はじめに:なぜ「本」をコードにするのか
建築実務において、条文・指針・技術書(数百ページ級のPDF) は仕事の核心です。
しかし、昨今の「RAG(検索拡張生成)」ブームにおいて、これらは単なる「重たいPDF」として扱われがちです。
- PDFのままでは検索が不安定(ページ跨ぎ、段組み、図表の崩れ)
- Web検索では出てこない(専門書のニッチな判定ロジックや係数表)
- 計算に使えない(文字としては読めても、プログラムが変数を代入できない)
そこで私は決意しました。
「都度検索するのではなく、最初に専門書を“AIが読みやすいMarkdown”に全変換してしまえば、そこからツールを自動生成できるのではないか?」
本記事は、200MB超のPDFを画像ベースで分割処理し、PythonとGemini(無料枠)を駆使して完全自動で構造化。そのデータをもとに 「ブラウザで動く構造計算ソフト」 を作り上げるまでの技術記録です。
第1章:まずは成果物を見てほしい
数百ページの専門書(木造許容応力度計算の技術書)をMarkdown化し、その中の「数式」「判定フロー」「係数表」をAIに仕様書として渡して生成させたのが、この 構造計算ツール(MVP) です。
成果物:DXF→許容応力度計算ツール
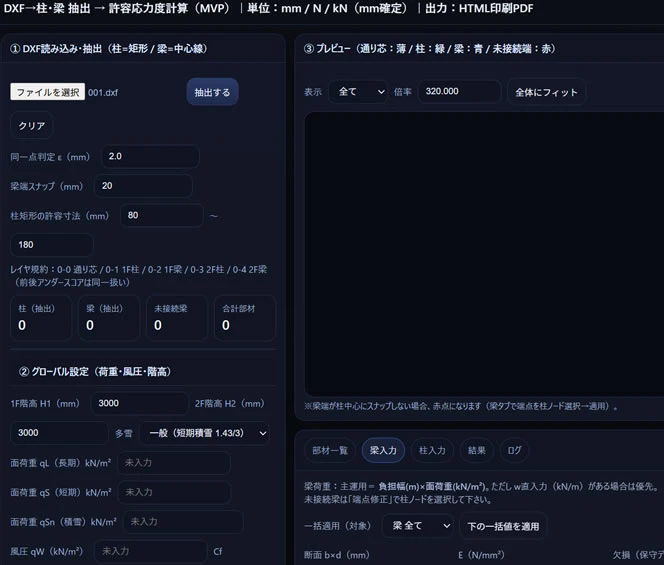
(※イメージ: ブラウザ上でDXF図面を読み込み、自動抽出した柱・梁に対して許容応力度検定を行っている画面)
実装された機能
このツールは、単なる「チャットボット」ではありません。書籍のロジックが 「計算エンジン」 として実装されています。
-
DXF解析エンジン:
- アップロードされたDXF(テキスト形式)をパースし、レイヤごとの線分情報を解析。
- 「柱(閉じた矩形)」と「梁(中心線)」を幾何学的に自動抽出・スナップ処理。
-
部材プロパティの自動推定:
- 書籍の記述に基づき、樹種・強度区分・断面欠損係数などを自動割り当て。
-
リアルタイム検定:
- 長期・短期・積雪・風圧(複合) の全ケースをブラウザ内で計算。
- 判定ロジックは、Markdown化された書籍の数式(例:$ \sigma_c = \frac{N}{A} \le f_c' $ 等)をそのままコードに変換。
「PDFを検索する」のではなく、「PDFをロジック(コード)に変換する」。
これができると、実務のDXは劇的に加速します。
第2章:どうやって「200MBのPDF」をMarkdownにしたか
ここからは、このツールの「原料」となるMarkdownデータを生成するための、Pythonアーキテクチャについて解説します。
課題設定:Gemini無料枠とFiles APIの「50MBの壁」
対象は高密度の専門書(A4版 500ページ超)で、ファイルサイズは200MBを超えます。
Gemini APIの Files API は便利ですが、PDFファイルのアップロード上限は50MBという制約があります(公式ドキュメント参照)。
そのため、200MBのPDFを直接投げることはできません。
そこで、PDFをページごとの画像(JPEG/PNG)に変換し、Visionモデルで1ページずつ「視覚的に」OCR+構造化する アプローチを取りました。
しかし、これを無料枠(Free Tier)で回すには、さらに深い壁があります。
-
API制限の壁: RPM(分間リクエスト)、TPM(分間トークン)、RPD(日次リクエスト)の制限ですぐに
429 Resource Exhaustedで止まる。 - 解像度の壁: 複雑なフローチャートや詳細図が、縮小されて「幻覚」を起こす。
- 障害復旧の壁: 500ページの処理中にPCがスリープしたりネットが切れたら、最初からやり直しか?
