はじめに
こんにちわ。
pythonを使ったデータ分析や機械学習の勉強をしています。勉強したことを振り返りながら、初投稿してみたいと思います。テーマを何にしようかと悩みましたが、少し前に中古マンションを買ったこともあり、これ今売ったらいくらになるんだろうか、また、お得な物件見つけられないだろうか。。。
ということで、東京23区の中古マンション価格を「何区?専有面積は?駅まで徒歩何分?」といった情報から販売価格予測するモデルを構築してみたいと思います。
環境
- MacOS 12.4
- python 3.7.13
- Google Colaboratory
やったこと (手順)
本記事では以下の手順で、東京23区の中古マンション販売価格の予測を行っていきました。
| 工程 | 内容 |
|---|---|
| 1.準備 | 必要なパッケージのインポートなどの準備 |
| 2.データ収集 | 東京23区の中古マンション販売情報をスクレイピング |
| 3.前処理 | 学習データの前処理。最寄駅に乗降客数も付与 |
| 4.データ可視化 | データの概観を確認 |
| 5.予測モデル構築 | 今回は重回帰分析、ランダムフォレスト回帰、LightGBM(と参考にMLP)でモデルを構築。 |
| 6.予測 | 一番評価が良かったモデルを使って予測値を計算し、お得な物件探し。(※あくまで個人的な試みであり、販売価格に対してご意見するものではありません。) |
参考文献
今回、以下サイトを参考にさせていただき、また大変勉強させていただきました。感謝申し上げます。
SUUMO の中古物件情報を Tableau で分析してみる ~データ収集編~
SUUMO の中古物件情報を Tableau で分析してみる ~データ予測編~
機械学習を使って東京23区のお買い得賃貸物件を探してみた 〜スクレイピング編〜
オープンポータル (オープンデータ活用サイト、競売、人口、駅)
1.準備:パッケージインポートなど
1.1 Google Driveへのマウント、パッケージのインポート
ここでは、Google CplaboratoryからGoogle Driveへファイル書き出し、読み込みをするための準備や、今回使うパッケージのインポートを行いました。また、後ほどデータ加工用の関数群も予め定義しておきます。
#ドライブ設定
PATH_GMOUNT='/content/gdrive'
PATH_MYDRIVE=PATH_GMOUNT+'/My Drive'
#GDriveマウント
#以下を実行するとGoogleDriveへのマンウント許可を求められるので、許可する
from google.colab import drive
drive.mount(PATH_GMOUNT)
!pip install japanize-matplotlib #Google colab上でグラフで日本語表示するためにインストール
#必要なライブラリのインポート
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import requests
import re
import time
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
import lightgbm as lgb
from sklearn.model_selection import train_test_split
1.2 データ加工用の関数群
スクレイピングしてきたデータを加工するための関数群を定義しておきます。(こちらは参考情報のページの関数を少し修正して使わせていただきました。)
#データ加工用の関数群
def identify_floor_plan(floor_plan):
# 間取りの種類が多すぎるのでまとめる
if floor_plan.find("ワンルーム") > -1:
floor_plan = "1K"
if floor_plan.find("+") > -1:
floor_plan = floor_plan[:floor_plan.find("+")]
if floor_plan.find("LK") > -1:
floor_plan = floor_plan[0:1] + "LDK"
if floor_plan.find("LL") > -1 or \
floor_plan.find("DD") > -1 or \
floor_plan.find("KK") > -1:
floor_plan = floor_plan = floor_plan[0:1] + "LDK"
return floor_plan
def convert_price(price):
# 万円※権利金含むの処理
if price.find("※") > -1:
price = price[:price.find("※") ]
# ○○万円~○○万円の処理
if price.find("~") > -1:
price = price[price.find("~") + 1: ]
if price.find("億") > -1:
# 1億円ジャストのような場合の処理
if price.find("万") == -1:
price = int(price[:price.find("億")]) * 10000
else:
oku = int(price[:price.find("億")]) * 10000
price = oku + int(price[price.find("億") + 1:-2])
else:
price = int(price[:price.find("万")])
else:
if price.find("億") > -1:
# 1億円ジャストのような場合の処理
if price.find("万") == -1:
price = int(price[:price.find("億")]) * 10000
else:
oku = int(price[:price.find("億")]) * 10000
price = oku + int(price[price.find("億") + 1:-2])
else:
price = int(price[:price.find("万")])
return price
def remove_brackets(data):
# ○○~○○の処理
if data.find("~") > -1:
data = data[data.find("~") + 1:]
# m2以降を除去
if data.find("m2") > -1:
data = data[:data.find("m")]
# ()を除去
if data.find("(") > -1:
data = data[:data.find("(")]
return data
def get_line_station(line_station):
# JRをJRに変換
if line_station.find("JR") > -1:
line_station = line_station.replace("JR", "JR")
# バスと徒歩の時間を取得
if line_station.find("バス") > -1:
bus_time = int(line_station[line_station.find("バス") + 2 : line_station.find("分")])
