はじめに
ゴールデンウィークに外出ができなかったので、kaggleの「Predict Future Sales」に挑戦してみました。
このお題は、日ごとに集計されたデータ(2013.1〜2015.10)から来月(2015.11)の商品の売上個数を予測するものです。
今回のデータの特徴は、
・とにかくデータが量が多い
・学習データとテストデータとでshopの種類とitemの種類が異なる
・学習データは日毎で、予測するのは月の売上個数なので、形式をテストデータに合わせる必要がある
・時系列の要素があるのでラグをとった特徴量を追加する必要がある
では、やっていきます。
今回はこれを参考にやっていきました。
kaggle: Feature engineering, xgboost
ライブラリのインポート
import copy
import numpy as np
import pandas as pd
from itertools import product
import matplotlib.pyplot as plt
import seaborn as sns
from lightgbm.sklearn import LGBMRegressor
from lightgbm import plot_importance
from sklearn.preprocessing import LabelEncoder
pd.set_option('display.max_rows', 100)
データの読み込み
day_train_data = pd.read_csv('path/sales_train.csv')
month_test_data = pd.read_csv('path/test.csv')
item_categories = pd.read_csv('path/item_categories.csv')
items = pd.read_csv('path/items.csv')
shops = pd.read_csv('path/shops.csv')
データの修正
今回はday_train_dataにある'date'は使わないので、先に削除していきます。
day_train_data.drop('date', axis=1, inplace=True)
big_category_idとsub_category_idの作成
item_categoriesの'item_category_name'を確認してみると、'-'の前後でカテゴリーが分かれています。
item_categories['item_category_name'].head()
# [出力結果]
# 0 PC - Гарнитуры/Наушники
# 1 Аксессуары - PS2
# 2 Аксессуары - PS3
# 3 Аксессуары - PS4
# 4 Аксессуары - PSP
# Name: item_category_name, dtype: object
これを分解してlabel encodingしていきます。また、同じような名前がついたものもあるので、修正していきます。
item_categories['split_name'] = item_categories['item_category_name'].str.split('-')
item_categories['big_category_name'] =\
item_categories['split_name'].map(lambda x: x[0].strip())
item_categories['sub_category_name'] =\
tem_categories['split_name'].map(lambda x: x[1].strip() if len(x) > 1 else x[0].strip())
item_categories.loc[item_categories['big_category_name'] == 'Чистые носители(штучные)', 'big_category_name'] = 'Чистые носители (шпиль)'
# label encoding
item_categories['big_category_id'] = LabelEncoder().fit_transform(item_categories['big_category_name'])
item_categories['sub_category_id'] = LabelEncoder().fit_transform(item_categories['sub_category_name'])
# データの整理
item_categories = item_categories[['item_category_id', 'big_category_id', 'sub_category_id']]
city_idの作成と修正
カテゴリーと同様に、shopsの'shop_name'から都市の情報が得られるので、変数にしていきます。
ついでに、入力ミスもあるので、それも修正していきます。
