スラブアロケータで始めるLinuxカーネル開発
この記事はLinux Advent Calendar 2018 5日目の記事です。
Linuxカーネルの開発をやってみたいけどなかなか手が出せないという皆さん!Linuxカーネルのスラブアロケータを開発してみませんか?スラブアロケータはLinuxの他のコンポーネントと比べ、比較的用意に開発を行うことができると私は思います。
今回の記事では、スラブアロケータが実装すべきインターフェースとその開発の流れについて、また開発の情報、そして拙作のSLOBAについて書きたいと思います。
スラブアロケータ開発の魅力
- Linuxカーネルの強力な抽象化で特定の関数を実装すれば簡単にカーネルに組み込める。
- メモリ管理はカーネルの至るところで使用される。そのため・・・
- バグがあれば起動時すぐにコケるのでバグ見つけるのが簡単。
- デバッグ中にLinuxの様々なソースを読み漁ることになるので勉強になる。
- パフォーマンスに大きな影響を与える。
- カーネルに詳しくなくてもやりたいことがなんとなくわかる。
- シンプルなソースコードを書けば、500行程度で作ることができる。(もしくはもっと)
C言語少しできるという人はカーネルモジュールから始めてもいいかもしれません!
スラブアロケータとは?
詳しくはここを見てください。
これでは味気ないので一応簡単に説明します。
ユーザランドのmallocやfreeのような関数がカーネル内に存在していて、それを提供するのがスラブアロケータです。カーネル空間でのmalloc, freeはそれぞれkmalloc, kfreeと呼ばれています。
Linuxはメモリ管理の手法として、Buddyシステムというものを用いていますが、Buddyシステムはメモリをページごとに扱うので、x86_64アーキテクチャでは基本的に4KBごとに管理しています。なので、Buddyシステムに直接16byteの構造体を確保したいと言っても4KBのメモリをぶん投げてくるわけです。

これでは圧倒的なメモリの浪費ですね。そこで登場するのがスラブアロケータです。スラブアロケータはBuddyシステムとkmalloc呼び出し側の間に位置し、そのメモリを管理します。具体的には、Buddyシステムからページを確保し、それを切り分けて、kmallocの返り値として返すわけです。
最小限、スラブアロケータが提供しなければならないAPIは以下のようになっています。
- 準備系
- kmem_cache_init ☆
- kmem_cache_init_late ☆
- __kmem_cache_create ☆
- 確保系
- __kmalloc ☆
- __kmalloc_node_track_caller
- kmem_cache_alloc ☆
- kmem_cache_alloc_bulk
- 解放系
- kfree ☆
- kmem_cache_free ☆
- kmem_cache_free_bulk
- kmem_rcu_free ☆
- __kmem_cache_release
- __kmem_cache_shrink
- __kmem_cache_shutdown
- その他
- ksize ☆
一見多いように見えますが、☆マークがついているものが最も重要で、他の関数は2,3行程度で終わったり、他の関数を呼び出すだけだったりするので、全然問題ないですね。
では、以下に☆マークの関数それぞれの簡単な説明を書きます。
| 重要な関数 | 説明 |
|---|---|
| kmem_cache_init | スラブアロケータを初期化する |
