はじめに
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
現在、pythonを使ったデータ分析の勉強を始めて3か月がたちました。先月埼玉県の新築マンションを購入したので、将来購入したマンションがどのくらいの価格で売れるのか気になっています。そこで今回、埼玉県の中古マンションの価格予測モデルを作成し、購入した物件の20年後の価格を予測したいと思います!!
環境
Windows 11
python 3.10.12
Google Colaboratory
手順
| 工程 | 内容 | |
|---|---|---|
| 1 | 準備 | 必要なパッケージのインポートなどの準備 |
| 2 | データ収集 | 国土交通省土地総合情報システムからデータを収集 |
| 3 | 前処理 | 読み込めないデータの整形や欠損値、異常値の処理 |
| 4 | データ可視化 | データを可視化し、重要な特徴量を絞り込む |
| 5 | 予測モデル構築 | 線形回帰、リッジ回帰、ラッソ回帰、エラスティックネット回帰、ランダムフォレスト、LightGBMを使って、最も精度が高いモデルを探して予測 |
| 6 | 改善策 | 5で最も精度が高かったモデルの精度を改善(改築有無、最寄り駅の乗降客数、市区町村の人口密度、犯罪率、診療所の数の情報を付与、地理的特徴・路線情報等をOne-hot Encoding )、ディープニューラルネットワークもお試し |
| 7 | 予測 | 一番精度の良いモデルを使って、自身が購入したマンションの20年後の販売価格を予測 |
参考文献
以下のサイトを参考にさせていただきました。ありがとうございました。
【Python】東京23区の中古マンション販売価格予測をやってみた
https://qiita.com/hidemiya666/items/a65d7fed65ff6443947c
Pythonで不動産価格予測解析
https://note.com/maytakesao/n/n126165676d30
1.準備
データクレンジング処理と回帰予測を行いますので、以下パッケージをインポートしました。
一般的な処理用:numpy、pandasなど
可視化用:matplotlib、seabornなど
回帰分析用:LinearRegression、Ridge、Lasso、ElasticNet、RandomForest、LightGBMと全結合のディープラーニングのライブラリなど
# 必要なライブラリのインポート
import os
import re
import numpy as np
import pandas as pd
!pip install japanize-matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import sklearn
from sklearn.model_selection import train_test_split
# 回帰分析用 from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.ensemble import RandomForestRegressor
import lightgbm as lgb
# 全結合ディープラーニング用
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation,Dense,Dropout,Input,BatchNormalization
2.データ収集
2-1 データ収集
国土交通省土地総合情報システム(https://www.land.mlit.go.jp/webland/download.html)から、埼玉県(2005年第3四半期~2023年第3四半期)の18年分のデータを取得しました。
df_data = pd.read_csv(f'/content/11_Saitama Prefecture_20051_20233.csv',encoding="cp932")
2-2 データ項目(特徴量)の理解
Pandasを使用してどのような項目(特徴量)なのか理解します。
# 特徴量を確認
df_data.columns
データは、下記の項目で構成されており、取引価格(総額)が目的変数となり、その他29項目が説明変数の候補(特徴量)となります。
Index(['No', '種類', '地域', '市区町村コード', '都道府県名', '市区町村名', '地区名', '最寄駅:名称','最寄駅:距離(分)', '取引価格(総額)', '坪単価', '間取り', '面積(㎡)', '取引価格(㎡単価)', '土地の形状','間口', '延床面積(㎡)', '建築年', '建物の構造', '用途', '今後の利用目的', '前面道路:方位', '前面道路:種類','前面道路:幅員(m)', '都市計画', '建ぺい率(%)', '容積率(%)', '取引時点', '改装', '取引の事情等'],dtype='object')
# ランダムに1%のデータを抽出し、先頭から10件データを表示
df_data.sample(frac=0.01).head(10)
各特徴量についてuniqueの数と項目を確認します。
print(df_data.nunique())
print(df_data['市区町村名'].unique())
print(df_data['改装'].unique())
print(df_data['種類'].unique())
print(df_data['地域'].unique())
print(df_data['建築年'].unique())
print(df_data['最寄駅:距離(分)'].unique())
print(df_data['最寄駅:名称'].unique())
print(df_data['面積(㎡)'].unique())
各特徴量について欠損値の数を確認します。
df_data.isnull().sum() #各項目に対し、欠損数を確認
3.前処理
3-1 中古マンションのみ抽出
# 中古マンションのみを抽出
df_data2= df_data[df_data['種類'] == '中古マンション等']
df_data2.sample(frac=0.01).head(10)
3-2 読み込めないデータの整形や欠損値、異常値の処理
# 建築年(西暦)が欠損している行を削除
df_data2.dropna(subset=['建築年'], inplace=True)