shops.loc[shops['shop_name'] == 'Сергиев Посад ТЦ "7Я"', 'shop_name'] = 'СергиевПосад ТЦ "7Я"'
shops['city_name'] = shops['shop_name'].map(lambda x: x.split(' ')[0])
shops.loc[shops['city_name'] == '!Якутск', 'city_name'] = 'Якутск'
# label encoding
shops['city_id'] = LabelEncoder().fit_transform(shops['city_name'])
# データの整理
shops = shops[['shop_id', 'city_id']]
shop_idの修正
'shop_name'を見てみると、同じような名前になっています。kaggleのNotebooksを確認すると、どうやら同じっぽいので、修正していきます。これ以外にも後何個か存在します。
shops[(shops['shop_id'] == 0) | (shops['shop_id'] == 57)]
[出力結果]
| shop_id | shop_name | |
| 0 | !Якутск Орджоникидзе, 56 фран | 0 |
| 57 | Якутск Орджоникидзе, 56 | 57 |
修正するファイルは、day_train_dataとmonth_test_dataです。今回のプログラムでは、shopsの方はいじらない方がいいと思います。(後でマージとかをやるので、データ量地獄に陥ります。)
# shop_idの修正
day_train_data.loc[day_train_data['shop_id'] == 0, 'shop_id'] = 57
month_test_data.loc[month_test_data['shop_id'] == 0, 'shop_id'] = 57
day_train_data.loc[day_train_data['shop_id'] == 1, 'shop_id'] = 58
month_test_data.loc[month_test_data['shop_id'] == 1, 'shop_id'] = 58
day_train_data.loc[day_train_data['shop_id'] == 10, 'shop_id'] = 11
month_test_data.loc[month_test_data['shop_id'] == 10, 'shop_id'] = 11
item_priceとitem_cnt_dayの修正
item_priceとitem_cnt_dayで大きく値が外れているデータを削除していきます。
また、item_priceにマイナスの値があるので、同じ時期に同じ場所で売られているアイテムの中央値で修正をしていきます。
# 外れ値の削除
day_train_data.drop(day_train_data[day_train_data['item_price'] >= 100000].index, inplace=True)
day_train_data.drop(day_train_data[day_train_data['item_cnt_day'] > 1000].index, inplace=True)
# item_priceのエラー値を修正
median = day_train_data[(day_train_data['date_block_num'] == 4) & (day_train_data['shop_id'] == 32) & (day_train_data['item_id'] == 2973) & (day_train_data['item_price'] >= 0)]['item_price'].median()
day_train_data.loc[day_train_data['item_price'] < 0, 'item_price'] = median
データセットの作成
データセットの作成を行なっていきたいと思います。今回作成するデータセットは、day_train_dataとmonth_test_dataを合体させた不完全なパネルデータ??的な感じでです。また、予測するのは、month_test_dataにあるshopごとのitemなので、month_test_dataをdate_block_numの分だけコピーして縦にくっつけるような完全なパネルデータを作成するのもありだと思います。
ただ、その方法をやると、day_train_dataの一部が無駄になってしまうので、今回は前者の方でやっていきたいと思います。
# data_setの作成
data_set = []
cols = ['date_block_num', 'shop_id', 'item_id']
for date_num in range(34):
sales = day_train_data[day_train_data['date_block_num'] == date_num]