walk_time = int(line_station[line_station.find("停歩") + 2 : line_station.rfind("分")])
else:
bus_time = int(0)
walk_time = int(line_station[line_station.find("徒歩") + 2 : line_station.rfind("分")])
# 沿線と駅を取得
line = line_station[ : line_station.find("「") ]
station = line_station[line_station.find("「") + 1 : line_station.find("」")]
return line, station, bus_time, walk_time
2.データ収集: 東京23区の中古マンション販売情報をスクレイピング
今回はSUUMOさんのホームページから東京23区の中古マンション販売情報をスクレイピングさせていただきました。一度に東京23区の全てをスクレイピングせずに、4分割しました。コメントアウトしたurlについても、同様に実行して、後ほど結合します。
2.1 ページを取得
#SUUMOから東京23区の中古マンションの検索結果を取得していきます。量も多くなるので、いくつかに分割して取得します。
#東京都千代田区、東京都中央区、東京都港区、東京都新宿区、東京都文京区、東京都渋谷区の中古マンションの購入情報 検索結果一覧
url = "https://suumo.jp/jj/bukken/ichiran/JJ010FJ001/?ar=030&bs=011&ta=13&jspIdFlg=patternShikugun&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&kb=1&kt=9999999&mb=0&mt=9999999&ekTjCd=&ekTjNm=&tj=0&cnb=0&cn=9999999&srch_navi=1"
#東京都台東区、東京都墨田区、東京都江東区、東京都荒川区、東京都足立区、東京都葛飾区、東京都江戸川区の中古マンションの購入情報 検索結果一覧
#url = "https://suumo.jp/jj/bukken/ichiran/JJ010FJ001/?ar=030&bs=011&ta=13&jspIdFlg=patternShikugun&sc=13106&sc=13107&sc=13108&sc=13118&sc=13121&sc=13122&sc=13123&kb=1&kt=9999999&mb=0&mt=9999999&ekTjCd=&ekTjNm=&tj=0&cnb=0&cn=9999999&srch_navi=1"
#東京都品川区、東京都目黒区、東京都大田区、東京都世田谷区の中古マンションの購入情報 検索結果一覧
#url = "https://suumo.jp/jj/bukken/ichiran/JJ010FJ001/?ar=030&bs=011&ta=13&jspIdFlg=patternShikugun&sc=13109&sc=13110&sc=13111&sc=13112&kb=1&kt=9999999&mb=0&mt=9999999&ekTjCd=&ekTjNm=&tj=0&cnb=0&cn=9999999&srch_navi=1"
#東京都中野区、東京都杉並区、東京都練馬区、東京都豊島区、東京都北区、東京都板橋区の中古マンションの購入情報 検索結果一覧
#url = "https://suumo.jp/jj/bukken/ichiran/JJ010FJ001/?ar=030&bs=011&ta=13&jspIdFlg=patternShikugun&sc=13114&sc=13115&sc=13120&sc=13116&sc=13117&sc=13119&kb=1&kt=9999999&mb=0&mt=9999999&ekTjCd=&ekTjNm=&tj=0&cnb=0&cn=9999999&srch_navi=1"
r = requests.get(url)
soup = BeautifulSoup(r.text)
hit_count = soup.find("div", class_="pagination_set-hit").text
r.close()
#ページ数を取得
body = soup.find("body")
pages = body.find_all("div",{'class':'pagination pagination_set-nav'})
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
pages_split0 = pages_split[0]
pages_split1 = pages_split0[-3:]
pages_split2 = pages_split1.replace('>','')
pages_split3 = int(pages_split2) #これがページ数
#URLを入れるリスト
urls = []
#1ページ目を格納
urls.append(url)
#2ページ目から最後のページまでを格納
for i in range(pages_split3-1):
pg = str(i+2)
url_page = url + '&pn=' + pg
urls.append(url_page)
2.2 中古マンション販売情報をスクレイピング
SUUMOさんのサイトから、物件ごとに以下の情報をスクレイピングしました。サイトでは以下のような中古マンション販売情報が閲覧できます。
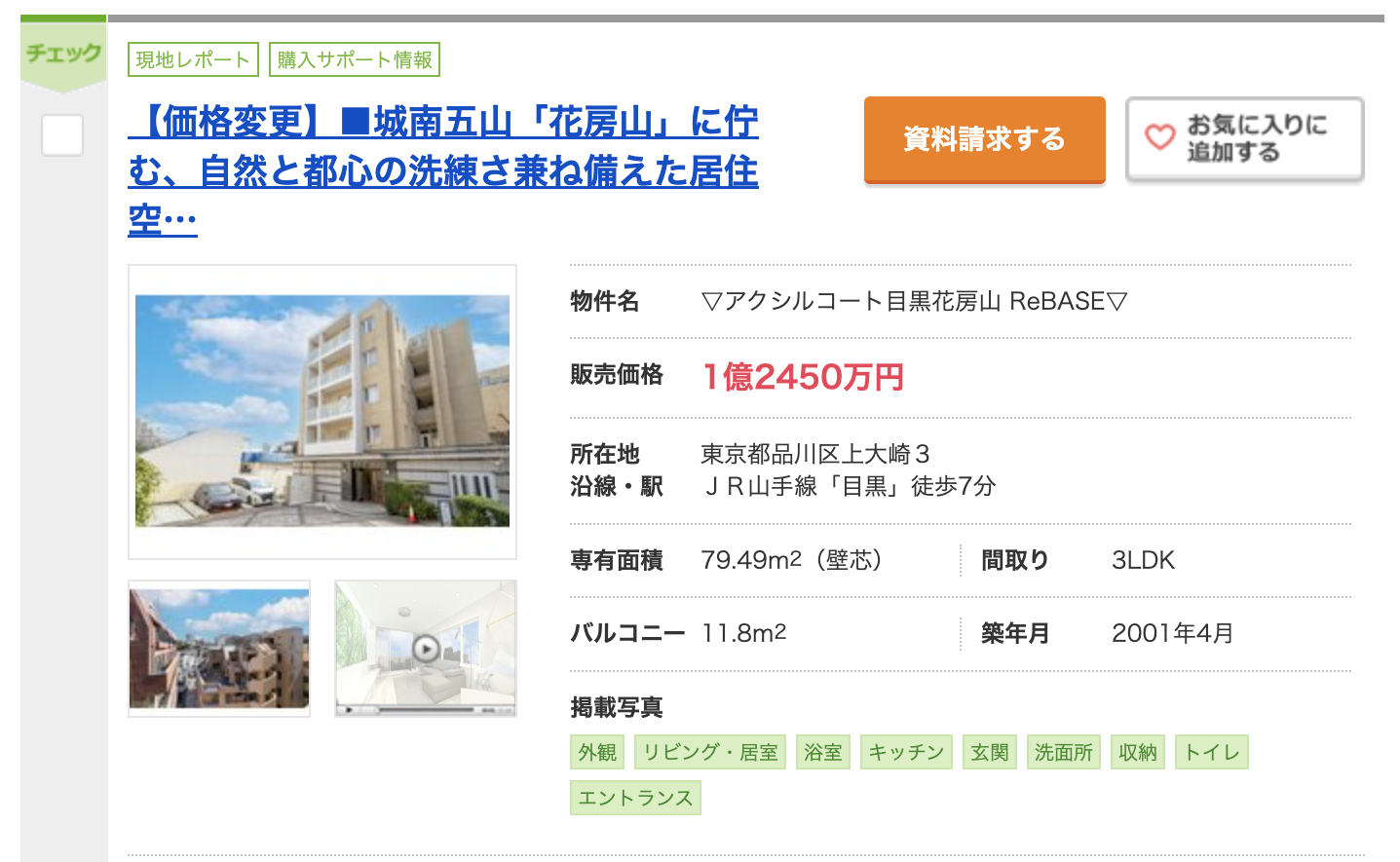
ここから物件名、販売価格、所在地、沿線・駅、専有面積、間取り、バルコニー、築年数の情報を取得しました。また、左上部にある青字の見出し情報に「リノベーション」や「リフォーム」といった情報がある場合に、フラグとして情報を記録しています。
#SUUMOのHPからスクレイピング
cols = ["price", "name", "address", "ward", "line_station", "line", "station","walk_time","bus_time","area", "balcony", "floor_plan", "age","renovation","reform"]
df = pd.DataFrame(index=[], columns=cols)
data = {}
for url in urls:
r = requests.get(url)
soup = BeautifulSoup(r.text)
r.close()
summary = soup.find_all('div', 'property_unit-content')
for s in summary:
#print(s.find_all('dl'))
s_2 = s.find_all('dl')
#物件名
data['name'] = s_2[0].find('dd').text
#販売価格
data['price'] = s_2[1].find('span').text
