1. はじめに
前回の記事「ClickPipes CDC の取り込み上限は ClickHouse レプリカを増やすと動くのか」で、PostgreSQL → ClickHouse Cloud の CDC は ClickHouse のレプリカを増やしても取り込みレートが変わらない(ボトルネックはパイプ側にある)ことを実測しました。
では、レプリカを増やす意味はどこにあるのか。前回の記事は最後に「レプリカ増の使いどころは取り込みではなく、OLAP クエリの同時実行側にある」と結んでいました。本記事はこの予告を 単一クエリのレイテンシ と 同時実行スループット に切り分け、今回はそのうち前者を確かめます。ClickHouse Cloud には、1 本のクエリを複数レプリカで分担して実行する parallel replicas という仕組みがあります。さらに 2026 年 5 月の公式ブログ マルチステージ分散クエリ実行 では、現行の parallel replicas の限界がはっきり書かれています。
- JOIN: 各ノードが完全な右側テーブルをメモリ保持する必要があった
- 集計: 最終マージが単一コーディネータに集約されていた
この「現行の限界」は、自分の環境のクエリではどう見えるのか。CDC で取り込んだテーブル(ReplacingMergeTree)相手に、レプリカ 1 → 2 → 3 台で実測してみます。CDC 構成ならではの観点として、取り込みが流れている最中の読みと、並列読みが取り込みを遅らせないかもあわせて確認します。
1.1. 今回の検証ゴール
| # | 検証項目 | 確認できれば OK |
|---|---|---|
| 1 | CDC 取り込み済みテーブルへの OLAP クエリは、parallel replicas でレプリカ数に応じて速くなるか | レプリカ 1/2/3 × 設定 off/on でクエリ種別ごとの実行時間の系列が揃う |
| 2 | 取り込み(約 20,000 行/秒)と読みは相互に干渉するか | 取り込み中の読みの傾向と、並列読み中のレプリケーションラグが数値で言える |
| 3 | ReplacingMergeTree の FINAL クエリで parallel replicas が無効になる(公式記載)ことの実測確認 | FINAL あり/なしの実行時間と EXPLAIN の差が取れる |
1.2. 結論の先出し
- スキャンと高カーディナリティ集計はレプリカ数でしっかりスケールする(高カーディナリティ集計は 3 台で約 1.65 倍、スキャン集計は約 1.20〜1.35 倍)。parallel replicas は「スケールするクエリ」では素直に台数効果が出る
- 取り込みと読みが両立する: 約 20,000 行/秒の CDC が流れている最中でも読みのスケール傾向は変わらず(むしろ微増)、逆に 4 並列で読みを流し続けてもレプリケーションラグは数秒のままで取り込みを遅らせない。リアルタイム分析の土台として心強い挙動
- 取り込み中の FINAL 劣化(1 台で +44%)はレプリカ増で解消する。これは並列読みではなくマージ容量が増えた効果で、レプリカを足すほど取り込み中の劣化が和らぐ
- 一方でスケールしにくいクエリもある: 複数テーブル JOIN はほぼ横ばい、複雑な JOIN は並列化対象外で設定 on だとプラン変化で約 15% 遅くなるケース、FINAL も対象外(いずれも現行モデルの制限で、公式は multi-stage 実行で解消を進めている)
2. parallel replicas の仕組みと公式の制限
公式 Docs によれば、parallel replicas はシャーディングなしの構成(ClickHouse Cloud)で 1 本のクエリを複数レプリカに分散する仕組みです。コーディネータとなったレプリカがテーブルを granule(読み取りの最小単位)のタスクに分割して各レプリカへ動的に割り当て、遅いレプリカのタスクを速いレプリカが引き取る task stealing も行います。
有効化はセッション設定で行います(今回は HTTP インターフェースの URL パラメータで指定)。