data_set.append(np.array(list(product([date_num],
sales['shop_id'].unique(),
sales['item_id'].unique()))))
data_set = pd.DataFrame(np.vstack(data_set), columns=cols)
data_set.sort_values(cols, inplace=True)
data_set = data_set.reset_index(drop=True)
# month_test_dataのmerge
month_test_data['date_block_num'] = 34
month_test_data['date_block_num'] = month_test_data['date_block_num']
month_test_data['shop_id'] = month_test_data['shop_id']
month_test_data['item_id'] = month_test_data['item_id']
data_set = pd.concat([data_set, month_test_data], ignore_index=True, sort=False, keys=cols)
# data_set = data_set + shops [city_id]
data_set = pd.merge(data_set, shops, on=['shop_id'], how='left')
# data_set = data_set + items [item_category_id]
data_set = pd.merge(data_set, items[['item_id', 'item_category_id']], on=['item_id'], how='left')
# data_set = data_set + item_categories [big_category_id, sub_category_id]
data_set = pd.merge(data_set, item_categories, on=['item_category_id'], how='left')
item_cnt_monthの作成
day_train_dataから月の売上個数を作成していきたいと思います。
この変数が目的変数となります。kaggleを見てみると、この変数をクリップした方が予測精度が上がるらしいです。
# item_sales_dayの作成
day_train_data['item_sales_day'] = day_train_data['item_price'] * day_train_data['item_cnt_day']
# item_cnt_monthの作成とmerge
merge_data = day_train_data.groupby(['date_block_num', 'shop_id', 'item_id'], as_index=False)['item_cnt_day'].agg('sum').rename(columns={'item_cnt_day': 'item_cnt_month'})
data_set = pd.merge(data_set, merge_data, on=cols, how='left')
data_set['item_cnt_month'] = data_set['item_cnt_month'].fillna(0).clip(0, 20)
月ごとのitem_cnt_monthをグラフに出してみます。
plot_data = day_train_data.groupby(['date_block_num'], as_index=False)['item_cnt_day'].agg('sum').rename(columns={'item_cnt_day': 'item_cnt_month'})
plt.figure(figsize=(20, 10))
sns.lineplot(data=plot_data, x='date_block_num', y='item_cnt_month')
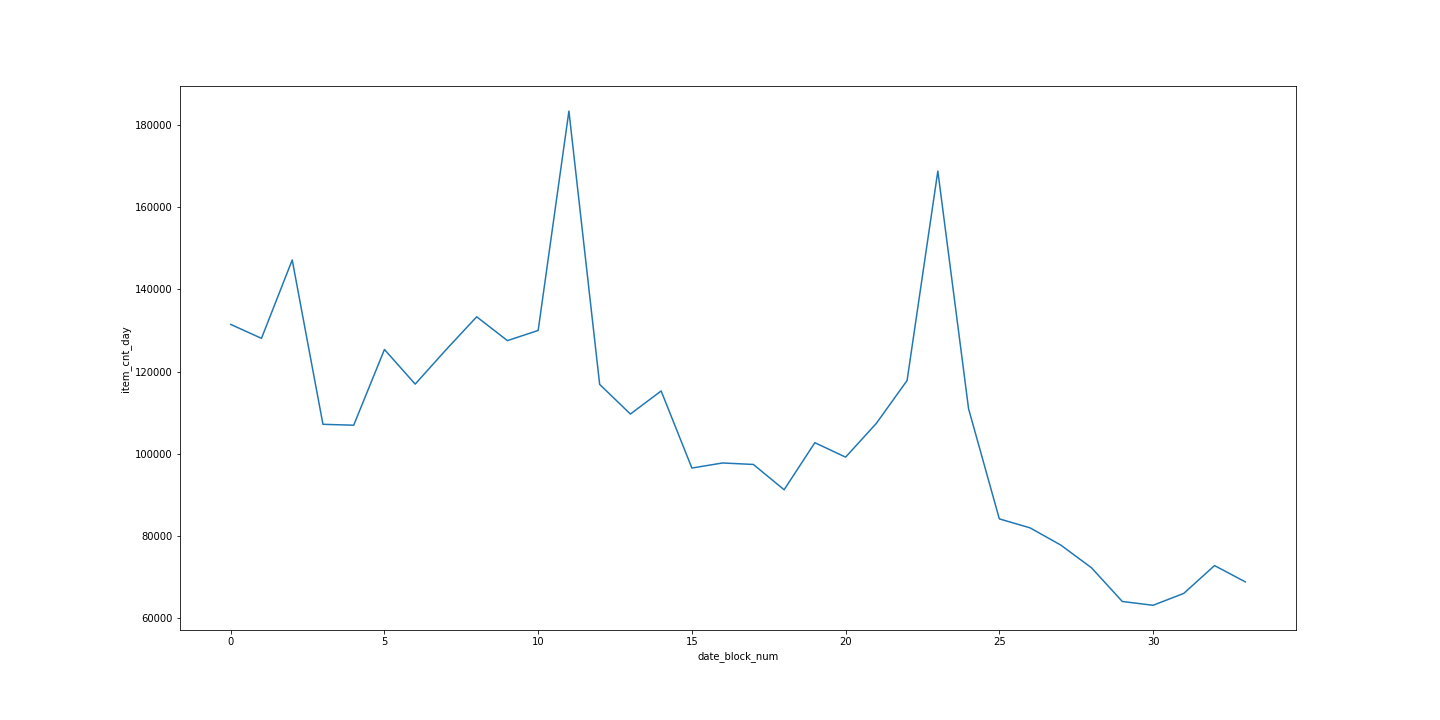
年々、減少傾向にあり、毎年12月に同じような感じで売上個数が上がっていて、周期性が確認できます。
こういうところを変数として入れてあげると精度が上がりそうです。
変動分解でもっと細かくみていきたいと思います。
import statsmodels.api as sm
res = sm.tsa.seasonal_decompose(plot_data['item_cnt_month'], freq=12)
plt.subplots_adjust(hspace=0.3)
plt.figure(figsize=(15, 9))
plt.subplot(411)
plt.plot(res.observed, lw=.6, c='darkblue')
plt.title('observed')
plt.subplot(412)
plt.plot(res.trend, lw=.6, c='indianred')