#所在地:住所と区を取り出す
address = s_2[2].find('dd').text
data['address'] = address
data['ward'] = address.replace('東京都','').split('区')[0] + '区'
#沿線・駅:沿線、駅名、徒歩時間、バス時間を取り出す
data["line_station"] = s_2[3].find('dd').text
#専有面積
data['area'] = s_2[4].find('dd').text
#間取り
data['floor_plan'] = identify_floor_plan(s_2[5].find('dd').text)
#バルコニー:
data['balcony'] = s_2[6].find('dd').text
#間取り
data['age'] = s_2[7].find('dd').text
header = s.find('h2').text
#リノベーション:ヘッダーに「リノベ」の文字列があるときにFlagとして持つ
if header.find('リノベ')>-1:
data['renovation'] = 1
else:
data['renovation'] = 0
#リフォーム:ヘッダーに「リフォーム」の文字列があるときにFlagとして持つ
if header.find('リフォーム')>-1:
data['reform'] = 1
else:
data['reform'] = 0
if len(data) >=1:
df = df.append(data, ignore_index=True)
data = {}
#スクレイピング時のマナーとして、プログラムを停止する
time.sleep(5)
# CSVファイルを出力します。
# 今回は23区を4分割で取得しているので、ファイル名を変えて4ファイルを出力。以下は1ファイル目。
df.to_csv(f'{PATH_MYDRIVE}/property_data_0709_1.csv', index=False)
#display(df)
3.前処理:販売価格予測モデルのための学習データの前処理
3.1 ファイルを読み込み
前段でスクレイピングしてcsvファイルで保管したデータを読み込みます。
#保存したcsvファイルを読み込み
df_1 = pd.read_csv(f'{PATH_MYDRIVE}/property_data_0705_1.csv')
df_2 = pd.read_csv(f'{PATH_MYDRIVE}/property_data_0705_2.csv')
df_3 = pd.read_csv(f'{PATH_MYDRIVE}/property_data_0705_3.csv')
df_4 = pd.read_csv(f'{PATH_MYDRIVE}/property_data_0705_4.csv')
#分割していたファイルを結合
df = pd.concat([df_1, df_2, df_3, df_4], axis=0, ignore_index=True)
3.2 データの前処理
それでは、データの前処理を行っていきます。
- 「沿線・駅」に含まれていたイレギュラーデータを削除。(例:徒歩時間の代わりに距離が記載してあったり、駅名のところにバス停名が記載してあったりです。)
- 「販売価格」を万円単位にしました。(例:1億2000万円→12000)
- 「沿線・駅」から、沿線、最寄駅、徒歩時間、バス時間を抜き出し。
- 「専有面積」、「バルコニー」から数値だけ抜き出し。
- 「築年数」を計算。(例:1982年3月→40)
### データの前処理
#「沿線・駅」にイレギュラーデータが入っている行を手動で削除。
df = df[~(df['line_station'].str.contains('JR山手線「東京」車8.3km'))]
df = df[~(df['line_station'].str.contains('都営バス「東砂五丁目」徒歩1分'))]
df = df[~(df['line_station'].str.contains('都営バス「なぎさニュータウン停」徒歩1分'))]
df = df[~(df['line_station'].str.contains('葛西「なぎさニュータウン」徒歩10分'))]
df = df[~(df['line_station'].str.contains('国際興業バス「宮の下」徒歩4分'))]
df = df[~(df['line_station'].str.contains('西武バス「春日野」徒歩1分'))]
#indexを振り直す
df = df.reset_index(drop=True)
#販売価格:「億」や「万円」をリプレイスして、int型に
for i,price in enumerate(df['price']):
df.loc[i,'price'] = convert_price(price)
#沿線・駅:沿線、駅名、徒歩時間、バス時間を取り出す
for i,line_station in enumerate(df['line_station']):
line, station, bus_time,walk_time = get_line_station(line_station)
df.loc[i, "line"] = line
df.loc[i, "station"]= station
df.loc[i, "walk_time"] = walk_time
df.loc[i, "bus_time"] = bus_time
#専有面積
for i,area in enumerate(df['area']):
df.loc[i, 'area'] = float(area[:area.find("m")]) #「m」より前を削除して、float型に
#バルコニー
for i,balcony in enumerate(df['balcony']):
if re.search(r'\d+',balcony):
if balcony.find('㎡') > -1:
df.loc[i, 'balcony'] = float(balcony[:balcony.find("㎡")]) #「㎡」より前を削除して、float型に
else:
df.loc[i, 'balcony'] = float(balcony[:balcony.find("m")]) #「m」より前を削除して、float型に
else:
df.loc[i, 'balcony'] = float(0) #数字以外(「-」など)が入っているときには、ゼロ(float型)にした
#築年数
for i,age in enumerate(df['age']):
df.loc[i, 'age'] = 2022 - int(age[:age.find("年")]) #年だけを取り出し、築年数を計算
#数値型へ変換
df = df.astype({'price': 'int32', 'area': 'float32', 'balcony': 'float32', 'age':'int8'})
ここまでで取得したデータを確認してみます。
display(df.head())