# 和暦を西暦に変換する
def wareki_to_seireki(wareki):
if pd.isnull(wareki):
return None
if wareki == '戦前':
return 1945
era_year = int(re.sub(r'\D', '', wareki))
if '昭和' in wareki:
return 1925 + era_year
elif '平成' in wareki:
return 1988 + era_year
elif '令和' in wareki:
return 2018 + era_year
else:
return None
# 建築年の列にある和暦を西暦に変換する
df_data2['建築年(西暦)'] = df_data2['建築年'].apply(wareki_to_seireki)
df_data2['建築年(西暦)'].replace('', np.nan, inplace=True)
df_data2['建築年(西暦)'] = df_data2['建築年(西暦)'].astype(float)
df_data2['建築年(西暦)'].info()
# 最寄駅:距離(分)が欠損している行を削除
df_data2.dropna(subset=['最寄駅:距離(分)'], inplace=True)
# 最寄駅:距離(分)を修正
df_data2=df_data2.replace( '30分?60分','30')
df_data2=df_data2.replace( '1H?1H30','60')
df_data2=df_data2.replace( '2H?','120')
df_data2=df_data2.replace( '1H30?2H','90')
df_data2["最寄駅:距離(分)"]=df_data2["最寄駅:距離(分)"].astype(float)
df_data2["最寄駅:距離(分)"].info()
# 面積(㎡)を修正
df_data2=df_data2.replace('2000㎡以上', '2000')
df_data2["面積(㎡)"]=df_data2["面積(㎡)"].astype(float)
df_data2["面積(㎡)"].info()
4.データの可視化
4-1 統計量の確認
#'最寄駅:距離(分)', '取引価格(総額)', '建築年(西暦)','面積(㎡)'の統計量を確認
display(df_data2[['取引価格(総額)','面積(㎡)','建築年(西暦)','最寄駅:距離(分)']].describe())
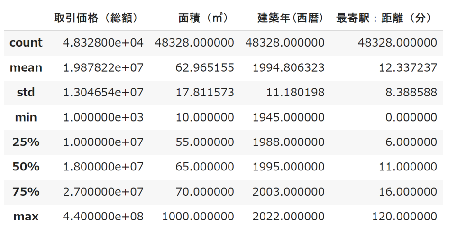
物件数は48,328件、取引価格(総額)は最大4億4,000万、平均1,988万でした。
4-2 グラフによるデータの可視化と外れ値の除去
ヒストグラムで取引価格を可視化
# 取引価格のヒストグラムの表示
sns.displot(df_data2['取引価格(総額)'])
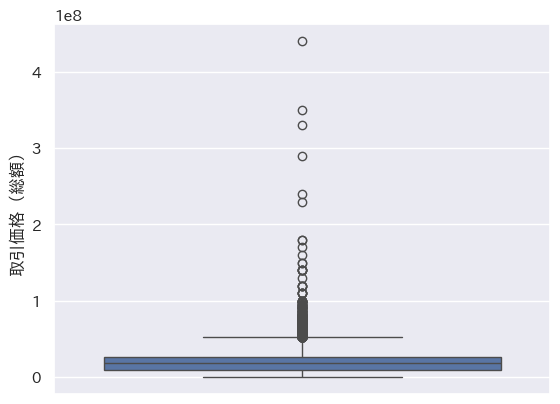
外れ値の確認
#取引価格の外れ値の表示
sns.boxplot(y=df_data2[取引価格(総額)']) #外れ値の確認
# 面積の外れ値の確認
sns.boxplot(y=df_data2['面積(㎡)'])
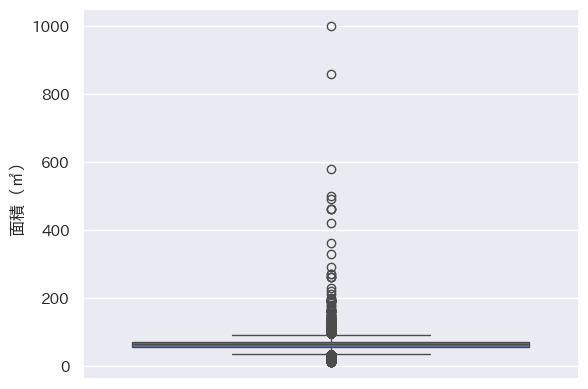
# 建築年(西暦)の外れ値の確認
sns.boxplot(y=df_data2[建築年(西暦)])
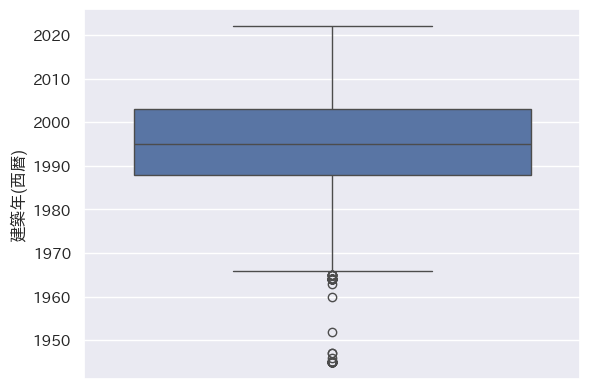
箱ひげ図から取引価格を100-6000万円、面積を100m2未満、築年数(西暦)を1970年より新しい物件のデータを解析対象とし、それ以外の物件のデータを削除することとしました。
# 外れ値の除去
df_data3 = df_data2.loc[df_data2['取引価格(総額)'] < 60000000]
df_data3 = df_data3.loc[df_data3['取引価格(総額)'] > 100]
df_data3 = df_data3.loc[df_data3['面積(㎡)'] < 100]
df_data3 = df_data3.loc[df_data3['建築年(西暦)'] > 1970]
外れ値除去後の統計量を再度確認します。
display(df_data3[['取引価格(総額)','面積(㎡)','建築年(西暦)','最寄駅:距離(分)']].describe())
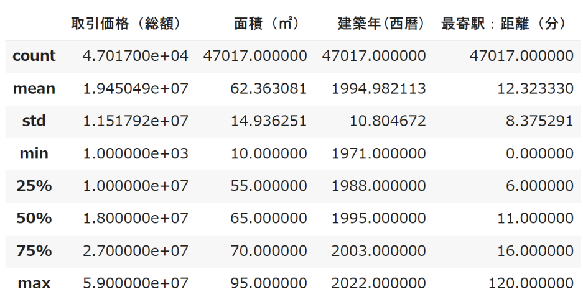
物件数は47,017件、取引価格(総額)は最大5,900万、平均1,945万となりました。
各特徴量の関係性を確認します。
# 散布図で取引価格、面積(㎡)、建築年(西暦)、最寄駅:距離(分)の関係性を確認
cols = ['取引価格(総額)', '面積(㎡)','建築年(西暦)', '最寄駅:距離(分)']
sns.pairplot(df_data3[cols], height = 2.5)
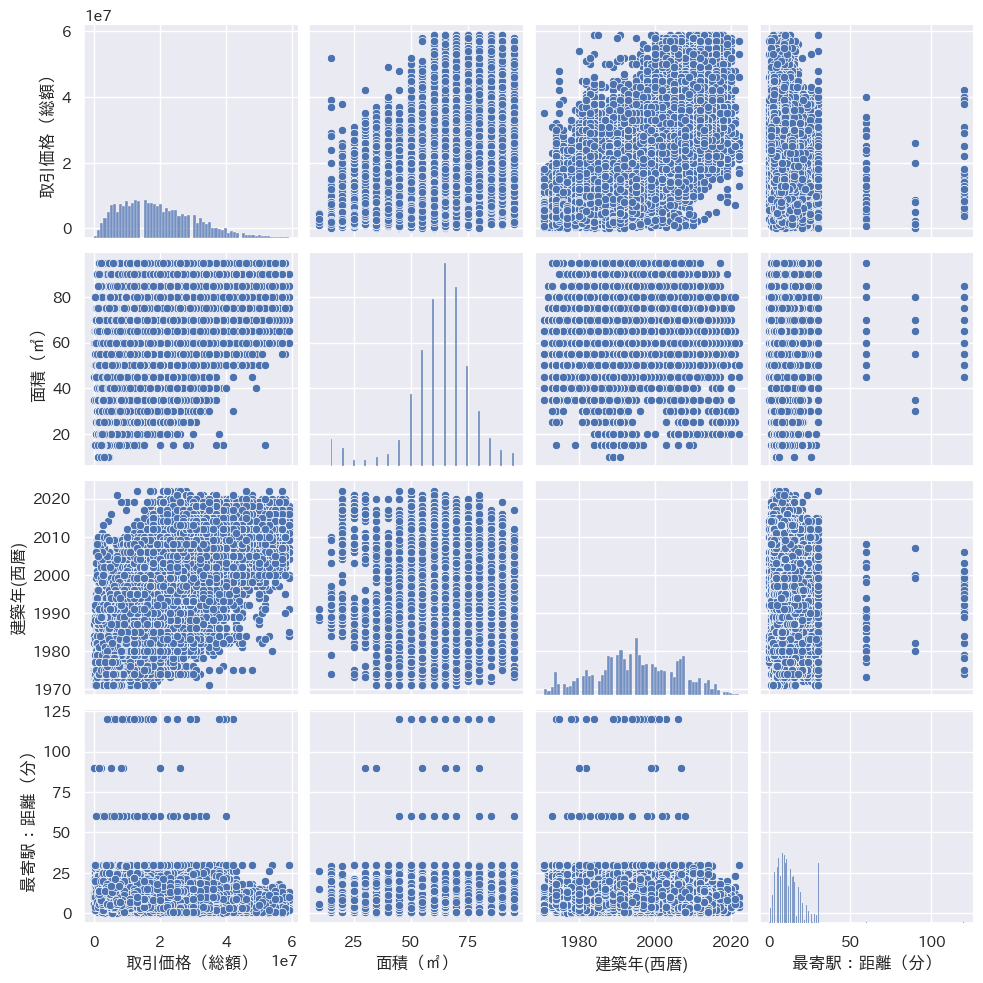
グラフから以下の傾向が掴めました。
・面積が大きくなるほど取引価格が高い
・建築年が新しいほど取引価格が高い
・最寄駅との距離が近いほど取引価格が高い
取引価格、築年数、面積の関係性をより詳細に見ていきます。
# relplotで取引価格、築年数、面積の関係性を可視化
sns.relplot(data=df_data3, x='面積(㎡)', y='取引価格(総額)', size='建築年(西暦)', hue='建築年(西暦)')
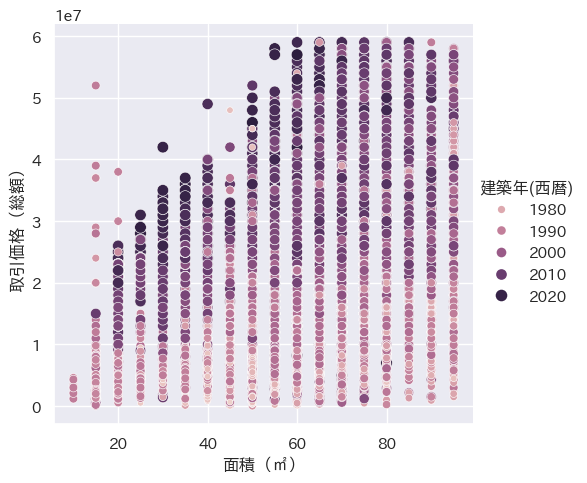
グラフから、建築年が新しく、かつ面積の大きい物件の取引価格が高額となる傾向がわかりました。
予測モデルの説明変数として、「面積(㎡)」「建築年(西暦)」 「最寄駅:距離(分)」を使用してモデルを作成したいと思います。
5.予測モデル構築
線形回帰、リッジ回帰、ラッソ回帰、エラスティックネット回帰、ランダムフォレスト、LightGBMを使って予測をしていきます。各モデルの二乗平均平方根誤差を比較し、値が最も小さくなるモデルをベストモデルとします。また、各モデルの訓練データと検証データの相関係数も確認しました。
X = df_data3[['面積(㎡)', '最寄駅:距離(分)','建築年(西暦)']]
