この記事について
この記事は、独学で書籍や Web 上の情報をみながらタイタニックデータの機械学習モデル作成を実施した内容のまとめです。以下の内容について記載しています。
- 前処理(欠損値の補完、型変換、binning)
- 様々な機械学習ライブラリでモデルを作成
- 交差検証
- グリッドサーチ(ハイパーパラメータのチューニング)
パッケージの import
各工程で共通して使用するパッケージです。これらをまず import します。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
前処理
データを読み込みデータフレーム化
データを読み込み、データフレーム化します。ここでは、input ディレクトリ下にタイタニックの訓練、テスト用データを置いているものとします。
df_train = pd.read_csv('input/train.csv')
df_test = pd.read_csv('input/test.csv')
前処理の内容と意図
前処理を実施します。訓練、テストデータに対して、以下の処理を実施しています。
- 型が int でないものは int に変換
- 欠損値を補完。Age, Fare は上記メソッドを使用し、Embarked は最頻値で埋める
- binning
- 新しい特徴量 FamilySize, IsAlone の作成
それぞれの意図は次の通りです。
型変換
機械学習ライブラリによっては int に変換しないと学習処理ができないためです。
欠損値の補完
機械学習ライブラリによっては欠損値がある状態だと学習処理ができないためです。ただし、ライブラリによっては欠損値ありでも処理できるものもあります。
binning
年齢のような幅広い値をとる特徴量を、固定数の bin に分割する処理です。binning によって幅広い分布を持ったものからカテゴリ化されたものに変換されます。よって、例えば年齢の場合は、年齢としてではなくどの年齢層かを、機械学習のライブラリに対して伝えやすくする意図があります。
新しい特徴量の作成
生存率と強い結びつきがある特徴量を作れるとモデルの正答率も上げることができます。要は生存率をくっきりと浮かび上がらせるような特徴量を作ることを目指します。データ生成の背景や現場知識があると、より効果的な特徴量を作ることができます。
欠損値補完用の関数を用意
欠損値補完用の関数を用意します。のちにデータフレームに対して、apply メソッドを実行することで呼び出して使用します。欠損値を含まない場合は何もせず元の値を返却します。欠損値がある場合は、客室クラスの平均値で補完するようにしました。
def impute(pclass, elem, pclass_dict):
"""欠損値の補完"""
if pd.isnull(elem):
return pclass_dict[pclass]
else:
return elem
def impute_age(cols):
"""Age の欠損値を補完"""
pclass=cols[1]
age=cols[0]
pclass_age = {1: 39, 2: 30, 3: 25}
return impute(pclass, age, pclass_age)
def impute_fare(cols):
"""Fare の欠損値を補完"""
pclass = cols[1]
fare = cols[0]
pclass_fare = {1: 84.254687, 2: 20.662183, 3: 13.675550}
return impute(pclass, fare, pclass_fare)
前処理のソースコード
コードは以下の通りです。
for dataset in df_train, df_test:
# - Sex -
# 型変換(object → int)
dataset['Sex'] = dataset['Sex'].map({'male': 0, 'female': 1})
# - Age -
# 欠損値を客席クラスの平均で補完
dataset['Age'] = dataset[['Age', 'Pclass']].apply(impute_age, axis = 1)
# binning
dataset['CategoricalAge'] = pd.qcut(dataset['Age'], 4, labels=False)
# - Embarked -
# 欠損値を最頻値の S で埋める。
dataset.loc[dataset['Embarked'].isnull(), 'Embarked'] = 'S'
# 型変換(object → int)
dataset['Embarked'] = dataset['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
# - Fare -
# 欠損値を客席クラスの平均で補完
dataset['Fare'] = dataset[['Fare', 'Pclass']].apply(impute_fare, axis = 1)
# binning
dataset['CategoricalFare'] = pd.qcut(dataset['Fare'], 4, labels=False)
# 新しい特徴量 FamilySize を作成
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
# 新しい特徴量 IsAlone を作成
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
不要な特徴量をドロップします。
for dataset in df_train, df_test:
dataset.drop(['PassengerId', 'Name', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Ticket'], axis=1, inplace=True)
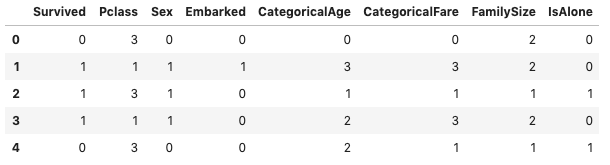
上記コードを実行すると、データフレームは以下の内容になります。
df_train.head()
様々な機械学習ライブラリでモデルを作成
ここでは複数の機械学習ライブラリを作成します。
まずは、学習させるために、訓練データと訓練ラベルを用意します。
X_train = df_train.drop(['Survived'], axis=1)
y_train = df_train['Survived']
今回の使用する機械学習ライブラリを import します。
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
後々扱いやすくするために、辞書にしておきます。
clfs = {'random_forest': RandomForestClassifier(random_state=0),
'extra_trees': ExtraTreesClassifier(random_state=0),
'ada_boost': AdaBoostClassifier(random_state=0),
'gradient_boosting': GradientBoostingClassifier(random_state=0),