display(df.describe())
display(df.describe(exclude='number'))

データ件数は22,148件で、販売価格の最大値は約30億円でした。バルコニーの最大面積が999㎡となっていましたが、データを見てみると入力ミスと思われたので、後工程で削除します。
3.3 重複データの削除
SUUMOさんのサイトを見ていただくとわかりますが、異なる不動産屋さんが同じ物件情報を入力するなど重複情報も見られますので、重複行を削除しました。
#重複行の削除 ※4000件以上が削除されました
df = df.drop_duplicates(ignore_index=True)
3.4 高額物件の除外
高額物件が外れ値となりそうですし、私には現実性のない価格感なので、今回は2億円以内のデータに絞りました。
#今回は販売価格が2億円以下の物件に絞った
df = df[df['price'] <= 20000]
3.5 徒歩時間、バルコニー面積の入力ミスの補正
徒歩時間やバルコニー面積が大きいデータを確認して、以下の補正を行いました。補正値は、一軒ずつサイトで確認するなど地道な作業を行っています。
#徒歩時間の補正 ※SUUMOホームページを確認して補正
df.loc[df['walk_time'] ==77, 'walk_time'] = 7
#バルコニーの外れ値の補正 ※SUUMOホームページを確認して補正
df.loc[df['balcony'] ==483.75, 'balcony'] = 4
df.loc[df['balcony'] ==60.11, 'balcony'] = 0
df.loc[df['balcony'] ==60.049999, 'balcony'] = 6
df.loc[df['balcony'] ==81.099998, 'balcony'] = 8.1
df.loc[df['balcony'] ==71.32, 'balcony'] = 7
df.loc[df['balcony'] ==306, 'balcony'] = 3.6
df.loc[df['balcony'] ==116, 'balcony'] = 11.6
df.loc[df['balcony'] > 900, 'balcony'] = 0
再度データの概要を見てみます。
display(df.describe())
display(df.describe(exclude='number'))

