前後2部構成の記事で、その実装の話を書きます。
前編では、システム全体のアーキテクチャと、ローカルLLMによる個人情報(PII)検出サービスの実装について説明します。
全体像
まず全体像を示します。
PII.apiプラグインから直接Ollamaを呼び出す構成も考えられましたが、まずローカルLLMがPDFの個人情報をどれくらい正確に検出できるのかを確かめたかったことと、OpenAIにも切り替えられるFacadeとして設計したかったため、この構成にしました。本記事ではPII Detection Serviceの実装を中心に説明します。
システムは3層に分かれています:
| レイヤー | 技術 | 役割 |
|---|---|---|
| Acrobat DC層 | C++プラグイン + JavaScript | PDF操作・UIの入口 |
| PII Detection Service | Next.js | LLM呼び出し・結果整形 |
| LLM層 | Ollama + qwen3.5:4b, OpenAI | テキストからPII検出 |
Acrobat SDKとは
AcrobatはC++プラグインとJavaScriptによる拡張の仕組みを持っており、SDKを使うことでAcrobat本体と同等の権限でPDFを操作するコードを書くことができます。SDKの詳細な仕組みや拡張方法の種類、今回C++プラグインを選んだ理由については後編で説明します。
まずLLMだけで検証した
プラグインの実装前に、そもそもローカルLLMがPDF内のPIIをどれだけ正確に検出できるのかを確かめておく必要がありました。ローカルLLMはパラメータ数が少なく精度として不安だったことと、モデルの選択肢も多いため、後から差し替えられる設計にしておきたいと考えました。そこでまず、LLM単体での精度を確かめるための評価用Webツールとして、Next.jsのPII Detection Serviceを作りました。PDFをドラッグ&ドロップして、プロバイダー(Ollama / OpenAI)とモデルを選択し、検出結果を確認できる簡単なWebアプリです。十分な精度を確認してから、同じサービスをプラグインのバックエンドとして再利用するという順序で進めました。
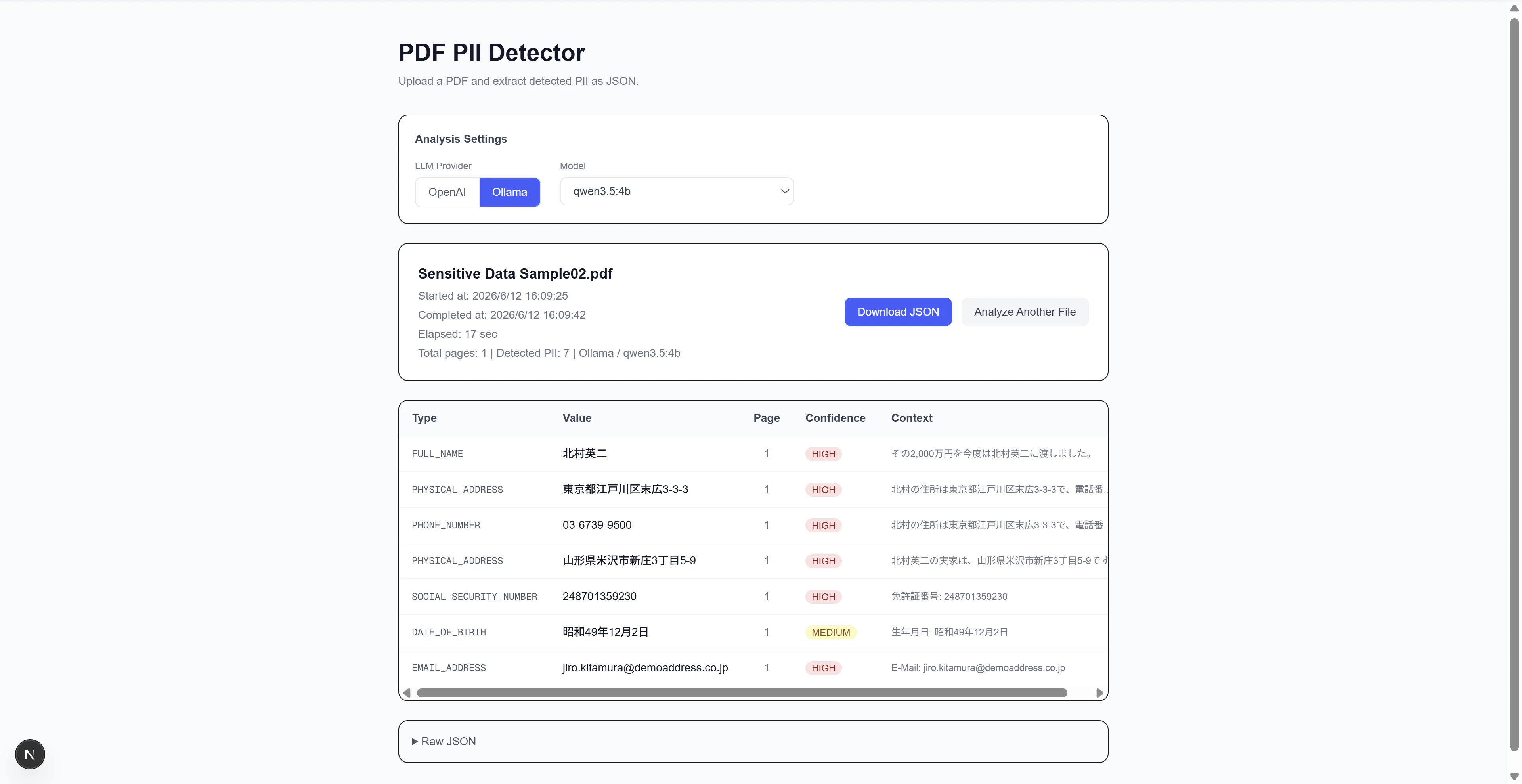
PII Detection Service のUI - PDFドラッグ&ドロップ画面
PII Detection Service の実装
PDFからテキストを抽出する
PDFはそのままLLMに渡せないので、まずテキストを抽出します。pdf-parse ライブラリを使ってページ単位でテキストを抽出し、1ページずつLLMに送る設計としました。
ページ単位にした理由:
- 大きなPDFでもメモリを使いすぎない
- ページ番号と紐づけてPII候補を返せる(後でPDF上の位置特定に使う)
- あるページでエラーが起きても他のページの処理を継続できる
OllamaでLLMを呼び出す
Ollamaの呼び出しで、Reasoning Modelに関して2つの問題にはまりました。
問題1:タイムアウト stream: false で呼び出すと、qwen3.5のようなReasoning Modelは推論が完了するまでHTTPレスポンスのヘッダーすら返してきません。結果、クライアント側でタイムアウトが発生します。
問題2:コンテキスト消費 Reasoning Modelはデフォルトのコンテキストウィンドウが60,000トークンと非常に大きく、初期化時のKVキャッシュ確保でPCのメモリを大量に消費します。リソースが限られた環境では、レスポンスがまったく返ってこないか、極端に遅くなります。
