はじめに
TRIAL&RetailAI Advent Calendar 2025 の 3 日目の記事です。
昨日は @mizoguchi_ryosuke さんの『遺伝性とマンスキーから学ぶ「○○ で決まる」の罠:生成 AI で実践する誠実な分析』でした。生成 AI 時代に求められる「分析の誠実さ」を学べる良記事ですので、ぜひご覧ください。
本記事も生成 AI がテーマです。AI エージェントにコード実行を許可する際の「安全性」にフォーカスします。
Claude や ChatGPT では「AI がタスク遂行に必要なコードを自分で書いて実行する」機能がすでに使えます。しかし、この機能を自前のエージェントに組み込むとなると話は別です。
Anthropic は 2025 年 11 月の記事で、コード実行パターンの威力を示しました:
- トークン消費: 150,000 → 2,000 tokens(98.7% 削減)
同時に、こうも述べています:
Running agent-generated code requires a secure execution environment with appropriate sandboxing, resource limits, and monitoring.
効率化のメリットを得るには、セキュリティの実装が不可欠となります。
本記事で紹介する Python Code Executor MCP サーバーは、具体的にどう実装するのかを示す例として紹介します。まずは動作を見てみましょう。
実際の動作
デモ 1: 画像処理タスク
ADK(Agent Development Kit) で実装したエージェントに Python Code Executor MCP サーバーを連携させ、「画像から目を検出して」と依頼した場合の動作です。画像は事前に Google Cloud Storage へアップロードしてます。
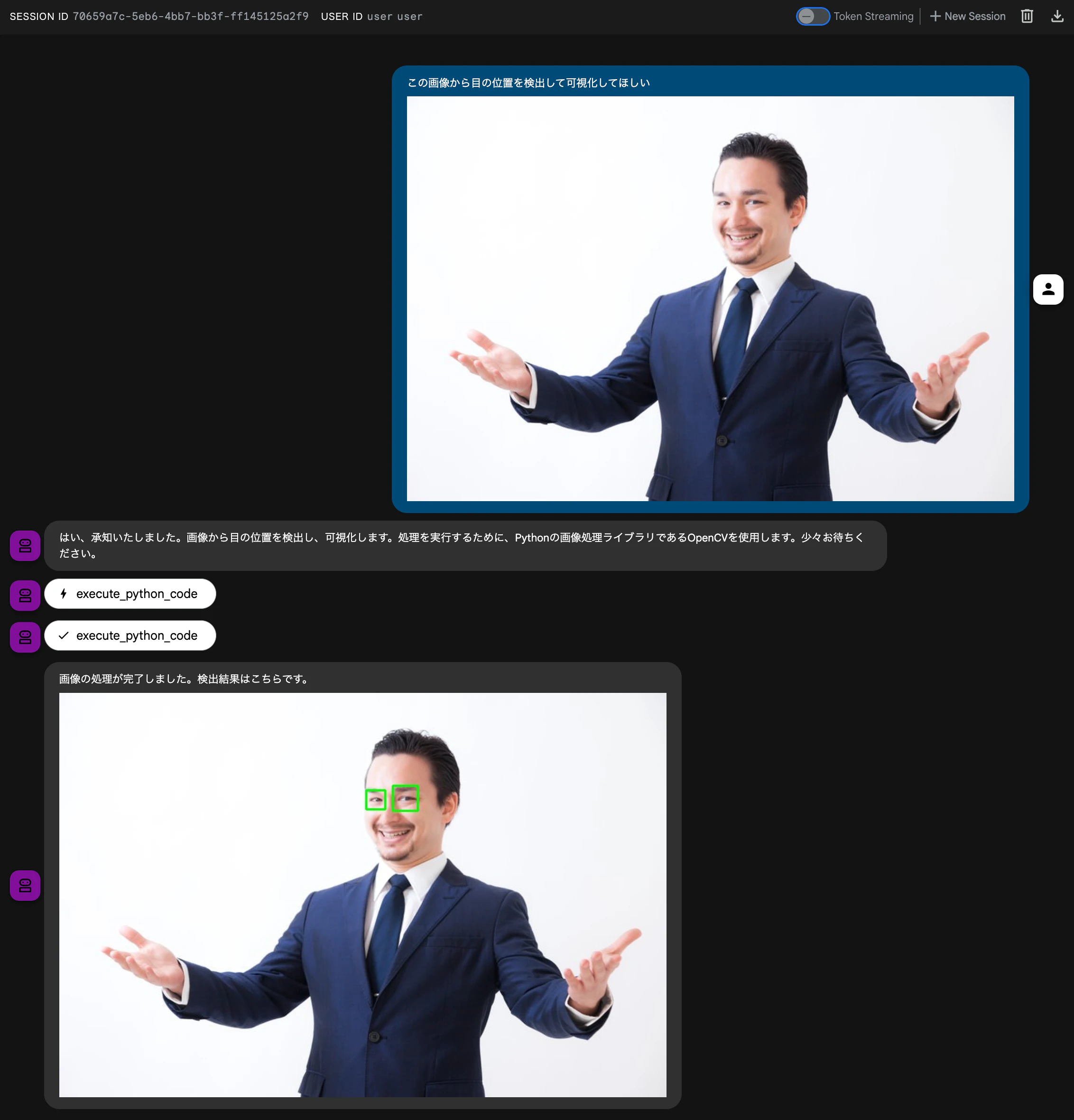
図: ADK による Python Code Executor MCP サーバー連携例
MCP サーバーへのツール実行リクエスト、および MCP サーバーからのレスポンスは以下のとおりです。
ツール実行リクエスト(code は省略):
{
"method": "tools/call",
"params": {