データ件数は17,950件になりました。
3.6 駅別乗降客数の取得
駅名をダミー変数として学習に用いると量が多くなるなあと思ったので、今回は駅名からその駅の1日あたりの乗降客数を付与することにしました。また、乗降客数をそのまま用いると、乖離が大きくなるので、説明変数には乗降客数の対数を用いることにします。
手順
- 東京都の駅別の1日あたりの乗降客数データを取得(※こちらの「オープンポータル (オープンデータ活用サイト、競売、人口、駅)」からcsvファイルを取得させていただきました。(2022年7月時点))
- 駅毎に乗降客数を集計。(取得データは路線・駅別なので、JR新宿駅と小田急線新宿駅で分かれている)
- 中古マンション販売情報の最寄駅とマッチングさせて、乗降客数を付与します。(※一部の最寄駅には乗降客数がマッチングしなかったので、手動で補正しました。(例:高輪ゲートウェイの乗降客数データがなかったり、「阿佐ヶ谷」が「阿佐ケ谷」となっていてアンマッチしていたり、最寄駅が東京都の駅でなかったりです。))
#SUUMOから取得したデータの駅名を抽出。(457駅)
station_df = pd.DataFrame(df['station'].unique(),columns=['station_name'])
#display(station_df)
#東京都の1日あたりの駅別乗降客数データを取得
#こちらのHPからcsvファイルを取得させていただきました。(2022年7月時点) → https://opendata-web.site/station/13/
#元ネタは国土数値情報ダウンロードサービスで 2021年7月8日 に公開された駅別乗降客数(2020年 令和2年度)
pass_num_df = pd.read_csv(f'{PATH_MYDRIVE}/csv_pref_13_best.csv', encoding='shift-jis')
pass_num_df = pass_num_df[pass_num_df['順位'] != '-'] #乗降客数が入っていない行は削除
pass_num_df['乗降客数'] = pass_num_df['乗降客数'].astype(int) #int型に変換
display(pass_num_df['駅名'].duplicated().sum()) #路線別の駅名があり、駅名は106行重複している
g = pass_num_df.groupby("駅名", as_index=False) #駅名で集計
pass_num_df = g.sum()
#中古マンションデータにあった駅名とマッチング
station_df2 = pd.merge(station_df, pass_num_df, left_on='station_name', right_on='駅名', how='left')
#マッチングしなかった最寄駅について手補正
station_df2.loc[station_df2['station_name']=='虎ノ門ヒルズ', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='虎ノ門', '乗降客数']) #虎ノ門駅で代替
station_df2.loc[station_df2['station_name']=='高輪ゲートウェイ', '乗降客数'] = (int(pass_num_df.loc[pass_num_df['駅名']=='品川', '乗降客数']) + int(pass_num_df.loc[pass_num_df['駅名']=='田町', '乗降客数']))/2 #品川と田町の間ということで平均値を取りました
station_df2.loc[station_df2['station_name']=='千駄ケ谷', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='千駄ヶ谷', '乗降客数'])
station_df2.loc[station_df2['station_name']=='市ケ谷', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='市ヶ谷', '乗降客数'])
station_df2.loc[station_df2['station_name']=='押上', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='押上(スカイツリー前)', '乗降客数'])
station_df2.loc[station_df2['station_name']=='谷塚', '乗降客数'] = int(30081)
station_df2.loc[station_df2['station_name']=='とうきょうスカイツリー', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='押上(スカイツリー前)', '乗降客数'])
station_df2.loc[station_df2['station_name']=='八潮', '乗降客数'] = int(20477)
station_df2.loc[station_df2['station_name']=='舞浜', '乗降客数'] = int(38395)
station_df2.loc[station_df2['station_name']=='阿佐ケ谷', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='阿佐ヶ谷', '乗降客数'])
station_df2.loc[station_df2['station_name']=='西ケ原', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='西ヶ原', '乗降客数'])
station_df2.loc[station_df2['station_name']=='南阿佐ケ谷', '乗降客数'] = int(pass_num_df.loc[pass_num_df['駅名']=='南阿佐ヶ谷', '乗降客数'])
#元の中古マンションデータに乗降客数を付加
df = pd.merge(df, station_df2, left_on='station', right_on='station_name', how='left')
#「乗降客数」のカラムをリネーム
df = df.rename(columns={'乗降客数': 'n_passenger'})
#対数をとったカラムも作成します
df['log_n_passenger'] = np.log10(df['n_passenger'])
4.データ可視化:概観を確認
4.1 販売価格の分布
plt.figure(figsize=(15,5))
plt.title('販売価格のヒストグラム')
sns.distplot(df['price'])
おおよそ4000万円前後の物件が最も多いようですね。