| kmem_cache_init_late | スラブアロケータを初期化する2 |
| __kmem_cache_create | kmem_cache構造体を初期化する |
| __kmalloc | 任意サイズのメモリを確保する |
| kmem_cache_alloc | スラブキャッシュを確保する |
| kfree | kmallocで確保したメモリを解放する |
| kmem_cache_free | スラブキャッシュを解放する |
| kmem_rcu_free | RCUの指定がされたスラブキャッシュを解放する |
| ksize | kmallocで返したメモリの実際のサイズを返す |
kmem_cacheとkmallocでどう違うんだ!と思う方もいると思います。この違いはkmallocはより汎用的でどんなオブジェクトにも対応できるのに対し、kmem_cacheは同じサイズの(普通は同じデータ型)のメモリを管理することでメモリ効率をあげようとするものです。そのため、kmem_cache_createなどの関数が必要になるわけです。
- kmem_cache: 特定のデータ型を扱う
- kmalloc: 汎用的なデータ型を扱う
スラブアロケータについてやそれぞれの関数の役割についてはより質の高い情報があると思うので、ここらへんにしておきます。
参考になるページについては、このぺージ下部で紹介しています。
スラブアロケータの開発
既存のLinuxにおけるスラブアロケータの実装は3種類あります。
| 実装 | 説明 |
|---|---|
| SLAB | オリジナルの実装。普通に速いスラブアロケータ。 |
| SLUB | 爆速スラブアロケータ。 |
| SLOB | K&R mallocアルゴリズムを用いた組み込み向けコンパクトスラブアロケータ |
基本的に、SLABやSLUBがメインで使われていますが、SLOBも組み込みなどで使われるそうです。
いきなり、スラブアロケータの開発を始めるのは難しいかもしれないので、SLOBの実装を見ながら開発を進めていくといいと思います。
開発の流れ
- アルゴリズムの検討やどのようなスラブアロケータにするのか考える
- 実装可能かどうかの検討
- 実装してみる
- 完成(デバッグ)
こんな感じです。特に1,2番は重要で、ここがはっきりしていないと、仕様変更の嵐でわけがわからなくなります。
まあ、1, 2を行うのは実際に開発を行う人その人だと思うので、ここからは実装工程の情報とTipsを書きたいと思います。
ビルドしていく
ソースコードがある程度書けてきたら、実際にコンパイルしてみます。
カーネルの準備
これがなければ始まりませんね!
$ git clone https://github.com/torvalds/linux.git
特定のバージョンにcheckout
開発のターゲットにしたいバージョンにcheckoutしましょう。
$ git checkout v4.19
カーネルをビルド
カーネルのビルドにはDebian系ではlibncurses-dev, bison, flex, libssl-dev, bcが必要になります。aptなどでインストールしておきましょう。(コンパイラはもちろん必要です。build-essentialをインストールするのが手っ取り早いです。)
$ make localmodconfig
$ make menuconfig
$ # ここで、自作のスラブアロケータのソースコードをslob.cとしてlinux/mm下のコピーしてください(SLOBに設定した人向け)
$ make -j$(grep -c processor /proc/cpuinfo)
