この記事は朝日新聞社 Advent Calendar 2021の第8日目の記事です。
こんにちは。朝日新聞社デジタル機動報道部でデータジャーナリズムの取り組みに携わっている山崎です。もともとエンジニアとして入社した背景を武器に、データの分析やそのビジュアライゼーションを記事の執筆に活かしているところなのですが、10月にあった衆院選で配信した「候補者つぶやき分析」の種明かしをしたいと思います!
1.目指すこと
執筆したのはこちらの記事↓↓
この中の後半に登場する、与野党の候補者でツイッターの投稿内容にどのような違いがあるのかについて表した、散布図のビジュアライゼーションを作ることがゴールです。
2.つぶやきの収集
収集には、pytyonライブラリ「tweepy」を活用しました。tweepyは、投稿、取得、いいね、リツイートなどの情報を簡単に集めることができるライブラリです。
まず、衆院選に立候補した候補者で、ツイッター社が本人のアカウントと認めた「認証済みバッジ」がある454アカウントに絞って、19日~27日に投稿された与党1万112件、野党1万984件のつぶやきの内容(リツイートを除く)を収集しました。
import pandas as pd
import tweepy
# Twitterオブジェクトの生成
# keyやTokenは各自の設定を入れる
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
# 取得したいユーザーのユーザーIDを代入
cols = ["twid", "name", "user", "party", "date", "tweet_text", "favo", "retw"]
df_tw = pd.DataFrame(index=[], columns=cols)
# df_twitterはアカウント一覧のDataframe
for index, row in df_twitter.iterrows():
user_id = row["tw_username"]
# つぶやきは(上限の)200件、リツイートは含まない、つぶやきを全文取得するオプションを設定
tweets = api.user_timeline(id=user_id, count=200, include_rts=False, tweet_mode="extended")
for tweet in tweets:
# つぶやき内容などと政党などの候補者の情報をDataframeに追加していく
df_tw = df_tw.append({"twid":tweet.id, "name":row["name"], "user":user_id, "party":row["party"], "date":tweet.created_at, "tweet_text":tweet.full_text, "favo":tweet.favorite_count, "retw":tweet.retweet_count }, ignore_index=True)
3.可視化
単語の出現頻度に合わせたきれいな散布図を生成できる「scattertext」というライブラリを使って可視化していきます。ライブラリでは、2012年にあった米大統領選における「共和党」と「民主党」の討論内容の差を例に散布図を作成しています。そのビジュアルにインスピレーションを受け、日本の選挙でも同じような違いが出るのではないか、と考えました。
日本語の文章はそのままでは解析できないので、分かち書きや品詞解析のためにginzaを活用。名詞、動詞、形容詞、副詞の単語の出現回数を集計します。
import scattertext as st
import spacy
from collections import Counter
from itertools import chain
import pandas as pd
# 品詞を絞りこんで、単語の出現回数を集計していく
class UnigramSelectedPos(st.FeatsFromSpacyDoc):
# 名詞、動詞、形容詞、副詞を集計
def __init__(self,use_pos=['NOUN', 'VERB', 'ADJ', 'ADV']):
super().__init__()
self._use_pos = use_pos
def get_feats(self, doc):
return Counter([c.lemma_ for c in doc if c.pos_ in self._use_pos])
# Corpusの作成
corpus = (st.CorpusFromPandas(df_tw,
category_col='label',
text_col='tweet_text',
nlp = spacy.load("ja_ginza"),
feats_from_spacy_doc=UnigramSelectedPos()
)
.build())
作成したcorpusから、単語の出現回数や単語のスコアを取り出します。また、散布図にプロットするために、単語の出現回数のランキングを与党、野党ごとに計算します。そうすることで、例えば与党で順位が高く、野党で順位が低い単語は「与党が使いがちな単語(争点)といえる可能性がある」ことになります。
scattertextは散布図のHTMLをきれいにはき出す機能も備えていますが、今回は成果物を外部のビジュアライゼーションツールで公開したかったので、その機能は活用しませんでした。
from scattertext.termscoring.RankDifference import RankDifference
from scipy.stats import rankdata
import numpy as np
# 各単語の出現回数とスコアを吐き出す
freq_df = corpus.get_term_freq_df()
freq_df["score"] = RankDifference().get_scores(freq_df["与党 freq"], freq_df["野党 freq"])
# 与野党候補のつぶやき総数が100回以下の単語は対象外にする
freq_df["count"] = freq_df["与党 freq"] + freq_df["野党 freq"]
freq_df = freq_df[freq_df["count"] > 100]
# 単語ごとの出現回数の順位を与野党ごとに計算する
freq_df["order_与党"] = rankdata(np.array(freq_df["与党 freq"]))
freq_df["order_野党"] = rankdata(np.array(freq_df["野党 freq"]))
# 出力
freq_df.to_csv('./scattertext_output.csv')
4.Flourishでビジュアライゼーション!
