Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesisを試してみたのでまとめてみます。tensorflowで実装してみたのでその際に詰まった点なども書いておこうと思います。
名前についてですが、このGANは「LightweightGAN」と呼ばれることが多いと思います。おそらく、公式実装よりも早く公開されたhttps://github.com/lucidrains/lightweight-ganからそう呼ばれているのでしょう。AI-SCHOLARの記事でも「GPU1枚、1日未満で学習!超高速学習GAN、「Lightweight GAN」」のように紹介されています。ですが、後に著者による実装(FastGAN-pytorch)が公開されたのでここでは「FastGAN」と呼ぶことにします。
FastGANについて
モデルの構造について簡単に説明します。ポイントは以下の2つ。内容はほとんど論文の要約+自分の解釈なので、間違っていることがあればご指摘頂きたいと思います。
- SKIP-LAYER CHANNEL-WISE EXCITATION
- SELF-SUPERVISED DISCRIMINATOR
tf.keras.utils.plot_modelで出力した図です。
サイズが大きいので折りたたんであります。
Generatorモデル図
Discriminatorモデル図
SKIP-LAYER CHANNEL-WISE EXCITATION
これはSqueeze-and-Excitation block(SEblock)と似ています。
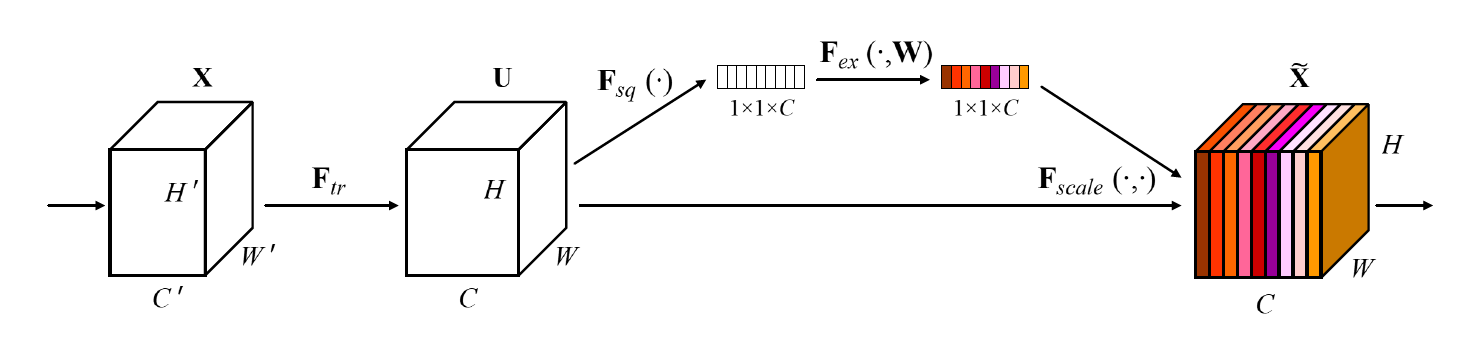
A Squeeze-and-Excitation block. Squeeze-and-Excitation Networksより
SEblockではチャンネルごとに重みづけを行います。これによってAttentionのような効果が期待できるようです。SEblockでは同じfeature mapからweightを求めていますが、SKIP-LAYER CHANNEL-WISE EXCITATIONでは「SKIP-LAYER」とあるように別のfeature mapからweightを求めます。これによってSEblockの効果に加えて、異なる層のskip connectionによって勾配の伝播が効率的に行えるようになることが期待されます。
またstyleGANのようなstyle mixingのような画像生成も可能です。styleGANについては詳しくは書きませんが、解像度ごとにstyleベクトルを作用させて画像生成を行います。その際ある解像度から別のstyleベクトルを使うことで複数の特徴を持った画像を出力させることができるというものです。FastGANではSKIP-LAYER CHANNEL-WISE EXCITATIONにおいて、別の潜在変数から生成したweightを掛け合わせることで同様の画像生成を行えます。これについては後述します。
SELF-SUPERVISED DISCRIMINATOR
