はじめに:前回のあらすじと、残された課題
前回の記事では、Python経験半年のバックエンドエンジニアである私が、AIエージェント(Gemini/Cursor)とペアプログラミングを行い、数日で**企業向けAIガバナンス基盤「Prism」**を開発した話を書きました。
前回時点で、以下の「守り」の機能は完成していました。
- ✅ ガバナンス: 質問内容に応じたモデル(Pro/Flash)の自動ルーティング
- ✅ マルチモーダル: PDFをアップロードしてその場で解析・比較
- ✅ 監査ログ: 全会話の記録と復元
しかし、実際に使ってみると2つの大きな課題が見えてきました。
- 「その場限り」の知識: ブラウザを閉じるとアップロードしたPDFの内容を忘れてしまう(長期記憶がない)。
- 待ち時間のストレス: 複雑な推論(決算比較など)を行うと、回答が出るまで20秒近く画面が固まる(UXが悪い)。
今回は、これらの課題を解決するために実装した**「ハイブリッドRAG」と「リアルタイム・ストリーミング」**の技術的な裏側を公開します。
🏆 進化した「Prism v1.0」
今回のアップデートにより、Prismは単なるチャットボットから、**「社内知識を蓄積し、即座に引き出せるナレッジ・プラットフォーム」**へと進化しました。
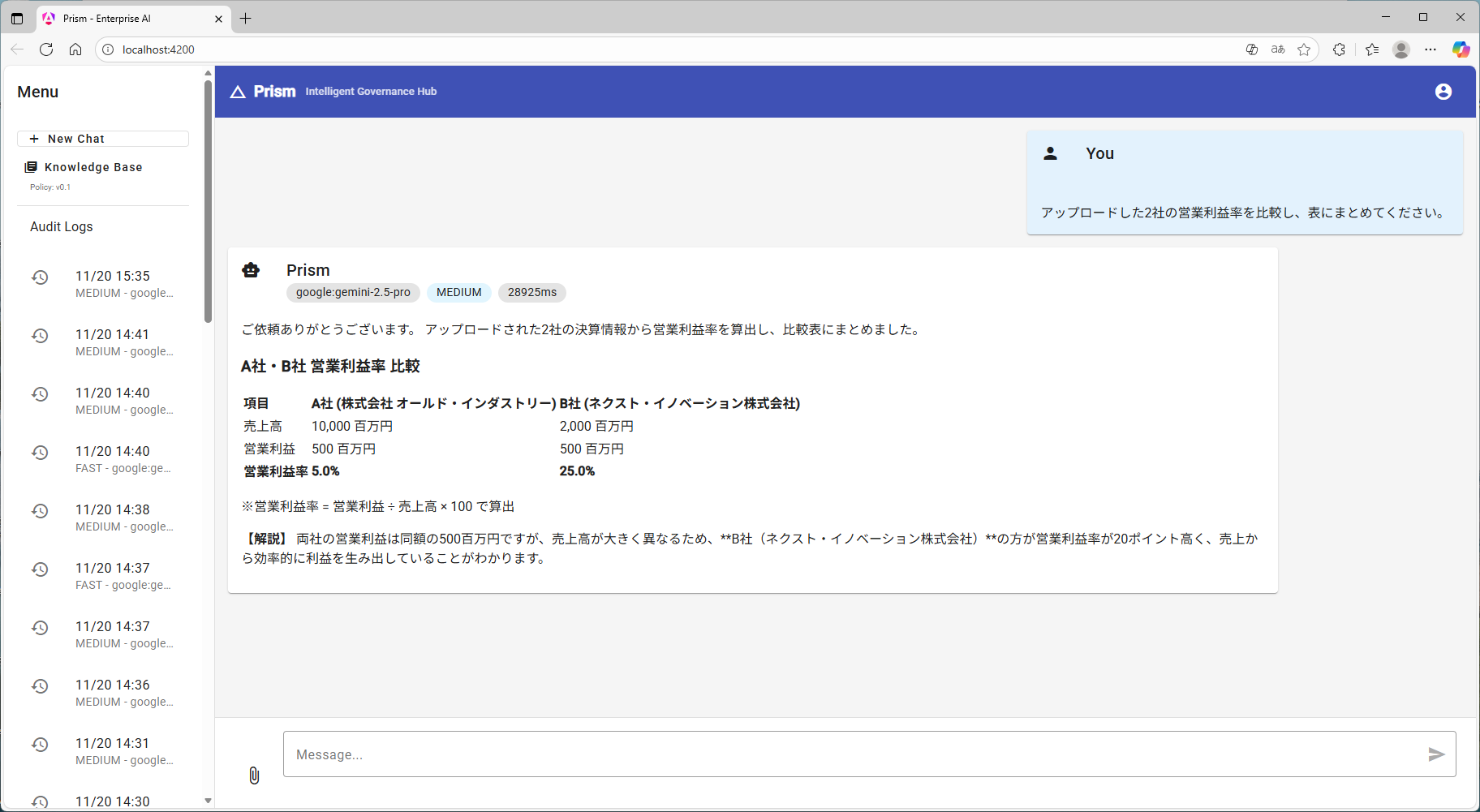
)
▲ Angular Material で構築したUI。回答がストリーミングで表示され、Markdownの表組みも綺麗にレンダリングされています。
追加された新機能
-
🧠 ハイブリッドRAG (検索拡張生成):
- ベクトル検索 (ChromaDB): 「セキュリティの思想は?」といった抽象的な質問に強い。
- キーワード検索 (SQLite): 「エラーコード E-404」といった記号の完全一致に強い。
- これらを組み合わせることで、「意味」と「記号」の両方を正確に検索できるようになりました。
-
⚡️ リアルタイム・ストリーミング:
- NDJSON (Newline Delimited JSON) を採用し、AIの思考プロセスをリアルタイムで画面に表示。「待ち時間ゼロ」の体感速度を実現しました。
-
📚 ナレッジベース管理画面:
- 社内規定やマニュアルをドラッグ&ドロップで登録し、管理する専用UIを実装しました。
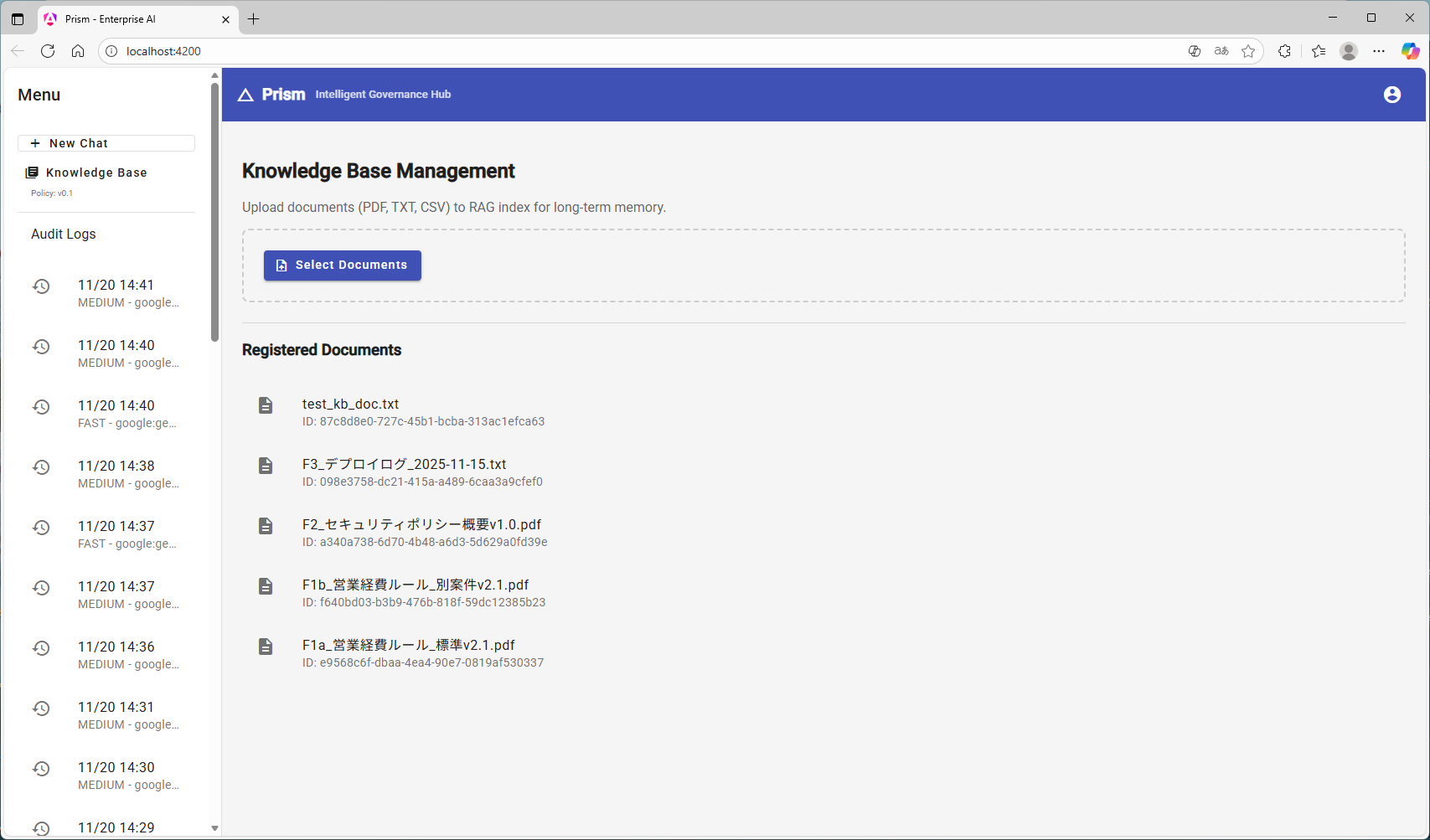
)