データの可視化には、簡単におしゃれでリッチなビジュアルが作れる「Flourish」を活用しました。報道用アカウントを発行してもらうと有料版の機能が無料で利用可能になるというのが採用理由なのですが、無料アカウントでもほぼ全ての機能が使えて、誰でもクオリティーの高いコンテンツを作成→公開まで出来るのが強みだと思います。
◆公開までの手順
1.テンプレートを選択
まずは散布図用のテンプレートを選択。Flourishは折れ線や棒グラフ、レースチャートなどのテンプレートがあらかじめ用意されていて、データを差し替えるだけですぐにアウトプットができるところも魅力の一つです。
2.データのアップロード
「Data」タブから、先ほどの単語とスコアのデータをアップします。列名は下図のように名付けました。
アップロードが完了したあとに、どの列を使うのかについても設定していきます(図では隠れてしまっていますが、「Filter control」にH列を設定しています)。
3.項目設定(と微調整)
Previewタブへ移動すると、すでに散布図が完成していると思います。右側にある設定項目で、見出しやフォントなどを調整。このあたりはマニュアルがなく、経験とセンスに頼る部分が大きく苦労するのですが、頑張って設定します(自分はデザイン部の社員の知恵をかり…笑)
4.公開!
「publish」ボタンを押して、コンテンツを公開します。
公開すると、URLが自動で割り当てられて、作成したビジュアルが誰でも閲覧できる状態になります。今回公開した弊社のコンテンツはこちら。朝日新聞デジタルではこれを記事内に埋め込んで読者に届けています。
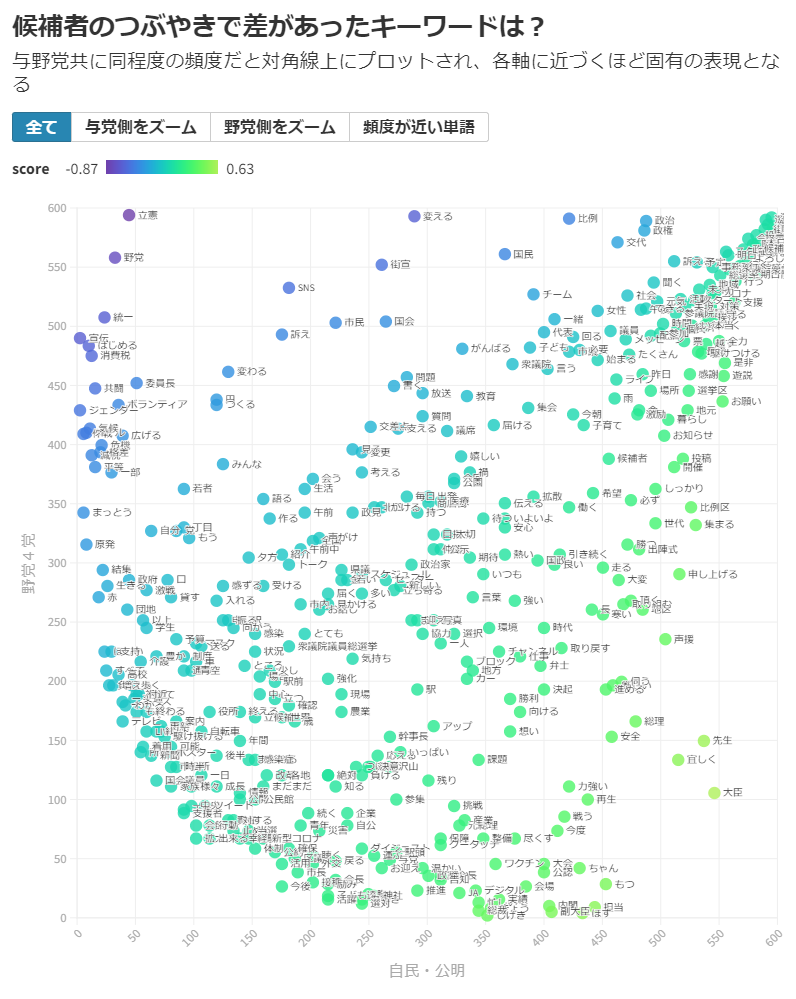
与野党それぞれでズームしてもらうと分かりやすいのですが、「消費税」「ジェンダー」「気候」「格差」といった単語の利用頻度で差があることがわかりました。いずれの単語も、野党候補者のつぶやきでそれぞれ100回以上登場していて、「気候危機、ジェンダー、若者の未来を奪う政治を変えなければ」「ジェンダーのテーマを正面に掲げて選挙で訴える」などといった投稿で使われていたのですが、一方の与党候補者ではこれらの単語はいずれも各10回ほどか、それ以下の言及にとどまっていました。
逆に与党側で目立ったのは、「大臣」「担当」などの役職を表す単語。「厳しい」も比較的多く、「初日から党本部から応援が来る厳しい戦いを走り抜けます」といったつぶやきが計185件あって、野党共闘候補などへの危機感を募らせる胸中がうかがえます。
5.終わりに
衆院選候補者ツイッターのつぶやき内容から、ビジュアライゼーションツールを使ってデータの可視化をすることで、単語の出現回数ランキングといった数値の一覧では理解しにくい違いが与野党間であることを、直感的に理解することができました。
デジタル機動報道部では、選挙だけでなく、犯罪やコロナなど気になるニュースや話題をデータから読み解く試みを続けています。取り組みをまとめたページも用意しているので、ぜひこちらもチェックしてみて下さい!
6.参考
scattertextで文章の単語出現頻度を可視化
Twitter APIで遊んでみた ~2. ツイートの投稿と取得~
朝日新聞社では、技術職の中途採用を強化しています。
ご興味のある方は下記リンクから希望職種の募集ページに進んでください。
皆様からのご応募、お待ちしております!