make menuconfigでは、自分のスラブアロケータをビルドするため、SLOBスラブアロケータをターゲットとして選択します。
SLABやSLUBが提供するような高度な機能が実装できた場合はこれでは駄目ですが、今のところ大丈夫でしょう。また、Kconfigを修正して、いい感じにしてもGoodです!一応こんな感じになると思います。
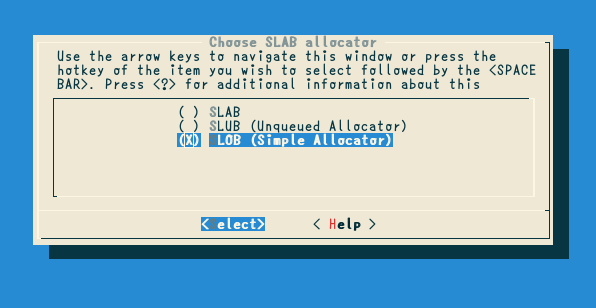
自作のスラブアロケータのソースコードをslob.cとしてlinux/mm下のコピーするのを忘れないようにしましょう。
※SLOBがサポートしていない機能を自作のスラブアロケータ実装に実装するような場合はKconfigをいじったほうがいいと思います。
make -j$(grep -c processor /proc/cpuinfo)を実行するとLinuxカーネルのビルドが始まります。環境にもよりますが、結構かかるので、まったり待ちましょう。
QEMUで走らせてみる
ここからは実際にスラブアロケータをある程度実装したあとの話です。まだ実装していない人も、目を通して流れを把握するのもいいかもしれません。
rootfs.imgの生成法はこちら記事が参考になります。
ビルドしたLinuxカーネル(をブートできる最低限の環境を用意する(with Busybox & qemu)
$ qemu-system-x86_64 -kernel ./linux/arch/x86_64/boot/bzImage -initrd ./rootfs.img -append "root=/dev/ram console=ttyS0,115200n8 panic=3 rdinit=/bin/sh" -no-reboot -boot c -nographic
うまくスラブアロケータが開発できていると、簡素なシェルが起動すると思います。これで第一難関突破です。
こんな感じです。

もし、これで動かなければエクストラデバッグタイムへ突入です。gdbをqemuに接続し、デバッグを行います。
以下のコマンドを実行すると、qemuはgdbの接続待ち状態になります。
$ qemu-system-x86_64 -kernel ./linux/arch/x86_64/boot/bzImage -initrd ./rootfs.img -append "root=/dev/ram console=ttyS0,115200n8 panic=3 rdinit=/bin/sh" -no-reboot -boot c -nographic -gdb tcp::10000 -S
そこで、gdbを接続してあげます。Tipsとして、gdbのシェルで何回かコマンドを入力する必要があり、これが面倒なので、次のようなファイルに書き込んで以下のようにgdbを起動してあげましょう。
target remote localhost:10000
source linux
symbol-file linux/vmlinux
b start_kernel
la src
$ gdb -x kgdb.src
gdbが起動したあとは、いつもどおりgdbを使うことができます。gdbの使い方はググってください。
実際にgdbが起動すると次のような画面でいつも通りソースコードを見ながらデバッグ作業を行うことができます。
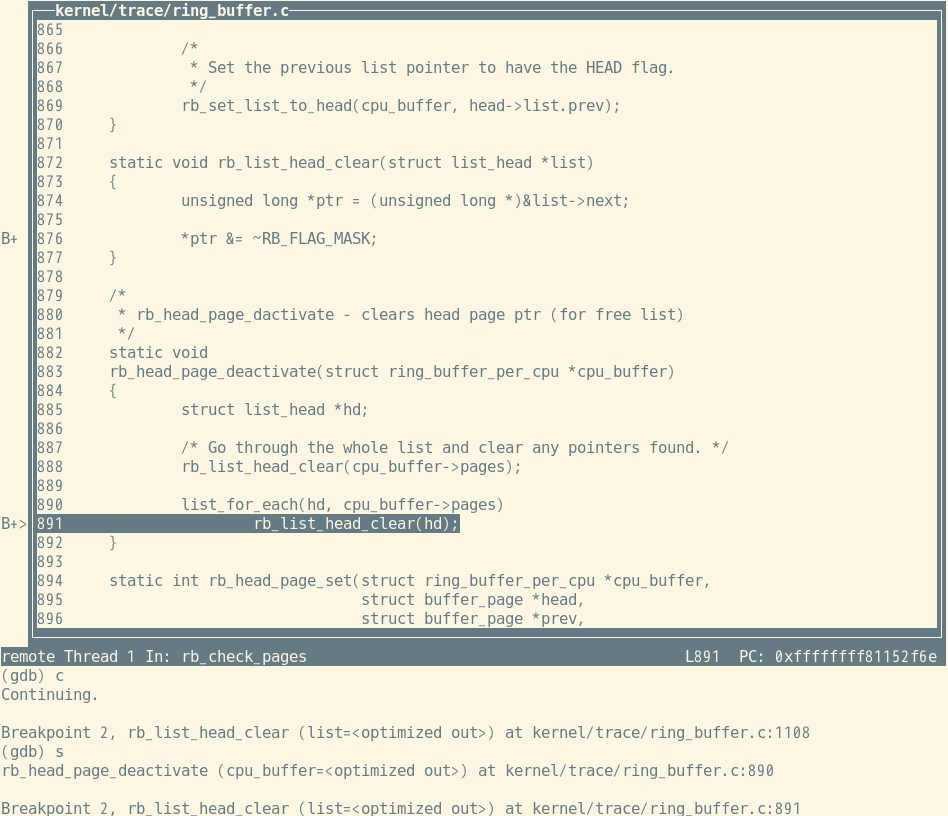
見事バグを解決されることを願っています。
仮想マシン上にインストールする