y = df_data3['取引価格(総額)']
# 訓練データ検証データに分ける(9:1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.1, random_state=0)
best_model = ""
pred_model = []
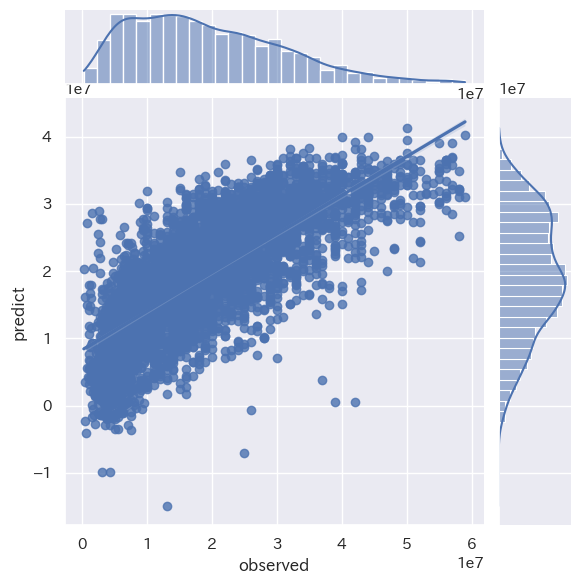
# 線形回帰
model = LinearRegression() # 線形回帰モデル
model.fit(train_X,train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("LinearRegression RMSE : %.2f" % (mse** 0.5))
min_mse = mse
best_model = "線形"
pred_model = pred_model.append(model)
# 訓練データと検証データでの決定係数を確認
print('LinearRegression train score : {}'.format(model.score(train_X, train_y)))
print('LinearRegression test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
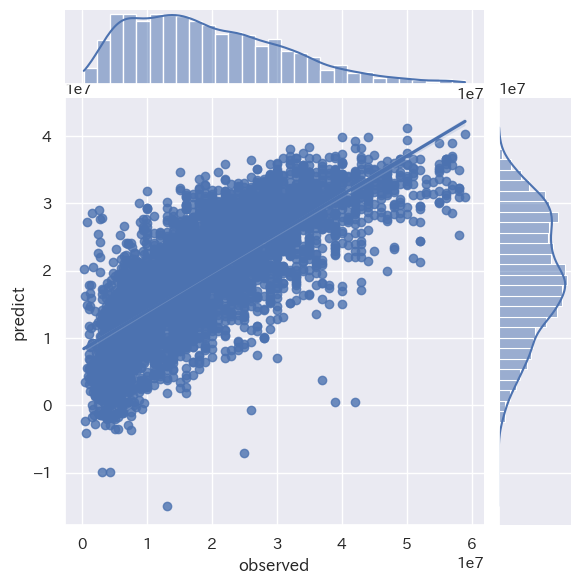
# リッジ回帰
model = Ridge() # リッジ回帰モデル
model.fit(train_X, train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("Ridge RMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "リッジ"
pred_model = model
# 訓練データと検証データでの決定係数を確認
print('Ridge train score : {}'.format(model.score(train_X, train_y)))
print('Ridge test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
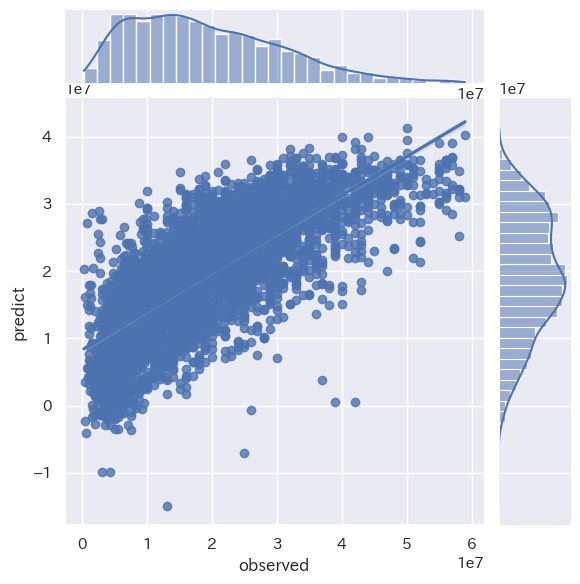
# ラッソ回帰
model = Lasso() # ラッソ回帰モデル
model.fit(train_X, train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("Lasso RMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "ラッソ"
pred_model = model
# 訓練データと検証データでの決定係数を確認
print('Lasso train score : {}'.format(model.score(train_X, train_y)))
print('Lasso test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
# ElasticNet回帰
model = ElasticNet(l1_ratio=0.5) # エラスティックネット回帰モデル
model.fit(train_X, train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("ElasticNet RMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "エラスティックネット"
pred_model = model
# 訓練データと検証データでの決定係数を確認
print('ElasticNet train score : {}'.format(model.score(train_X, train_y)))
print('ElasticNet test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
# RandomForest回帰
model = RandomForestRegressor(100) # ランダムフォレスト回帰モデル
model.fit(train_X,train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("RandomForestRegressor RMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "ランダムフォレスト回帰"
pred_model = model
# 訓練データと検証データでの決定係数を確認
print('RandomForestRegressor train score : {}'.format(model.score(train_X, train_y)))
print('RandomForestRegressor test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
# LightGBM
gbm_reg = lgb.LGBMRegressor(objective='regression', n_estimators=500)
model = gbm_reg.fit(train_X, train_y, eval_set=[(test_X, test_y)], eval_metric='l2')
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("LightGBM RMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "LightGBM"
pred_model = model
# 訓練データと検証データでの決定係数を確認
print('LightGBM train score : {}'.format(model.score(train_X, train_y)))
print('LightGBM test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
print("ベストモデル:{}".format(best_model))
LinearRegression RMSE : 8176019.01