SET enable_parallel_replicas = 1;
SET cluster_for_parallel_replicas = 'default'; -- Cloud では 'default'
SET max_parallel_replicas = 3; -- 分散させる最大レプリカ数
同じ公式 Docs に制限事項も列挙されています。今回の検証に関係するのは次の 2 点です。
- FINAL では無効化される("Parallel replicas are disabled with FINAL")— CDC の取り込み先 ReplacingMergeTree で重複排除込みの正確な読みをするには FINAL が要るため、CDC 構成では直撃する制限です
- 小さいクエリではノード間の調整コストが効果を相殺する、CTE(
WITH句で定義する一時的な名前付き結果セット)・サブクエリ・JOIN を含む複雑なクエリでは性能低下の可能性がある
3. 検証環境
| 項目 | 値 |
|---|---|
| ソース DB | ClickHouse Managed Postgres(r8gd.4xlarge: 16 vCPU / 128 GiB、No standby)、PostgreSQL 18.4 |
| 取り込み先 | ClickHouse Cloud 26.2.1、レプリカあたり 12 GiB / 3 vCPU(オートスケール固定)、Number of replicas を 1 → 2 → 3 と手動変更 |
| CDC | ClickPipes for Postgres(既定設定、稼働中の既存パイプを流用) |
| 読み対象データ | TPC-C SF=20 の CDC 取り込みテーブル(order_line 731 万行ほか)+ 追記テーブル cdc_probe 約 1.08 億行 |
| 負荷生成・読みクライアント | 同一 PC(pgbench / curl 経由 HTTPS)。全条件で共通 |
レプリカあたりのサイズは 12 GiB・3 vCPU に固定(垂直オートスケール無効)し、変えるのはレプリカ台数だけです。台数変更は Cloud コンソールの Scaling 設定で行いました。
 |
 |
|---|
4. 検証設計
4.1. 計測マトリクス
| 軸 | 振った値 |
|---|---|
| レプリカ台数 | 1 / 2 / 3 |
| parallel replicas | off / on(on 時は max_parallel_replicas = 台数) |
| CDC 取り込み負荷 | なし / 約 20,000 行/秒(pgbench でバッチ INSERT、各台数で 15 分間) |
| クエリ | 下記 5 種、各条件で warmup 1 回 + 本計測 3 回の平均 |
取り込みレートの 20,000 行/秒は、前回実測した(デフォルトコンピュート時の)単一パイプの持続取り込みレート 約 40,000 行/秒の半分で、ラグが増え続けない安定域として選んでいます。クエリの実行順は全台数で固定し、計測は同一クライアントからの HTTPS 経由(応答までの時間)です。ネットワーク往復は全条件共通なので、条件間の比較では相殺されます。
4.2. クエリ 5 種
TPC-C のテーブルへの分析クエリ集(HTAP 向けベンチマーク CH-benCHmark に由来。TPC-C は本来 OLTP 向けですが、その表に OLAP クエリを足したものです)から、性質の異なる 3 本と、確かめたい点を直接ねらった合成クエリ 2 本を使います。
| 表内の略称 | 対象 | 内容 | 見たい性質 |
|---|---|---|---|
| スキャン集計 | order_line(731 万行) | 日付・数量条件で sum
|
単純スキャンの分散 |
| JOIN+集計 | customer × oorder × order_line × nation | 顧客別売上の GROUP BY | 中規模 JOIN + 集計 |
| 重い JOIN | 5 テーブル + 相関 NOT EXISTS | 配送遅延サプライヤ集計 | 複雑な JOIN の挙動 |
