概要
「こちら」の試行錯誤編です。
長くなってしまいましたので2つに分けました。
※「試行1」は重複して記載しています。
試行1「罪と罰」
何はなくとも、まずは公開されているオリジナルをそのまま実行してみます。
- [オリジナルcolab実行環境(Google Colaboratory)]
(https://colab.research.google.com/github/google/trax/blob/master/trax/models/reformer/text_generation.ipynb)
オリジナルの処理で何をやっているかというと、ドストエフスキーの小説「罪と罰」を学習してモデルを作成後、任意に入力した「There was a time when」に続く文章を自動生成しています。
- 学習データの読み込み
読み込むファイルのパスは、「gs://」となっており、Cloud Storage内に公開ファイルとして置かれていますので、気にせずにそのまま実行します。

- 学習(1step)
学習は「train_epoch」にて行っていますが、1stepしか学習していないため、精度や損失は非常に悪いです。

- 文章生成1
最後に「There was a time when」に続く文章を8パターン自動生成しています。
 パッと見て単語の並び順は合っていそうですが、よく読むと、「There was a time when the door , 」のように変な位置にカンマが登場していて、理解できない文章も多いです。
パッと見て単語の並び順は合っていそうですが、よく読むと、「There was a time when the door , 」のように変な位置にカンマが登場していて、理解できない文章も多いです。
- 学習(600step)
学習量を600stepに増やしてみると、精度が72%にまで向上しています。

- 文章生成2
この状態で再度文章を生成してみると、まだ理解に苦しむ部分は残っていますが、先ほどよりは改善しているようです。

試行2「新書太閤記」
試行2-1(学習データ置き換え)
今回の目的である日本語の文章を生成するために、何でも構わないのでとにかく日本語を学習させます。
とりあえず、青空文庫で公開されていた吉川英治著「新書太閤記」を学習させてみます。
ぜひもなく秀吉もまた、軍をかえして、楽田へひきあげた。
彼が舌を巻いて嘆じて云った――モチにも網にもかからない家康と、またふたたび、小牧において、にらみあいの対峙をつづけるほかなかった。
こうして、長久手の一戦は、池田勝入父子のあせりに大きな敗因があったにしても、秀吉にとって、重大な黒星であったことは、いなみ得ない。
だが。
こんどに限っては、終始、秀吉のほうが何となく、その序戦の前からすべてに立ち後れをとっていたのも事実である。
それは、秀吉が、戦場における家康を見て、初めて、モチにも網にもかからない男だと知ったのでなく、戦わざるうちから、家康の何者なるかを、熟知していたためだった。
いわば、達人と達人、横綱対横綱の、立ちあがりにも似ていた。
そして、「秀吉は、」で始まる文を自動生成させます。

結果はご覧の通り、単に英字が出力されているだけです。やはり、学習データを変えるだけでは日本語は生成されないようです。
日本語を生成できないのは「新書太閤記」の日本語をトークンに分割するトークナイザが「cp.320.model」ファイルになっているためです。この謎の「cp.320.model」ファイルですが、これは、トークナイザSentencepieceによって作成されたモデルファイルです。

「cp.320.model」と一緒に置かれている「cp.320.vocab」に分割可能なトークンの一覧が記載されています。「cp.320.vocab」の中身を見ると、英語単語よりも短い英字サブワードが記載されていて、日本語はひとつも存在していません。このため、日本語の書物である「新書太閤記」をトークンに分割することができないのです。

試行2-2(日本語版トークナイズモデル)
トークナイズモデルを日本語版に置き換えます。
ちょうど、以下のサイトに日本語のSentencePieceモデルが公開されていましたので使用させていただきます。
このようなファイルを公開していただけるのは、時間を短縮できますので非常に助かります。
ここ数年の自然言語処理の技術進化は、ものすごく速く、個人で全てを追いかけるのは無理があります。ましてや、私のように趣味で試す人達にとっては(そんな人が他にどれだけいるのか分かりませんが)、十分に時間をとれません。
こういった形で成果を共有し合うことは、とても重要に考えています。
上記SentencePieceモデルをトークナイザにセットして、改めて学習します。