こちらはDiscriminator側の工夫で、やっていることはかなりシンプルです。DiscriminatorをAutoEncoderのような構造にし、Discriminatorの中間層の出力から元の画像を復元するDecoderを追加しその復元誤差をDのロスに加えて学習させます。Decoderの構造は以下のようにシンプルなネットワークになっています。
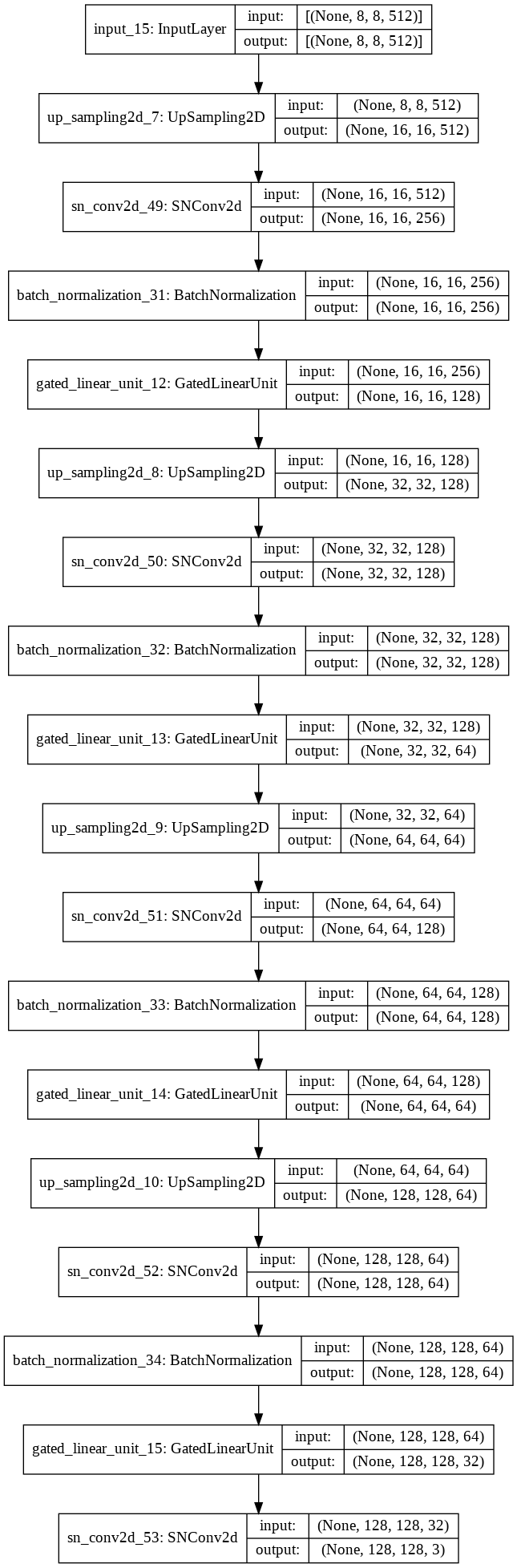
Decoderの出力は128x128で、同じサイズにリサイズした画像と誤差を取ります。Decoderは2つ用いていて1つは8x8のfeature mapから画像全体を復元し、もう1つは16x16のfeature mapを8x8にクロップして復元します。クロップはランダムに行いますが、完全にランダムクロップするのではなくHW方向にそれぞれ2分割した4つの中からランダムにピックアップしてDecoderに通します。それを同じ部分を切り取り・128x128にリサイズした画像と誤差を取ります。
AutoEncoder構造によってDiscriminatorがより包括的(comprehensive)な特徴を抽出するようになります。8x8から画像全体を復元することで全体的な特徴を、クロップして部分的に復元することで局所的な特徴を学習することが期待されます。
実装時の注意点
実装時にハマった点や、著者実装と論文との差異・(私が読んだ限り)論文に明記されていない点などを書いていきます。
Spectral Normalization
論文中には明記されていなかったと思いますが、すべての畳み込み層にSpectral Normalizationを用いています。Spectral NormalizationはGANの正規化の手法でGANの安定化にかなり有効だと言われています。私は数学的な理論や背景を詳しく理解しているわけではないので解説はできませんが、解説記事などもあるので詳しく知りたい方はそちらや元論文を参照してください。Tensorflow+kerasで実装する際に一番苦労した点です。当初はtensorflow_addonsのSpectral Normalizationを用いていましたが、学習が全く進まずこの調査にかなりの時間を要しました。
tensorflow_addonsのSpectral Normalizationの問題点
以下、tensorflow_addons 0.13.0-dev時点での内容なのでご注意下さい(開発中のバージョンですが、ソースコードを読む限り2021/4/15時点では修正されていないようです)githubのissuesで指摘されているので近いうちに修正されるかもしれません。
問題点は以下の2つです。
- power iterationの実装
- wのassign
以下はtensorflow_addonsの実装の一部です。
@tf.function
def normalize_weights(self):
"""Generate spectral normalized weights.