4.2 専有面積の分布
plt.figure(figsize=(15,5))
plt.title('専有面積のヒストグラム')
sns.distplot(df['area'])
専有面積は60㎡あたりにピークがあるようです。

4.3 築年数の分布
plt.figure(figsize=(15,5))
plt.title('築年数のヒストグラム')
sns.distplot(df['age'])
築40年を超えたところにピークがありますね。築30年あたりの物件数は少なくなっているんですね。この時期はマンションの建築数が少なかったのか、この辺りの物件は売りに出されにくいのでしょうかね。。

4.4 区別の物件販売数
#日本語表示
japanize_matplotlib.japanize()
#区別の物件数を確認
plt.figure(figsize=(15,5))
plt.title('区別物件販売数')
sns.countplot(y='ward', data=df, order = df['ward'].value_counts().index)
物件数は港区、江東区、世田谷区の順になっていました。逆に、千代田区は物件が少ないですね。

4.5 区別の販売価格
order_index = df.groupby('ward').median()['price'].sort_values(ascending=False).index
plt.figure(figsize=(8,8))
plt.title('区別販売価格の箱ひげ図')
sns.boxplot(x="price", y="ward", data=df, order = order_index)
港区、千代田区、中央区の順に販売価格の上位となっています。

4.6 築年数別の販売平均価格
plot = df.groupby('age', as_index=False).mean()
plt.figure(figsize=(15,5))
sns.barplot(x='age', y='price', data=plot)
やはり築年数が上がるとともに、販売平均価格も下がる傾向にありますね。築20年から築30年あたりで販売平均価格がグッと下がり、その後は緩やかに下がっているように見えますね。

4.7 専有面積・築年数・販売価格
sns.relplot(data=df, x="area", y="price", size="age", hue="age")
専有面積が大きくなると、販売価格も高くなる傾向は見えますね。

では、次は販売価格の予測モデルを構築していきます。
5.予測:中古マンションの販売価格予測モデルの構築
今回は重回帰分析、ランダムフォレスト回帰、LightGBM、マルチパーセプトロン(ディープラーニング)でモデルを構築してみました。 (※現時点、私にはハイパーパラメータをうまくチューニングするスキルはありません。そこは温かい目で見てください)
5.1 学習データの準備
学習に使うデータを準備していきます。
今回は最寄駅までの徒歩時間、バス乗車時間、専有面積、バルコニー面積、築年数、リノベーションの有無、リフォームの有無、一日あたりの乗降客数の対数、行政区、路線を説明変数として、販売価格を予測します。行政区と路線はダミー変数化して使います。
#display(df.head())
X = df[["walk_time", "bus_time","area", "balcony", "age","renovation","reform","log_n_passenger","ward","line"]]
y = df['price']
# 区と路線をダミー変数化(One-Hot_Encodingで変換)
X = pd.get_dummies(X, columns= ["ward", "line"])
#訓練データ検証データに分ける(9:1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.1, random_state=0)
5.2 重回帰分析
### 重回帰分析
model = LinearRegression()
model.fit(train_X, train_y)
#訓練データと検証データでの決定係数を確認
print('LinearRegression train score : {}'.format(model.score(train_X, train_y)))
print('LinearRegression test score : {}'.format(model.score(test_X, test_y)))
# 予測値と実際の値を可視化して確認
pred_y = model.predict(test_X)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
出力結果は以下の通り。訓練データと検証データについていずれも決定係数は0.8弱くらいでした。
LinearRegression train score : 0.7986167634026528
LinearRegression test score : 0.7896758222895618
こちらは縦軸に予測値、横軸に実際の販売価格として、プロットしたものです。予測値が0円より低くなっているものもありますね。。。