| 高カーディナリティ集計 | cdc_probe(1.08 億行) | 約 1,080 万グループの GROUP BY(合成) | 集計マージのコーディネータ集中 |
| FINAL 付き集計 | cdc_probe FINAL | 重複排除込みの count / sum | CDC テーブルの正確な読み |
合成クエリ 2 本は次のとおりです。高カーディナリティ集計は、multi-stage ブログが挙げる「最終マージの単一コーディネータ集約」を直接突くために、グループ数を意図的に約 1,080 万まで増やしています。
-- 高カーディナリティ集計(約 1.08 億行 → 約 1,080 万グループ)
SELECT intDiv(id, 10) AS grp, count() AS c, max(length(payload)) AS ml
FROM cdc_probe
WHERE id <= 108000000
GROUP BY grp
ORDER BY c DESC, grp DESC
LIMIT 10;
-- FINAL 付き集計(ReplacingMergeTree の重複排除込み)
SELECT count(), sum(length(payload))
FROM cdc_probe FINAL
WHERE id <= 108000000;
id <= 108000000 の固定条件は、計測中の取り込み INSERT(id はこれより大きい採番)で対象データが変わらないようにするためです。台数間の比較条件を揃える役割があります。
4.3. つまずいた点: PostgreSQL で動くクエリをそのまま流用すると結果が変わる
これらの分析クエリを ClickHouse 側へ流用する際、2 件の修正が必要でした。
1 件目: CHAR 列の末尾スペース。 nation.n_name は PostgreSQL 側で CHAR(25) です。PostgreSQL の CHAR 比較は末尾スペースを無視するため n_name = 'Germany' が 1 行一致しますが、CDC で ClickHouse に取り込まれると型は String になり、パディングがそのまま保持されるため同じ述語が 0 行になります。重い JOIN のクエリがこの影響で 0 行即返しになっていたため、trimRight(n_name) = 'Germany' に修正しました(nation は 62 行のディメンション表なので関数適用の性能影響は無視できます)。
2 件目: 日付リテラルとデータ分布の不一致。 スキャン集計クエリの範囲 [1999-01-01, 2020-01-01) は、BenchBase が生成する TPC-C データ(ol_delivery_d は未配送 = 1970 年エポックか、実行時刻 = 2026 年の二極)に 1 行も一致せず、サーバ側の実行 3 ms・読み取り 0 行の実質空振りでした。範囲を [2020-01-01, 2027-01-01) に変更し、配送済み約 486 万行を実スキャンする形にしています。
どちらも「クエリは正常に返るのに、意図した仕事をしていない」パターンです。流用クエリは結果行数と読み取り行数(system.query_log の read_rows)を必ず確認してから使うことをおすすめします。
5. 計測結果 1: 読みはレプリカ数でスケールするか(無負荷)
5.1. off はすべて横ばい(サニティチェック)
まず parallel replicas を使わない場合、レプリカを増やしても 1 本のクエリは 1 レプリカで実行されるため、速くならないはずです。実測もそのとおりでした(1 台を 1.00 とした倍率。大きいほど速い)。
| クエリ | 1 台(秒) | 2 台(秒) | 3 台(秒) | 2 台 倍率 | 3 台 倍率 |
|---|---|---|---|---|---|
| スキャン集計 | 0.104 | 0.092 | 0.149 | 1.13x | 0.70x |
| JOIN+集計 | 1.310 | 1.229 | 1.354 | 1.07x | 0.97x |
| 重い JOIN | 3.022 | 2.749 | 2.711 | 1.10x | 1.11x |