This method will update the value of `self.w` with the
spectral normalized value, so that the layer is ready for `call()`.
"""
w = tf.reshape(self.w, [-1, self.w_shape[-1]])
u = self.u
with tf.name_scope("spectral_normalize"):
for _ in range(self.power_iterations):
v = tf.math.l2_normalize(tf.matmul(u, w, transpose_b=True))
u = tf.math.l2_normalize(tf.matmul(v, w))
sigma = tf.matmul(tf.matmul(v, w), u, transpose_b=True)
self.w.assign(self.w / sigma)
self.u.assign(u)
まず1つ目の問題点ですが、
v = tf.math.l2_normalize(tf.matmul(u, w, transpose_b=True))
u = tf.math.l2_normalize(tf.matmul(v, w))
の部分です。wは正規化の対象となる畳み込み層や全結合層のweightです。この計算自体に問題はありませんが、計算にwを用いているため勾配を逆伝播させる際にpower iterationを通して伝播してしまいます。この計算はSpectral Normを求める(近似する)ためのものでこれを通してbackpropagationされてしまうと学習がおかしくなります。なのでtf.stop_gradientを使って勾配の逆伝播を止める必要があります。
2つ目の問題として、正規化したwを直接assignしている点です。私が間違って理解していたら指摘して欲しいと思いますが、Spectral Normalizationを用いて学習させる際は順伝播には正規化されたweightを使います。正規化はpower iterationによって定数(Spectral Norm)を求めて定数倍することです。backpropagationの際は、順伝播時に用いた正規化されたweightを通して正規化前の元々のweightに対して勾配を求めてweightの更新を行うものと理解しています。なので、正規化されたweightを直接assignしてしまうと学習に問題が起こると思われます。
これらを踏まえて修正したコードが以下になります。計算上の問題はクリアされていると思いますが、かなり使い勝手が悪いので要改善です。
Spectral Normalization Convolution, transposed Convolution
class SNConv2d(tf.keras.layers.Conv2D):
def __init__(self,
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
power_iterations=1,
**kwargs):
super(SNConv2d, self).__init__(
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
data_format=data_format,
dilation_rate=dilation_rate,
groups=groups,
activation=activation,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
activity_regularizer=activity_regularizer,
kernel_constraint=kernel_constraint,
bias_constraint=bias_constraint,
**kwargs)
self.power_iterations = power_iterations
self._kernel = None
self.sigma = tf.constant(1.0, tf.float32)
@property
def kernel(self):
return self._kernel / self.sigma
@kernel.setter
def kernel(self, val):
self._kernel = val
def build(self, input_shape):
super().build(input_shape)
self.w_shape = self._kernel.shape.as_list()
self.u = self.add_weight(
shape=(1, self.w_shape[-1]),
initializer=tf.initializers.TruncatedNormal(stddev=0.02),
trainable=False,
name="sn_u",
dtype=self._kernel.dtype,
)
def call(self, inputs, training=None):
if training is None:
training = tf.keras.backend.learning_phase()
if training:
self.sigma = self.normalize_weights()
output = super().call(inputs)
return output
# @tf.function
def normalize_weights(self):
w = tf.reshape(self._kernel, [-1, self.w_shape[-1]])
u = self.u
with tf.name_scope("spectral_normalize"):
for _ in range(self.power_iterations):
v = tf.stop_gradient(tf.math.l2_normalize(tf.matmul(u, w, transpose_b=True)))
u = tf.stop_gradient(tf.math.l2_normalize(tf.matmul(v, w)))
sigma = tf.matmul(tf.matmul(v, w), u, transpose_b=True)
self.u.assign(u)
return tf.squeeze(sigma)
def get_config(self):
config = {"power_iterations": self.power_iterations}
base_config = super().get_config()
return {**base_config, **config}
class SNConv2d_transpose(tf.keras.layers.Conv2DTranspose):
def __init__(self,
filters,
kernel_size,
strides=(1, 1),
padding='valid',
output_padding=None,
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
power_iterations=1,
