Intro
Twitterでこんなツイートが流れてきた。
都道府県Tier表
— 颯は新B1を救う (@Ryoutahasehase) March 14, 2024
Tier 0 東京
Tier 1大阪 京都 神奈川
Tier 2愛知 福岡 北海道 千葉 埼玉 兵庫 広島
Tier 3宮城 静岡 奈良 熊本 長崎
Tier 4 秋田 福島 新潟 長野 岐阜 富山 石川 山梨 茨城 三重 山口 岡山 高知 愛媛 香川 鹿児島 沖縄
こういうランキング形式は個人的には面白いが、少々疑問の残るランキング付けと感じた。
特に群馬がTier6なのは嘘で、実際に住んでいるがそんなにクソ田舎だとは思わない1 2。
まあこういうのはどのように算出しても賛否両論ではあるかと思うが3、ちゃんとしたデータを元にランク付けをしてみたい。
TL;DR

仮説
各市町村ごとに 地価 * 住民数 を計算し、その値が高いところ=高Tierと予測する。
住民が多いというのは様々な要因があるが、究極的には便利だからと考えられる。
また、地価が高いというのも同様に、便利だからという要素が大きい。
地価が高いと住みにくいため普通は住民が減るはずだが、それを差し置いても人が多い → 相当便利だ、と言えそうである。
データ準備
住民数データは「住民基本台帳に基づく人口、人口動態及び世帯数調査」の令和5年度データを使った。
https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200241&tstat=000001039591&cycle=7&tclass1=000001039601&tclass2val=0
また、地価データは「地価公示データ」の令和5年度データを使用した。
http://www.tikara.jp/72.html
それぞれ特に登録せずにダウンロードできるので、使用させていただく。
データ加工
pip install polars[all] openpyxl
して、さくっと結合する。
住民数データ
割と素直なデータではあるが
北海道 -
(北海道全体のデータと、北海道内の各市区町村のデータと両方がある)
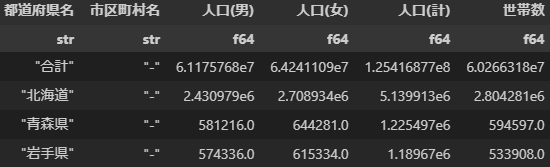
とか
群馬県 佐波郡
(佐波郡は玉村町のみからなるが、ご丁寧に両方とも登録されている)
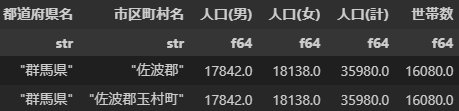
などがあり、ここらへんをどかす必要がある。
これについては市区町村を抽出するための正規表現を使用し、こういったデータについてはあらかじめ除外した。
なお、この正規表現はこのあとの地価データについても使用する。
また、さらに厄介なのが政令指定都市で
札幌市
札幌市中央区
は重複している上に簡単には取り除けない。
これについては、今回は力技で除去した。
import pandas as pd
import polars as pl
# 市区町村抽出の正規表現
# from https://qiita.com/zakuroishikuro/items/066421bce820e3c73ce9
EXTRACT_REG=r"(...??[都道府県])((?:旭川|伊達|石狩|盛岡|奥州|田村|南相馬|那須塩原|東村山|武蔵村山|羽村|十日町|上越|富山|野々市|大町|蒲郡|四日市|姫路|大和郡山|廿日市|下松|岩国|田川|大村)市|.+?郡(?:玉村|大町|.+?)[町村]|.+?市.+?区|.+?[市区町村])(.*)"
# 独特なExcelなので、頑張って読み込む。
jinko_df = (
pl.from_dataframe(
pd.read_excel(
"2303ssjin.xlsx",
usecols="A:G", skiprows=5,
names=[
"団体コード", "都道府県名", "市区町村名", "人口(男)", "人口(女)", "人口(計)", "世帯数"
]
)
)
.with_columns([
# 正規表現から市町村列を追加する (地価データを結合する用)
(pl.col("都道府県名") + pl.col("市区町村名"))
.str.extract(EXTRACT_REG, 2)
.alias("市区町村"),
