VSCode Remote Containersで.NET Core + MySQL + Elasticsearchの開発環境構築 の続きです。
今回はElasticsearchをAWS上に構築し、EC2インスタンス上に配置されたWebアプリから接続するところまでをご紹介しようと思います。
環境
Elasticsearch 7.8
Elasticsearchインスタンスの作成
まずはElasticsearchインスタンスを作成していきましょう。
以下手順でElasticsearchのコンソールを開き、ドメインの作成メニューを開いてください。
- AWSマネジメントコンソールにログイン
- 「サービス」の「すべてのサービス」に
Elasticsearchを入力 - Elasticsearch Serviceへのリンクが表示されるので押下
- Elasticsearch Serviceコンソールが表示されるので、「新しいドメインの作成」を押下
以降各セクションごとに説明します。
Step 1: デプロイタイプの選択
デプロイタイプに「開発およびテスト」を選択します。
Elasticsearchのバージョンは「7.8」を選択します。
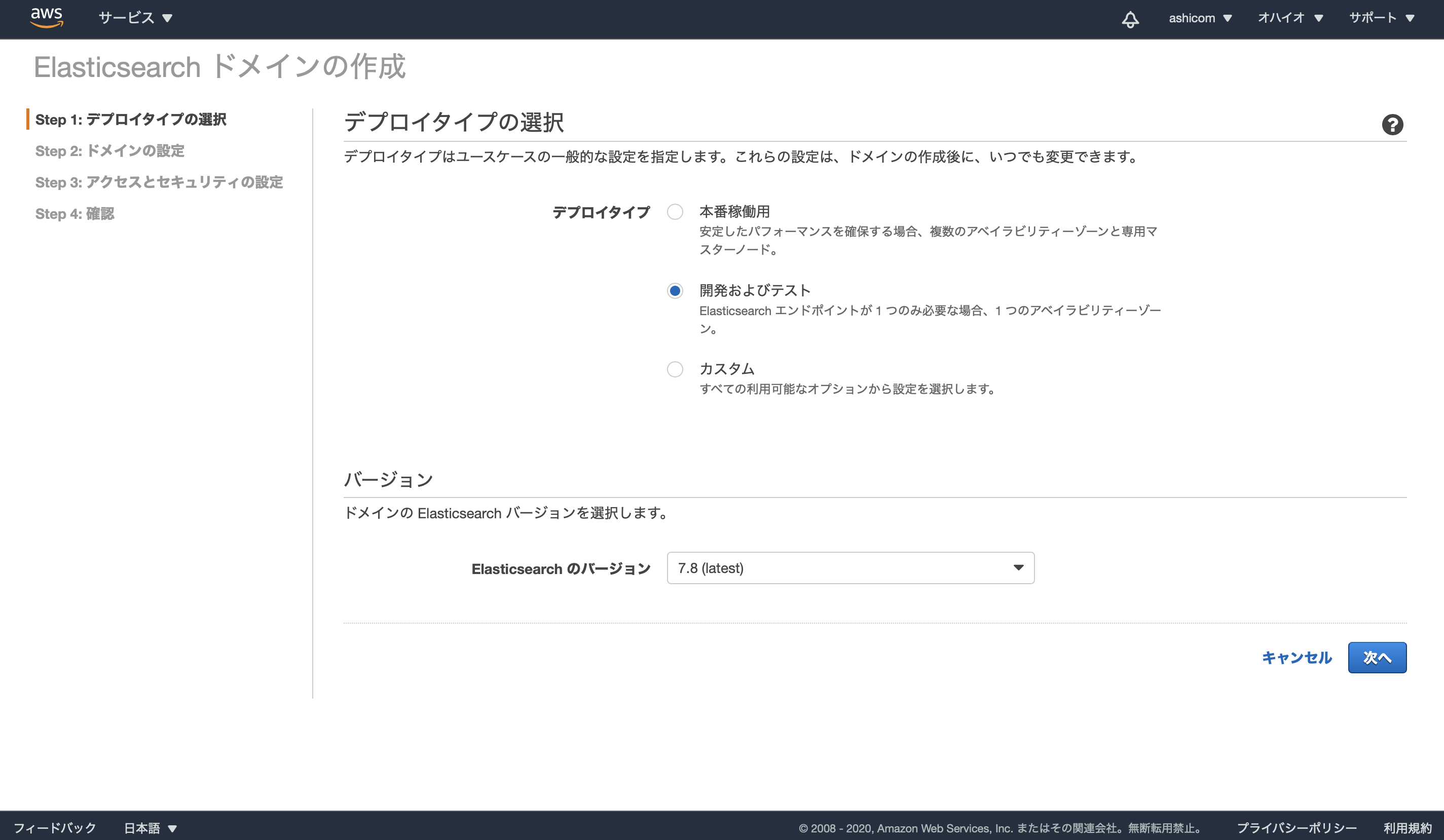
※余談ですが、最初にElasticsearchを試した時は最新バージョンが7.7で、現在(2020-11-03)は7.8になっており、その間僅か1ヶ月ほどの出来事でした。AWSのElasticsearchは最新バージョンが使えないというのが風潮としてあるように感じていましたが、その不満も徐々に解消していくのかもしれませんね。
Step 2: ドメインの設定
このセクションについて
