はじめに
2024年4月に改正された 障害者差別解消法 では、民間企業においても「合理的配慮の提供」が義務化されました。また、合わせて 環境の整備(バリアフリー化のための仕組みや体制づくり) が努力義務とされています。
この法律において「すべてのWebサイトやPDFをアクセシブルにしなければならない」と規定されているわけではありませんが、企業にとっては 将来に備えた文書のアクセシビリティ対応 が重要性を増しているのは間違いありません。既に欧米では、コンテンツのアクセシビリティが法律で義務化され、W3Cが定める国際標準ガイドラインであるWCAG(Web Content Accessibility Guidelines)に対応することが求められています。
PDFは、契約書・マニュアル・教材・報告書など幅広く利用されている一方で、タグが付与されていないPDF が多く存在します。タグがないPDFはスクリーンリーダーで正しく読み上げられず、検索性やリフロー表示も不十分なため、アクセシビリティの大きな障壁となります。
そこで役立つのが Adobe PDF Accessibility Auto-Tag APIです。このAPIを使えば、既存のPDFに後から自動的にタグを付与でき、大量の文書を効率的にアクセシブル化することが可能になります。
タグ付きPDF
PDFには「タグ」という概念があり、見た目のレイアウトだけでなく、
- 見出し(Heading)
- 段落(Paragraph)
- 表(Table)
- リスト(List)
といった文書の論理構造を定義することができます。
これにより、スクリーンリーダーによる読み上げや検索性の向上、さらにリフロー(折り返し)表示などが可能になります。特にアクセシビリティ基準(WCAGやPDF/UA)に準拠するうえでタグは必須要素です。
PDFのタグの有無は、PDFのプロパティを見ることで確認ができます。
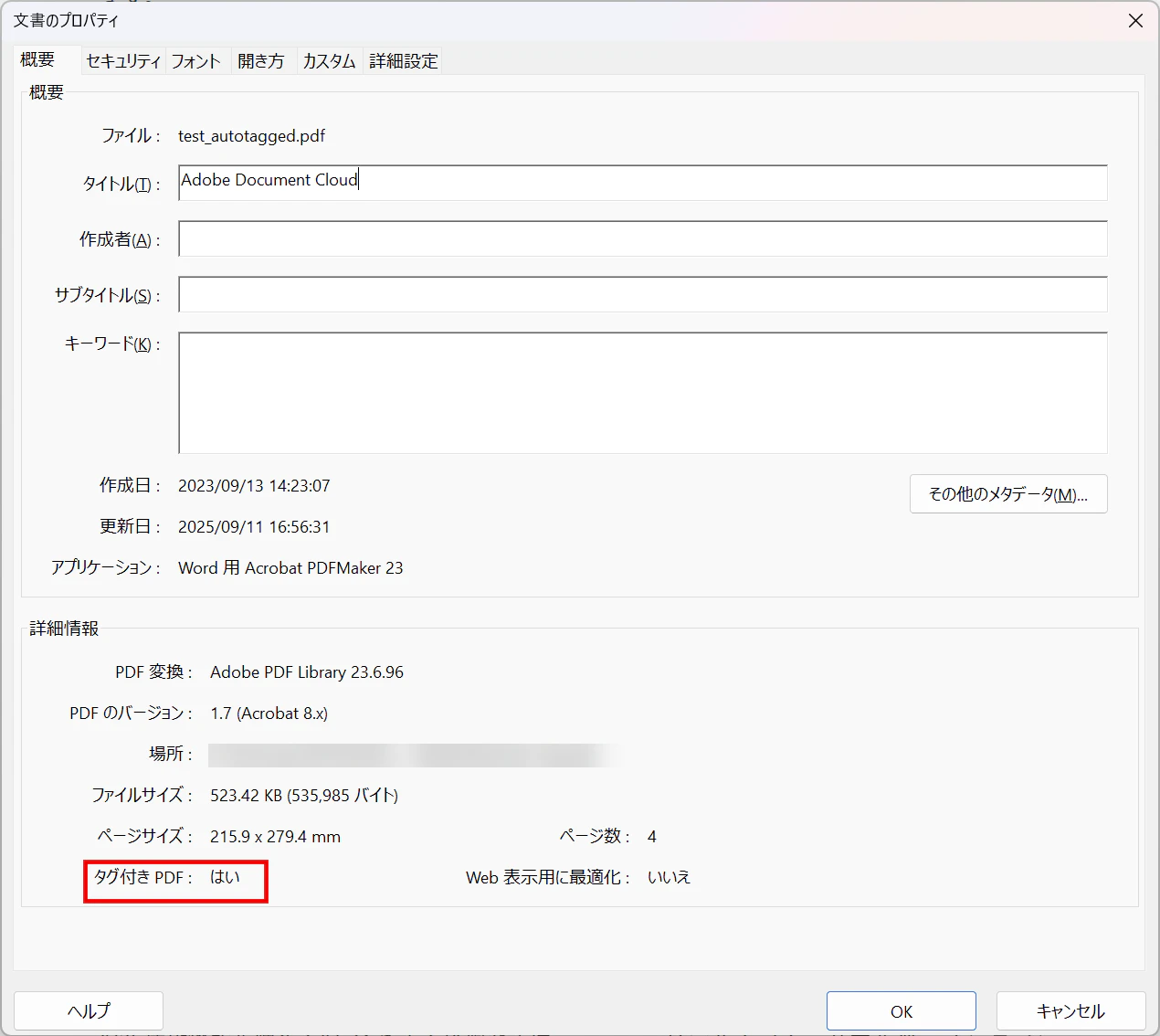
また、タグの付き方は、「アクセシビリティタグ」(Acrobatでは右側のリボンメニュー。表示されていない場合には、リボンを右クリック)から確認することができます。
タグのないPDF
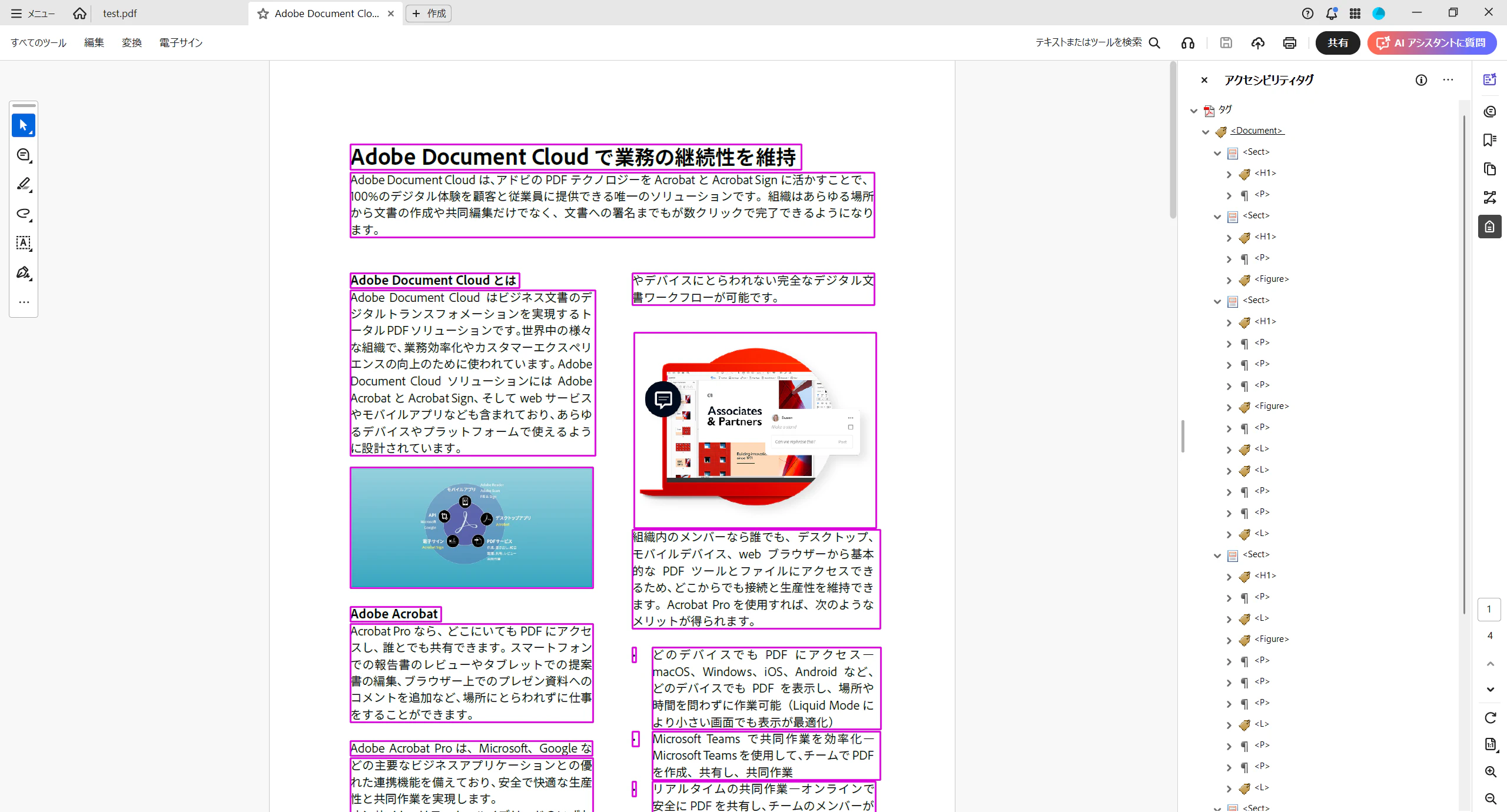