"name": "execute_python_code",
"arguments": {
"code": "import cv2\n# ... OpenCV による目検出処理 ...\nprint(\"目の位置を検出した画像を保存しました。\")",
"packages": ["opencv-python"],
"gcs_input_files": [
"https://storage.cloud.google.com/my-bucket/sample/demo1.jpg"
]
}
}
}
実行結果:
{
"stdout": "目の位置を検出した画像を data/eyes_detected.jpg に保存しました。\n",
"artifacts": [
{
"path": "data/eyes_detected.jpg",
"gcs_url": "https://storage.cloud.google.com/my-bucket/output/.../data/eyes_detected.jpg"
}
],
"isError": false
}
AI エージェントが生成したコードが実行され、必要な Python パッケージ(OpenCV)のインストールと、成果物の GCS への自動アップロードが行われています。
デモ 2:セキュリティ検証の動作
AI エージェント が万が一危険なコードを生成した場合、Python Code Executor MCP サーバーはコード実行前にブロックします。
# 危険なコード例
import os
os.system("rm -rf /") # システム破壊コマンド
実行結果(text 部のみ抽出):
CodeExecutionError: Code validation failed: 2 violation(s) found:
DANGER violations (2):
- Line 2: Forbidden import 'os' (security risk)
- Line 3: Dangerous function call 'os.system' (security risk)
Risk Level: DANGER
Recommendation: This code contains dangerous operations and should not be executed.