本番運用を考慮した場合はこのインスタンスとボリュームの設定が性能と費用に直結するため、非常に重要な選択となります。
今回は学習用のため無料枠での選択となりますが、本番環境構築を考えている方は各セクションについて理解を深めた上で意思決定をしてください。詳しくはこちら。
ドメイン名を決める
まずはドメイン名を決めます。今回は「my-elasticsearch」としました。

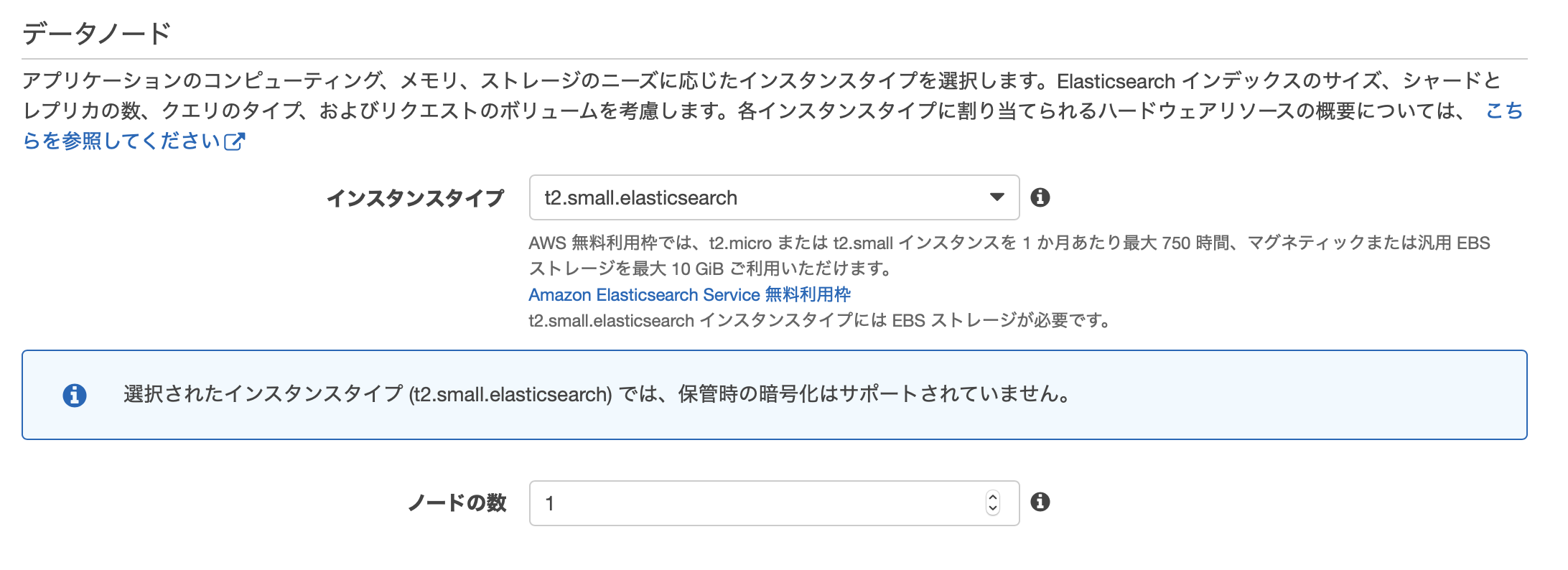
データノード
続いてはデータノードの設定です。
インスタンスタイプは無料枠である「t2.small.elasticsearch」
ノードの数は「1」に設定します。
データノードストレージ
続いて、データノードのストレージ要件を設定していきます。
今回はEBSボリュームタイプに一番安価な「マグネティック」を設定し、他はデフォルトのままにしておきます。

専用マスターノード
デフォルトで無効になっているのでそのままで進みましょう。
スナップショットの設定
Elasticsearch バージョン 5.3 以降では設定できないみたいなので先に進みましょう。
Step 3: アクセスとセキュリティの設定
続いてはネットワークや認証周りの設定をしていきます。
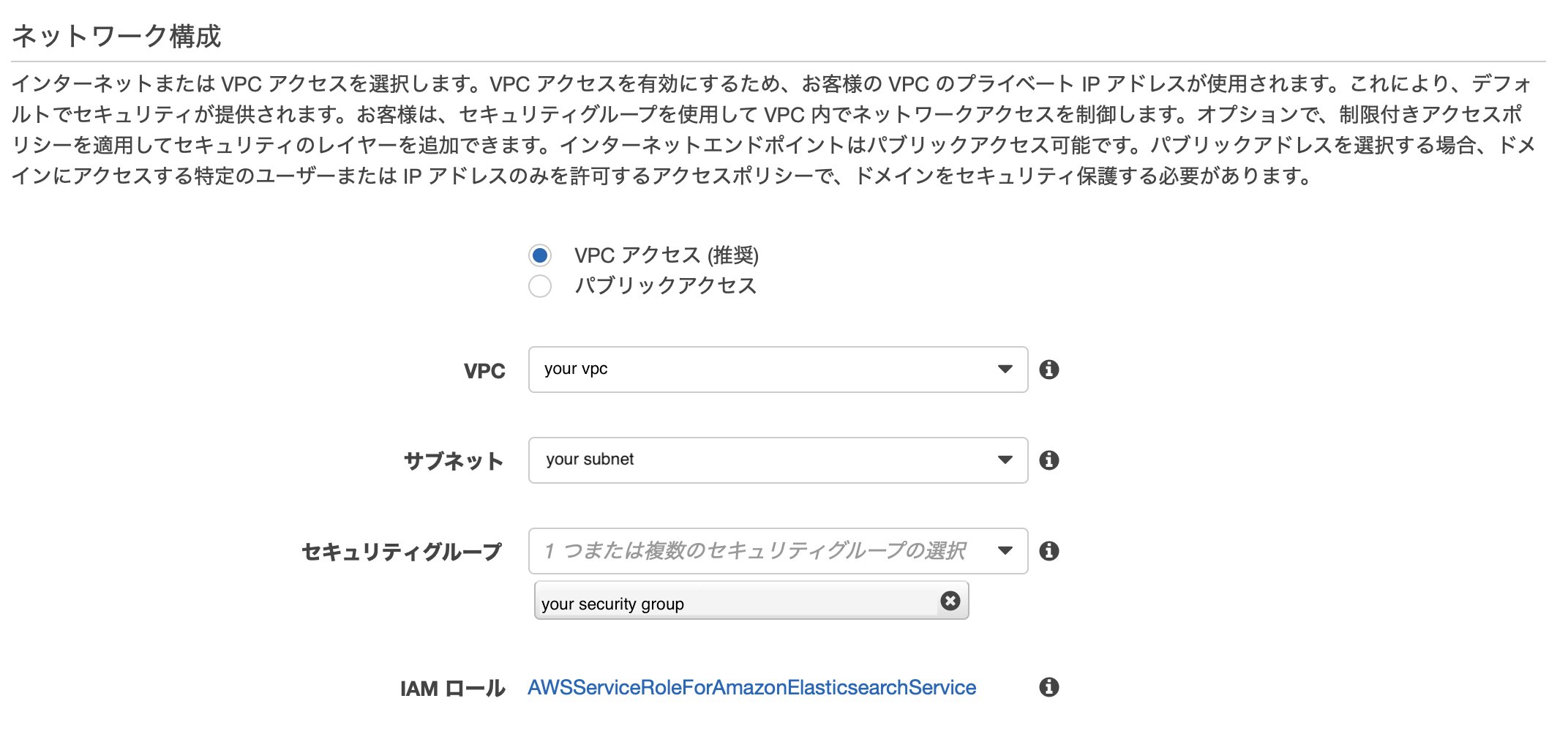
ネットワーク構成
「VPC アクセス (推奨)」を選択します。
VPCとサブネットに関しては事前に作成したものを割り当ててください。
セキュリティグループに関してはHTTPSのポートが開いているものを割り当てる必要があります。
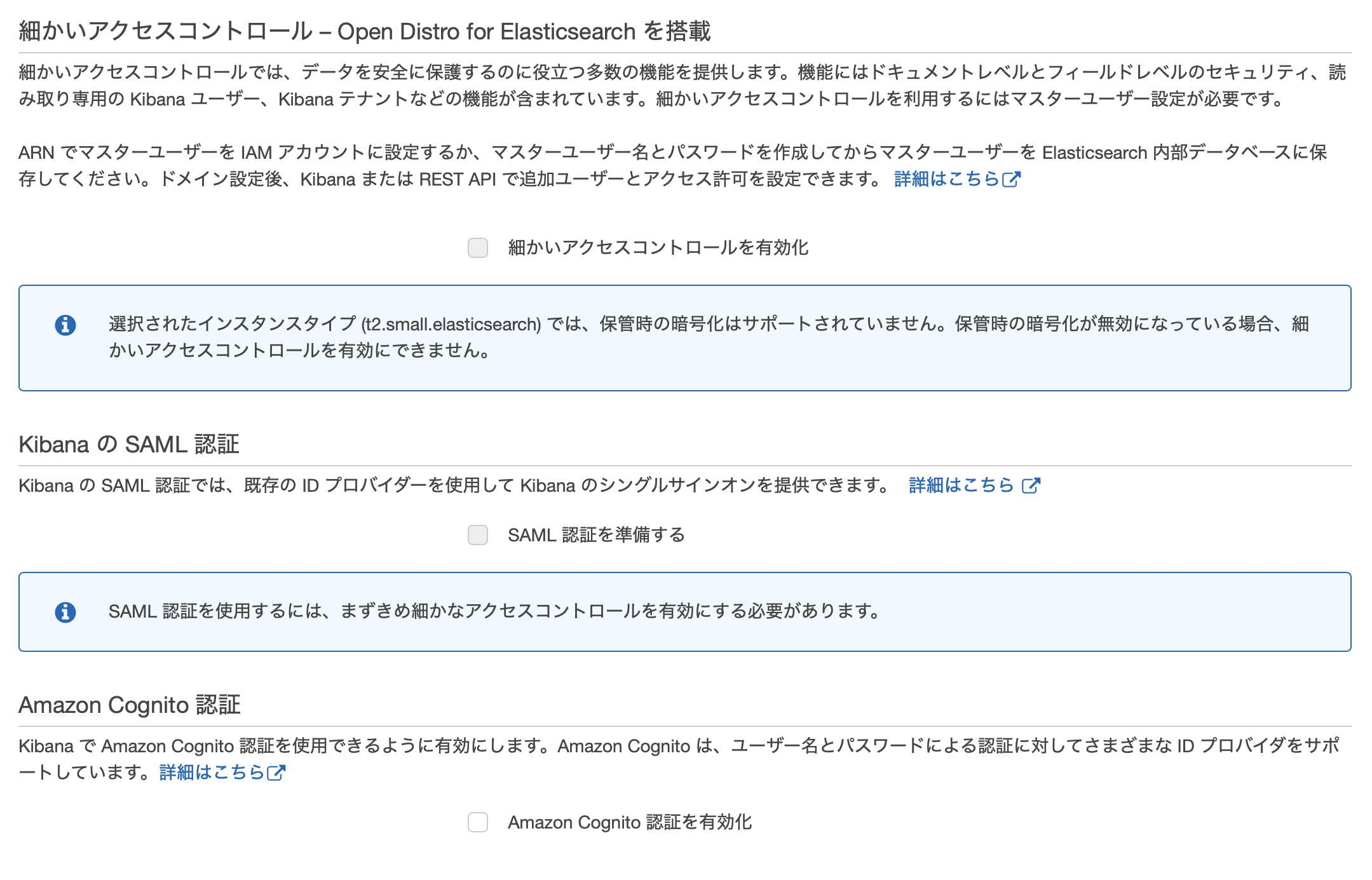
Kibana参照時の認証系
- 細かいアクセスコントロール – Open Distro for Elasticsearch を搭載