先程のQEMUは最小構成のLinuxとユーザプログラムしかありません。なので、スラブアロケータにバグがあっても、たまに問題なく動いてしまうことがあります。なので、このまま実機にインストールをすると、見事にカーネルパニックになるかもしれないので、一度仮想マシンにLinuxディストリビューションをインストールし、そこでテストをしましょう。VirtualBoxかKVMがやりやすいです。また、仮想マシンのセットアップを簡単に行うため、vagrantを用います。
vagrantによる仮想マシンのセットアップは他の方の記事のほうがよっぽど参考になるので、そちらをどうぞ。
仮想環境をすべて自分で構築・管理してもいいのですが、いろいろとめんどくさいところもあると思います。そんな方には、武内さん作のelkdatがおすすめです。お手軽にカーネル開発のための仮想環境を構築することができます。このツールは素晴らしくカーネル開発に特化していて、これからの話はあんまり関係なくなるかもしれません。
いざインストール
では、仮想マシンのセットアップは完了したことにして話を進めます。
今までは、LinuxのbzImageを生成して、QEMUに渡し、実行していましたが、今回は実際にインストールする必要があります。
$ git clone https://github.com/torvalds/linux.git
$ git checkout v4.19
$ make localmodconfig
$ make menuconfig
$ make -j$(grep -c processor /proc/cpuinfo)
これを実行した後に、以下のコマンドを実行してください。
$ sudo make modules_install
$ sudo make install
これで仮想マシンに自作カーネルがインストールされます。
しょぼいTipsですが、わざわざ2回コマンドを打つのはめんどくさいので、次のように省略できます。
$ sudo make modules_install install
これで自作カーネルを起動すればいいのですが、もし、このカーネルがバグっていた場合、他のカーネルに切り替えることができず、詰むので、次のページを参考にgrubの設定を変更してください。
その後、次のコマンドを実行し、設定を反映します。
$ sudo update-grub
仮想マシンを再起動すると、カーネルの選択画面が出ると思うので、自作カーネルを起動します。これでバグらなければ、自作スラブアロケータはほぼ完成です。さらに磨きをかけてもいいですし、実機で起動してみてもいいかもしれません。ここでコケたらいろいろと面倒ですが、このデバッグにはLinux Advent Calendar 2018 1日目 masami256さんの記事、Linuxカーネルをgdbでデバッグ(またはディストリビューションのカーネルを使うときは当たってるパッチにも注意しよう)が大変役に立つと思います。または、自分のソースコードを凝視してバグを発見しましょう。
バグ発見Tips
いままで私が遭遇したバグたちの潰し方です。
- alloc_pagesなど、ロックしてはいけない処理でロックしていないか?
- コンパイラからの警告が出ていないか?(出ていたら積極的に修正すること)
- page構造体のフラグのリセットやセットをしっかり行っているか?
- 想定している条件分岐で例外は有りないことを確認する。
- 処理実行中にデータが変更されたくない場合はしっかりとロックすること。特にページの情報。
- ポインタのポインタなどを扱うとき、その書き込み先や読み込み先は正しいのか確認すること。
- container_ofの使い方がちゃんとしているか確認すること。
- 要求されたアドレスアラインを満たしているか?