| 高カーディナリティ集計 | 2.395 | 2.517 | 2.215 | 0.95x | 1.08x |
| FINAL 付き集計 | 2.310 | 2.208 | 2.277 | 1.05x | 1.01x |
おおむね ±10% の範囲で横ばいです(スキャン集計の 3 台 0.70x は 0.1 秒級の小さいクエリのばらつきで、他条件では再現していません)。
5.2. on でスケールしたのは集計系とスキャン(特に高カーディナリティ集計)
parallel replicas を有効にすると、クエリ種別ではっきり差が出ました。
| クエリ | 1 台(秒) | 2 台(秒) | 3 台(秒) | 2 台 倍率 | 3 台 倍率 |
|---|---|---|---|---|---|
| スキャン集計 | 0.095 | 0.073 | 0.079 | 1.30x | 1.20x |
| JOIN+集計 | 1.354 | 1.311 | 1.271 | 1.03x | 1.06x |
| 重い JOIN | 2.945 | 3.335 | 3.482 | 0.88x | 0.85x |
| 高カーディナリティ集計 | 2.286 | 1.580 | 1.384 | 1.45x | 1.65x |
| FINAL 付き集計 | 2.327 | 2.216 | 2.212 | 1.05x | 1.05x |
- 高カーディナリティ集計は 3 台で 1.65 倍と最もはっきりスケールしました(台数比例の 3 倍には届かないものの、明確な台数効果)
- スキャン集計も 2 台 1.30 倍・3 台 1.20 倍とスケールします(0.1 秒級の小さいクエリのため倍率のばらつきは大きめ)
- JOIN+集計はほぼ変わらず(3 台で 1.06 倍)
- 重い JOIN は逆に 15% 前後遅くなりました(次節)
- FINAL 付き集計は変わりません(7 章)
5.3. EXPLAIN で裏取りする
並列化が実際に行われたかは実行計画で確認できます。レプリカ 2 台・設定 on のスキャン集計では、プランに ReadFromRemoteParallelReplicas が現れ、もう 1 台のレプリカへ作業が配布されています。
Expression ((Project names + Projection))
MergingAggregated
Union
Aggregating
Expression (Before GROUP BY)
Expression ((WHERE + Change column names to column identifiers))
ReadFromMergeTree (default.public_order_line)
ReadFromRemoteParallelReplicas (Query: SELECT sum(...) FROM default.public_order_line ...(中略))
off では通常の単一レプリカのプランです。
Expression ((Project names + Projection))
Aggregating
Expression (Before GROUP BY)
Expression ((WHERE + Change column names to column identifiers))
ReadFromMergeTree (default.public_order_line)
5.4. 重い JOIN は「並列化されないのに遅くなる」
意外だったのは重い JOIN です。設定 on のプランを確認すると、ReadFromRemoteParallelReplicas は現れません。相関 NOT EXISTS を含む複雑な形状のため並列化の対象外になったようです。ところが実行時間は off より一貫して遅い。
off と on の EXPLAIN を比較すると、並列化はされていないのに JOIN の組み立て順序が変わっていました(supplier と stock の結合順が入れ替わり、order_line の読み取り位置が移動)。設定を有効にしただけで、並列化されないクエリのプラン選択まで変わり、今回はそれが遅い側に転んだ、という挙動です。