- Kibana の SAML 認証
- Amazon Cognito 認証
この3つについてですが、主にKibanaを参照する場合の認証まわりを設定する項目となります。
今回はElasticsearchを動かす目的なので割愛しますが、本番環境を構築する際はKibanaをElasticsearchのコンソールとして利用することになると思うので、項目の存在は忘れないようにしましょう。
アクセスポリシー
ユーザやロール、また特定のIPごとに、機能単位の詳細なアクセス制御を行う場合、こちらを設定していきます。
今回はVPC内であればどのアクセスも許可する構成とするので「ドメインへのオープンアクセスを許可」に設定します。

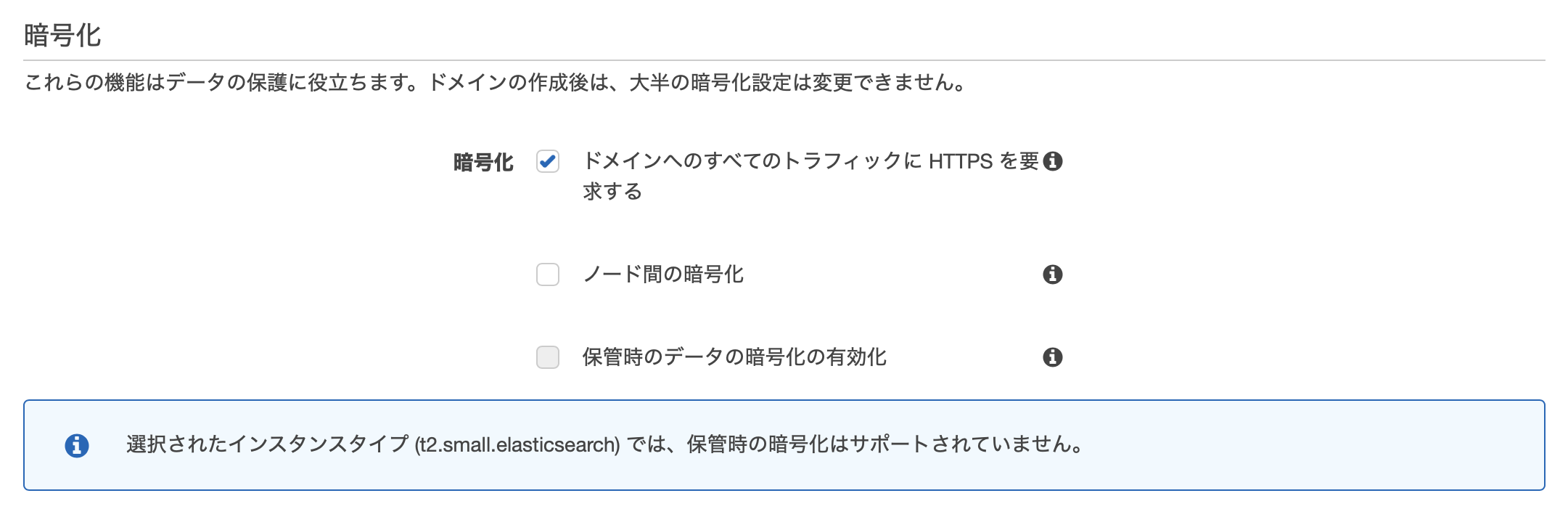
暗号化
リクエストやデータの暗号化設定です。この設定によりデータの機密性が高まります。
今回はデフォルトの「ドメインへのすべてのトラフィックに HTTPS を要求する」のみチェックしておきましょう。
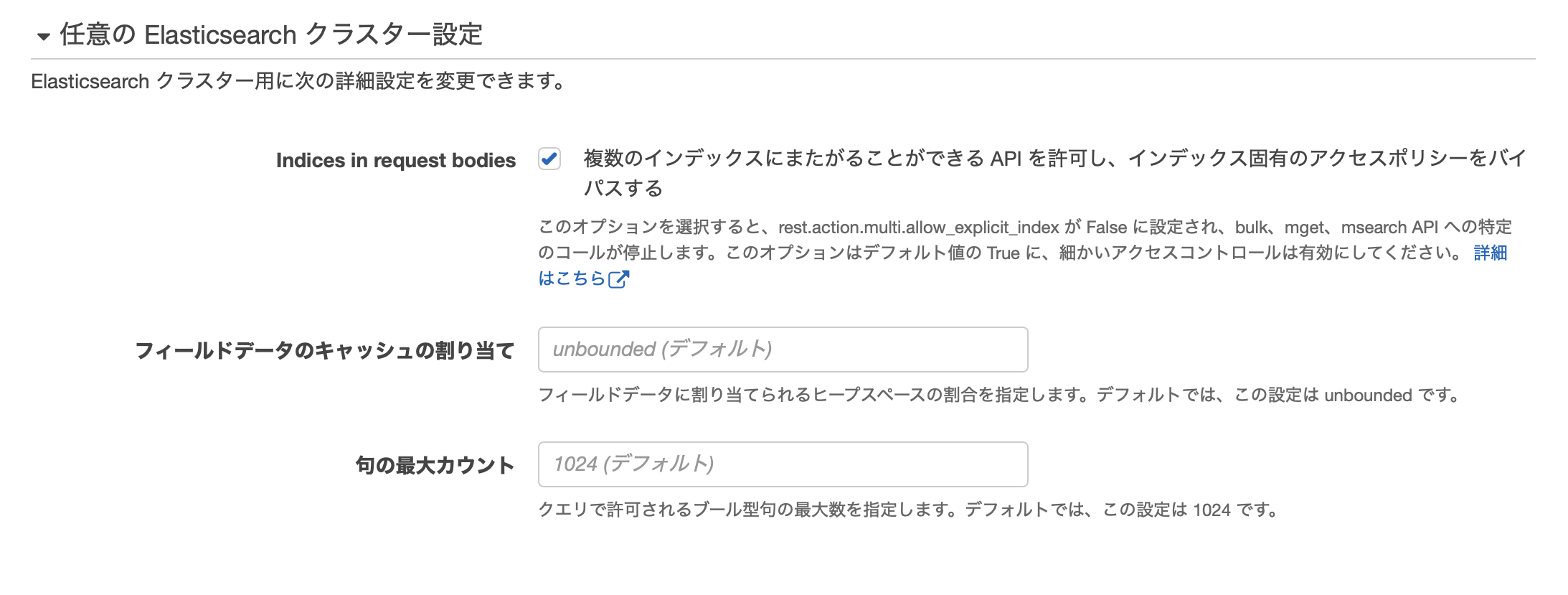
任意のクラスター設定
こちら今回は特に設定を変更しませんが、各項目の意味や利用用途をさらっと調べたので共有しておきます。
Indices in request bodies
デフォルト値であるtrueでは、その名の通りリクエストボディ内でのインデックス指定を有効化します。
falseにする場合の利用用途としてはユーザによる意図しないインデックスへの操作を防ぐ目的で使われるようです。
フィールドデータのキャッシュ割り当て
スループットを高めるため、Elasticsearchはフィールドデータをキャッシュする構成になっています。