セキュリティチェックの種類:
- ✅ AST ベースの静的解析:構文木レベルで危険なパターンを検出
- ✅ ホワイトリスト方式:明示的に許可されたライブラリのみ使用可能
- ✅ リスクレベル分類:SAFE / WARNING / DANGER の 3 段階評価
特筆すべきは、これらすべてが数秒〜数十秒程度で完了し、かつ安全に動作することです。
Anthropic が示した「効率化」と「セキュリティ」の両立が実現されています。それでは、この動作を支える設計思想と実装について、詳しく見ていきましょう。
AI にコード実行を許可する際の課題
この動作を支える設計思想を理解するために、まず Anthropic が提唱するコード実行パターンの背景を整理します。
Anthropic の提唱するコード実行パターン
Anthropic は 2025 年 11 月に、コード実行に関する 2 つの重要な記事を公開しました。
-
Code execution with MCP: Building more efficient agents(2025/11/04)
- 「ツールを直接呼び出す代わりに、コードを書いてツールを呼び出す」というアイデア
- トークン消費を 150,000 tokens から 2,000 tokens へ 98.7% 削減することが可能
-
Introducing advanced tool use on the Claude Developer Platform(2025/11/24)
- 上記の概念を公式機能として実装
- Programmatic Tool Calling により、Claude がコードを書いてツールを呼び出し、中間結果をコンテキストから除外することが可能
これらの記事は、コード実行の「なぜ必要か」と「何ができるか」を示しています。以下の表で、Anthropic の記事と本実装の対応関係を整理します。
| 課題 | Anthropic の記事 | Python Code Executor の解決策 |
|---|---|---|
| トークン効率 | ✅ 98.7% 削減(Code Execution with MCP) | ✅ Anthropic のアプローチを踏襲 |
| 中間結果の除外 | ✅ Programmatic Tool Calling で 37% 削減 | ✅ コード実行環境内でデータ処理 |
| セキュリティ検証 | ⚠️ 「安全な実行環境が必要」と言及 | ✅ AST 解析(実行前)+ ホワイトリスト |
| 隔離環境 | ⚠️ サンドボックス化が必要と言及 | ✅ uvx による依存関係の分離(パッケージ層) |
| ファイル管理 | ⚠️ 具体的な実装方法は未言及 | ✅ GCS 入出力の自動化、UUID ベースのパス管理 |
Python Code Executor の設計思想
本実装は以下の 2 層で防御します:
| レイヤー | 防御方式 | 防御時点 | 目的 |
|---|---|---|---|
| 🔒 レイヤー 1 | AST 解析、ホワイトリスト | 実行前 | 危険なコードを実行前にブロック |
| ⚡ レイヤー 2 | uvx による環境分離 | 実行時 | 独立した依存関係環境でクリーンに実行 |
アーキテクチャの全体像
Python Code Executor は、3 つの主要なレイヤーで構成されています。
アーキテクチャ図
主要な処理フロー
| フェーズ | 内容 | 目的 |
|---|---|---|
| 1. 検証 | コードが安全かどうかを AST 解析で事前にチェック | 危険なコードを実行前にブロック(レイヤー 1) |
| 2. 実行 | uvx で分離された環境でコードを実行 | 独立したパッケージ環境でクリーンに実行(レイヤー 2) |
| 3. 永続化 | 必要に応じて GCS とファイルをやり取り | 入力データの取得と生成ファイルの保存 |
| 4. 返却 | 実行結果とアーティファクトをクライアントに返却 | 実行結果の提供 (Runtime Error 時は Traceback を含む) |
各レイヤーの詳細は以降のセクションで解説します。
レイヤー 1: セキュリティ検証(実行前の防御)
このレイヤーは、コード実行前に危険なコードをブロックする最初の防御線です。
Anthropic の記事では「サンドボックス化が必要」と述べられていますが、具体的にどう実装すべきでしょうか?
本実装のアプローチは、実行前の静的解析です。コード検証は、Python Code Executor の最も重要なセキュリティレイヤーです。ここでは、AST 解析、ホワイトリスト方式、リスクレベル分類の 3 つの仕組みが連携して動作します。