タグのあるPDF(Auto-Tag APIで処理後)
さらに、Auto-Tag APIは スキャンされた画像のPDF に対してもタグ付けを行うことができます。処理されたPDFでは傾きも補正され、テキストの検索も可能となります。
画像のPDF

画像のPDF(Auto-Tag APIで処理後)

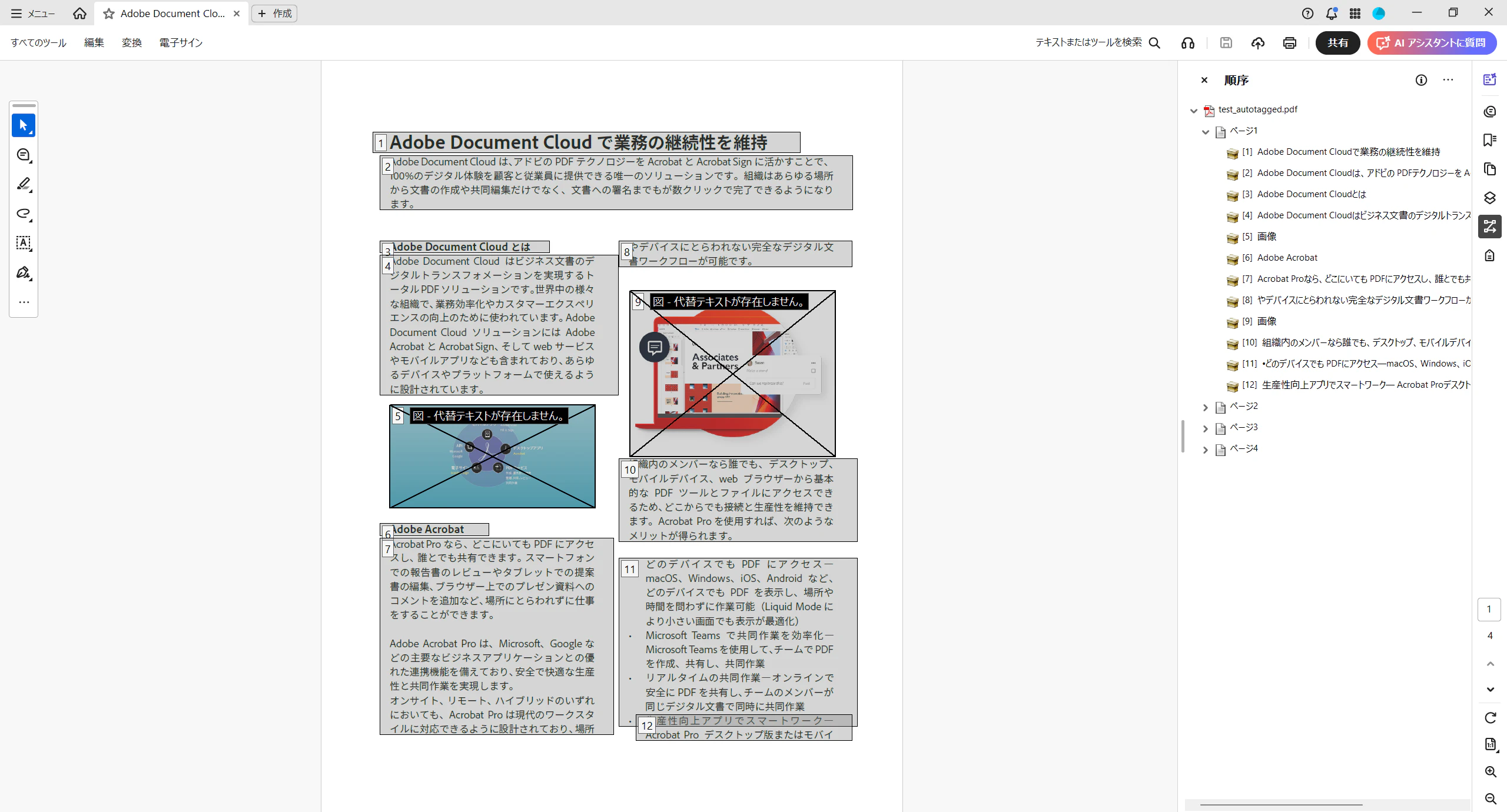
読み上げ順序の確認もタグの確認と同様に、右側リボンメニューの「順序」から確認ができます。
Adobe PDF Accessibility Auto-Tag API
Adobe PDF Accessibility Auto-Tag API(以下Auto-Tag API)は、Adobe Acrobat Servicesの一部として提供されているAPIです。主な機能は以下の通りです:
- PDFに対して自動でタグ付け(タグが既に付いているPDFについても確認、修正)
- スキャンされた画像PDFに対してもタグ付け可能
- 文章の流れを理解し、正しい読み上げ順序を設定
- タグ付け処理についてのレポートの出力
このAPIにより、既存の大量のPDF文書に対して自動的、かつ効率良くアクセシブル化することができます。
使い方 (Pythonの例)
Auto-Tag APIは他のAcrobat Services APIと同様に、RESTful APIとしてアクセスできます。また、Java, .NET, Node.jS, PythonのSDKも用意されています。ここではPythonのコードサンプルを紹介します。
Pythonで利用する場合は、pdfservices-sdkを事前にインストールします。
$ pip install pdfservices-sdk
Acrobat Services APIを利用するには、事前に Client ID と Client Secret を取得する必要があります。
取得した値は、それぞれ環境変数として
- PDF_SERVICES_CLIENT_ID
- PDF_SERVICES_CLIENT_SECRET
に設定し、コードから参照できるようにします。
コードサンプル
import sys
import os