5.3 ランダムフォレスト回帰
次にランダムフォレスト回帰を見てみます。
# モデル作成
rfr = RandomForestRegressor(random_state=0)
model = rfr.fit(train_X, train_y)
#訓練データと検証データでのスコアを確認
print('RandomForest train score : {}'.format(model.score(train_X, train_y)))
print('RandomForest test score : {}'.format(model.score(test_X, test_y)))
# 特徴量の重要度を確認
fti = rfr.feature_importances_
print('Feature Importances:')
for i, feat in enumerate(train_X.columns):
if fti[i] >= 0.01:
print('\t{0:10s} : {1:>.6f}'.format(feat, fti[i]))
# 予測値と実際の値を可視化して確認
pred_y = model.predict(test_X)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
出力結果は以下の通りです。訓練データと学習データで決定係数に差が出ており、過学習しているようですが、検証データの決定係数は重回帰分析よりも高く0.9は超えました。本当は過学習の対応をするチューニングをするべきなのでしょうが、本記事ではここまでです。
また、特徴量の重要度が大きいものを確認しました。専有面積、築年数の重要度が高く、ついで港区。その他にも、乗降客数や徒歩距離、渋谷区などが重要度が高めでした。
RandomForest train score : 0.9877444625180167
RandomForest test score : 0.9098652059786696
Feature Importances:
walk_time : 0.040408
area : 0.418918
balcony : 0.027236
age : 0.207803
log_n_passenger : 0.051984
ward_中央区 : 0.010179
ward_千代田区 : 0.010736
ward_新宿区 : 0.010948
ward_渋谷区 : 0.044129
ward_港区 : 0.079927
ward_足立区 : 0.015252
重回帰分析に比べると45度の角度に多く集まっており、誤差が小さくなっています。実際の販売価格が大きい方が誤差も大きいです。

5.4 LightGBM
十分に勉強できていませんが、LightGBMでの予測モデルも作成してみました。
#モデル構築
gbm_reg = lgb.LGBMRegressor(objective='regression', n_estimators=500)
model = gbm_reg.fit(train_X, train_y, eval_set=[(test_X, test_y)], eval_metric='l2', verbose=0)
#訓練データと検証データでのスコアを確認
print('LGB train score : {}'.format(model.score(train_X, train_y)))
print('LGB test score : {}'.format(model.score(test_X, test_y)))
# 特徴量の重要度を確認
fti = gbm_reg.feature_importances_
print('Feature Importances:')
for i, feat in enumerate(train_X.columns):
if fti[i] >= 100:
print('\t{0:10s} : {1:>.6f}'.format(feat, fti[i]))
# 予測値と実際の値を可視化して確認
pred_y = model.predict(test_X)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
出力結果は以下の通り。
検証データでの決定係数が0.929となりました。特徴量の重要度(頻度)では、専有面積、築年数、バルコニー、乗降客数が高く出ています。
LGB train score : 0.9719164815383786
LGB test score : 0.9297117378953533
Feature Importances:
walk_time : 1413.000000
area : 3612.000000
balcony : 2434.000000
age : 2455.000000
log_n_passenger : 2205.000000
ward_新宿区 : 106.000000
ward_渋谷区 : 143.000000
ward_港区 : 199.000000
ランダムフォレストよりもばらつきが小さくなりました。

5.5 (お試し)マルチパーセプトロン(ディープラーニング)
少し勉強を始めたディープラーニングを試してみました。
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Dropout, Input, BatchNormalization
from sklearn.metrics import mean_squared_error,r2_score
# 出力結果の固定
tf.random.set_seed(0)
model = Sequential()
model.add(Dense(128, input_dim=train_X.shape[1])) #input_dimに説明変数の数
model.add(Activation("relu"))
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dropout(rate=0.1))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(1))
# 損失関数にmse、最適化関数にadamを採用
model.compile(loss='mse', optimizer='adam')
# モデルを学習
history = model.fit(train_X, train_y, epochs=100 , batch_size=32 , verbose=0, validation_data=(test_X, test_y) )
# 予測値を出力
pred_y = model.predict(test_X)
#R2(決定係数)を計算
r2 = r2_score(test_y,pred_y)
print("R2(決定係数) : %.6f" % (r2))
# epoch毎の予測値の正解データとの誤差を表しています
# バリデーションデータのみ誤差が大きい場合は過学習
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(loss)
plt.plot(range(epochs), loss, marker = '.', label = 'loss')
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.show()
出力結果は以下の通り。
決定係数は0.893でした。チューニングによって高まるものと思いますが、本記事ではここまでです。。
R2(決定係数) : 0.893484
以下ご参考ですが、epoch毎の予測値の正解データとの誤差です。


今回は一番性能が高かったLightGBMのモデルを使っていきたいと思います。
6.予測:お得な物件探し
一番性能がが良かったLightGBMの回帰モデルを使って予測値を計算し、お得な物件を探してみました。今回は、お得度を 実際の販売価格÷予測価格 で計算しています。値が低い方がお得。
(※あくまで個人的な試みであり、販売価格に対してご意見するものではありません。)
#元データに予測値を結合
pred_y = pd.DataFrame(model.predict(X) ,columns=['pred'])
df_price_pred = pd.concat([df, pred_y], axis=1)
#お得度を「実際の販売価格÷予測価格」で計算。低い方がお得
df_price_pred['price_value'] = df_price_pred['price'] / df_price_pred['pred']
df_price_pred = df_price_pred.sort_values(['price_value'])
display(df_price_pred[['name', 'price', 'pred', 'price_value']].head())
出力結果は以下の通り。
今回のモデルで最もお得な5件がでました。いくつかみてみます。

1軒目はこちらになります。
専有面積が98.13㎡で4LDK、築32年、駅まで徒歩7分の物件で3,300万円です。感じ方は人それぞれだと思いますが、私はとてもお得だなあと思いました。

