そもそも、パーティションって何者?
BigQueryは数ペタバイト以上のデータを扱います。
めっちゃいっぱいのデータから検索するより、少しでも検索対象減らしたほうがパフォーマンス出るよね。
でも、シャーディングしちゃうと、テーブルいっぱい出来ちゃうし、検索のときにはJOINしなくちゃいけなくなるよね。
じゃあ、1つのテーブルの中で分けちゃえばいいんじゃない?
・・・ってことで用意された機能だと思っています。
何で分割するか、については以下3種類があります。
- 取り込み時間
- 日付/タイムスタンプ (任意の列を指定)
- 整数列 (任意の列を指定)
パーティションに関する詳細は以下をご参照ください。
検証したいこと
- パーティションテーブルの作成の方法
- パーティションっていつ反映されるの?
- パーティションの有効期限が切れたらどうなるの?
※なお、今回は 日付/タイムスタンプ によるパーティション分割に関して検証します。
※あと、今回はパーティションの挙動に関してをメインに扱うため、
BigQueryについてやCloudSDKなどについての説明は端折っています。
検証その1:パーティションテーブルの作成方法
まずはどうやって作成したらパーティションテーブルが作成されるか、ですね。
以下を参考に実際にやってみます。
公式ドキュメント:日付/タイムスタンプパーティション分割テーブルの作成
https://cloud.google.com/bigquery/docs/creating-column-partitions?hl=ja
空テーブルの作成
テーブルの作成方法はいろいろありますが、CLIでやっていきます。
以下、schema.jsonを用意します。
スキーマ(列)定義ですね。
なお、その下のbqコマンドにて直接スキーマを定義することもできます。
ただ、その場合descriptionとmodeの指定はできませんので注意してください。
※デフォルトのmodeはNULLABLE(空白許容)みたい
[
{ "description": "id", "mode": "REQUIRED", "name": "id", "type": "INTEGER" },
{ "description": "受注日", "mode": "REQUIRED", "name": "order_date", "type": "TIMESTAMP" }
]
以下のコマンドでテーブル作成します。
$ bq mk -t \
--expiration 86400 \
--schema schema.json \
--time_partitioning_field order_date \
--time_partitioning_expiration 1800 \
--require_partition_filter \
--description "Timestamp partition example" \
--label org:dev \
sample.date_part
<コマンド解説>(*は必須)
-
*
-t:mkがmakeの意味っぽい。テーブルを作成するよ。(--tableと書くこともできます) -
expiration: テーブル自体の有効期限(秒で設定)
ex) 1日 ✕ 24時間 ✕ 60分 ✕ 60秒 = 86400秒 -
*
schema: スキーマファイルの指定(ここに)直接スキーマを記載するのでもOK -
*
time_partitioning_field: どの列をパーティション列にするかの指定 -
time_partitioning_expiration: パーティションの有効期限(秒で設定:expiration参照) -
require_partition_filter: クエリのときは絶対にパーティションを使ってね、の指定 -
description: 説明。 -
label: ラベル -
sample.date_part:で、最後のこれは [データセット名].[テーブル名]
検証その2: パーティションっていつ反映される?&有効期限が切れたら?