- 文章生成(学習1stepのみ)
「秀吉は、」を与えると、今度は英字ではなく日本語が出力されました。
 日本語と言っても、日本語で使われている文字を羅列しただけで、まるで暗号文のようです。これでは全く理解できません。
日本語と言っても、日本語で使われている文字を羅列しただけで、まるで暗号文のようです。これでは全く理解できません。
試行2-3(学習量増加)
1stepでは精度が低かったため学習量を増やします。
- 学習成果(59step)
精度が14%まで向上しました。

- 文章生成
今度は、文字の羅列というよりは、読点やかぎかっこが増え、頑張って会話を生成しようとしている感じが伝わってきます。

このあと、768stepまで学習して精度は28%まで上昇しましたが、生成された文は59stepの時とそれほど変わりませんでした。
学習データに使った「新書太閤記」は、会話文も多く存在するため、学習するのが難しいのかもしれません。
「アつッ。アつ、つ、つ」
「船火事っ」
「消せ。はやく、ふみ消せ」
「かた寄るな。船が、沈むぞ」
次は学習データを変更してみます。
試行3「坊っちゃん」
試行3-1(冒頭二行のみ学習)
学習データを夏目漱石の「坊っちゃん」に変更します。
少なくとも「新書太閤記」よりは、現在の文体で表現されていますので、生成される文章が改善されるのではないかという期待があります。
まずは、自分で期待した通りの結果になるか、冒頭の二行だけを学習してみます。
親譲りの無鉄砲で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰を抜かした事がある。なぜそんな無闇をしたと聞く人があるかも知れぬ。別段深い理由でもない。新築の二階から首を出していたら、同級生の一人が冗談に、いくら威張っても、そこから飛び降りる事は出来まい。弱虫やーい。と囃したからである。小使に負ぶさって帰って来た時、おやじが大きな眼をして二階ぐらいから飛び降りて腰を抜かす奴があるかと云ったから、この次は抜かさずに飛んで見せますと答えた。
親類のものから西洋製のナイフを貰って奇麗な刃を日に翳して、友達に見せていたら、一人が光る事は光るが切れそうもないと云った。切れぬ事があるか、何でも切ってみせると受け合った。そんなら君の指を切ってみろと注文したから、何だ指ぐらいこの通りだと右の手の親指の甲をはすに切り込んだ。幸ナイフが小さいのと、親指の骨が堅かったので、今だに親指は手に付いている。しかし創痕は死ぬまで消えぬ。
- 文章生成
「坊っちゃん」の冒頭「親譲り」に続く文章を自動生成させてみます。
 どこをどう学習すれば「**親譲りし的な西放送**」が生み出されるのか分かりませんが、漢字・ひらがな・カタカナが羅列されているだけで、正しい日本語にはほど遠いです。
どこをどう学習すれば「**親譲りし的な西放送**」が生み出されるのか分かりませんが、漢字・ひらがな・カタカナが羅列されているだけで、正しい日本語にはほど遠いです。
また、読点が全くないのも問題です。読点がないと、読み手はどこまで読み進めてから理解すれば良いのか分からず、自分で意味の区切りを推測しながら読む必要があり、余計に疲れます。例えるなら、坊っちゃんを息継ぎせずに読み進めるようなものです。
試行3-2(全行学習)
さすがに二行だけでは、学習データ量が少なかったのかと思い直し、「坊っちゃん」全体を学習させることにします。さらに、学習量も一晩寝かせて4000stepまで増やします。
-
学習成果(4000step)
4000stepまで学習すると精度43%まで上昇しました。(1300step時点で同程度まで達成していました。)