LinearRegression train score : 0.5706224862294396
LinearRegression test score : 0.5681238064580749
Ridge RMSE : 8176019.05
Ridge train score : 0.5706224862293938
Ridge test score : 0.5681238017076011
Lasso RMSE : 7577927.49
Lasso train score : 0.5819759227133539
Lasso test score : 0.5795980352727739
ElasticNet RMSE : 7578385.14
ElasticNet train score : 0.5819692568285745
ElasticNet test score : 0.5795472552373728
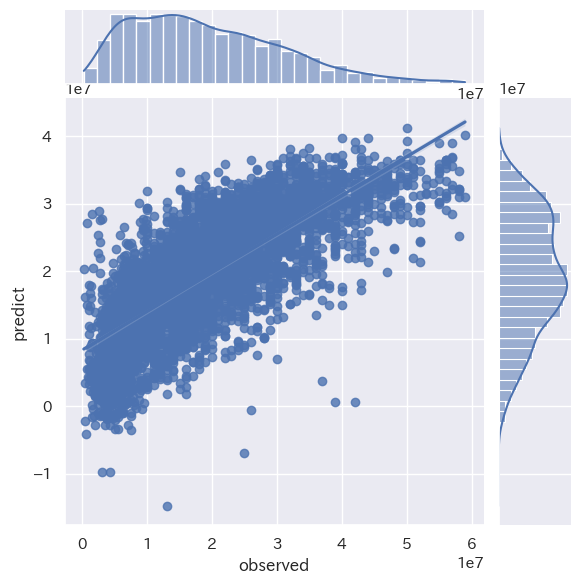
RandomForestRegressor RMSE : 6799271.43
RandomForestRegressor train score : 0.7511080411947532
RandomForestRegressor test score : 0.6615546092901717
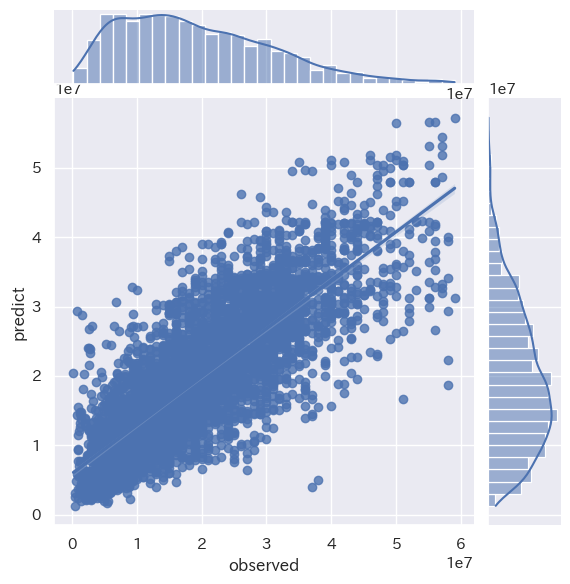
LightGBM RMSE : 6630140.68
LightGBM train score : 0.7056799400030382
LightGBM test score : 0.6781827401264625
ベストモデル:LightGBM
予測の結果、LightGBMが最も良いモデルとなりましたが、現時点では精度が十分とは言えない結果となっています。
LightGBM RMSE : 6630140.68
LightGBM train score : 0.7056799400030382
LightGBM test score : 0.6781827401264625
6.改善策
最も精度の高かったLightGBMを使用します。
6-1 改善策1
モデルに使用した説明変数が不十分と考えられましたので、築年数、改築有無、最寄駅の利用者数、市区町村の人口密度、犯罪発生率、診療所の数の情報を付加していきます。
新しい特徴量「築年数」の追加
# 取引時点から取引年に修正
df_data_normal["取引時点"] = df_data_normal["取引時点"].str[:-6].astype(int)
print(df_data_normal["取引時点"].unique())
# "築年数"の追加
df_data_normal['築年数'] = df_data_normal['取引時点'] - df_data_normal['建築年(西暦)']
改装有無の追加
# 改装ありを1なしを0とする、欠損値は0とする
df_data_normal=df_data_normal.replace( '改装済','1')
df_data_normal=df_data_normal.replace( '未改装','0')
df_data_normal['改装'].fillna(0, inplace=True)
df_data_normal["改装"]=df_data_normal["改装"].astype(int)
新しい特徴量「乗降客数」の追加
# 最寄駅:名称を修正
df_data_normal['最寄駅:名称'] = df_data_normal['最寄駅:名称'].str.replace('(埼玉)', '', regex=False)
df_data_normal['最寄駅:名称'] = df_data_normal['最寄駅:名称'].str.replace('(東京)', '', regex=False)
df_data_normal['最寄駅:名称'] = df_data_normal['最寄駅:名称'].str.replace(r"\(.*?\)", "", regex=True)
# 駅別乗降客数の取得
# 国土交通省土地総合情報システムから取得したデータの駅名を抽出
station_df = pd.DataFrame(df_data_normal['最寄駅:名称'].unique(),columns=['駅名'])
display(station_df)
# 埼玉県、東京都、千葉県の1日あたりの駅別乗降客数データを取得
# こちらのHPからcsvファイルを取得(2023年5月時点) → https://opendata-web.site/station/11/,https://opendata-web.site/station/
# 元データは国土数値情報ダウンロードサービス
pass_num_df1 = pd.read_csv(f'/content/csv_pref_11_best.csv')
pass_num_df2 = pd.read_csv(f'/content/csv_pref_12_best.csv')
pass_num_df3 = pd.read_csv(f'/content/csv_pref_13_best.csv')
pass_num_df = pd.concat([pass_num_df1, pass_num_df2, pass_num_df3], axis=0, ignore_index=True)
# 乗降客数データと駅名を修正
pass_num_df = pass_num_df[pass_num_df['乗降客数'] != '他路線に含む'] #乗降客数が入っていない行は削除
pass_num_df = pass_num_df[pass_num_df['乗降客数'] != 'データなし']
pass_num_df = pass_num_df[pass_num_df['乗降客数'] != '-']
pass_num_df['乗降客数'] = pass_num_df['乗降客数'].str.replace(",","")
pass_num_df['駅名'] = pass_num_df['駅名'].str.replace("ヶ","ケ")
pass_num_df['乗降客数'] = pass_num_df['乗降客数'].astype(int)
display(pass_num_df)
display(pass_num_df['駅名'].duplicated().sum())