役に立つウェブぺージ
https://www.kernel.org/doc/gorman/html/understand/understand011.html
英語ですが、Linuxのスラブアロケータを理解するのに持ってこいです。
https://kernhack.hatenablog.com/entry/2017/12/01/004544
去年のLinux Advent Calendarの記事で、masami256さんがお書きになったものです。Kconfigの設定の項目も含まれており、非常にわかりやすいのでおすすめです。
http://www.coins.tsukuba.ac.jp/~yas/coins/os2-2010/2011-01-11/
筑波大学の授業用の資料っぽいですが、Buddyシステムからちゃんと書いてあるのでわかりやすいです。
拙作 SLOBAの話
ここまで、いろいろ書いて来ましたが、これらの工程は実際に私がSLOBAを開発する過程で出来上がった変な道のりなので、別に真似しなくてもいいです。むしろ真似しない方がいいですね。では、SLOBAについてちょっと話したいと思います。
SLOBAの初版は私が2018年8月に開発したもので、アルゴリズムは一応独自で開発しました。というより、当時はSLABの実装を全く読んでいなかったので、SLABのハイレベルな技巧は思いつくわけもなく独自にならざる得ない状況だったわけですが。この開発は様々な人にアドバイスを手伝ってもらい完成させることができました。そして、SLABに微妙に劣る程度のパフォーマンスを発揮しましたが、結構ボロい作りだったので、もっとまともに実装したいと思っていました。ようやく先月から大改造を始め、孤独なデバッグ作業の結果一昨日仮想環境上のUbuntuで動作しました(笑)
一応このバージョンをSLOBA-v2とし、初版をSLOBA-v1とします。
SLOBAのGitHubリポジトリはここです。
SLOBA-v2はv2ブランチのソースコードです。まだ実機でのテストを行っていないので、masterにマージしていません。masterはSLOBA-v1のソースコードです。
では、SLOBA-v2のパフォーマンスを見ていきます。
SLOBA-v2のパフォーマンス
dentryバトル
duコマンドをlinuxのソースツリーに対して行った結果です。
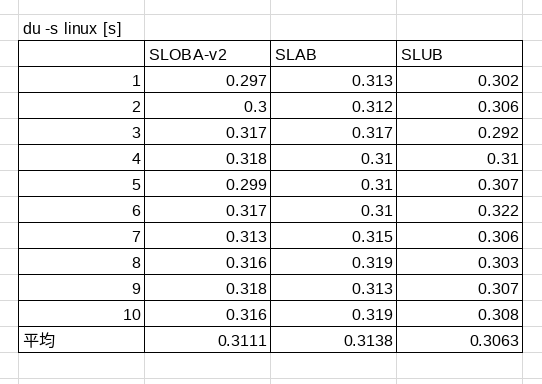
ファイル情報の取得の際には、カーネルでdentryのスラブオブジェクトが大量に確保されます。他にもいろいろなデータ構造がスラブキャッシュとして確保されるため、一応ベンチマークテストになります。
平均をグラフ化したものです。
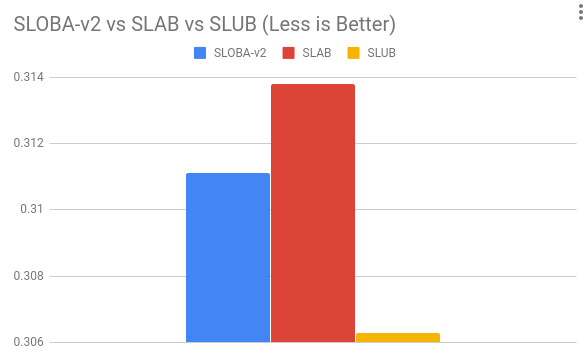
大体のランクとしては SLAB < SLOBA << SLUB といった感じでしょうか。
次に起動速度対決です。
起動速度バトル
起動速度に関しては、ディスクIOが強く絡んでくるので、性能の判定が難しいのですが、一応スラブアロケータと起動時間に相関ができています。
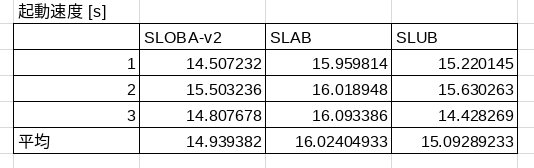
グラフです。
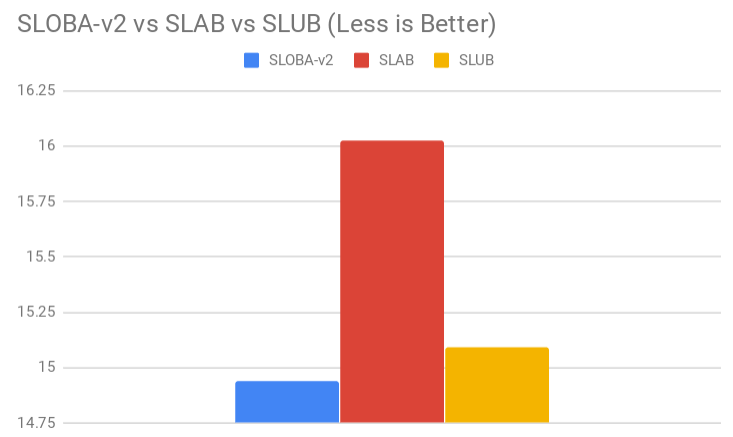
おお!?一応SLOBA-v2が最速ですね。SLABよりかは確実に高速なことがわかります!