plt.title('trend')
plt.subplot(413)
plt.plot(res.seasonal, lw=.6, c='indianred')
plt.title('seasonal')
plt.subplot(414)
plt.plot(res.resid, lw=.6, c='indianred')
plt.title('residual')
ここで一旦、データをキャストしていきます。
data_set.fillna(0, inplace=True)
data_set['date_block_num'] = data_set['date_block_num'].astype(np.uint8)
data_set['shop_id'] = data_set['shop_id'].astype(np.uint8)
data_set['item_id'] = data_set['item_id'].astype(np.uint16)
data_set['item_cnt_month'] = data_set['item_cnt_month'].astype(np.float16)
data_set['ID'] = data_set['ID'].astype(np.uint32)
data_set['city_id'] = data_set['city_id'].astype(np.uint8)
data_set['item_category_id'] = data_set['item_category_id'].astype(np.uint8)
data_set['big_category_id'] = data_set['big_category_id'].astype(np.uint8)
data_set['sub_category_id'] = data_set['sub_category_id'].astype(np.uint8)
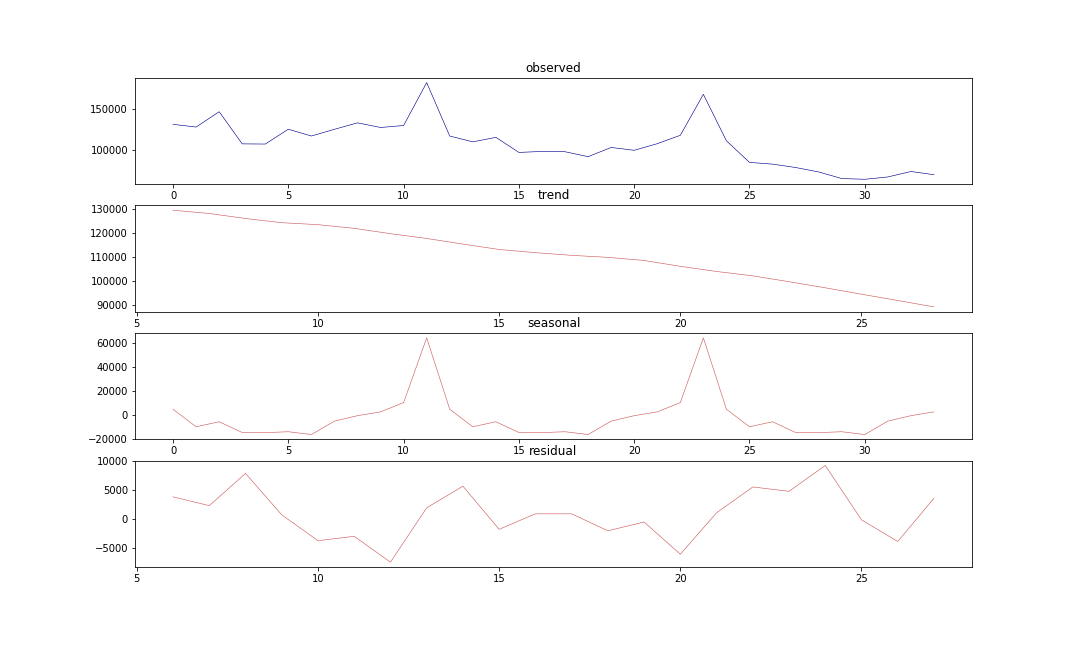
これを見ると、傾向や季節性があるのがよく分かりますね。
Feature Engineering
この関数は今回たくさん使っていきますが、一時的にメモリをたくさん使うので注意です。
def feature_lags(df, lags, lag_col):
tmp = df[['date_block_num', 'shop_id', 'item_id', lag_col]]
for lag in lags:
shifted = tmp.copy()
shifted.columns = ['date_block_num', 'shop_id', 'item_id', str(lag_col) + '_lag_' + str(lag)]
shifted['date_block_num'] += lag
shifted = shifted[shifted['date_block_num'] <= 34]
df = pd.merge(df, shifted, on=['date_block_num', 'shop_id', 'item_id'], how='left', copy=False)
return df
item_cnt_monthのfeature engineering
# target_lags
data_set = feature_lags(df=data_set, lags=[1, 2, 3, 6, 12], lag_col='item_cnt_month')
# date_avg_item_cnt
date_avg_item_cnt = data_set.groupby(['date_block_num'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_avg_item_cnt'})
data_set = pd.merge(data_set, date_avg_item_cnt, on=['date_block_num'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_avg_item_cnt')
data_set.drop(['date_avg_item_cnt'], axis=1, inplace=True)
# date_item_avg_item_cnt
date_item_avg_item_cnt = data_set.groupby(['date_block_num', 'item_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_item_avg_item_cnt'})
data_set = pd.merge(data_set, date_item_avg_item_cnt, on=['date_block_num', 'item_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_item_avg_item_cnt')
data_set.drop(['date_item_avg_item_cnt'], axis=1, inplace=True)