print(pass_num_df.sort_values('乗降客数', ascending=False))
# データにあった駅名とマッチング
# station_dfとpass_num_dfから重複を削除
station_df_unique = station_df.drop_duplicates(subset='駅名')
pass_num_df_unique = pass_num_df.drop_duplicates(subset='駅名')
# 駅名をキーにして左外部結合
station_df2 = pd.merge(station_df_unique, pass_num_df_unique, on='駅名', how='left')
# df_data_normalとstation_df2を最寄駅:名称と駅名をキーにして左外部結合
df2 = pd.merge(df_data_normal, station_df2, left_on='最寄駅:名称', right_on='駅名', how='left')
print(df2.sort_values('乗降客数', ascending=False))
# 欠損値を0に修正
df2['乗降客数'].fillna(0, inplace=True)
新しい特徴量「人口密度」の追加
#s-Stat政府統計の総合窓口より埼玉県の市区町村別人口密度を取得
pass_num_df4 = pd.read_csv(f'/content/001_11 (1).csv',encoding="cp932")
display(pass_num_df4)
print(pass_num_df4['市区町村'].unique()) #Uniqueの項目を見る
# 人口密度データと市区町村を修正
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("\u3000","")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace(" ","")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("人口集中地区","")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("杉戸町","北葛飾郡杉戸町")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("宮代町","南埼玉郡宮代町")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("越生町","入間郡越生町")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("毛呂山町","入間郡毛呂山町")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("三芳町","入間郡三芳町")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("伊奈町","北足立郡伊奈町")
pass_num_df4['市区町村'] = pass_num_df4['市区町村'].str.replace("ヶ","ケ")
pass_num_df4 = pass_num_df4[pass_num_df4['市区町村'] != 'Ⅰ']
pass_num_df4 = pass_num_df4[pass_num_df4['市区町村'] != 'Ⅱ']
pass_num_df4 = pass_num_df4[pass_num_df4['市区町村'] != 'Ⅲ']
pass_num_df4 = pass_num_df4[pass_num_df4['市区町村'] != 'Ⅳ']
pass_num_df4 = pass_num_df4[pass_num_df4['市区町村'] != 'Ⅴ']
pass_num_df4 = pass_num_df4[~pass_num_df4['市区町村'].str.contains('旧')]
print(pass_num_df4['市区町村'].unique()) #Uniqueの項目を見る
# データにあった市町村名とマッチング
# city_dfとpass_num_df4から重複を削除
city_df_unique = city_df.drop_duplicates(subset='市区町村名')
pass_num_df4_unique = pass_num_df4.drop_duplicates(subset='市区町村')
# 市区町村名をキーにして左外部結合
city_df2 = pd.merge(city_df_unique, pass_num_df4_unique, left_on='市区町村名', right_on='市区町村', how='left')
# df2とcity_df2を市区町村名をキーにして左外部結合
df3 = pd.merge(df2, city_df2, left_on='市区町村名', right_on='市区町村名', how='left')
print(df3.sort_values('人口密度(1km2当たり)', ascending=False))
#欠損値を0に修正
df3['人口密度(1km2当たり)'].fillna(0, inplace=True)
新しい特徴量「犯罪発生率」の追加
# 埼玉県警察HPより刑法犯認知件数(市町村別)(令和5年確定版)を取得→chromeextension://efaidnbmnnnibpcajpcglclefindmkaj/https://www.police.pref.saitama.lg.jp/documents/27624/sichouson.pdf
# 取得したPDFの表をCSVファイルとして保存する
!pip install tabula-py
import tabula
tabula.convert_into('/content/sichouson.pdf', '/content/output.csv', output_format='csv', pages=1)
crime_num_df1 = pd.read_csv(f'/content/output.csv')
display(crime_num_df1)
# 一部の文字、数値がPDFからCSVへうまく変換できなかったため、手動でcsvに変換したファイルを読み込む
crime_num_df2 = pd.read_csv('/content/sichouson.csv', encoding='shift-jis')