(off と on の EXPLAIN diff・抜粋)
< ReadFromMergeTree (default.public_stock)
---
> ReadFromMergeTree (default.public_supplier)
6. 計測結果 2: 継続 CDC との相互干渉
6.1. 取り込み中でも読みのスケール傾向は同じ
各レプリカ台数で、pgbench から cdc_probe へ約 20,000 行/秒のバッチ INSERT を 15 分間流し(実績 19,959〜20,110 行/秒、失敗 0)、その最中に同じクエリセットを実行しました。設定 on の結果です。
| クエリ | 1 台(秒) | 2 台(秒) | 3 台(秒) | 2 台 倍率 | 3 台 倍率 |
|---|---|---|---|---|---|
| スキャン集計 | 0.087 | 0.069 | 0.064 | 1.26x | 1.35x |
| JOIN+集計 | 1.453 | 1.326 | 1.196 | 1.10x | 1.22x |
| 重い JOIN | 2.885 | 3.311 | 3.286 | 0.87x | 0.88x |
| 高カーディナリティ集計 | 2.350 | 1.572 | 1.440 | 1.50x | 1.63x |
| FINAL 付き集計 | 3.227 | 2.367 | 2.213 | 1.36x | 1.46x |
無負荷時と同じ傾向です(高カーディナリティ集計がスケールし、重い JOIN は悪化)。取り込みが流れていても読みのスケール特性は変わりません。むしろ取り込み中はスキャン集計・JOIN+集計の倍率がやや上向き(3 台で 1.35x / 1.22x)で、ライブな CDC データに対しても parallel replicas が素直にスケールします。「書き込みながら読む」状況で台数効果が目減りしないのは、HTAP 的な使い方の追い風です。FINAL 付き集計だけは無負荷時と違う動きをしており、これは 7 章で扱います。
6.2. 並列読みはレプリケーションラグを悪化させない
逆方向の干渉も見ます。取り込みを流したまま、スキャン集計と重い JOIN を 4 並列で 5 分間連続実行し、その間のレプリケーションラグを 15 秒間隔で記録しました。ラグは「ClickHouse 側に取り込まれた最新行のタイムスタンプと現在時刻の差」、スロットのラグは PostgreSQL 側 pg_replication_slots の未転送バイト数です。
| レプリカ台数 | ラグ: 読みなし avg/max | ラグ: 並列読み中 avg/max | スロット: 読みなし avg | スロット: 並列読み中 avg |
|---|---|---|---|---|
| 1 | 3.7 秒 / 5.8 秒 | 3.6 秒 / 6.3 秒 | 13.8 MB | 22.9 MB |
| 2 | 2.7 秒 / 4.7 秒 | 4.0 秒 / 6.4 秒 | 15.9 MB | 18.3 MB |
| 3 | 2.9 秒 / 5.4 秒 | 4.2 秒 / 6.2 秒 | 17.9 MB | 20.0 MB |
並列読み中もラグは avg 4 秒前後・max 6.4 秒以内で、読みなし区間と同じ水準でした。この負荷水準では、並列読みが CDC の取り込みを遅らせることはありませんでした。読み負荷と取り込みがレプリカ上でうまく分離されており、分析クエリを並列に叩いてもレプリケーションラグが伸びない——取り込みと OLAP を同じ基盤に同居させたいケースでは扱いやすい性質です。
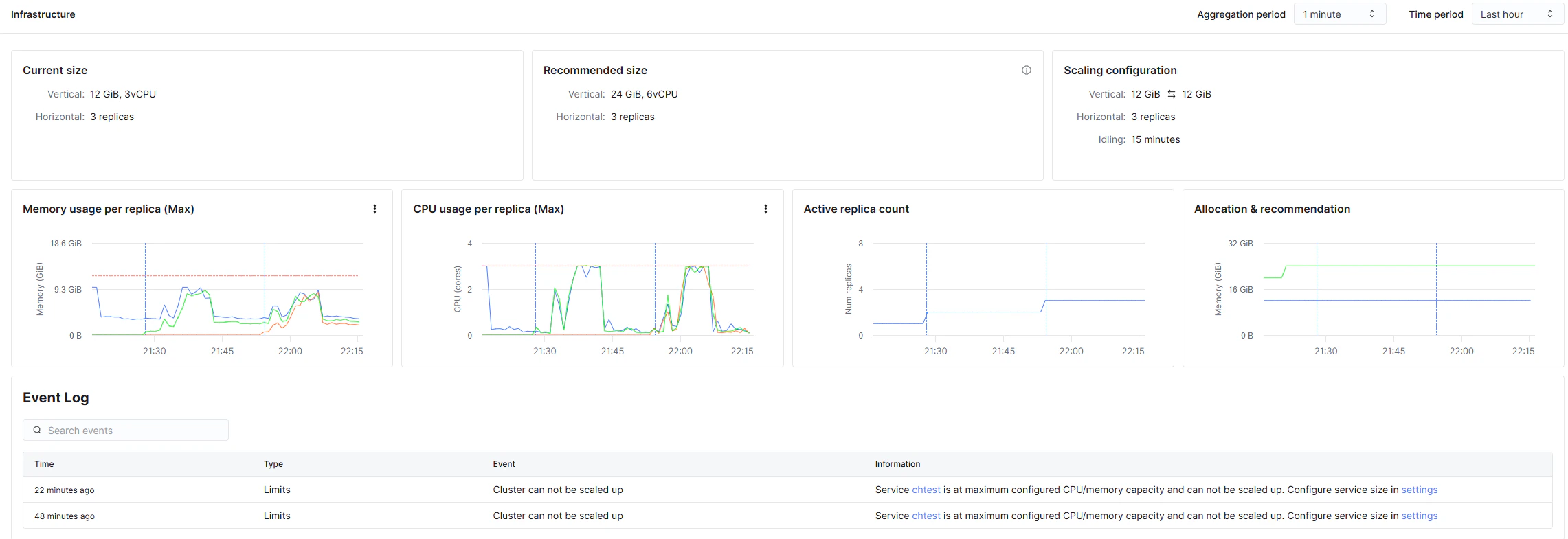
読みが実際に全レプリカへ分散したことは、コンソールの Infrastructure 画面でも確認できます。並列読みの時間帯に、3 レプリカの CPU が揃って上限(3 cores)近くまで上がっています。
7. 計測結果 3: FINAL と parallel replicas — CDC 取り込みテーブル固有の制約