# date_shop_avg_item_cnt
date_shop_avg_item_cnt = data_set.groupby(['date_block_num', 'shop_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_shop_avg_item_cnt'})
data_set = pd.merge(data_set, date_shop_avg_item_cnt, on=['date_block_num', 'shop_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_shop_avg_item_cnt')
data_set.drop(['date_shop_avg_item_cnt'], axis=1, inplace=True)
# date_category_avg_item_cnt
date_category_avg_item_cnt = data_set.groupby(['date_block_num', 'item_category_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_category_avg_item_cnt'})
data_set = pd.merge(data_set, date_category_avg_item_cnt, on=['date_block_num', 'item_category_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_category_avg_item_cnt')
data_set.drop(['date_category_avg_item_cnt'], axis=1, inplace=True)
# date_shop_category_avg_item_cnt
date_shop_category_avg_item_cnt = data_set.groupby(['date_block_num', 'shop_id', 'item_category_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_shop_category_avg_item_cnt'})
data_set = pd.merge(data_set, date_shop_category_avg_item_cnt, on=['date_block_num', 'shop_id', 'item_category_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_shop_category_avg_item_cnt')
data_set.drop(['date_shop_category_avg_item_cnt'], axis=1, inplace=True)
# date_shop_bigcat_avg_item_cnt
date_shop_bigcat_avg_item_cnt = data_set.groupby(['date_block_num', 'shop_id', 'big_category_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_shop_bigcat_avg_item_cnt'})
data_set = pd.merge(data_set, date_shop_bigcat_avg_item_cnt, on=['date_block_num', 'shop_id', 'big_category_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_shop_bigcat_avg_item_cnt')
data_set.drop(['date_shop_bigcat_avg_item_cnt'], axis=1, inplace=True)
# date_shop_subcat_avg_item_cnt
date_shop_subcat_avg_item_cnt = data_set.groupby(['date_block_num', 'shop_id', 'sub_category_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_shop_subcat_avg_item_cnt'})
data_set = pd.merge(data_set, date_shop_subcat_avg_item_cnt, on=['date_block_num', 'shop_id', 'sub_category_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_shop_subcat_avg_item_cnt')
data_set.drop(['date_shop_subcat_avg_item_cnt'], axis=1, inplace=True)
