AI時代のテストをどう変えるべきか

〜『AIとソフトウェアテスト』を読み、現場で使える形に落とし込むための考察〜
近ごろ、AIを活用したシステム開発があらゆる領域で当たり前になってきた。そんな中、個人的に強い関心をもって読みふけったのが『AIとソフトウェアテスト』という書籍だ。AIを含むソフトウェアの品質をどう捉えればよいのか、どのように評価すべきなのかについて、非常に丁寧に整理してくれる内容だった。
ただ、読み進めていくと、 問題意識は明確である一方で、「では明日から現場で何をすればいいのか」という点についてはやや抽象度が高いまま終わってしまう印象もあった。 AIのテストは、従来のテスト手法の延長線上では語れない。だからこそ、この書籍をきっかけに、実際の開発現場ではどのような姿勢で品質保証に取り組むべきなのか、改めて考え直す必要があると強く感じた。
この記事では、書籍の要点を整理しつつ、私自身の経験や現場の課題意識も踏まえながら、AI時代のテストをどう再構築していくべきかについて整理していきたい。
本稿はソフトウェアテスト Advent Calendar 2025の3日目の記事となります。
AIは“正解が揺らぐ”世界に生きている

書籍の最初の強調点でもあるが、AIシステムは従来のソフトウェアとは決定的に違う。もっとも特徴的なのは、同じ条件でも毎回同じ答えが返ってくるとは限らないという点だ。AIの判断は確率で揺らぎ、その揺らぎはデータの種類や状況によって大きく変わる。
日常の例で言うと、顔認識アプリが明るい昼間では正確なのに、薄暗い室内では全く違う人として認識されてしまう、といった現象に近い。これは単に “暗かったからミスした” という単純な話ではなく、モデルが学習したデータのバランスや特徴の偏りが根本にある。つまり、AIは常に「揺らぎ」の中で判断を行っており、従来の「仕様書どおりに動くかどうか」を確認するテストの枠組みには収まらない。
この揺らぎをどう扱うかが、AI時代のテストを考える上で最初のハードルになる。
データが品質を決める時代

本書でも繰り返し述べられているが、AI品質の大部分はデータに依存している。プログラムのロジックではなく、モデルがどのようなデータをどのような分布で学習したのかが、後の性能に直結する。
例えば、黒い犬を“猫”と誤認するAIがあったとして、その原因がコードにあるとは限らない。単純に「黒い犬」の写真が学習データに少なかっただけ、あるいは“暗い環境”に関するデータが欠けていたという可能性もある。つまり、コードレビューや仕様確認だけでは捉えられない品質問題が山ほど存在する。
AIを扱う上では、「そのAIがどんな世界を見て育ったのか」を理解することが不可欠であり、データ自体のレビューや検証がこれまで以上に重要になってくる。
バイアスという“品質欠陥”

AIにおけるバイアスは、悪意ではなく“偶然によって”生まれることが多い。学習データの偏り、アルゴリズムの特性、人間の判断などが複雑に絡み合い、本人たちの意図とは無関係に偏った結果が生じてしまう。
採用AIが男性を優先する、といったニュースも一時期話題になったが、あれも“過去のデータ”に偏りがあったからだ。AIは“見たことのある世界”を基準に判断するため、そこに偏りがあれば、自然とその偏りが継承されてしまう。
バイアスはAIにおける重要な品質問題であり、通常の機能テストの範疇には収まらない。テスターは「どう動くべきか」を確認するだけでなく、「どんな偏りがあり得るか」を探る役割も担う必要がある。
AIテストに必要な考え方──“揺らぎの法則”を理解する

