まえがき
ニジボックスではキャリア採用向けにWantedlyを利用しています。 (興味があればこちらから)
で、ストーリーが更新されたときに、社内のSlackなんかにも通知できないかなと思ってソースを眺めてみたのですが、
RSSフィードが存在しません。1
となると、パーサーを駆使してデータ構造をうまいこと加工する必要が出てくる...
そのために何をやったかを、この記事では残します。
本日のスタートとゴール
素材となるのは、ニジボックスのWantedlyにある、「ストーリー」です。
https://www.wantedly.com/companies/nijibox/feed
ここから、「別のアウトプットに耐えられるようなデータ構造」を抽出するコードを書いていきます。
答え(=出来上がったもの)
import json
import pprint
import requests
from bs4 import BeautifulSoup
URL = 'https://www.wantedly.com/companies/nijibox/feed'
resp = requests.get(URL)
soup = BeautifulSoup(resp.content, 'html.parser')
# <script data-placeholder-key="wtd-ssr-placeholder"> の中身を取ってきてる
# このタグの中身はJSON文字列なのだが、先頭に'// 'があるため、読み込み用に除去
feed_raw = soup.find('script', {'data-placeholder-key': "wtd-ssr-placeholder"}).string[3:]
feeds = json.loads(feed_raw)
# JSON全体の中のbodyにいろいろ入っているのだが、body自体がdictで企業キーと思われるキーになってた
# ただし、1個しか無いっぽいので、超雑に抽出
feed_body = feeds['body'][list(feeds['body'].keys())[0]]
# 固定ポストと思われる項目
pprint.pprint(feed_body['latest_pinnable_posts'])
これを実行すると、こんな感じになります。
$ python3 feed-from-wantedly.py
[{'id': 188578,
'image': {'id': 4141479,
'url': 'https://d2v9k5u4v94ulw.cloudfront.net/assets/images/4141479/original/9064f3ba-9327-4fce-9724-c11bf1ea71e2?1569833471'},
'post_path': '/companies/nijibox/post_articles/188578',
'title': 'まずは気軽にカジュアル面談から!ニジボックスが求職者の方に伝えたいこと、採用への思い'},
{'id': 185158,
'image': {'id': 4063780,
'url': 'https://d2v9k5u4v94ulw.cloudfront.net/assets/images/4063780/original/44109f75-6590-43cb-a631-cb8b719564d4?1567582305'},
'post_path': '/companies/nijibox/post_articles/185158',
'title': '【初心者向け】デザインは「感覚」ではなく「理論」。今日からできる!UIデザイナーになるための作法'},
{'id': 185123,
'image': {'id': 4062946,
'url': 'https://d2v9k5u4v94ulw.cloudfront.net/assets/images/4062946/original/ff2169c7-568e-4992-b082-56f1e1be2780?1567573415'},