**kwargs):
super(SNConv2d_transpose, self).__init__(
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
data_format=data_format,
dilation_rate=dilation_rate,
activation=activation,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
activity_regularizer=activity_regularizer,
kernel_constraint=kernel_constraint,
bias_constraint=bias_constraint,
**kwargs)
self.power_iterations = power_iterations
self._kernel = None
self.sigma = tf.constant(1.0, tf.float32)
@property
def kernel(self):
return self._kernel / self.sigma
@kernel.setter
def kernel(self, val):
self._kernel = val
def build(self, input_shape):
super().build(input_shape)
self.w_shape = self._kernel.shape.as_list()
self.u = self.add_weight(
shape=(1, self.w_shape[-2]),
initializer=tf.initializers.TruncatedNormal(stddev=0.02),
trainable=False,
name="sn_u",
dtype=self._kernel.dtype,
)
def call(self, inputs, training=None):
if training is None:
training = tf.keras.backend.learning_phase()
if training:
self.sigma = self.normalize_weights()
output = super().call(inputs)
return output
# @tf.function
def normalize_weights(self):
w = tf.reshape(tf.transpose(self._kernel, [0, 1, 3, 2]), [-1, self.w_shape[-2]])
u = self.u
with tf.name_scope("spectral_normalize"):
for _ in range(self.power_iterations):
v = tf.stop_gradient(tf.math.l2_normalize(tf.matmul(u, w, transpose_b=True)))
u = tf.stop_gradient(tf.math.l2_normalize(tf.matmul(v, w)))
sigma = tf.matmul(tf.matmul(v, w), u, transpose_b=True)
self.u.assign(u)
return tf.squeeze(sigma)
def get_config(self):
config = {"power_iterations": self.power_iterations}
base_config = super().get_config()
return {**base_config, **config}
SKIP-LAYER CHANNEL-WISE EXCITATION in Discriminator
詳細はDiscriminatorのモデル図を見てもらうと分かりますが、DiscriminatorにもSKIP-LAYER CHANNEL-WISE EXCITATIONが用いられていました。
Small Discriminator
Generatorのモデル図の中に128x128x3の出力があります。これは128x128の画像を出力しこちらについてもAdversarial lossを取り学習させています。これも論文中で特に言及されていなかったと思いますが、これはかなり効果的だと思います。一度しか試していませんが、この構造を除いた際に学習がほぼ進みませんでした。なので中間層から低解像の出力をしてそちらも使って学習させることで安定化につながるor学習スピードが上がる効果があると考えられます。
reconstruction loss
Discriminatorのロスとして再構成誤差を使うことは上述しましたが、その誤差を取る際にMAEやMSEではなく、LPIPSを使用しています。LPIPSは2つの画像間の差異を測る指標でalexnetやVGGなどの学習済みモデルの中間層の出力を全結合層に入力して画像間の差のスコアを出力します。LPIPSについてはLPIPSのproject pageに詳しく書かれています。今回はhttps://github.com/richzhang/PerceptualSimilarityで公開されている学習済みモデルを利用しました。
+α
ここからは自分が試すときに追加で試してみた手法についてです。
Small Discriminator
低解像のDiscriminatorを学習させる際にGeneratorの出力を1チャンネルにしてグレースケール画像を出力させるようにしました。この目的としては低解像部分ではテクスチャを、高解像部分では色についての特徴を学習するように役割分担させるためです。以下はanimefaceで学習させた10,000step時点での出力の比較です。
| color | grayscale |
|---|---|
 |
 |
BATCHNORM STATISTICS AND SAMPLING
これはbigGANで使われていた手法で、推論時のbatch normalizationの扱いについてです。この問題点についてbigGANの論文中で次のように指摘されています。(以下は私の要約です。詳細はbigGANの論文を参照してください。)
Batch normalizationは通常、推論時には学習時に保存していた平均・分散の移動平均を用いて正規化を行います。一方、GANにおいては推論時にもbatch内の平均・分散を用いたほうがよいといわれています。しかし、推論時にbatch内の統計量を用いることは生成画像がbatchsizeの影響を受けてしまうことや、生成画像の再現性が失われてしまうという問題があります。
これについてbigGANでは学習後のモデルでbatch内の平均・分散を保存しておき、推論時はその平均を用いて正規化を行っています。
学習結果
最後に学習結果です。絵画のデータセット(著者が公開していたもの)1000枚・oxford flowers Dataset 約8000枚・アニメイラスト 約5000枚で学習させました。それぞれ約50000step学習させました。



おわりに
今回実装するにあたってspectral normalizationでかなり苦労しました。最初は何も考えずにライブラリを使っていましたが、それがどういった実装になっているかまで見ていくことは必要だと思いました。