])
.filter(
# 人口が0の場所を除く(北方領土とか)
pl.col("人口(計)") > 0
)
.filter(
# 市町村がうまく拾えないレコード(例: 県全体・◯◯郡 など)を除く
pl.col("市区町村").is_not_null()
)
.filter([
# 政令指定都市は区単位と市単位両方あって二重にカウントしてしまうので、力技で抜く
~pl.col("市区町村").str.contains(
"(静岡市|神戸市|広島市|千葉市|熊本市|名古屋市|新潟市|横浜市|京都市|岡山市|大阪市|堺市|福岡市|北九州市|川崎市|相模原市|浜松市|さいたま市|札幌市|仙台市)$",
)
])
.select([
"都道府県名", "市区町村", "人口(計)"
])
)
地価データ
地価データには「住所」と「地価の推移」が記載されている。
今回は市区町村単位で分かればよかったので、正規表現で市区町村を抽出している。
また、地価推移もだいぶ変な入れ方をしてあるので、最新データを抜き取る。
# 変わったcsvなので、頑張って加工する
chika_df = (
pl.from_dataframe(
pd.read_csv("chika.csv",encoding="cp932")
)
.rename({
"住所(住居表示・所在地番)":"住所",
"〒R4←R3←R2":"地価推移"
})
.select([
"住所", "地価推移"
])
.with_columns([
pl.col("住所")
.str.extract(EXTRACT_REG, 1)
.alias("都道府県名"),
pl.col("住所")
.str.replace(" ", "")
.str.extract(EXTRACT_REG, 2)
.alias("市区町村"),
pl.col("地価推移")
# 変な保持方法なので、正規表現で抜き取る
.str.extract(r"R4=(\d*\.?\d+\.?)", 1)
.cast(pl.Float32)
.alias("最新地価"),
])
.select([
"都道府県名", "市区町村", "住所", "最新地価"
])
)
結合
この記事を書くまで知らなかったのだが、地価データはすべての市区町村に対して開示されているわけではなく、部分的にしかない。また、一つの市区町村に対して複数の地価があることもあり得る。
そこで、該当市区町村の中央値地価を採用し、1件もヒットしない場所については県地価の中央値を採用した。
# 各市町村ごとに、地価の中央値を結合する
df_city = (jinko_df
.join(chika_df, on=["都道府県名", "市区町村"], how="left")
.group_by(["都道府県名", "市区町村"])
.agg([
pl.mean("人口(計)").alias("人口"),
pl.median("最新地価").alias("地価中央値")
])
)
# 各都道府県ごとに、地価の中央値を結合する
df_pref = (jinko_df
.join(chika_df, on=["都道府県名", "市区町村"], how="left")
.group_by(["都道府県名"])
.agg([
pl.sum("人口(計)").alias("人口"),
pl.median("最新地価").alias("地価中央値")
])
)
# 市区町村内に地価データがあればその中央値、なければ県の中央値
df_city_fill = (df_city
.join(df_pref, on="都道府県名", how="left", suffix="_pref")
.with_columns([
pl.col("地価中央値").is_not_null().alias("地価データ有無"),
])
.with_columns([
pl.when(pl.col("地価データ有無"))
.then(pl.col("地価中央値"))
.otherwise(pl.col("地価中央値_pref"))
.alias("地価中央値")
])
)
市区町村単位の「人口*地価」を算出する
単純に掛け算するだけ。そのままだと値が大きすぎたので、適当に100万で割る。