両問題に共通する対策は think: false です。今回のようなPIIの抽出はタスクとしては単純なので、thinkingプロセス自体をオフにすることで、長い推論チェーンの生成を抑え、タイムアウトとコンテキスト消費の両方を緩和できます。
それぞれの追加対策として、タイムアウトには stream: true でNDJSON形式のチャンクを逐次読み取ることでヘッダーを即時受信できるようにし、コンテキスト消費には num_ctx と num_predict をReasoning Modelのみ4096トークンに制限しています:
...(isThinkingModel && { num_ctx: 4096, num_predict: 4096 }),
実装全体はこうなっています:
const response = await fetch(`${OLLAMA_BASE_URL}/api/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: model,
messages: [
{ role: "system", content: SYSTEM_PROMPT },
{ role: "user", content: `Analyze the following text from page ${pageNum}...\n${pageText}` },
],
stream: true, // Reasoning Model でもヘッダーを即時受信できる
think: false,
format: PII_JSON_SCHEMA, // JSONスキーマを渡してJSON出力を強制
options: {
temperature: 0.1, // 低めに設定してハルシネーションを抑制
presence_penalty: 1.5,
},
}),
signal: controller.signal,
});
// NDJSONを都度読み取って結合する
const reader = response.body!.getReader();
let fullContent = "";
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
for (const line of chunk.split("\n")) {
const trimmed = line.trim();
if (!trimmed) continue;
try {
const data = JSON.parse(trimmed);
fullContent += data.message?.content ?? "";
} catch { /* incomplete chunk — skip */ }
}
}
format パラメータにJSONスキーマを渡すことで、LLMの出力を定義したスキーマに沿ったJSONへ強制しています。ページ単位でテキストを送る設計のため、num_ctx 4096で十分機能します。
なお、モデルによってはJSONをMarkdownのコードフェンスで囲んで返すことがあります。パース前に正規化する処理を入れています:
function extractJsonCandidate(value: string): string {
// thinking タグを除去してからコードフェンスを剥がす
const trimmed = stripMarkdownCodeFence(
value.replace(/<think>[\s\S]*?<\/think>/g, "").trim()
);
// { ... } または [ ... ] の範囲を抽出する
const objectStart = trimmed.indexOf("{");
const objectEnd = trimmed.lastIndexOf("}");
if (objectStart !== -1 && objectEnd > objectStart) {