これらを解決するために実装したのが、以下の 「耐障害(Fault Tolerant)スクリプト」 です。
第3章:技術的Deep Dive(Python実装の要点)
1. 「適応型レートリミッタ」によるAPI制限ハック
無料枠を使い倒すには、「固定で5秒待つ」ような単純な制御では非効率です。また、429エラーはRPMだけでなく、TPM(トークン過多)でも発生します。
そこで、TCPの輻輳制御(Congestion Control)に似たアルゴリズムを実装し、「怒られるギリギリまで攻める」 挙動を実現しました。
- Success Decay: 成功が続けば、待機時間を徐々に短縮(×0.97)して攻める。
- Throttle Grow: 429エラーが返ってきたら、待機時間を指数関数的(Exponential Backoff)に増加(×1.7)させて退避する。
import time
from google.genai import errors # 最新SDKの場合
class AdaptiveRateLimiter:
"""
APIの機嫌(サーバー負荷・RPM/TPM残量)に合わせて、待機時間を動的に伸縮させる
"""
def __init__(self, init_rpm=10):
self.interval = 60.0 / init_rpm
self.min_interval = 2.0 # 安全マージン
self.max_interval = 60.0 # 退避上限
def on_success(self):
# 成功したら間隔を少し詰める(攻める)
self.interval = max(self.min_interval, self.interval * 0.97)
def on_throttle(self, error):
# APIから Retry-After ヘッダが返ってくればそれを尊重
# ※SDKの実装により属性名は異なる場合があるため確認推奨
retry_after = getattr(error, 'retry_after', None)
# なければ指数バックオフ
wait = float(retry_after) if retry_after else self.interval * 1.7
self.interval = min(self.max_interval, max(wait, self.interval))
print(f"Throttled. Backing off to {self.interval:.2f}s")
self.force_wait(self.interval)
def force_wait(self, seconds):
time.sleep(seconds)
この実装により、単純な time.sleep と比較して約1.4倍の速度で処理が完了しました。
2. 解像度不足を物理で殴る「Tile Fallback戦略」
Visionモデルは優秀ですが、ページ全体を1枚の画像として投げると、細かい文字や矢印の向きが潰れることがあります。
そこで、「怪しい時は4分割して拡大再撮影」 するロジックを組み込みました。
「完全構造化」の定義と検証
ここで言う「完全構造化」とは以下を指します。
- 見出しレベル(#)が論理構造と一致している
- 数式が $LaTeX$ 形式で記述されている
- 表(Table)が崩れずにMarkdown Tableになっている
- フローチャートが箇条書きの入れ子等で表現されている
処理フロー
- まずはページ全体をGeminiに投げる。
- 出力結果を正規表現で検査。
-
……のような無意味な連続文字(OCR崩れの兆候)がないか? - 「フローチャート」という単語があるのに、矢印
->がない、リスト構造が浅すぎる等はNG。
-
- 疑わしい場合のみ、画像を2×2の4枚にクロップ し、マルチモーダル入力として再送信して統合。
import re
def needs_tile_refine(md: str) -> bool:
"""出力が怪しい(OCR崩れ/図解の認識失敗)かを判定"""
# 1. 意味不明なドット連打を検知
if re.search(r"[・..…⋯•·]{80,}", md): return True
# 2. フローチャート崩れ検知(矢印がない、分岐がない等)
has_flow_keyword = ("フロー" in md) or ("Start" in md)
has_arrow = ("→" in md) or ("->" in md)