# date_bigcat_avg_item_cnt
date_bigcat_avg_item_cnt = data_set.groupby(['date_block_num', 'big_category_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_bigcat_avg_item_cnt'})
data_set = pd.merge(data_set, date_bigcat_avg_item_cnt, on=['date_block_num', 'big_category_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_bigcat_avg_item_cnt')
data_set.drop(['date_bigcat_avg_item_cnt'], axis=1, inplace=True)
# date_subcat_avg_item_cnt
date_subcat_avg_item_cnt = data_set.groupby(['date_block_num', 'sub_category_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_subcat_avg_item_cnt'})
data_set = pd.merge(data_set, date_subcat_avg_item_cnt, on=['date_block_num', 'sub_category_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_subcat_avg_item_cnt')
data_set.drop(['date_subcat_avg_item_cnt'], axis=1, inplace=True)
# date_city_avg_item_cnt
date_city_avg_item_cnt = data_set.groupby(['date_block_num', 'city_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_city_avg_item_cnt'})
data_set = pd.merge(data_set, date_city_avg_item_cnt, on=['date_block_num', 'city_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_city_avg_item_cnt')
data_set.drop(['date_city_avg_item_cnt'], axis=1, inplace=True)
# date_item_city_avg_item_cnt
date_item_city_avg_item_cnt = data_set.groupby(['date_block_num', 'item_id', 'city_id'], as_index=False)['item_cnt_month'].agg('mean').rename(columns={'item_cnt_month': 'date_item_city_avg_item_cnt'})
data_set = pd.merge(data_set, date_item_city_avg_item_cnt, on=['date_block_num', 'item_id', 'city_id'], how='left')
data_set = feature_lags(df=data_set, lags=[1], lag_col='date_item_city_avg_item_cnt')
data_set.drop(['date_item_city_avg_item_cnt'], axis=1, inplace=True)
item_salesのfature engineering
# item_avg_item_price
item_avg_item_price = day_train_data.groupby(['item_id'], as_index=False)['item_price'].agg('mean').rename(columns={'item_price': 'item_avg_item_price'})
data_set = pd.merge(data_set, item_avg_item_price, on=['item_id'], how='left')
# date_item_avg_item_price
date_item_avg_item_price = day_train_data.groupby(['date_block_num', 'item_id'], as_index=False)['item_price'].agg('mean').rename(columns={'item_price': 'date_item_avg_item_price'})
data_set = pd.merge(data_set, date_item_avg_item_price, on=['date_block_num', 'item_id'], how='left')