AST 解析による構造的なコード検証
「危険なコードを検出する」と聞くと、正規表現で eval や os.system を探せばいいと思うかもしれません。しかし、それでは不十分です。
# 正規表現 "eval" で検索すると...
evaluation_score = 100 # ❌ 誤検知:ただの変数名
# This evaluates the model # ❌ 誤検知:ただのコメント
eval("malicious_code") # ✅ 検出したい:危険なコード
正規表現は「文字列のパターン」を見ます。一方、AST(抽象構文木)は「コードが何をするのか」を見ます。
Python Code Executor は、コードを AST として解析し、関数呼び出しノードとして eval() を認識します。変数名やコメントに含まれる文字列 "eval" は、関数呼び出しではないため検出対象になりません。
# AST は「構造」を見る
eval("code") # Call ノード → 危険な関数呼び出しとして検出
import os # Import ノード → 禁止モジュールとして検出
os.system("rm -rf /") # Attribute + Call ノード → 危険なメソッド呼び出しとして検出
この「構造で判断する」アプローチにより、単純な難読化も検出できます:
# これらは全て危険な動作
eval("code") # 基本形 → 検出可能
getattr(__builtins__, "eval") # 間接的な呼び出し → __builtins__ アクセスとして検出
globals()["eval"] # 辞書経由 → globals() 自体を警告対象に
実装は ast.NodeVisitor を継承したクラスで、コードの各ノードを走査します:
class ASTSecurityVisitor(ast.NodeVisitor):
def visit_Import(self, node: ast.Import) -> None:
"""Import文を構造的に解析"""
for alias in node.names:
module_name = alias.name.split(".")[0]
if module_name in self.policy.forbidden_imports:
self.violations.append(...) # 違反として記録
ホワイトリスト方式でデフォルトを安全に
Python Code Executor はホワイトリスト方式を取ります。デフォルトで全てを拒否し、明示的に安全と確認されたもののみを許可します。
# 許可されるモジュール例
allowed_imports = {
# データサイエンス系
"numpy", "pandas", "matplotlib", "seaborn", "scipy", "sklearn",
"cv2", "PIL", "keras", "xgb", "lgb",
# 標準ライブラリ(安全なもののみ)
"math", "random", "datetime", "json", "csv",
"collections", "itertools", "functools"
}
# 明示的に禁止されるモジュール
forbidden_imports = {
"subprocess", "os", "sys",
"socket", "urllib", "requests",
"shutil", "__builtin__", "__builtins__"
}
この設計により、非ホワイトリストのライブラリが使用された場合、自動的にブロックされます。
一方で、ホワイトリストは用途に応じてカスタマイズ可能です。厳格な本番環境では許可モジュールを最小限に、探索的なデータ分析がメインであれば pandas、numpy、matplotlib などをデフォルトで許可しておくといった柔軟な運用ができます。
3 段階のリスクレベル分類
セキュリティレベルも 3 段階で分類されており、開発者はコンテキストに応じた判断ができます。厳格な本番環境では警告すらブロックし、開発環境では警告付きで実行を許可する、といった運用が可能です。
- SAFE(安全):データ分析や基本的な計算など、明確に安全なコード
- WARNING(警告):未定義変数の使用や、非ホワイトリストライブラリのインポートなど、慎重に扱うべきコード
-
DANGER(危険):
eval()の使用、ファイルシステムアクセス、サブプロセス実行など、実行すべきでないコード
# SAFE: 基本的なデータ分析
import pandas as pd
df = pd.DataFrame({"values": [1, 2, 3]})
print(df.mean())
# WARNING: 未定義変数の可能性
print(unknown_var)
# DANGER: 動的コード実行
eval("import os; os.system('ls')")
Python は高度に動的な言語であるため、AST 解析ですべての悪意あるパターン(複雑なメタプログラミングやリフレクションを用いた攻撃など)を完全に検知することは理論的に困難です。本実装における AST 解析は、「意図しないミスや一般的な危険操作」を防ぐための強力なガードレールとして機能します。悪意のある攻撃者が想定される環境では、これに加え OS レベルのサンドボックス(gVisor, Firecracker 等)の併用を推奨します。
レイヤー 2: 一時的実行環境(依存関係のクリーンアップ)
バリデーションを通過したコードを実行するフェーズです。
Anthropic の記事にある通り、エージェントの体験を損なわないためには高速な起動が不可欠です。
uvx による「環境」の使い捨て
本実装では、セキュリティサンドボックス(VM やコンテナ)の代わりに、uv の uvx run を活用した依存関係の分離を採用しています。