return trimmed.slice(objectStart, objectEnd + 1);
}
return trimmed;
}
個人情報検出プロンプトの設計
LLMへのシステムプロンプトの設計が検出精度の鍵です。検出対象のカテゴリを明示的に定義しています:
FULL_NAME, FIRST_NAME, LAST_NAME, EMAIL_ADDRESS, PHONE_NUMBER,
PHYSICAL_ADDRESS, DATE_OF_BIRTH, SOCIAL_SECURITY_NUMBER,
NATIONAL_ID, PASSPORT_NUMBER, CREDIT_CARD_NUMBER,
BANK_ACCOUNT_NUMBER, IP_ADDRESS, DRIVER_LICENSE,
MEDICAL_RECORD_NUMBER, OTHER_PII
さらに、日本語の人名検出ルールも設定しました。日本語の人名は文脈なしには判断が難しく、「山田」が人名なのか地名なのかは周囲のテキストを見ないとわかりません。
プロンプトにはこのような文脈判断のルールを詳細に記述しています:
Name detection rules:
- Detect LAST_NAME even when only the family name appears, if the
surrounding text indicates it refers to a specific person.
- A standalone name should be extracted if there is evidence such as:
- nearby person markers: 氏名, 姓, 名, フリガナ, 署名, 申請者, 担当者
- honorifics: 様, 氏, 先生, さん
- the same document contains the person's full name elsewhere
Examples:
- "申請者: 山田" -> LAST_NAME
- "山田様" -> LAST_NAME(value は "山田"、"様" は含まない)
- "氏名: 山田 太郎" -> FULL_NAME
各検出結果には信頼度スコア(HIGH / MEDIUM / LOW)も付けています。
ローカルLLMに対応した理由
PIIの検出にパブリックなLLMを使う場合、PDFの内容がクラウドへ送信されることになります。用途や契約よってはそれで問題ありませんが、機密性の高い文書を扱う場面では、情報をどこに送るかをコントロールしたいというニーズがあります。
ローカルLLMであれば、データは一切外部に出ません。精度よりも情報管理を優先したい、あるいはネットワーク的に閉じた環境で動かしたいといったケースで有効な選択肢です。
今回のシステムをOpenAIとローカルLLM(Ollama)の両方に対応した設計としたのも、この考えからです。用途や環境に応じてプロバイダーを選べるようにしておくことで、より幅広いシーンで使えるシステムになります。
前編まとめ
前編では以下をカバーしました:
- PII Detection Service:Next.jsで作ったLLM評価プラットフォーム
- Ollamaクライアント:ストリーミング必須・Reasoning Model対応・JSONスキーマ強制
- プロンプト設計:日本語のPII検出の工夫と信頼度スコア
- ローカルLLMに対応した理由:情報管理の観点から、プロバイダーを選べる設計に
後編では、Acrobat SDK C++プラグインの実装に踏み込みます。SDKの仕組みと拡張方法を押さえた上で、PII Detection Serviceを呼び出すプラグインを実装し、Action WizardからPDFに墨消しアノテーションを付与するところまでを説明します。