起動速度に関して簡単な考察
SLOBAには/proc/slobinfoのprocfsファイルを作る機能が備わっていません。なので、起動時にはその工程をスキップできるため、SLUBよりも高速になったと考えられます。SLABに関しては、/proc/slabinfoを作るのに1秒もかからないと思うので、SLOBAはSLABと同等またはより高速なことは明白でしょう。
SLOBA-v2概説
確保処理
SLOBAは基本的にdlmallocから影響を受けています。
なのでSLOBAでは、CPUごとにグローバル変数でkmem_cache構造体を45個をbinsとして保持しています。これはkmalloc用に使います。
ちなみに、kmallocで提供するサイズはすべて8byteアラインされたサイズです。
kmem_cache構造体は拡張され、cache_array構造体を含んでいます。cache_array構造体はメモリページを一つ保持しています。これをスラブオブジェクトのサイズで分割し次のように配列として扱い、kmem_cache_alloc, kmallocを実装しています。ページを使い切り、そのページに乗っかているすべてのスラブオブジェクトが開放された時点で、RCUフラグが立っている場合を除き、即座にBuddyシステムに返します。
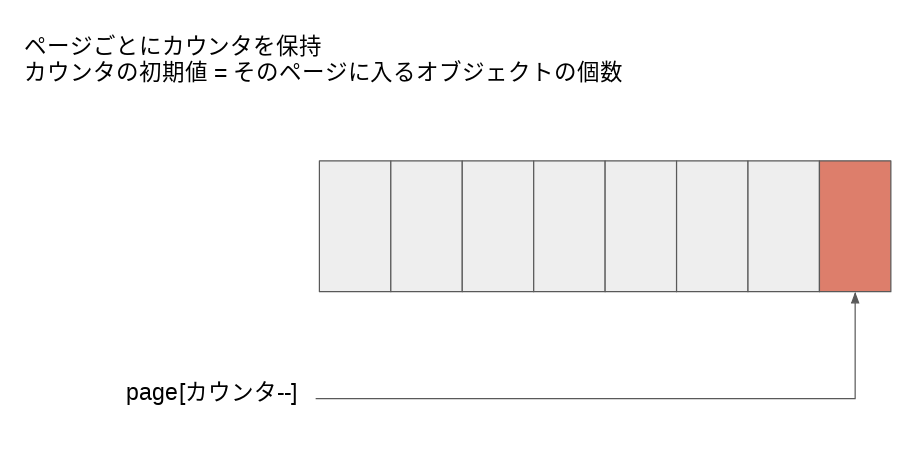
ページの後ろから確保していくため、kmallocのkmem_cacheのサイズが全て8byteアラインされていることも相まって確保できるアドレスは必ず8byteアラインされることになります。これによって、SLOBA-v1で使っていた複雑かつメモリ効率悪化につながるメタデータ保存処理を除去できるわけです。
解放処理