uv はあくまで「Python パッケージ環境」を分離するツールであり、OS レベルのサンドボックス(ファイルシステムやネットワークの完全な遮断)を提供するものではありません。
本アーキテクチャにおいて uvx を採用したのは、Docker コンテナの起動オーバーヘッドを回避し、エージェントの応答速度(UX)を最大化するためです。そのため、前段の レイヤー 1(AST 解析)による事前の「危険コード排除」 を極めて厳格に行う設計としています。
# 各実行が独立した依存関係環境で動作
uvx uv run --python 3.12 \
--with pandas \
--with numpy \
--with opencv-python \
script.py
このアプローチにより、重量級のコンテナを都度立ち上げるよりも遥かに高速な実行が可能になります。また、実行ごとに環境は破棄されるため、前の実行による状態汚染(グローバル変数の残りや、インストールされたパッケージの競合)を防ぐことができます。
ストレージレイヤー(GCS 統合)
一時的な実行環境では、入力データの取得と生成ファイルの永続化が課題となります。Python Code Executor は Google Cloud Storage との統合により、これを自動化します。
双方向ファイル交換
-
入力: GCS から
data/ディレクトリへ自動ダウンロード - 出力: 生成ファイルを UUID ベースのパスで GCS へ自動アップロード
この仕様は Tool Description に記載されているため、エージェントは data/ ディレクトリからファイルを読み込むコードを自動的に生成します。
# 設定例
config = ExecutionConfig(
gcs_input_files=["gs://my-bucket/demo.png"],
packages=["opencv-python"]
)
# コード内では data/ から直接アクセス
code = """
import cv2
img = cv2.imread("data/demo.png")
cv2.imwrite("data/result.png", cv2.cvtColor(img, cv2.COLOR_BGR2GRAY))
"""
# 実行後、result.png が自動的に GCS にアップロード
result = executor.execute(code, **config.model_dump())
print(result.code_artifacts[0].gcs_url)
# https://storage.cloud.google.com/my-results-bucket/uuid-xxxx/data/result.png
これにより、AI エージェントは既存データの活用と成果物の永続化をシームレスに行えます。
実運用アーキテクチャ:コード生成時代の設計指針
ここまで Python Code Executor の実装を見てきました。しかし、これを実運用に組み込むには、もう一段階の設計判断が必要です。
パラダイムの転換を理解する
従来の「Tool Use」は、開発者が実装した関数を AI が呼び出す「決定的(Deterministic)」な処理でした。同じ入力に対して、常に同じツールが同じ方法で呼び出されます。
対して、本記事で紹介したコード実行は、ロジックそのものを AI が生成する「非決定的(Non-deterministic)」な処理です。同じタスクを依頼しても、生成されるコードは毎回異なる可能性があります。変数名が違う、アルゴリズムが違う、使うライブラリが違う——これは LLM の本質的な性質であり、避けられません。
これは、「ツールの実装コスト」がゼロになる代わりに、「AI が書いたコードの統制コスト」が新たに発生することを意味します。
設計指針 1:責務の局所化
Anthropic のデモは単一エージェントで多様なタスクをこなす汎用型ですが、実運用ではマルチエージェントシステムが有効です。
- 最小権限の原則: 一つのエージェントには最小限の役割とツールのみを付与
- リスクの分散: 複雑なタスクは複数のエージェントで協調して遂行させることで、コンテキストの汚染を防ぎ、万が一の暴走時の影響範囲を限定
設計指針 2:ツールの階層化
すべての処理を Code Executor に任せるのは得策ではありません。「定型」と「非定型」でツールを使い分ける階層化戦略が重要です。
| 処理タイプ | 実装方式 | 例 |
|---|---|---|
| 定型・頻出 | 専用ツール | Google Drive からのファイル取得、Slack 通知 |
| 非定型・探索的 | Code Executor | EDA、柔軟なデータ加工 |
専用ツールは再現性と信頼性を、Code Executor は柔軟性を担保します。どちらか一方ではなく、両者を組み合わせることで、堅牢かつ柔軟なシステムが実現できます。
おわりに
本記事では、AI エージェントのコード実行を安全にするための実装として、Python Code Executor MCP サーバーを紹介しました。
ツールをすべて手作りする時代から、AI が生成したロジックをいかに安全に走らせるかという「実行環境の設計」へ。エンジニアの役割は、コードを書くこと自体から、AI がコードを書くための安全な「場」を設計することへと変化しています。
本記事が、AI エージェント開発の一助となれば幸いです。
明日のアドベントカレンダーは、@kakine_juri さんの『ライティングソフトウェアを履修したい』です。お楽しみに!!
最後になりますが、Retail AI と TRIAL ではエンジニアを募集しています。
AI エージェントや生成 AI に関する取り組みも行っておりますので、この記事を見て興味を持ったという方がいらっしゃいましたら、ぜひご連絡ください!