-
文章生成
 今度の文章は、先ほどの「羅列」よりは日本語らしいです。読点を巧みに使い、「**おやが小山**」などとダジャレのような表現まで飛び出すありようです。もしかすると、卓越された高度な日本語なのかもしれませんが、残念ながら私には理解できません。
今度の文章は、先ほどの「羅列」よりは日本語らしいです。読点を巧みに使い、「**おやが小山**」などとダジャレのような表現まで飛び出すありようです。もしかすると、卓越された高度な日本語なのかもしれませんが、残念ながら私には理解できません。
「新書太閤記」を使った時も同じでしたが、学習量を増やして初めて読点を習得できます。
(このような特徴はReformerに限ったものではないと思います。)
読点を習得できたのは良かったですが、日本語らしいかどうかの評価は、文章全体に対して行う必要があります。しかし、文章が改善したのか改悪したのか、何を基準に評価すれば良いかよく分かりません。そのため、「坊っちゃん」全行学習のまま進めて良いかどうか判断できません。
試行3-3(冒頭一文のみ学習)
ひとつの傾向として、学習文を減らすと精度が上がりやすかったことから、極端に学習文を減らしてみます。
こういった検証を行うときは、まずは広く浅く試すことが効率化のポイントです。暗黒の中を手探り状態で出口を探している訳でですから、わずかでも光が見えそうであればそのまま進んで良いですし、暗闇のままであれば方向を変えれば良いのです。
坊ちゃんを冒頭の一文だけにして学習します。
親譲りの無鉄砲で小供の時から損ばかりしている。
- 学習成果(600step)
600step学習させると、精度50%まで上昇しました。(80stepで既に50%になっていました。)

- 文章生成
文章を生成すると「している。」が連発されます。
 学習文の真ん中の「無鉄砲で小供の時から損ばかり」がほとんど出力されません。細かく見ると、生成文「**親譲りので**」は、学習文「**親譲りの**無鉄砲**で**」から「無鉄砲」を取り除いた状態とも見て取れます。
学習文の真ん中の「無鉄砲で小供の時から損ばかり」がほとんど出力されません。細かく見ると、生成文「**親譲りので**」は、学習文「**親譲りの**無鉄砲**で**」から「無鉄砲」を取り除いた状態とも見て取れます。
この状態になる理由は一文だけを学習し過ぎているせいでしょう。あえて例えるなら、親しい人同士が
「今日はやっておいたよ。」
「ありがとう。代わりに進めておくね。」
のように長年の積み重ねによって、一部を省略しても会話が成立するような状態です。
結局、学習データを減らしすぎても良い訳ではありません。気づいた点は、試行3-1の文章生成で出力された「西放送」という単語が学習データには存在しない点です。存在しないにもかかわらず出力されたのは、使用させていただいたwiki.modelに「西放送」が含まれていて、「親譲りし的な」の次に続くキーワードとして「西放送」の確率が高いとwiki.modelが記憶しているからです。つまり、生成される文章は、学習データだけでなくトークナイズモデルにも大きく影響を受けていそうです。
試行4「Wikipedia」
トークナイズモデルと学習データを合わせます。学習データの方をWikipedia(日本語)に合わせます。
ところが、Wikipediaに変更した途端、GoogleColabのリソース問題に直面することになります。
これまでの「坊ちゃん」はせいぜい300KBのファイルサイズですが、Wikipediaでは数GBにもなります。GoogleColabでは、リソース不足によりこの10分の1すらも学習できませんでしたので、行数を大きく減らします。
試行4-1(1stepのみ学習)
Wikipedia(概要)の先頭1万行だけを学習させます。
- 文章生成1(1stepのみ学習)
「オートバイとは、」に続く文を生成します。
気のせいか「車」の単語が多いような気がします。

- 文章生成2
この試行では学習データは「坊ちゃん」ではありませんが、「親譲り」も試してみます。
 ここでも「**14日されネ放送**」「**親譲り放送**」「**親譲りしているチ行放送**」と、バラエティに富んだ怪しい放送が出力されているので、「親譲り」と「放送」は、切っても切れない関係にあるようです。
ここでも「**14日されネ放送**」「**親譲り放送**」「**親譲りしているチ行放送**」と、バラエティに富んだ怪しい放送が出力されているので、「親譲り」と「放送」は、切っても切れない関係にあるようです。
試行4-2(学習量増加)
このまま学習量を増やします。
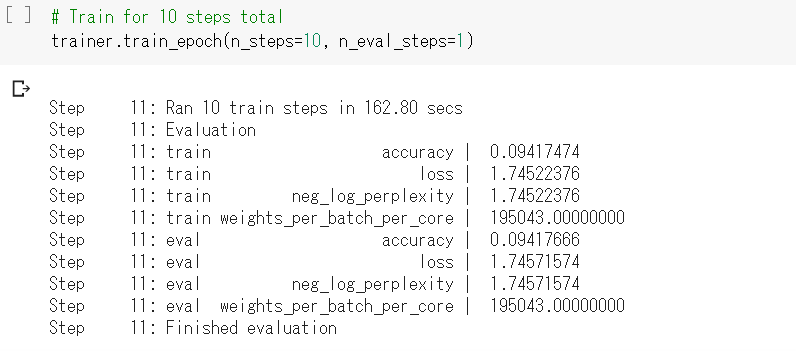
- 学習成果(11step)
順調に学習していそうです。
- 文章生成1
「オートバイとは、」に続く文を生成します。
何故か「⁇」が多く出力されます。
 - 文章生成2
「親譲り」も同様に「⁇」が多いです。
- 文章生成2
「親譲り」も同様に「⁇」が多いです。