lags = [1, 2, 3, 4, 5, 6]
data_set = feature_lags(df=data_set, lags=lags, lag_col='date_item_avg_item_price')
for lag in lags:
data_set['delta_price_lag_' + str(lag)] = (data_set['date_item_avg_item_price_lag_' + str(lag)] - data_set['item_avg_item_price'] / data_set['item_avg_item_price'])
def select_trend(row):
for lag in lags:
if row['delta_price_lag_' + str(lag)]:
return row['delta_price_lag_' + str(lag)]
return 0
data_set['delta_price_lag'] = data_set.apply(select_trend, axis=1)
data_set['delta_price_lag'].fillna(0, inplace=True)
# 使わないデータの削除
features_to_drop = ['item_avg_item_price', 'date_item_avg_item_price']
for lag in lags:
features_to_drop += ['date_item_avg_item_price_lag_' + str(lag)]
features_to_drop += ['delta_price_lag_' + str(lag)]
data_set.drop(features_to_drop, axis=1, inplace=True)
item_sales_dayのfeature engineering
date_shop_sales = day_train_data.groupby(['date_block_num', 'shop_id'], as_index=False)['item_sales_day'].agg('sum').rename(columns={'item_sales_day': 'date_shop_sales'})
data_set = pd.merge(data_set, date_shop_sales, on=['date_block_num', 'shop_id'], how='left')
shop_avg_sales = day_train_data.groupby(['shop_id'], as_index=False)['item_sales_day'].agg('mean').rename(columns={'item_sales_day': 'shop_avg_sales'})
data_set = pd.merge(data_set, shop_avg_sales, on=['shop_id'], how='left')
data_set['delta_sales'] = (data_set['date_shop_sales'] - data_set['shop_avg_sales']) / data_set['shop_avg_sales']
data_set = feature_lags(df=data_set, lags=[1], lag_col='delta_sales')
data_set.drop(['date_shop_sales', 'shop_avg_sales', 'delta_sales'], axis=1, inplace=True)
月データと月の日数
data_set['month'] = data_set['date_block_num'] % 12
days = pd.Series([31,28,31,30,31,30,31,31,30,31,30,31])
data_set['day'] = data_set['month'].map(days)
data_set['day'] = data_set['day'].astype(np.uint8)
train_dataとtest_dataの作成
data_setからデータを分ける前にmergeによるNaNに0を入れておきます。
data_set.fillna(0, inplace=True)
これでdata_setの完成です。
data_setの情報を載せておきます。
これをキャストしていないと倍以上のデータ量になっていると思います。
data_set.info()
""" out
<class 'pandas.core.frame.DataFrame'>
Int64Index: 11128004 entries, 0 to 11128003
Data columns (total 29 columns):
date_block_num uint8
shop_id uint8
item_id uint16
item_cnt_month float16
ID uint32
city_id uint8
item_category_id uint8