▲ サイドバーから切り替え可能な管理画面。ここで登録したPDFは永続的にAIの知識となります。
🔧 技術的な実装ポイント
1. 「意味」と「記号」を逃さないハイブリッド検索の実装
RAGの実装において、単なるベクトル検索(Embedding)だけでは、「品番(PROJ-A77)」のような特定の記号検索に弱いという課題がありました。
そこで、軽量な構成でハイブリッド検索を実現するアーキテクチャを採用しました。
-
Vector Store:
ChromaDB(OSS版) を採用。サーバーレスでPythonコード内に組み込めるため、手軽に導入可能。 -
Keyword Store: 既存の
SQLiteを活用し、簡易的な全文検索を実装。
# backend/rag_kernel.py (イメージ)
class HybridRetriever:
def search(self, query):
# 1. 意味で検索 (Vector / ChromaDB)
vector_results = self.vector_store.search(query)
# 2. キーワードで検索 (Keyword / SQLite)
keyword_results = self.keyword_store.search(query)
# 3. 結果を統合 (Rerank / Merge)
return self.merge_results(vector_results, keyword_results)
2. UXを劇的に改善するストリーミング (NDJSON)
Gemini ProによるRAG検索と推論は、処理に時間がかかります(長いときは20秒〜)。
その間、ユーザーを待たせないために、NDJSON を用いたストリーミング応答を実装しました。
Backend (FastAPI):
yield を使った非同期ジェネレータで、処理状況(ステータス)と回答(チャンク)を順次送信します。
# backend/main.py (非同期ジェネレータ)
async def chat_stream():
# 1. まず「検索中」と伝える
yield json.dumps({"type": "status", "content": "🔍 Searching Knowledge Base..."}) + "\n"
# 2. RAG検索 (非同期実行でブロック回避)
context = await run_in_threadpool(retriever.search, query)