crime_num_df2['犯罪件数(2023年)'] = pd.to_numeric(crime_num_df2['犯罪件数(2023年)'], errors='coerce')
display(crime_num_df2)
# データにあった市町村名とマッチング
# city_dfとcrime_num_df2から重複を削除
city_df_unique = city_df.drop_duplicates(subset='市区町村名')
crime_num_df2_unique = crime_num_df2.drop_duplicates(subset='市区町村')
# 市区町村名をキーにして左外部結合
crime_num_df3 = pd.merge(city_df_unique, crime_num_df2_unique, left_on='市区町村名', right_on='市区町村', how='left')
# df3とcrime_num_df3を市区町村名をキーにして左外部結合
df4 = pd.merge(df3, crime_num_df3, left_on='市区町村名', right_on='市区町村名', how='left')
# 新しい特徴量"犯罪発生率(%)"の追加
df4['犯罪発生率(%)'] = df4['犯罪件数(2023年)'] /df4['人口']*100
print(df4.sort_values('犯罪発生率(%)', ascending=False))
# 欠損値を0に修正
df4['犯罪発生率(%)'].fillna(0, inplace=True)
新しい特徴量「診療所の数」の追加
# データの市区町村名を抽出
city_df = pd.DataFrame(df4['市区町村名'].unique(),columns=['市区町村名'])
display(station_df)
# 令和元年 埼玉県保健統計年報 統計資料(第2章 医療統計)
# 医療施設数及び病床数(保健所・市区町村別)→https://www.pref.saitama.lg.jp/documents/204138/r1_2-10_18.xlsx
# 上記より市区町村別一般診療所(人口10万人対)を取得
clinic_num_df = pd.read_csv('/content/shinryojyo.csv', encoding='shift-jis')
clinic_num_df['一般診療所(10万人あたり)'] = pd.to_numeric(clinic_num_df['一般診療所(10万人あたり)'], errors='coerce')
display(clinic_num_df)
print(clinic_num_df['市区町村'].unique()) #Uniqueの項目を見る
clinic_num_df['市区町村'] = clinic_num_df['市区町村'].str.replace("\u3000","")
clinic_num_df['市区町村'] = clinic_num_df['市区町村'].str.replace(" ","")
print(clinic_num_df['市区町村'].unique()) #Uniqueの項目を見る
# データにあった市町村名とマッチング
# city_dfとcrime_num_dfから重複を削除
city_df_unique = city_df.drop_duplicates(subset='市区町村名')
clinic_num_df_unique = clinic_num_df.drop_duplicates(subset='市区町村')
# 市区町村名をキーにして左外部結合
clinic_num_df2 = pd.merge(city_df_unique, clinic_num_df_unique, left_on='市区町村名', right_on='市区町村', how='left')
# df4とclinic_num_dfを市区町村名をキーにして左外部結合
df5 = pd.merge(df4, clinic_num_df2, left_on='市区町村名', right_on='市区町村名', how='left')
# 欠損値を0に修正
df5['一般診療所(10万人あたり)'].fillna(0, inplace=True)
予測モデル再構築
説明変数に 「取引時点」,「築年数」,「改装」,「乗降客数」,「人口密度(1km2当たり)」,「犯罪発生率(%)」,「一般診療所(10万人あたり)」を追加し予測モデルを再構築します
X = df5[["面積(㎡)", "最寄駅:距離(分)","建築年(西暦)","取引時点","築年数","改装","乗降客数", "人口密度(1km2当たり)","犯罪発生率(%)",'一般診療所(10万人あたり)']]
y = df5["取引価格(総額)"]
# 訓練データ検証データに分ける(9:1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.1, random_state=0)
# LightGBM
gbm_reg = lgb.LGBMRegressor(objective='regression', n_estimators=500)
model = gbm_reg.fit(train_X, train_y, eval_set=[(test_X, test_y)], eval_metric='l2')
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("LightGBM RMSE : %.2f" % (mse** 0.5))
# 訓練データと検証データでの決定係数を確認
print('LightGBM train score : {}'.format(model.score(train_X, train_y)))
print('LightGBM test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
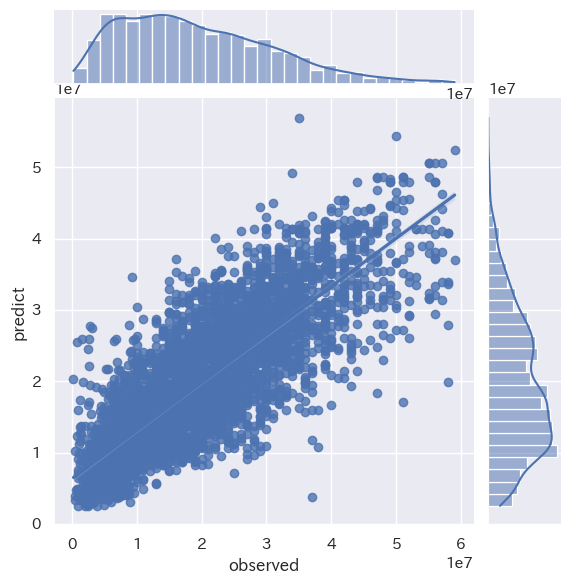
LightGBM RMSE : 3670378.10
LightGBM train score : 0.9187354854206382
LightGBM test score : 0.9013753545306167
精度が改善されました!!