7.1. FINAL は並列化されない(公式記載どおり)
ClickPipes の取り込み先は ReplacingMergeTree なので、UPDATE を含むテーブルで「正確な値」を読むには FINAL が必要です。公式 Docs に「Parallel replicas are disabled with FINAL」とあるとおり、設定 on で FINAL 付きクエリの EXPLAIN を取っても ReadFromRemoteParallelReplicas は現れず、エラーも警告もなく単一レプリカのプランで実行されました。実測も全台数で 1.05 倍と横ばいです。
CDC 取り込みテーブルの「重複排除込みの正確な読み」は、レプリカを増やしても並列化されません。設定を on にしてもエラーにならず黙ってフォールバックするため、効いているつもりで効いていない状態に気づきにくい点に注意してください。
7.2. ただし取り込み中の FINAL 劣化はレプリカ増で解消する
一方で、取り込み中の FINAL には別の動きがありました。
| レプリカ台数 | 無負荷(秒) | 取り込み中(秒) | 取り込みによる変化 |
|---|---|---|---|
| 1 | 2.310 | 3.317 | +44% |
| 2 | 2.208 | 2.344 | +6% |
| 3 | 2.277 | 2.190 | −4%(差なし) |
1 台では取り込み中に 44% 遅くなりますが、2 台でほぼ解消します。これは parallel replicas の効果ではありません(設定 off でも同じ値でした)。取り込み中はマージ前の parts が増え(1 台では active parts が 6 → 13 まで増加、2 台では 7〜10 で安定)、FINAL がクエリ時に処理する未マージ parts の量が変わるためと考えられます。つまり レプリカ増は「並列読み」ではなく「マージ容量」として FINAL に効いた、という切り分けです。
8. 考察
8.1. スケールしたもの・しなかったものの整理
今回の結果を、並列化の有無(EXPLAIN で確認)と合わせて整理します。
| クエリ種別 | 並列化(EXPLAIN) | 3 台での倍率(無負荷・on) | multi-stage ブログの対応箇所 |
|---|---|---|---|
| スキャン集計 | される | 1.20x | スキャン主体は現行モデルでも分散される |
| JOIN+集計 | される | 1.06x | JOIN は右表を各ノードが全量保持 → 効果が出ない |
| 重い JOIN | されない(プランのみ変化) | 0.85x | 複雑な形状は対象外。性能低下の可能性も公式記載 |
| 高カーディナリティ集計 | される | 1.65x | 最終マージがコーディネータ集中 → 台数比例に届かない |
| FINAL 付き集計 | されない(公式記載) | 1.05x | 言及なし(CDC 構成固有の制約) |
この結果は multi-stage ブログの説明とよく整合します。同ブログは、現行 parallel replicas の弱点として JOIN の右表全量保持と集計マージのコーディネータ集中を挙げ、ステージ間で中間データを再パーティション化する Exchange オペレータ(ShuffleExchange / BroadcastExchange)で解決するとしています。今回スケールしなかった JOIN 系と、サブリニアに留まった高カーディナリティ集計は、まさにその対象です。なお multi-stage 実行は執筆時点(2026/6)でプライベートプレビューであり、一般には試せません。本記事の結果は「multi-stage 以前の現行モデル」の実測値です。
重い JOIN が設定 on で遅くなった件は、EXPLAIN の比較で JOIN の組み立て順序が変わったことまでは確認できましたが、なぜ遅い順序が選ばれたかは未深掘りです(要追加検証)。並列化の対象外になるクエリが混在するワークロードでは、セッション一律で on にするのではなく、クエリ単位で設定する方が安全と考えられます。
8.2. 前提と限定