# 3. 生成された文字を逐次送信
async for chunk in llm.generate_stream(prompt, context):
yield json.dumps({"type": "chunk", "content": chunk.text}) + "\n"
Frontend (Angular):
Angular標準の HttpClient はストリームの途中経過を取得できないため、ネイティブの fetch API を使用して実装しました。
// frontend/src/app/chat.service.ts
async sendMessageStream(message: string): Promise<void> {
const response = await fetch('/api/chat', { ... });
const reader = response.body!.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 受信したJSON行をパースして画面に反映
this.updateChatUI(new TextDecoder().decode(value));
}
}
これにより、検索中は「🔍 Searching...」とステータスを表示し、回答生成が始まると文字がパラパラと流れる**「ChatGPTのようなUX」**を実現しました。
🚀 実際の挙動(デモ)
シナリオ:ログ解析と経費ルールの特定
- 「デプロイログ.txt」と「経費規定.pdf」をナレッジベースに登録。
- 「11月15日のエラーの原因と、そのプロジェクトの経費上限を教えて」 と複合的な指示を出す。
結果:
Prismはハイブリッド検索でログからエラー原因(ユーザー名)を特定し、同時に規定から金額(5000円)を抽出。
それらを組み合わせて、Gemini 2.5 Pro が論理的な回答を生成しました。
🏁 まとめ
今回の開発を通じて、Prismは単なるツールから**「業務に組み込めるプラットフォーム」**へと進化しました。
- 技術力: FastAPIの非同期処理、Angularのストリーム処理、ChromaDBの統合など、モダンな技術スタックを実践で習得できました。
- 設計力: 「ガバナンス」と「利便性」を両立させるアーキテクチャを設計し、実装まで落とし込む経験ができました。
公開リポジトリ
コードはGitHubで公開しています。
GitHub: KanadeYumesaki/prism-enterprise-ai