df_city_pr = (df_city_fill
.with_columns([
(pl.col("人口") * pl.col("地価中央値") / 1_000_000).alias("人口地価積"),
])
.sort("人口地価積", descending=True)
)
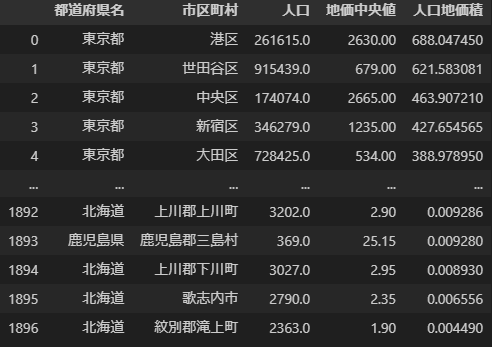
結果はこんな感じ。
港区は住民も多いし地価も高いのですごいことになっている。世田谷区は住民が異常に多い。
県単位で集約する
県で集約するにあたり、どの地点を代表として選ぶかは議論の分かれるところだと思う。
とりあえずいろいろな%地点で出してみる。
df_pref_rank = (df_city_pr
.select([
"都道府県名", "市区町村", "人口地価積", "人口", "地価平均", "地価データ有無"
])
.group_by(["都道府県名"])
.agg([
(pl.sum("人口") / 10_000).alias("人口(万)"),
pl.col("人口地価積").quantile(0.99).alias("人口地価積_99%"),
pl.col("人口地価積").quantile(0.90).alias("人口地価積_90%"),
pl.col("人口地価積").quantile(0.75).alias("人口地価積_75%"),
pl.col("人口地価積").quantile(0.50).alias("人口地価積_50%"),
pl.col("人口地価積").quantile(0.25).alias("人口地価積_25%"),
pl.col("人口地価積").quantile(0.10).alias("人口地価積_10%"),
])
)
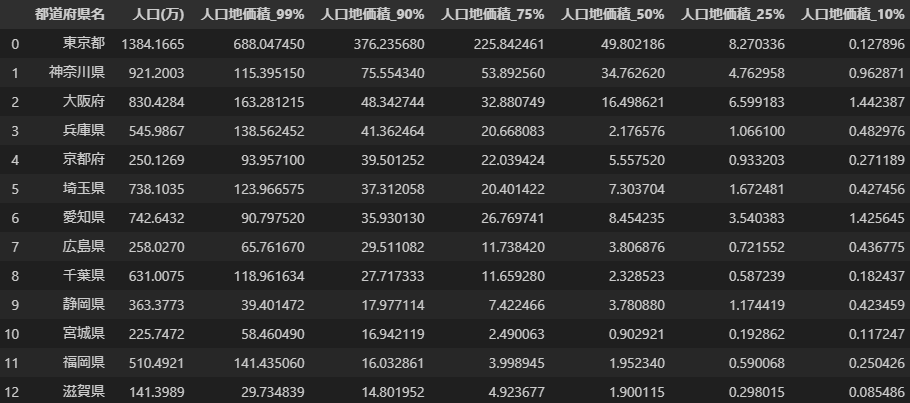
今回は90%値を使用した。
理由としては、大体こういう話はみんな地方都市を元に行うと考えられるため。
なお、ここの選択次第で結果は大きく変わる。
例えば、東京でも10%値を使うと非常にランクは下がる(島嶼は人口が非常に少ないため)
Tier表を作成
最後に、適当にlogをとって値の大小でtier表を作る。
def rank_func(val: float) -> str:
if val > 2.0:
return "#1"
if val > 1.50:
return "#2"
if val > 1.00:
return "#3"
if val > 0.75:
return "#4"
if val > 0.50:
return "#5"
if val > 0.25:
return "#6"
return "#7"
(df_pref_rank
.with_columns([
pl.col("人口地価積_90%").log10().alias("log10"),
pl.col("人口地価積_90%").log10().map_elements(rank_func).alias("Tier")
])
.group_by(["Tier"])
.agg([
pl.col("都道府県名")
])
.select([
"Tier",
pl.col("都道府県名").list.join(separator=", ")
])
.sort("Tier")
.to_pandas()
.to_markdown(index=False)
)
結果
| Tier | 都道府県名 |
|---|---|
| #1 | 東京都 |
| #2 | 神奈川県, 大阪府, 兵庫県, 京都府, 埼玉県, 愛知県 |
| #3 | 広島県, 千葉県, 静岡県, 宮城県, 福岡県, 滋賀県, 岡山県 |
| #4 | 新潟県, 三重県, 群馬県, 山口県, 奈良県, 沖縄県, 愛媛県, 大分県, 富山県 |
| #5 | 熊本県, 長崎県, 島根県, 茨城県, 鳥取県, 石川県, 香川県, 岐阜県, 栃木県, 佐賀県 |
| #6 | 福井県, 山梨県, 宮崎県, 長野県, 岩手県, 山形県, 和歌山県, 鹿児島県, 北海道 |
| #7 | 徳島県, 秋田県, 福島県, 高知県, 青森県 |
感想
Polars最高!
ググっても情報が出てこないこと以外は最高です。みんなも使おう。