OpenAIがPPO(Proximal Policy Optimization)というアルゴリズムを同団体の標準アルゴリズムにするとの発表をしました。コードもリリースされているので早速試してみます。baselinesという強化学習パッケージに入っているようですね。
OSX 10.11.6, Python 3.5.1, TensorFlow 1.2.1 で試しました。
倒立振子を立ててみる(またか!)
インストール手順は後述で、まずやってみます。ここのrun_atari.pyがサンプルですね。
python run_atari.py
なにやら走り出しましたが、手元のMacBook Proごときだとatari環境では時間がかかりそうなので、何か軽いものということで例によって倒立振子にしましょう。OpenAI gymのPendulmn-v0を使います。どんだけ倒立振子振り上げが好きなんだとか言われそうですが、簡単だけど達成感あるという意味でちょうどいいんですよ。。。
それはいいのですが、学習結果を保存したり学習済のエージェントで実験したりという、ユーザ目線でいうと一番楽しいところのコードがないですね。まあ書きましょう。。。係数の取扱が面倒なのでTensorFlowのセッションをまるごと保存・リストアするという乱暴な方法でやりました。コードはこちらにあげておきました。
python run_pendulmn.py train
python run_pendulmn.py replay
でそれぞれ学習と、学習済モデルでの再生を行います。
学習の過程はmonitor.jsonに書き出されますのでrewardの推移をプロットしてみます。横軸がイテレーション回数、縦軸がrewardです。
python plot_log.py
でpngを吐き出します。
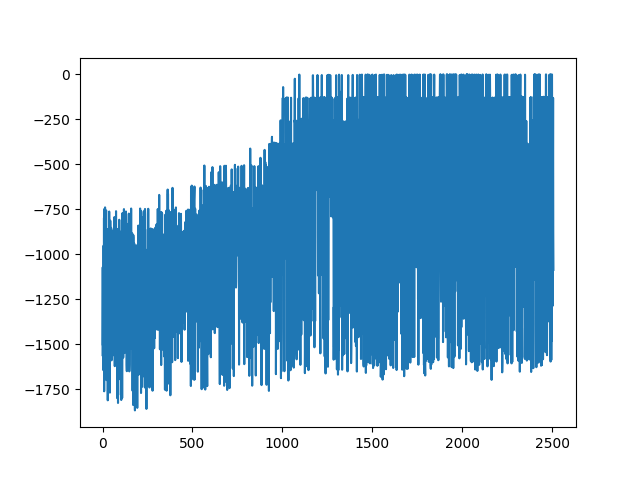
フムッティー。例によって最高記録を達成してからの挙動が安定しないですね。まあ不安定系に適用した強化学習とはそんなものと言ってしまえばそれまでですが、reward上位ランキングのエージェントは残せるようになっているといいですね。
少しでもマシにできないかハイパーパラメータでどうにかしてみましょう。learn()の引数にscheduleというのがあり、今回はschedule="linear"で線形に学習率を減衰させるようにしましたが、線形だと下がりきってからしばらく落ち着かせるという効果がでないですね。そこでカスタムの減衰率を下記のようにしました。極小になってからしばらく待つかんじです。このあたりはpposgd_simple.pyというファイル内でやっているので手を加えました。
cur_lrmult = max(1.0 - float(timesteps_so_far) / (max_timesteps/2), 0)
if cur_lrmult<1e-5:
cur_lrmult = 1e-5
さあどうでしょうか。
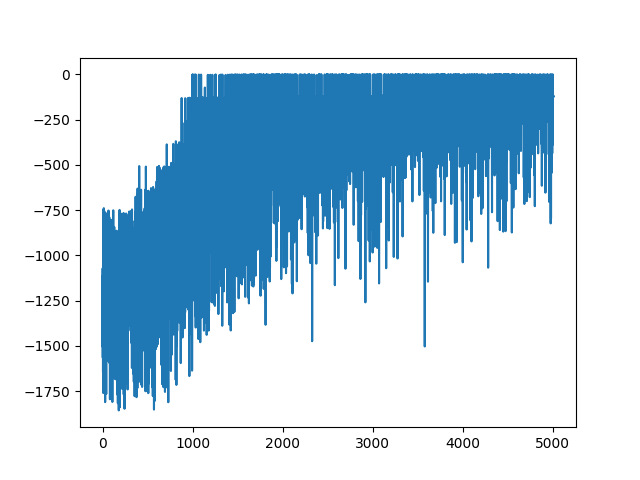
はい。少しは良くなりました。もっと長時間やらないとだめでしょうかね。あと、Pendulmn-v0は初期状態がランダムで振られるようで、その影響も出ていると思います。
では学習結果をリプレイしてみましょう。

いい感じですね。前の私のエントリとちがってこのエージェントは連続量を出力することもあり、とくに静止後がとても美しいです。
感想とか
PPOの論文を一行も読まずに実行できたのでコードリリースには感謝としかいいようがありません。ただ、標準アルゴリズムとまで持ち上げるのであればもう少しとっつきやすくしたほうがよいのではという気がします。まあこれからなんでしょうけど。
おなじOpenAIのgymは環境側のインターフェイスを統一するという意味でとてもすばらしい仕事だと思います。エージェント側も同じように統一したインターフェイスを作れないものでしょうかね。ざっとみたかんじ、baselinesのDQNとPPOですら統一されていないですし(まあ・・一般化は難しいというのはわかりますが)。
DQNとのベンチマークはやっていませんが、もっと難しい問題でやらないと差は出ないんじゃないかなあと思っています。
インストール
さて、下記は今日(2017/7/22)時点のインストール手順です。そのうちpip一発で通るようになるでしょう。。
まずTensorFlowの1.0.0以上が必要です。TensorFlowのインストールはドキュメントを見ましょう。
pip install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.2.1-py3-none-any.whl
次にbaselineの最新版をgitからインストールします。pipでも行けるようですが今日時点では不整合があるようでした。
git clone https://github.com/openai/baselines.git
baselines/baselines/pposgd/に、以下内容の__init__.pyを追加します。
from baselines.pposgd import *
インストールです。
cd baselines
python setup.py install
その他依存しているものをインストールします。
brew install openmpi
pip install mpi4py
pip install atari_py
以上で少なくともサンプルのrun_atari.pyは通りました。