6-2 改善策2
取引価格に影響しそうな、地理的情報と駅・路線情報をOne-Hotエンコーディングでダミー変数に変換して、説明変数に使用し、LightGBMで再度予測モデルを構築します。
# 地理的特徴と路線情報をOne-hot Encoding
geographical_features = pd.get_dummies(df5[['市区町村名', '地区名', '最寄駅:名称', '路線名']], drop_first=True)
# 既存の特徴量セット
existing_features = df5[['面積(㎡)', '最寄駅:距離(分)','建築年(西暦)','取引時点','築年数','改装','乗降客数', '人口密度(1km2当たり)','犯罪発生率(%)','一般診療所(10万人あたり)']]
# エンコーディングされた特徴量と既存の特徴量を結合
X = pd.concat([existing_features, geographical_features], axis=1)
y = df5["取引価格(総額)"]
# 訓練データ検証データに分ける(9:1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.1, random_state=0)
#LightGBM
gbm_reg = lgb.LGBMRegressor(objective='regression', n_estimators=500)
model = gbm_reg.fit(train_X, train_y, eval_set=[(test_X, test_y)], eval_metric='12')
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("LightGBM RMSE : %.2f" % (mse** 0.5))
# 訓練データと検証データでの決定係数を確認
print('LightGBM train score : {}'.format(model.score(train_X, train_y)))
print('LightGBM test score : {}'.format(model.score(test_X, test_y)))
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
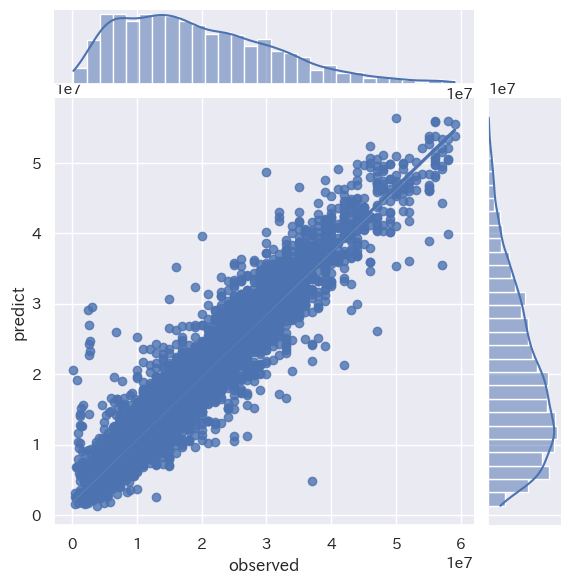
LightGBM RMSE : 3624628.23
LightGBM train score : 0.9177314160649876
LightGBM test score : 0.9038186688496301
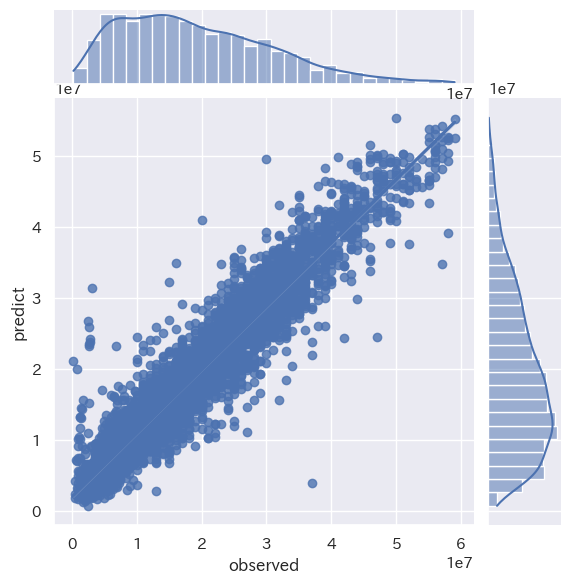
さらに精度が向上しました!!