2軒目はこちら。
専有面積がなんと204.3㎡で6LDK、築42年ですが、駅まで徒歩7分の物件で6,490万円です。バルコニーも41.49㎡もあって、洗濯物も干し放題ですね。

3軒目はこちら。
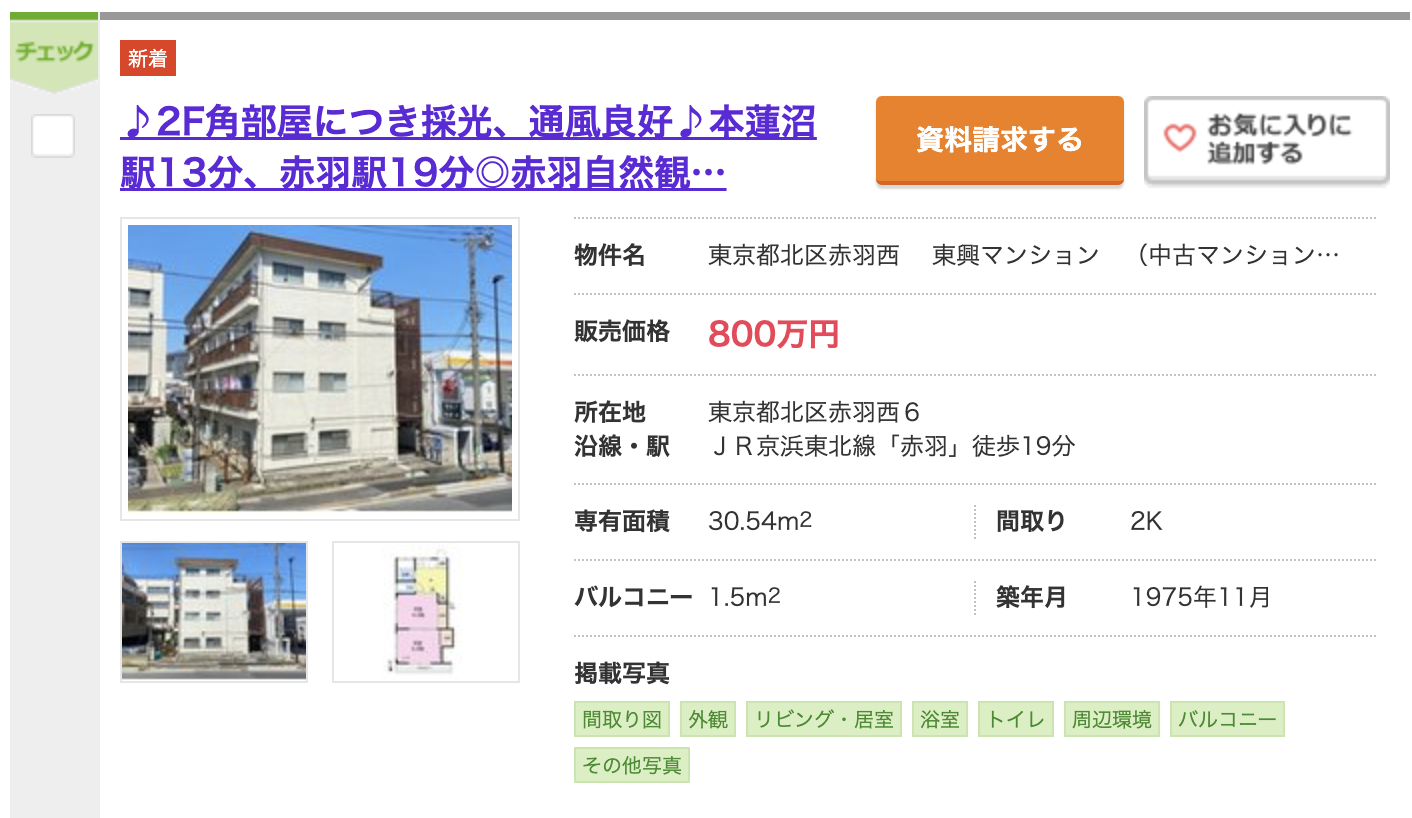
専有面積は30.54㎡で2K、築47年で、駅までは徒歩19分かかりますが、800万円という価格にお得感を感じます。
終わりに
今回はSUUMOさんのホームページから中古マンション販売情報をスクレイピングさせていただき、その情報をもとに販売価格予測を行ってみました。
感想としては、不慣れなスクレイピングと、やはりデータの前処理に時間がかかりました。仕方がないことですが、入力ミスのデータもあり、手動で対応する部分もありました。また、今回いくつかの手法で予測モデルを構築してみましたが、ハイパーパラメータのチューニングなど十分にできていませんので、この辺りはこれからも勉強を続けていきたいと思います。(あと、もっとキレイなコードを書けるようにならないといけない。。。)
長くなってしまいましたが、本記事は以上にしたいと思います。
ありがとうございました!!!