OpenStreepMa(OSM) API から施設情報などを取得し、特徴量の候補にしようとして、
欠損値をそのままモデルにいれるよりも、欠損値フラグ列 を追加するだけで、大きく精度が改善した。
オープンデータを使うと、「本当にゼロ」なのか「データ取得できなかっただけ」なのかをどう扱うかは、モデル精度に大きく影響することがわかった。
TL;DR
- 0 = 存在しない(意味のある観測値)
- NaN = データ取得できなかった(情報不足)
- NaNフラグを追加すると精度改善することが多い
モデル
- モデル
- LightBGM
- 精度指標
- RMSE
- R²
1. 0とNaNは区別する
- 施設が存在しない → 0
- データを取得できなかった → NaN
# OSMから施設数が取れなかった自治体フラグ
df['OSM_missing'] = df[['駅密度','スーパー密度','病院密度','学校密度']].isna().all(axis=1).astype(int)
2. NaNフラグを追加する
LightGBMにNaNを渡すだけでも動くけど、NaNフラグ列を加えた
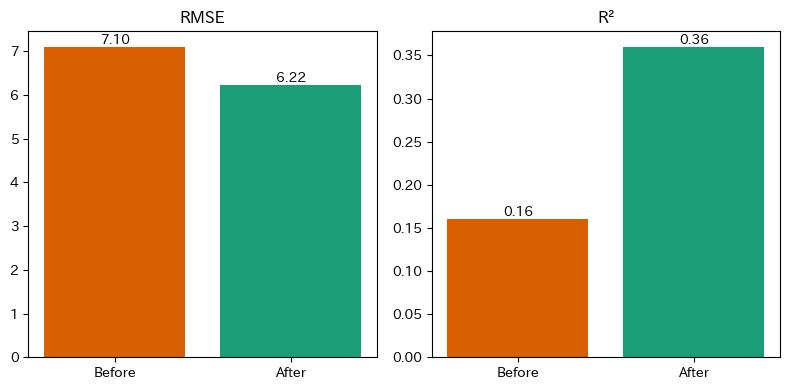
| Before | After |
|---|---|
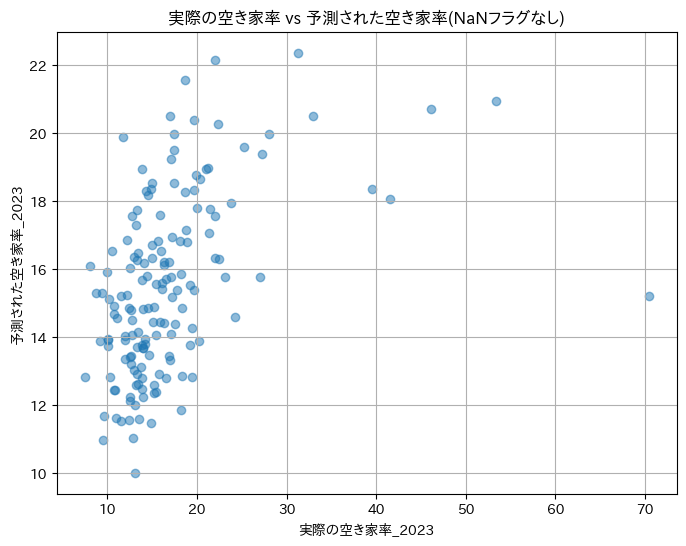 |
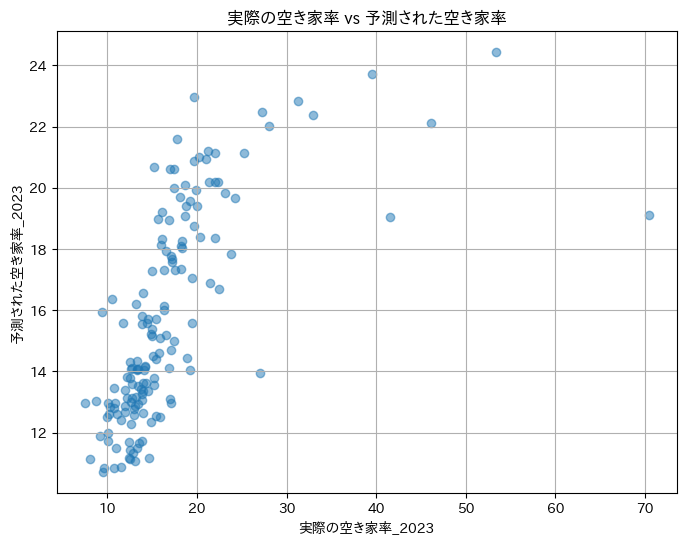 |
💡R²が2倍以上改善!
まとめ
- 0は0、NaNはNaNとして扱う
- NaNフラグを追加するとモデルが「欠損そのもの」を学習できる
- 欠損値処理はただの前処理じゃなくて、特徴量エンジニアリング
- オープンデータ・地理データでは有効?!
まだまだR²が低い。ベースライン作成がんばろ…