この設定では、キャッシュを保持する領域の、Javaヒープサイズに対する割合を設定します。
デフォルトでは無制限となるのでOutOfMemoryエラーが発生する危険性をはらみます。
また、AWSの公式ドキュメントによると、以下のようなことが記載されています。
多くのお客様が、ローテーションするインデックスのクエリを毎日実行しています。indices.fielddata.cache.size を使用してベンチマークテストを始めることをお勧めします。このとき、ほとんどのユースケースでは JVM ヒープを 40% に設定してください。ただし、非常に大きいインデックスがある場合、さらに大きいフィールドデータキャッシュが必要になることがあります。
デフォルト40%にしといてくれたらええやん…
句の最大カウント
search apiを使用する場合のbool型句の使用制限です。
デフォルトの1024個を超えるような条件指定はあまり想像がつきませんが、そういったレアケースに対応する場合にこの値をチューニングする必要があります。
ただ、上限を高く設定してしまうとTooManyClausesエラーが発生する危険性があります。
Step 4: 確認
表示内容を確認し、「確認」ボタン押下でドメインが作成されます。
作成されたElasticsearchのURLをServiceの環境変数に記述
最後に前回作成したアプリケーションからElasticsearchインスタンスを参照できるように、Serviceの環境変数を編集します。
EC2インスタンスにSSH後、以下コマンドを実行します。
$ sudo vim /etc/systemd/system/kestrel-asp-net-app.service