本記事の「スケールしない」は、ClickHouse Cloud 26.2.1・レプリカあたり 12 GiB / 3 vCPU・本記事のクエリセットという構成での結果です。multi-stage 実行が一般提供されればこの結論は変わる可能性が高く(公式がそのための機能と明言しています)、またデータ規模が大きいほど調整コストよりスキャン分散の効果が出やすくなる方向です。秒未満の小さいクエリでは、公式 Docs の注意どおり調整コストで効果が薄れます。
また、レプリカ増の価値は単一クエリのレイテンシ短縮よりも、取り込みとの両立・マージ容量(7.2 章)や、同時実行スループット・可用性の側にあると考えられます。同時実行スループットのスケールは今回計測しておらず、今後の課題です。
9. まとめ
| 観点 | 結果 |
|---|---|
| 読みのレプリカスケール | スキャン・高カーディナリティ集計は素直にスケール(高カーディナリティ集計 3 台で 1.65 倍、スキャン 1.2〜1.35 倍)。JOIN 系は効果薄、複雑な JOIN は現行モデルで対象外 |
| 設定 on の副作用 | 並列化対象外の複雑な JOIN でプラン選択が変わり、約 15% 遅くなるケースあり(EXPLAIN diff で確認) |
| FINAL(CDC の正確な読み) | parallel replicas の対象外(公式+EXPLAIN+実測で一致)。取り込み中の劣化(+44%)はレプリカ増で解消し、これはマージ容量の効果 |
| CDC との相互干渉 | 約 20,000 行/秒の取り込み中も読みのスケールは不変(むしろ微増)。読みを 4 並列で流してもレプリケーションラグは数秒のまま=取り込みと読みが両立 |
| レプリカ増の使いどころ | 単一クエリのレイテンシ短縮目的では効果が限定的。価値は取り込みとの両立・マージ容量(実測)と、同時実行・可用性(今後)にある |
書き込み側(前記事)と合わせると、現行モデルの実像はこう整理できます。CDC の取り込み自体はレプリカ数で変わらない(前記事)一方、読み側ではスキャンと高カーディナリティ集計が素直にスケールし、取り込みと読みも両立する(取り込み中もスケール傾向は不変、4 並列で読みを流してもレプリケーションラグは数秒)。スケールしにくい JOIN 系と FINAL は、公式が multi-stage 実行で解消を進めている現行モデルの制限です。前記事が示した「レプリカ増の使いどころはクエリ側」という見立ては、本記事で 「スケールするクエリの単一レイテンシ+取り込みとの両立・マージ容量」には当てはまり、JOIN 系の単一レイテンシや同時実行スループット(未計測)はこれから と精緻化できました。multi-stage 実行が JOIN と集計のシャッフルを解禁したとき、この表がどう塗り替わるかを楽しみにしています。
参考
- マルチステージ分散クエリ実行(ClickHouse 公式ブログ・日本語) — 現行 parallel replicas の限界と Exchange オペレータによる解決、プライベートプレビューの提供状況
- Parallel Replicas(ClickHouse 公式 Docs) — 仕組み・設定・制限事項(FINAL 非対応ほか)
- Postgres to ClickHouse: Data Modeling Tips(ClickHouse 公式ブログ) — CDC で取り込んだ ReplacingMergeTree の重複排除(FINAL ほか)とデータモデリング
- ClickPipes for Postgres: Scaling(ClickHouse 公式 Docs) — 取り込み側のスケール手段
- BenchBase(CMU-DB) — TPC-C / CH-benCHmark ドライバー
- 前記事: ClickPipes CDC に書き込みを増やして、ClickHouse の取り込み限界を試してみた
- 前記事: ClickPipes CDC の取り込み上限は ClickHouse レプリカを増やすと動くのか
- 前記事: ClickHouse Managed Postgres の CDC はどれくらい速い?