from adobe.pdfservices.operation.auth.service_principal_credentials import ServicePrincipalCredentials
from adobe.pdfservices.operation.pdf_services import PDFServices
from adobe.pdfservices.operation.io.cloud_asset import CloudAsset
from adobe.pdfservices.operation.io.stream_asset import StreamAsset
from adobe.pdfservices.operation.pdf_services_media_type import PDFServicesMediaType
from adobe.pdfservices.operation.pdfjobs.jobs.autotag_pdf_job import AutotagPDFJob
from adobe.pdfservices.operation.pdfjobs.params.autotag_pdf.autotag_pdf_params import AutotagPDFParams
from adobe.pdfservices.operation.pdfjobs.result.autotag_pdf_result import AutotagPDFResult
def addTags(args):
# コマンドライン引数の解析
if len(args) == 2 and args[0] == "-report":
file_path = args[1]
generate_report = True
else:
file_path = args[0]
generate_report = False
# 入力ファイルPathから出力ファイルPathを生成
base, ext = os.path.splitext(file_path)
output_file_path = base + "_autotagged" + ext
report_file_path = base + "_report.xlsx"
try:
# 対象ファイルを開く
with open(file_path, 'rb') as file:
content = file.read()
# Credentialsの設定
credentials = ServicePrincipalCredentials(
client_id = os.getenv("PDF_SERVICES_CLIENT_ID"),
client_secret = os.getenv("PDF_SERVICES_CLIENT_SECRET"),
)
# PDFサービスの初期化
pdf_services = PDFServices(credentials)
# 対象ファイルのアップロード
uploaded_file = pdf_services.upload(input_stream=content, mime_type=PDFServicesMediaType.PDF)
# Jobの作成
params = AutotagPDFParams(generate_report=generate_report)
job = AutotagPDFJob(input_asset=uploaded_file, autotag_pdf_params=params)
# Jobの実行
result = pdf_services.submit(job)
pdf_services_response = pdf_services.get_job_result(result, AutotagPDFResult)
# 結果の取得と保存
result_asset = pdf_services_response.get_result().get_tagged_pdf()
stream_asset = pdf_services.get_content(result_asset)
with open(output_file_path, 'wb') as output_file:
output_file.write(stream_asset.get_input_stream())
if generate_report:
report_asset = pdf_services_response.get_result().get_report()