続いて訓練データと検証データを色分けしてプロットしてみます。
plt.figure()
plt.scatter(train_y,model.predict(train_X),label='Train',c='blue')
plt.scatter(test_y,pred_y,c='orange',label='Test',alpha=0.8)
plt.title('Predictor')
plt.xlabel('observed')
plt.ylabel('Predicted')
plt.legend()
plt.show()
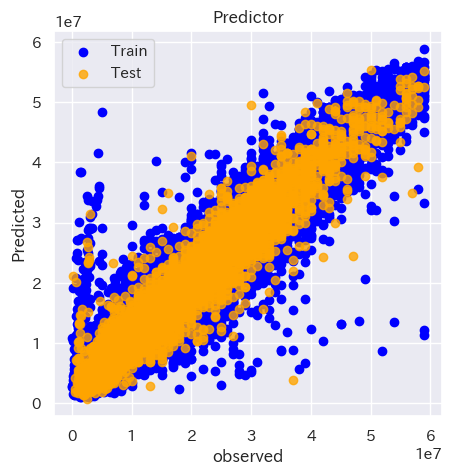
青が訓練データ、オレンジが検証データを示しています。X軸が実測値、Y軸が予測値を示しています。訓練データ、検証データが重なりあっており、高い相関を持っていることが分かります。
6-3 特徴量の重要度の確認
# 特徴量の重要度を確認
importances = model.feature_importances_
# 特徴量の重要度を特徴量名と対応させてDataFrameにする
feature_importance_df = pd.DataFrame({
'Feature': train_X.columns,
'Importance': importances
})
# 重要度で降順にソート
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)
# 上位10項目を表示
top_10_features = feature_importance_df.head(10)
print(top_10_features)
重要度のランキング(TOP20)は以下のようになりました
1 建築年(西暦) 1899
2 最寄駅:距離(分) 1855
3 面積(㎡) 1629
4 取引時点 1551
5 築年数 1444
6 乗降客数 648
7 改装 405
8 人口密度(1km2当たり) 376
9 一般診療所(10万人あたり) 275
10 犯罪発生率(%) 256
11 地区名_本町 41
12 地区名_上落合 40
13 路線名_伊勢崎線 37
14 地区名_常盤 37
15 地区名_高砂 36
16 路線名_東北線 36
17 最寄駅:名称_川口元郷 35
18 地区名_別所 35
19 市区町村名_戸田市 33
20 地区名_栄町 31
やはり、初めに説明変数に選択した3つがTOP3に入っています。取引時点が4位に入っており、年々物件価格が高騰しているので、重要度が高いのかと推察されます。築年数より取引時点の重要度が高いというのが少し驚きましたが、近年の物件価格の高騰のほうが取引価格への影響度が高いってことなんでしょうか。病院の数、犯罪発生率なども住みたいエリアとしての重要ポイントとなるので、TOP10に食い込んでいるようです。
6-4 (お試し)ディープニューラルネットワーク
少し勉強したディープニューラルネットワークも試してみます。
# DNN回帰
model = Sequential()
model.add(Dense(128, input_dim=train_X.shape[1]))
model.add(Activation("relu"))
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dropout(rate=0.1))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
history = model.fit(train_X, train_y, epochs=100 , batch_size=32 , verbose=0, validation_data=(test_X, test_y) ) # 学習
pred_y = model.predict(test_X) # 予測
train_pred_y = model.predict(train_X)
mse= mean_squared_error(test_y, pred_y)# 評価
print("DeepNuralNet RMSE : %.2f" % (mse** 0.5))
#訓練データと検証データでの決定係数を確認
from sklearn.metrics import r2_score
r2_train = r2_score(train_y, train_pred_y)
r2_test = r2_score(test_y, pred_y)
print('DeepNuralNet train score : ', r2_train)
print('DeepNuralNet test score :', r2_test)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
DeepNuralNet RMSE : 5793268.52
DeepNuralNet train score : 0.7846371613674508
DeepNuralNet test score : 0.7831682888701976
思ったほど精度があがらない結果となりました。
チューニングが必要なようです。
7.予測
自分の購入したマンションが20年後どのくらいの価格で売れるのか、構築したLightGBMモデルで予測してみます。(20年後とかなり先になるので、このモデルでは20年後の不動産価格の推移までは正確にとらえらていないと思いますがご了承ください。細かい情報は個人情報にあたるので伏せさせていただきます)
# 訓練データ検証データに分ける(9:1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.1, random_state=0)
# LightGBM
gbm_reg = lgb.LGBMRegressor(objective='regression', n_estimators=500)
model = gbm_reg.fit(train_X, train_y, eval_set=[(test_X, test_y)], eval_metric='12')
# 新しいデータポイントを作成
new_data_point = {
'市区町村名': 'xxx',
'地区名': 'xx',
'最寄駅:名称': 'xx',
'路線名': 'xxxx',
'面積(㎡)': xx,
'最寄駅:距離(分)': xx,
'建築年(西暦)':2024,
'築年数': 20,
'乗降客数': xxxxx,
'人口密度(1km2当たり)': xxxxx,
'改装': 0,
'取引時点': 2044,
'犯罪発生率(%)' : x.xxxx,
'一般診療所(10万人あたり)' : xx.x
}
test_series_data=pd.Series(new_data_point)
one_hot_list=['市区町村名', '地区名', '最寄駅:名称', '路線名']
for i in one_hot_list:
test_series_data[i+"_"+test_series_data[i]]=1
make_data=[]
for i in X.columns:
if i not in test_series_data.index:
make_data.append(0)
else:
make_data.append(test_series_data[i])
test_case=pd.Series(make_data,index=X.columns).to_frame().T
# 学習済みモデルを使って予測
predicted_price = model.predict(test_case)
print("20年後の予測価格:", predicted_price)
# 20年後の取引価格が新築購入時の購入価格の何%になったか算出
purchase_price= xxxxxxxx # 新築購入時の価格
print("20年後の予測価格/新築購入時価格(%):",predicted_price/purchase_price*100)
20年後の予測価格(総額): [xxxxxxxx.xxxxxxxxx]
20年後の予測価格/新築時購入価格(%): [104.91065052]
20年後の予測価格は新築購入時の価格の約105%と予測されました!!
(予測価格は伏せています。すいません。)
終わりに(考察)
はじめはSUUMOさんから物件情報のスクレイピングを実施しましたが、現在掲載中の埼玉県の中古マンションの物件のみでは物件数が少なく断念しました。その代わりに国土交通省土地総合情報システムより過去18年分の取引データを取得し、その情報をもとに販売価格予測を行ってみました。
感想としては、データの前処理と物件情報にないデータを付加する部分で、かなり時間を使いました。自分なりに工夫をし、試行錯誤してモデルの精度を向上できたと思います。使用した物件データには方角(東西南北)や階数等のデータがなかったのですが、この辺の情報もあるともっと精度が上がったのかなと思います。
今回いくつかの手法で予測モデルを構築してみましたが、ハイパーパラメータのチューニングなど十分にできていませんので、これからも勉強を続けていきたいと思います。また、機械的な変数選択などもトライしてみたいです。
ニューラルネットワークも試してみましたが、精度があまり上がらない結果となりました。こちらも今後知見を深めて行きたいです。