# Environment=ASPNETCORE_ENVIRONMENT=Production以下に追加
Environment=DB_CONNECTION_STRING=server=サーバのエンドポイント;uid=admin;pwd=パスワード;database=asp_net_sample
Environment=ELASTIC_SEARCH_SERVER=VPCエンドポイント
VPCエンドポイントはElasticsearch Service Management Consoleにて、ドメインを選択して表示されたドメイン詳細画面に記載があります。
Environment=DB_CONNECTION_STRING=server=サーバのエンドポイント;uid=admin;pwd=パスワード;database=asp_net_sample
こちらについてはRDSでもEC2内でもいいので接続可能なデータベースへの接続文字列を入れておいてください。
RDS構築についてはこちら。
設定後、反映のためEC2インスタンスを再起動します。
確認
ローカルマシンにてhttp://サーバIP/をブラウザで開いてください。
Elasticsearchインスタンスが作成されたばかりでインデックスが存在していないので、環境の初期化を押下します。
以下のように検索が実行されれば正常に動作しています。

links
AWS Elasticsearch Serviceの公式ドキュメント
以下自分用メモ
ワークロード
・Long-lived index:長期間保持されるインデックス。検索サービスとしてElastic Searchを使用する場合、この手法が用いられる。想定すべき保守作業として、データのスキーマ更新等が発生した場合のインデックス内容の更新が挙げられる。
ハードディスク要件としては検索結果を導くためのデータ格納量に依存する。