if has_flow_keyword and not has_arrow:
return True
return False
# 判定がTrueなら、4枚の画像をGeminiに投げて「統合して」と指示する
3. 「冪等性」を担保したステートフルな保存
500ページの処理には数時間かかります。いつ落ちても良いように、「何度実行しても結果が壊れない(冪等性)」 設計にしました。
単純な追記(append)ではなく、ブロック置換を採用しています。
-
Markdown構造: 各ページを
--- PAGE 123 ---という一意なマーカーで区切る。 - 書き込みロジック: ファイル全体をスキャンし、該当ページがあればRegexで置換、なければ末尾に追加。
def replace_page_block(output_path, page_num, new_block):
"""
既存ファイルの --- PAGE X --- ブロックを探して置換する。
これにより、途中再開時に「ページの重複」や「順序崩れ」を防ぐ。
"""
try:
with open(output_path, "r", encoding="utf-8") as f:
txt = f.read()
except FileNotFoundError:
txt = ""
# 正規表現で該当ページブロックを特定
# re.S (DOTALL) は必須。これがないと改行を含むブロック全体にマッチしない
pattern = re.compile(rf"\n\n--- PAGE {page_num} ---\n\n.*?(?=\n\n--- PAGE \d+ ---\n\n|\Z)", re.S)
if pattern.search(txt):
# 置換(Update)
txt = pattern.sub(new_block.strip("\n"), txt, count=1)
print(f"Page {page_num}: Updated.")
else:
# 追記(Append)
txt += "\n" + new_block
print(f"Page {page_num}: Appended.")
with open(output_path, "w", encoding="utf-8") as f:
f.write(txt)
この設計により、「PCが落ちたら再起動してスクリプトを叩くだけ。続きから自動で走り出す」 というストレスフリーな運用が完成しました。
第4章:運用フロー「フォルダ放り込み」の最強感
技術的に高度なことよりも、「人間が張り付く必要がない」 運用設計が重要です。
- Input: 指定フォルダにPDFを置く(スクリプトが画像化)。
-
Process: スクリプトが起動。
- 完了済みのPDFはスキップ。
- 途中のPDFは
state.jsonを見て続きから再開。 - API制限にかかったら自動で待機。
-
Output: 同フォルダに
_Refined_Export.mdが生成される。
私はこれを、寝る前にセットしています。朝起きると、専門書1冊分の知識がMarkdown化され、AIが活用できる状態になっています。
まとめと注意点
技術スタックまとめ
-
Model: Gemini 2.0 Flash (困ったときは
gemini-1.5-flash-latestも検討) - Language: Python 3.10+
-
Key Libraries:
google-genai,pymupdf(fitz),Pillow - Concepts: Adaptive Rate Limiting, Idempotency, RAG Pre-processing
著作権と利用に関する注意
本記事は「非構造化データ(画像/PDF)を構造化データ(Markdown/コード)へ変換する技術」の検証記録です。
変換対象となる専門書や技術資料の著作権は、各著作者・出版社に帰属します。
- 私的利用・内部利用: 業務効率化のための社内ツール開発や検証は、適切な利用範囲内で行ってください。
- 再配布の禁止: 生成されたMarkdownデータや、それを含んだツールを著作者の許諾なく外部へ公開・販売することは著作権法に抵触する可能性があります。
「知識の採掘(Mining)」技術を正しく使い、エンジニアリングで実務の壁を突破しましょう。
▼ 前回の記事はこちら
【建築士×ChatGPT】「読み方も分からない技術」で、野良DXFを3秒で解析する爆速ツールをHTML1枚で作った話【2025年法改正】