big_category_id uint8
sub_category_id uint8
item_cnt_month_lag_1 float16
item_cnt_month_lag_2 float16
item_cnt_month_lag_3 float16
item_cnt_month_lag_6 float16
item_cnt_month_lag_12 float16
date_avg_item_cnt_lag_1 float16
date_item_avg_item_cnt_lag_1 float16
date_shop_avg_item_cnt_lag_1 float16
date_category_avg_item_cnt_lag_1 float16
date_shop_category_avg_item_cnt_lag_1 float16
date_shop_bigcat_avg_item_cnt_lag_1 float16
date_shop_subcat_avg_item_cnt_lag_1 float16
date_bigcat_avg_item_cnt_lag_1 float16
date_subcat_avg_item_cnt_lag_1 float16
date_city_avg_item_cnt_lag_1 float16
date_item_city_avg_item_cnt_lag_1 float16
delta_price_lag float64
delta_sales_lag_1 float64
month uint8
day uint8
dtypes: float16(17), float64(2), uint16(1), uint32(1), uint8(8)
memory usage: 764.1 MB
"""
次にtrain_dataとtest_dataを作成していきます。
target_col = 'item_cnt_month'
exclude_cols = ['ID', target_col]
feature_cols = []
for col in train_data.columns:
if col not in exclude_cols:
feature_cols.append(col)
x_train = train_data[train_data['date_block_num'] <= 32][feature_cols]
y_train = train_data[train_data['date_block_num'] <= 32][target_col]
x_val = train_data[train_data['date_block_num'] == 33][feature_cols]
y_val = train_data[train_data['date_block_num'] == 33][target_col]
x_test = test_data[feature_cols]
LightGBMによる学習
まずは、チューニングさせずにデフォルトでやっていきたいと思います。
ts = time.time()
gbm = LGBMRegressor(n_jobs=-1)
gbm.fit(x_train, y_train,
eval_metric='rmse',
eval_set=(x_val, y_val))
time.time() - ts
# rmse: 0.948226
# time:23.153272
チューニングなしだと0.948226でした。時間も30秒以内でランダムフォレストとかよりもだいぶ早く学習してくれました。
次に、max_depthとn_estimatorsを変えてやっていきたいと思います。
ts = time.time()
gbm = LGBMRegressor(n_estimators=10000, max_depth=10, n_jobs=-1)
gbm.fit(x_train, y_train,
early_stopping_rounds=20,
eval_metric='rmse',
eval_set=(x_val, y_val),
verbose=1)
time.time() - ts
# Early stopping, best iteration is: [105] valid_0's rmse: 0.943153
# time30.228255
n_estimatorsが105の時がベストスコアとなりました。
あんまりrmseに変化はないですね。
feature_importancesを可視化してみます。
date_item_avg_item_cnt_lag_1が一番効いてますね。
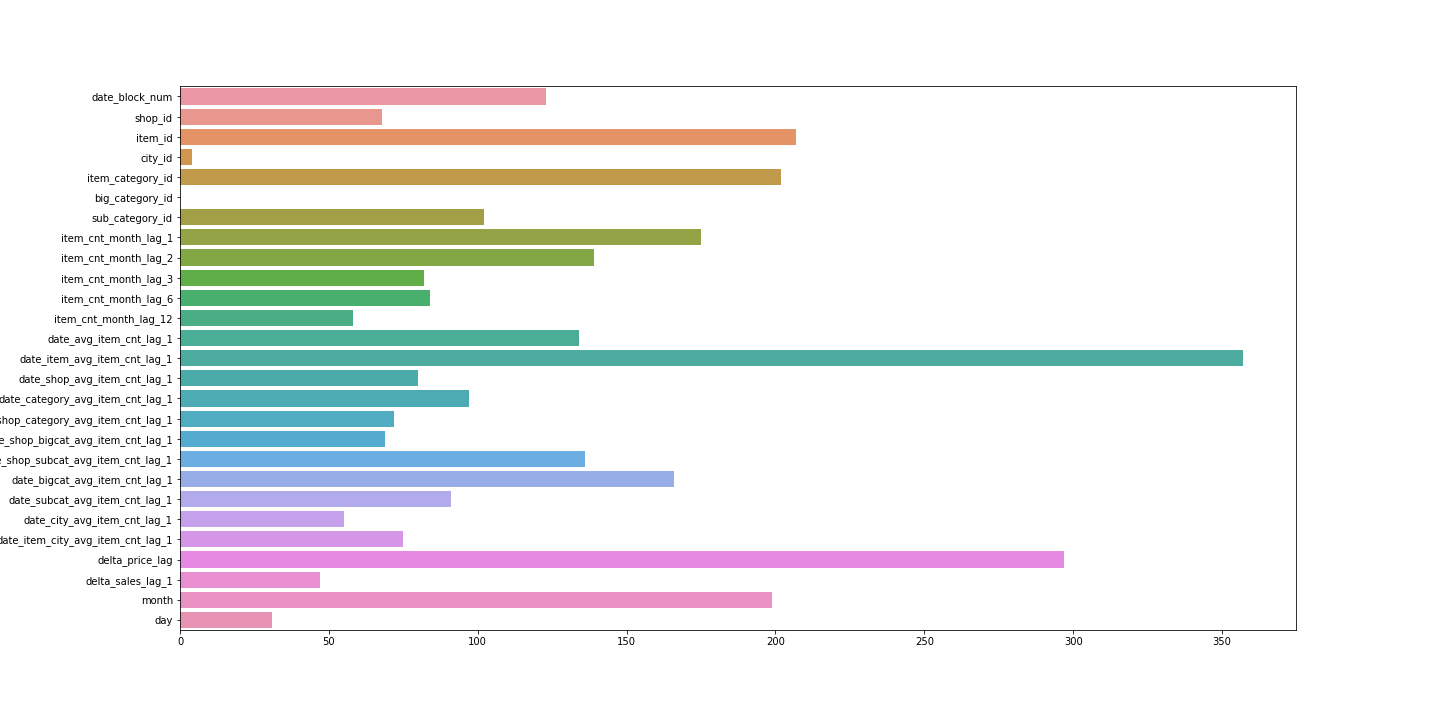
このモデルでpredictした結果をkaggleに提出しました。
結果は、0.96079でした。
終わりに
今回は、kaggleのNotebooksを参考にデータを作り予測してみました。
まだ、ハイパーパラメーターのチューニングをしっかりやっていないので、
次回は、optunaというライブラリのLightGBM lunarでチューニングをしていきたいと思います。