このまま、3500stepまで学習すると精度44%まで上昇して学習は非常に順調でしたが、文章生成すると、やはり「⁇」が多く出力されました。「新書太閤記」をの時も「⁇」は少しだけ出力されていましたが、さすがにここまで多いと文章として読めませんので対策が必要です。
試行5「Sentencepieceモデル自作」
「??」が出力されるのは、学習データに認識できない文字があるからだと思っていましたが、実はSentencepiece側の問題です。Sentencepieceのソースを見ると以下の説明があります。
UNK id is decoded into U+2047 (⁇) by default. We can change UNK surface with --unk_surface=<STR> flag.
つまり、Sentencepieceモデルに存在しないワードの場合は「⁇」を出力する仕様ということです。
Sentencepieceは、サブワード単位に学習しているため未知語を少なくできるのが特長ですが、ある程度は学習データとSentencepieceモデルのデータ範囲を合わせておくべきです。今回は、公開されているwikipediaモデルを使用させていただきましたが、私が学習させたwikipediaとは対象範囲が異なっていた可能性があります。
手間を省いて進めてきましたが、やはりそう簡単にはうまくいきません。時間をかけて粘り強く試行錯誤を繰り返すことが、結果的に最短ルートになることもあります。特に、新しい技術を取り扱う時はその傾向が強いです。
Sentencepieceモデルを自作します。(詳細は省略します。)
試行5-1
トークナイザを自作したSentencepieceモデルに変更した上で、もう一度、Wikipedia(概要)の先頭1万行だけを学習させます。
- 学習成果(600step)

- 学習成果(2600step)
 このあと3000stepまで学習させましたが、精度は向上しませんでした。
このあと3000stepまで学習させましたが、精度は向上しませんでした。
- 文章生成1
「オートバイ」に続く文を生成してみると、「⁇」が消えているのが分かります。