従来のテストでは、同じ操作をすれば同じ結果が返る前提があった。しかしAIでは、明るさが変わる、角度が変わる、ノイズが入る、といった入力条件のちょっとした違いが結果に大きく影響する。
画像分類モデルなら、同じ対象の写真でも、傾きや影の入り方で判定が変わることは珍しくない。テキストモデルなら、句読点や表記揺れ、言い換えによって出力が変わることもある。
これらはすべて AI にとっての“揺らぎの法則”であり、この法則を理解しない限り、AIの品質を正しく評価することは難しい。とりわけ QA エンジニアは、AIがどういう条件に弱いのか、どのような変化に反応するのかを深く理解しなければ、バグを発見することすらできない。
テスターに求められる知識の変化
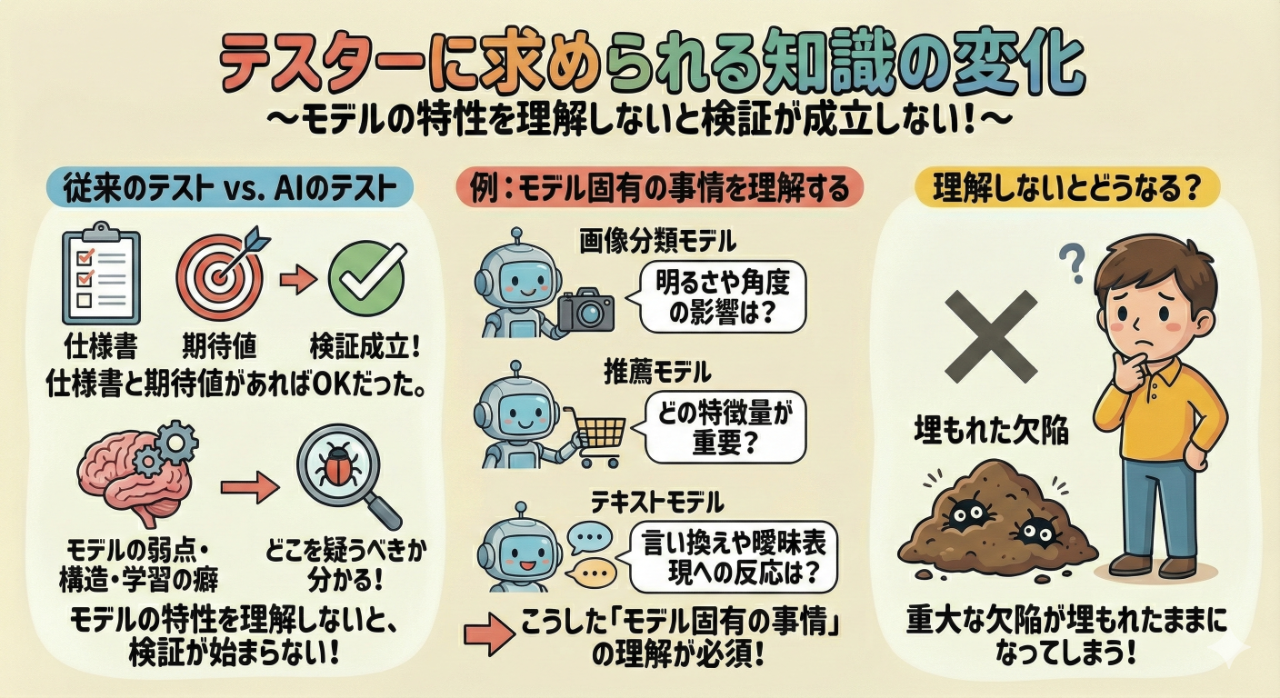
AIテストが難しい理由のひとつに、テスターがモデルの特性を理解していないと検証が成立しないという点がある。
従来のテストでは、仕様書と期待値があれば成立した。しかしAIでは、モデルが持つ弱点やデータの構造、学習の癖を理解しないと、そもそも「どこを疑うべきか」が分からない。
画像分類モデルなら、明るさや角度を変えるとどう影響するのか。
推薦モデルなら、どの特徴量が重要なのか。
テキストモデルなら、言い換えや曖昧表現にどう反応するのか。
こうした“モデル固有の事情”を理解していないと、重大な欠陥が埋もれたままになってしまう。
QAだけではAIテストは成立しない