・Rolling indices:決められた期間のみデータを保持するインデックス。ログ分析等、直近のデータを対象とした分析を行う場合に用いられる。
ハードディスク要件としてはログ等の出力頻度に依存する。
ストレージ要件詳細
- レプリカ:インデックスの完全なコピー。完全なコピーのため、ストレージ要件も同様。耐障害性を考慮した場合に少なくとも一つ以上のレプリカが必要。検索のスループットも考慮した場合はさらに必要になる場合もある。
- インデックス作成時のオーバーヘッド
インデックス作成時のオーバーヘッドにより、実際のディスク上のサイズはソースデータよりも10%大きくなることが見込まれるらしい… - オペレーティングシステムの予約済み領域
Linuxにおけるデフォルトの占有領域。rootユーザ用にファイルシステムの5%を予約している。 - Amazon ESのオーバーヘッド
Amazon ESにおけるデフォルトの占有領域。各インスタンスのストレージスペースの20%(最大で20GiB)を予約している。
以上を踏まえたストレージ要件の式は以下
ソースデータ * (1 + レプリカ数) * (1 + インデックス作成のオーバーヘッド) / (1 - Linuxの予約済み領域) / (1 - Amazon ESのオーバーヘッド) = 最小ストレージ要件
シンプルに算出する場合は以下
ソースデータ * (1 + レプリカ数) * 1.45 = 最小ストレージ要件
他のインスタンスに対する留意点
・最小ストレージ要件が1PBを超える場合:Petabyte Scale for Amazon Elasticsearch Service
・Rolling Indicesであり、ホットウォームアーキテクチャを採用する場合:UltraWarm for Amazon Elasticsearch Service