SLOBAはページの先頭にpage_cache_head構造体を保持しています。この構造体のフィールドにvoid *型のfreelistというものがあります。ここにSLOBAの真髄があります。SLOBAはスラブオブジェクト解放時に解放されたオブジェクトの先頭アドレスを次のようにしてスタックリスト構造として保持します。解放後のメモリ空間はスラブアロケータ側が自由に使ってもいいだろうという考えが基になっています。
freelistはNULLで初期化されているとします。
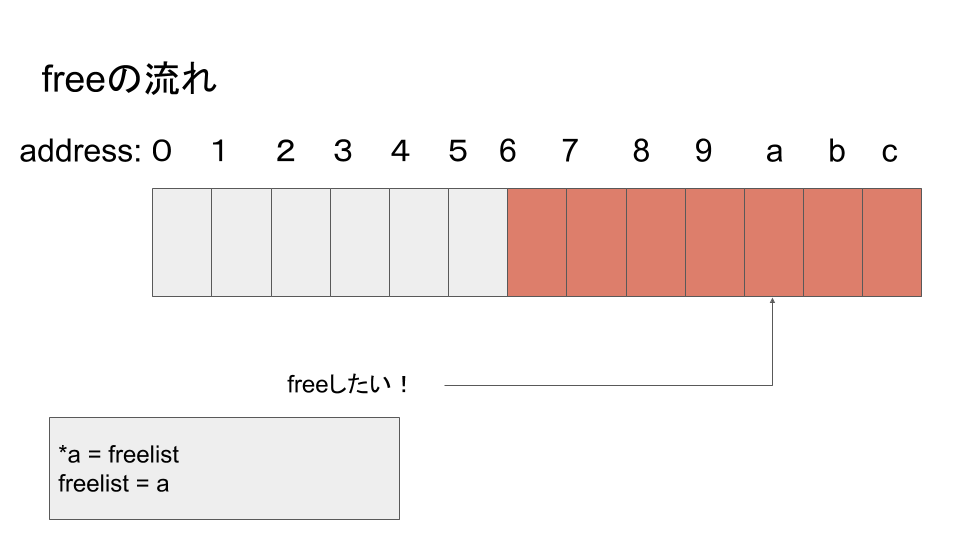
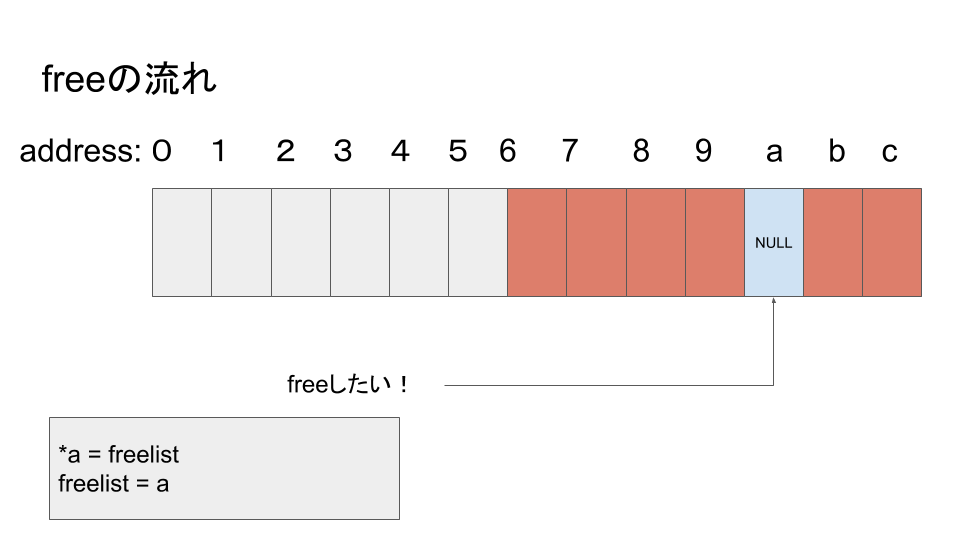
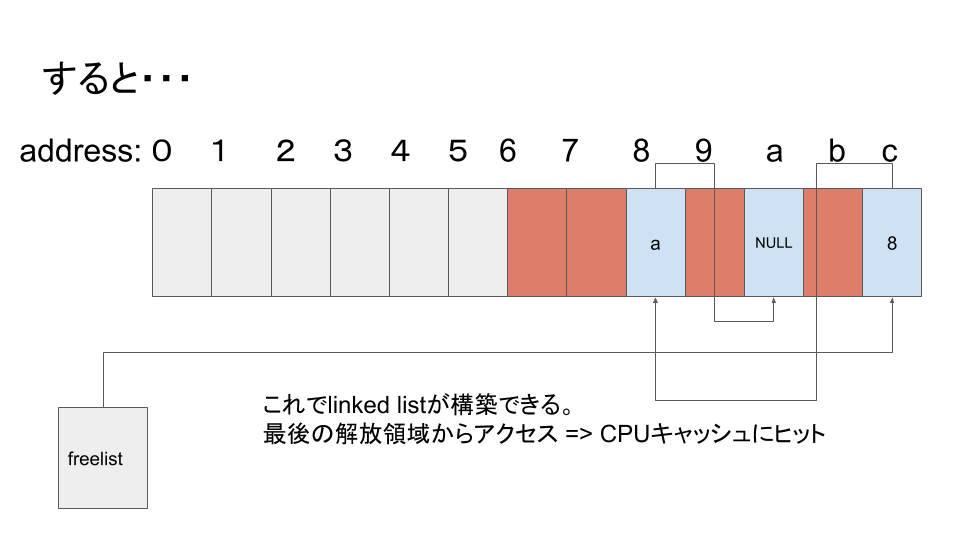
まあこんな具合です。そして、freelistに積まれた空きメモリ空間は確保処理時に使い回されます。RCUの場合は、参照が切れるまで上書きできないので、この機構は動作しません。
x86_64アーキテクチャではページサイズは4096byteで、page_cache_head構造体が16byteなので、4080byte分のメモリのやり取りでカーネルのスラブオブジェクトのやり取りが定常状態に入った場合、Buddyシステムに頼る必要がないので、非常に効率よく動作します。まあ、4080byte分だけのやりとりで定常状態に入ることは多くはないと思いますが、今後、ページサイズが拡大されていけば行くほど、SLOBAは効率よく動作するわけです。
freelistからの確保処理
page_cache_head構造体のfreelistフィールドがNULLでない場合、それは空きオブジェクトが積まれたということなので、即座に返すアドレスが決定します。freelistはLinked Listでスタックを表現したようになっているので、返り値決定後、freelistは更新され、次の空きオブジェクトのアドレスまたはNULLが入ります。