- 文章生成2
「親譲り」の方も無事に「⁇」が消えています。
 まだ正しい日本語ではありませんが、これで、ようやくスタートラインに立った感じがします。
改善すべきは、不要な読点や、「この」「など」「ある」のような表現が多過ぎる点です。この辺りを改善して、最低限「主語+述語」の構造は生み出したいです。
まだ正しい日本語ではありませんが、これで、ようやくスタートラインに立った感じがします。
改善すべきは、不要な読点や、「この」「など」「ある」のような表現が多過ぎる点です。この辺りを改善して、最低限「主語+述語」の構造は生み出したいです。
最近の自然言語の学習では、手軽に大量のデータを利用できるという点で真っ先にWikipediaを思い浮かべます。今回の試行でも使用していますが、果たしてWikipediaが万能かというと必ずしもそうではありません。Wikipedia全体を使用すると、自分が制御できる範囲を超えていることも多く、「何故そのような結果になったのか」を検討する際に判断を誤る恐れがあります。
このため、特に新しい技術を試すようなミニマム環境においては、自分がコントロールできる小さいデータから使用し始める方が良いと思います。
試行6「Wikipedia(映画)」
Wikipediaのデータから「映画」というキーワードを含む行だけを抽出して、データサイズを小さくします。また、GoogleColabのリソース問題もありますので行数を減らします。
試行6-1
- 文章生成1(10step学習)
 さすがに「映画」のみを学習しただけあって「映画」という単語が多く出力されていますが、「映画」を説明するのに「映画」を多用するのは上手ではありません。また、漢字とひらがなの出現数の割合は良い感じがしますが、構文上、単語の並びは正しくありません。
さすがに「映画」のみを学習しただけあって「映画」という単語が多く出力されていますが、「映画」を説明するのに「映画」を多用するのは上手ではありません。また、漢字とひらがなの出現数の割合は良い感じがしますが、構文上、単語の並びは正しくありません。
試行7「Wikipedia(映画):Sentencepieceモデル(映画)」
続けて、Sentencepieceモデルも学習データに合わせて「映画」から取得するようにします。
本来、Sentencepieceモデルは出来るだけ大きいデータで学習した方が単語を網羅できますが、今回は、GoogleColab環境のリソースの問題でエラーになってしまう問題もありましたので、こちらも行数を減らします。
試行7-1
- 文章生成1(Sentencepieceモデル:映画)
「映画とは、」に続く文を生成してみます。
 冒頭だけ「??」になってしまいますが、
これまでとは明らかに違って、かなり日本語らしい文章になりました。
手動で入力した「映画とは、」が「??」になってしまう理由は、「映画とは、」がSentencepieceモデルに存在しないためです。手動で与える時も分かち書きにすると解決します。
冒頭だけ「??」になってしまいますが、
これまでとは明らかに違って、かなり日本語らしい文章になりました。
手動で入力した「映画とは、」が「??」になってしまう理由は、「映画とは、」がSentencepieceモデルに存在しないためです。手動で与える時も分かち書きにすると解決します。
試行7-2(Reformerパラメタ微調整)
ここでようやくReformerの出番です。GoogleColab環境のリソース上限のため、学習データサイズやSentencepieceモデルサイズが大きい場合のエラー対策として、Reformerのパラメタも少し変更します。

- 文章生成
「映画 と は 、」と分かち書きで与えて文章生成します。
 だいぶ、日本語になりました。
だいぶ、日本語になりました。
- 学習成果(10step)
さらに学習します。

- 文章生成
 また、ひらがなが多くなってしまいましたが、精度が向上しているため気にせずに学習を続けます。
また、ひらがなが多くなってしまいましたが、精度が向上しているため気にせずに学習を続けます。
- 学習成果(600step)
精度44%まで到達しました。

- 文章生成
これで完成です。
これなら日本語と言っても怒られはしないでしょう。

- 学習成果(4600step)
4600stepまで学習して精度62%まで到達しました。(2500step時点で62%に到達していました。)

- 文章生成
600stepの時の方が自然な文章かもしれません。
細かく読むとまだまだ改善点は、ありますが、当初の目的は達成できましたので、今回の試行はここまでとします。

感想
終わってみると、入力部分を少し変えれば実現できたので、それほど難易度は高くなかったと思います。ただ、個人的に日曜日に2〜3時間くらいしかまとまった時間が取れず、試行結果がNGでやり直しを翌週に持ち越していたので、ものすごく長い期間をかけた感じがします。
ただ、Sentencepieceの処理の速さには助かりました。大量のデータ量を短時間で処理できるのは驚くべきことです。Mecabの分かち書きスピードには昔から驚いていましたが、Sentencepieceにも開発者である工藤さんの思想が組み込まれているのでしょう。
文章の精度に関して、トークナイズモデルをしっかり合わせれば、「新書太閤記」や「坊ちゃん」でもそれなりの文章を生成できたかもしれません。今後の改善点としては、Dropoutなどのハイパーパラメータのチューニング余地は十分に残っていますので、さらなる精度改善も可能かもしれません。
最後に、私が自然言語に興味を持ち始めた2007年頃は、世の中の傾向はどちらかというとクローズドでした。QiitaやGitHubも存在していませんので、何か新しいことを調査する場合、国内で一部の稀有なユーザが公開している情報が頼りでした。しかし、少ない情報からは自分の欲しいノウハウは見つからず、結局は自分で手を動かすことが度々ありました。今思えば、自分で手を動かしたことの方が理解も深く記憶も長く残っています。今回の試行錯誤もそういう意味で試す価値はありました。
最後まで読んでいただきありがとうございました。
参考資料
Googleが公開しているipynbから文章生成のセルが消えていたので、私がforkした時のipynbファイルをご参考にしてください。
以上