'xgboost': XGBClassifier(random_state=0)
}
学習をします。
for k, clf in clfs.items():
clf.fit(X_train, y_train)
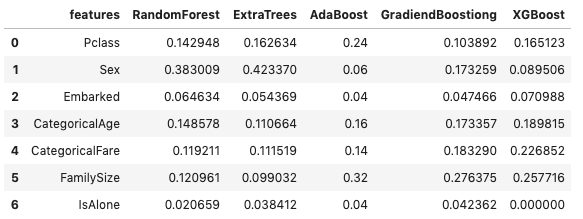
学習後は feature_importances_ 属性に特徴量の重要度が格納されています。各ライブラリの特徴量の重要度を見やすくするためにデータフレーム化してみます。
feature_dataframe = pd.DataFrame( {'features': X_train.columns,
'RandomForest': clfs['random_forest'].feature_importances_,
'ExtraTrees': clfs['extra_trees'].feature_importances_,
'AdaBoost': clfs['ada_boost'].feature_importances_,
'GradiendBoostiong': clfs['gradient_boosting'].feature_importances_,
'XGBoost': clfs['xgboost'].feature_importances_,
})
次のようなデータフレームができました。
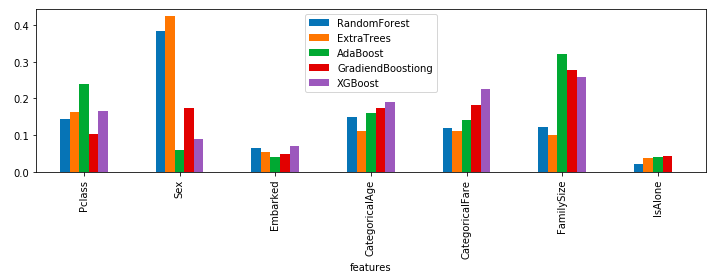
棒グラフにすると以下の通りです。ライブラリによって、重要視された特徴量が結構異なっていることが見て取れます。
feature_dataframe.plot.bar(x='features', figsize=(12, 3))
交差検証
各モデルの正答率を評価するために交差検証を行います。交差検証とは、例えばデータを 3 分割し 2/3 のデータで訓練し、残り 1/3 のデータでテストすることで正答率を出します。3 分割した場合は、訓練データ、テストデータの選び方は 3 通りあるので、それぞれの正答率を求めます。
まず、パッケージを import します。
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
次に交差検証し、結果を表示します。
for k, clf in clfs.items():
scores = cross_val_score(clf, X_train, y_train)
print(f'{k:<18}: {np.round(scores * 100, 1)}, '
+ f'average={round(scores.mean() *100, 1)}')
結果は以下の通り。機械学習のライブラリによって正答率に違いが出ていることがわかります。
random_forest : [76.1 81.8 80.1], average=79.3
extra_trees : [76.1 83.5 78.8], average=79.5
ada_boost : [76.8 82.2 80.1], average=79.7
gradient_boosting : [78.5 84.8 80.1], average=81.1
xgboost : [78.5 83.8 81.5], average=81.3
グリッドサーチ(ハイパーパラメータのチューニング)
実務においては単に正答率の高さを見るだけでなく、適合率、再現率など目的に沿った指標に基づいて判断が必要かと思いますが、ここでは上記の交差検証で最も高い正答率を出した XGBoost のハイパーパラメータをチューニングします。
グリッドサーチを使います。指定したパラメータ値の組み合わせを総当たりで試して最も高い正答率を出すパラメータを探す手法です。
まず、パッケージを import します。
from sklearn.model_selection import GridSearchCV
試したいパラメータを parameters の辞書で設定します。GridSearchCV のインスタンスを作成し、fit メソッドを実行することで、パラメータの組み合わせに対して交差検証が実行されます。
parameters = {
'max_depth': [4, 5, 6, 7],
'gamma': [0,5, 1, 2, 4, 10],
}
clf = XGBClassifier(random_state=0)
grid_search = GridSearchCV(clf, parameters, scoring='accuracy', cv=3)
grid_search.fit(X_train, y_train)
なお、上記コードを実行して大量の Warning が出力される場合があります。
DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
その場合は、以下のコードを実行しておきます。こちらの issue の問題のようです。
import warnings
warnings.filterwarnings(action='ignore', category=DeprecationWarning)
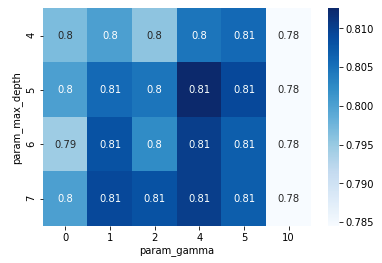
グリッドサーチをして全てのパラメータの組み合わせのなかで最も良いスコアだった組み合わせは best_params 属性に格納されています。
print(grid_search.best_params_)
{'gamma': 4, 'max_depth': 5}
パラメータの組み合わせごとの交差検証結果の分布を見ることもできます。
df_cv_results = pd.DataFrame(grid_search.cv_results_)
df_precision = df_cv_results.pivot(index='param_max_depth', columns='param_gamma', values='mean_test_score')
sns.heatmap(df_precision, annot=True, cmap='Blues')
また、最も良い結果のパラメータの組み合わせで学習したモデルは best_estimator_ 属性に格納されています。これを使って交差検証してみます。
kf = KFold(n_splits=3)
scores = cross_val_score(grid_search.best_estimator_, X_train, y_train, cv=kf)
print(f'{np.round(scores * 100, 1)}, '
+ f'average={round(scores.mean() * 100, 1)}')
[80.1 81.1 80.1], average=80.5
結果はデフォルトのパラメータよりも悪くなっています・・。ただ、上記の手続きにより様々な組み合わせを試すことで良いパラメータを探っていきます。
参考文献
最後に、参考にさせていただいた書籍を紹介させていただきます。
技術書典で巡り合った書籍です。探索的データアプローチのやり方や考え方、新しい特徴量の作り方などの一連の流れを体系だって学ぶことができる書籍です。
書籍後半の章で特徴量エンジニアリング、交差検証、グリッドサーチについて記載されています。