認証・権限について
ElasticSearch Serviceの、ドメインに対するアクセスの制限方法について
-
Resource-based Policies
リソースに対する許可アクションを、ユーザ、アカウント、ロールに対して設定することのできるアクセスポリシー。
権限は常にResource要素に指定されたドメイン配下のサブリソースにのみ適用される。
また、このポリシーで宣言された許可アクションについては、ドメインではなく、ドメインのサブリソースに対してのみ適用されるものであり、ドメインの構成を変更するようなアクションについては許容されない。前述のようなアクションを許容するにはIDベースのポリシーを利用しなければならない。 -
Identity-based Policies
AWSのIAMを使用したアクセスポリシー。
権限は常にResource要素に指定されたドメインにのみ適用される。
Resource-based Policiesとは異なり、ドメインの構成に対するアクションも許容することができる。
また、Resource-based Policiesとの違いとして、IAM内のユーザ、またはロールにアタッチするため、Principalの設定値を記述しなくて良いことが挙げられる。
本番運用する場合にはこちらを使用して権限を抽象化した方が良さそう。 -
IP-based Policies
IPアドレス、またはCIDRブロックを使用したアクセスポリシー。
Amazon ESドメインに署名されていないリクエストを許容できるので、curlやKibanaなどのクライアントを使用したり、プロキシサーバーを介してドメインにアクセスしたりすることができるようになる。