RCUに関する処理
SLOBA-v1ではSLOB実装に似た方法でRCUなオブジェクトを処理していました。つまり、オブジェクトごとにRCUのフラグが立っていて、解放の際は個別にcall_rcu関数を呼び出すような構造でした。ですが、SLOBA-v2では、SLABに近い方法である、ページごとのRCU解放を行うようにしています。
大きなオブジェクトに対する処理
ページサイズの半分のサイズ以上の大きさのオブジェクトの確保には、ページを直接Buddyシステムから取得し、返しています。この実装はかなりシンプルなソースコードになりますが、メモリ効率は悪化します。なぜなら、2100byteの要求があった場合は、4096byte返すわけで、さらにBuddyシステムは2のn乗ごとにしかページを切り出せないので、オブジェクトのサイズが大きくなればなるほど、メモリ効率は悪化します。まあ、そこまで大きなオブジェクトの要求が何度も来るような場合は珍しいので、そこまで性能やメモリ効率に影響しません。
まとめ
私の変なLinuxカーネル開発法をまとめてみました。スラブアロケータは非常にシンプルに書ける割にシステムのメモリ管理の要の重要な機構です。この手法を真似する必要はありませんので、あー、こういうふうに開発している人もいるんだなぁと思っていただければ幸いです。Linux開発に興味がある皆さん、スラブアロケータから開発を初めて見るのはいかがでしょうか。楽しいカーネル開発ライフが待っていますよ。
ここまで読んでいただきありがとうございました。この記事におかしいところがありましたら遠慮なく言ってやってください。