本書を読みながら何度も感じたのは、「AIテストはQAだけでは完結しない」という事実だ。
データの偏りを分析するにはデータサイエンティストの知識が必要になるし、モデルの構造や弱点を理解するにはモデルの実装者の協力が欠かせない。さらには運用後の性能劣化を検知するためには、SRE などの運用チームとの連携も必要になる。
AIを扱う組織では、QA が中心となりつつも、データサイエンティスト・エンジニア・SRE と協力しながら品質保証を進める“横断的な体制” が求められる。
従来のテストのように「この範囲はQAの担当」という境界が曖昧になり、品質保証が組織全体の共同作業になっていく。AIを利用する企業が増えるほど、この構造を理解しなければ、テストが機能しないまま形骸化する危険性すらある。
では、実際に何をすべきか──AIテストのロードマップ

本書は問題の本質を非常に丁寧に整理してくれる一方で、具体的な手順や実務のアプローチについては深掘りされていない。そこで私自身の経験や現場の実感を踏まえながら、AI時代のテストをどう実行していくべきかを考えてみたい。
まず必要なのは、「データ品質レビュー」を標準プロセスとして組み込むことだ。AIの品質はデータで決まる以上、学習データの偏りや、アノテーションの正確さ、外れ値や欠損値の扱いなど、これまで以上にデータを慎重に扱う必要がある。
また、学習時と本番のデータが大きく異なると、性能が急激に落ちることも珍しくない。そのため、データ分布の変化を定期的に観測する仕組みも欠かせない。
次に重要なのが、“揺らぎを測定するテスト環境”の整備だ。明るさや角度、ノイズの入り方などを人工的に変えながらモデルの反応を観察することで、モデルの弱点が見えてくる。こうした揺らぎへの耐性を評価しない限り、実運用で安定した性能は期待できない。
正解が分からない場合には、“メタモルフィックテスト”という手法が役に立つ。「条件Aから条件Bに変えても、本来なら結果はこう変化するべきだ」という“期待される関係性”を定義しておく方法だ。AIの特性を理解しつつ仕組みを設計するため、ある程度の知識が必要になるが、その分、AI特有の欠陥を発見しやすくなる。
運用が始まれば、Shift-Rightと呼ばれる“運用中の性能監視”が極めて重要になる。AIは環境変化に敏感であり、運用中にデータ分布が変わることで性能が劣化することが多い。定期的にモデルを評価し直したり、異常な振る舞いを検知したりする仕組みが必要だ。ここでは SRE チームや運用エンジニアとの連携が鍵になる。
組織はどう変わるべきか
AIを活用する企業が増える中、品質保証のあり方も大きく変わりつつある。
特に実感しているのは、QA単独ではAIテストを成立させることが難しいという点だ。
正確に言えば、QAだけで頑張るのではなく、
必要な知識を持った専門家(データサイエンティストやエンジニア)を巻き込みながら、
横断的なチームで品質を支えていく姿勢が求められる。
そのためには、QA側にも「巻き込む力」が必要になる。
データの偏りを理解するためにDSを巻き込み、
モデルの意図を理解するためにエンジニアを巻き込み、
運用データの変化を監視するためにSREに協力してもらう。
AIを扱う組織では、このような“協働”こそが品質保証を成功させる鍵になる。
おわりに──AI時代のテストは不確実性との戦いである

『AIとソフトウェアテスト』は、AI時代の品質課題を丁寧に整理した良書だ。
ただし、そのまま現場に適用するには、いくつかの補完が必要になる。
AIのテストは、正解の検証ではなく、不確実性の理解から始まる。
揺らぎを受け入れつつ、その揺らぎがどのような場合にどこまで許容できるのか、
丁寧に見極めていく必要がある。
そして何より、AIの品質保証はひとつの職種に閉じることなく、
組織全体で協力しながら進めるべき領域だ。
品質を支えるためには、職種の境界を越えたコミュニケーションと理解が不可欠になる。
AIが当たり前のように組み込まれる時代において、
私たちは従来の「テスト」の枠を越え、
より広い視野で品質問題に向き合う必要がある。
その第一歩は、AIの揺らぎやバイアスを理解し、
データやモデルの特性を正しく捉えるところから始まる。
品質保証の役割が大きく変わる今こそ、
AI時代のテストのあり方を組織全体で考えていくべき時期に来ているのだ。