report_stream_asset = pdf_services.get_content(report_asset)
with open(report_file_path, 'wb') as report_file:
report_file.write(report_stream_asset.get_input_stream())
print(f"Process Completed : {output_file_path}" + (f", {report_file_path}" if generate_report else ""))
except Exception as e:
print(f"Exception was occurred: {e}")
def main():
args = sys.argv
if (len(args) == 3 and args[1] == "-report") or len(args) == 2:
addTags(args[1:])
else:
print("Usage: python auto-tag-test.py [-report] <filePath>")
if __name__ == "__main__":
main()
実行
上記のサンプルコードをご覧いただければわかりますが、タグ付きPDFは元のファイル名_autotagged.pdfという名前で出力されます。レポートも出力する場合には、-reportオプションを追加します。
$ python main.py [-report] <filepath>
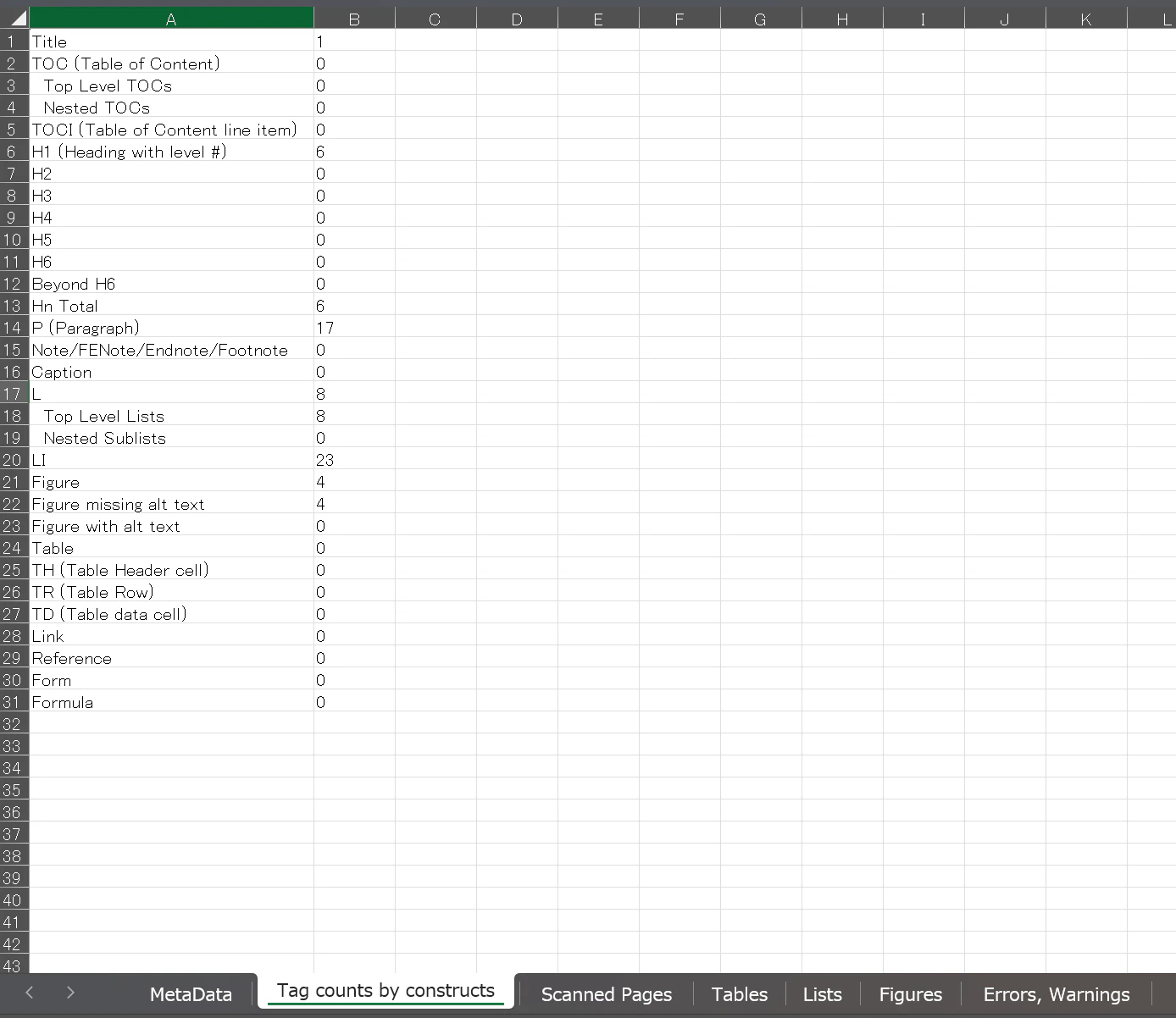
レポートはxlsx形式で出力され、各タブにはメタデータ、付与したタグの数、スキャンしたページ、表、リスト、図、その他処理中のエラー情報が出力されます。
まとめ
Adobe PDF Accessibility Auto-Tag APIを利用することで、タグが存在しないPDFでも後から自動的にタグを付与でき、PDF文書のアクセシビリティを大幅に向上させることができます。
PDFを再作成することなく既存の資産を効率的に活かしながら、文書をよりユーザーフレンドリーにし、さらに組織としての文書配布環境の整備にもつなげられる点は、大きなメリットです。