'post_path': '/companies/nijibox/post_articles/185123',
'title': 'ICSの池田さんとReact勉強会を行いました!'}]
準備
今回は、以下のような環境で作ってます。
- Python 3.7.3
- beautifulsoup4==4.8.1
- requests==2.20.0
順に見ていく
「requestsでレスポンスを受け取り、BeautifulSoup4を使ってパースする」までは、いわゆるよくあることなので、今回はスキップします。
よりパースするところはどこか
今回は「注目の投稿」のところを見つけてパースするわけなのですが、ここで2個ほど課題が出てきます。
-
id="posts"というわかりやすい領域はあるが、その中に結構な数のdivがあって面倒 - レスポンスの時点では、
body部分はほぼ空っぽ
特に後者が厄介で、タグをsoup.findで追いかける方式は通用しません。2
じゃあ、どこをパースするかというと
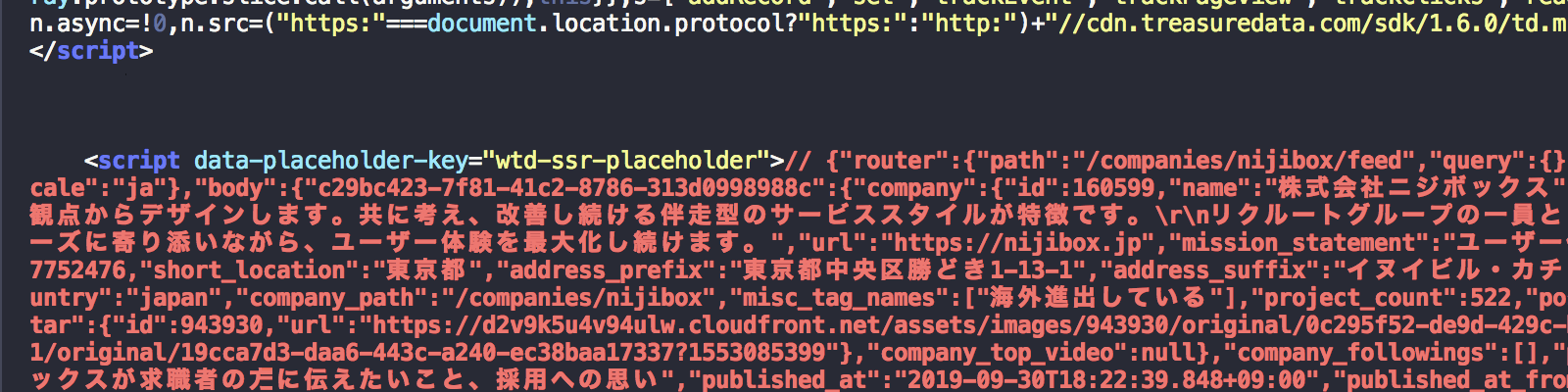
ここです。
WantedlyのSSR考察(ソースのみ)
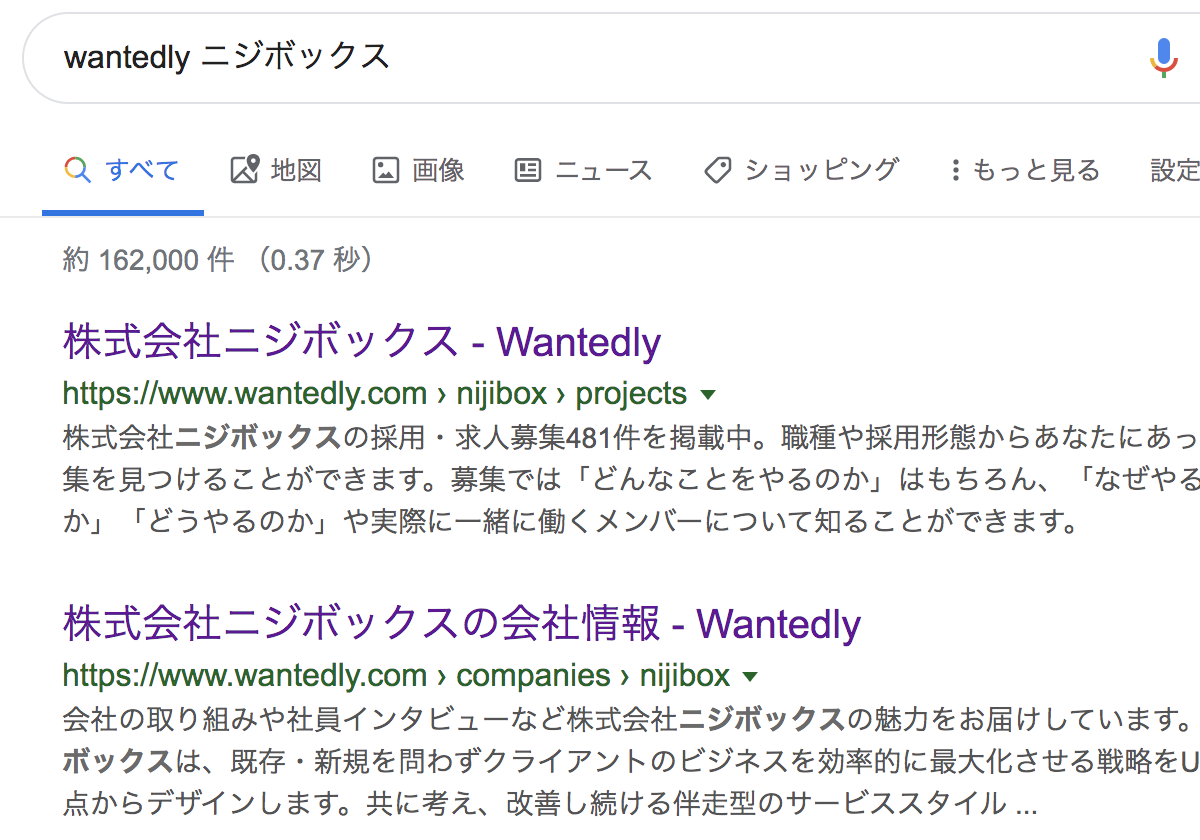
これは、上記の通り「ニジボックス」「Wantedly」でGoogle検索した結果なのですが、レスポンスのbodyタグ内にはない概要などがちゃんと載っています。
WantedlyのサイトはコンテンツそのものはJS実行時の素材JSONとして持たせて、これをレンダリングする仕様のようです。
BeautifulSoupで該当項目を抽出する
BeautifulSoupが仕事をするのは、実質この行のみです。
feed_raw = soup.find('script', {'data-placeholder-key': "wtd-ssr-placeholder"}).string[3:]
BeautifulSoupのfind_allはタグだけでななく属性レベルでの絞り込みが効くので、一発で取りたい中身を取れました。便利ですね。
なお、string[3:]としているのは、この中身の先頭には// というJSONとしてパースするには邪魔な文字が入っているからです。3
後はJSON文字列をオブジェクト化してパースのみ...と思いきや
ざっくり書くと、パース化したオブジェクトの中身は、こんな感じになってます。
{
"router":{"略"},
"page":"companies#feed",
"auth":{"略"},
"body":{
"c29bc423-7f81-41c2-8786-313d0998988c":{
"company":{"略"}
}
}
}
謎のUUIDが。多分企業IDとは別に使う何かなんでしょう。
というわけで、この中身まで掘り進む必要があります。
feed_body = feeds['body'][list(feeds['body'].keys())[0]]
幸いですが、 bodyの中身に使われているキーは1社分だけみたいなので、超雑に奥に分け入っていきます。
最後に項目を抽出
今の所、便利そうな項目は次の2個です。
posts: これまでの全ストーリー?
latest_pinnable_posts: 「注目の投稿」に該当する部分
今回は最小限だけ必要ということにして、latest_pinnable_postsを出力してフィニッシュ。お疲れ様でした。
pprint.pprint(feed_body['latest_pinnable_posts'])
Slack通知は?
現時点ではまだ作ってません。
- 直前投稿のパース結果との差分を見て、新しい分だけ通知
- RSSフィード化して、SlackIntegrationに丸投げ 4
などのようなアプローチがありますね。ひとまず今回は対象外。
振り返り
久々にBeautifulSoup4を触りましたが、やっぱり機能が揃ってて使いやすいですね。