次にデータを投入していきます。
いつから反映されるんだろね。
ストリーミング挿入
まずは投入データを用意します。
テーブルを作成するタイミングで、order_date列がパーティションの基準列として設定しました。
ので、order_timeにいろんな日付を入れてみた。
{ "id": 1, "order_date":"2020-05-10 00:00:00" }
{ "id": 2, "order_date":"2020-05-10 09:00:00" }
{ "id": 3, "order_date":"2020-05-11 00:00:00" }
{ "id": 4, "order_date":"2020-05-11 09:00:00" }
{ "id": 5, "order_date":"2020-05-12 00:00:00" }
{ "id": 6, "order_date":"2020-05-12 09:00:00" }
{ "id": 7, "order_date":"2020-05-13 00:00:00" }
{ "id": 8, "order_date":"2020-05-13 09:00:00" }
{ "id": 9, "order_date":"2020-05-14 00:00:00" }
{ "id": 10, "order_date":"2020-05-14 09:00:00" }
{ "id": 11, "order_date":"2020-05-15 00:00:00" }
{ "id": 12, "order_date":"2020-05-15 09:00:00" }
で、このjsonファイルのデータをストリーミング挿入。
コマンドはこちら。
$ bq insert \
--ignore_unknown_values \
sample.date_part data.json
<コマンド解説>
-
--ignore_unknown_values: ここに書いてないカラムは無視してね。
今回は2列しか作ってないのですが、たとえ3列以上あったとしても、これでもエラーにならない。
ただ、追加したカラムのmodeがREQUIREDになってる場合はエラーになるかも。 -
sample.date_part data.json: お察しの通り。
[データセット名].[テーブル名] [データを定義したjsonファイル名]
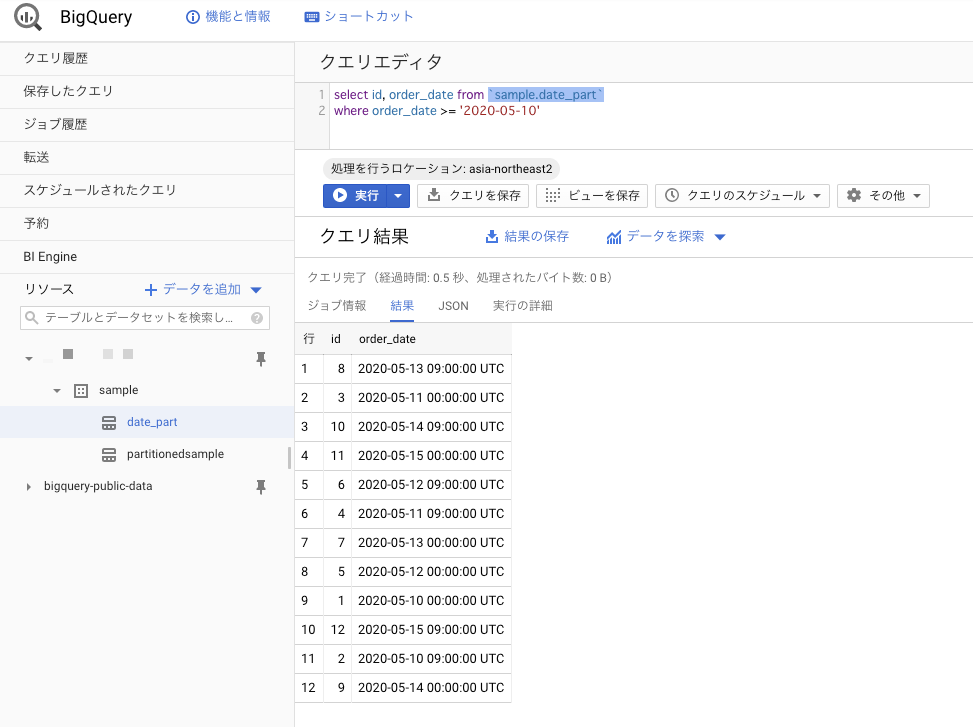
じゃ、はいったかどうか、画面で確認します。
・・・入ってますね。
ちなみに、テーブル作成時にrequire_partition_filterオプションをつけているので
検索時のSQLにwhere order_date ~ をつけないと、こんなエラーが吐かれます。

Cannot query over table 'sample.date_part' without a filter over column(s) 'order_date' that can be used for partition elimination(パーティションの操作?に使用できる列 'order_date'に対するフィルターがないと、テーブル 'sample.date_part'に対してクエリを実行できません)
せっかくパーティション分割してるんだから使ってよね、ってことですね。
でも、これだけだと、ちゃんとパーティションが生きているかわかりません。
というわけで、以下のコマンドでパーティションが作成されているのかどうかを確認します。
このコマンドはレガシーSQLらしい。
$ bq query --use_legacy_sql=true
'SELECT * FROM
[sample.date_part$__PARTITIONS_SUMMARY__]'
Waiting on bqjob_r2943b8070b183bd3_0000017211f87bec_1 ... (0s) Current status: DONE
+-----------------+------------+-----------+-------------------+---------------+---------------------+--------------------+-------------------------+
| project_id | dataset_id | table_id | partition_id | creation_time | creation_timestamp | last_modified_time | last_modified_timestamp |
+-----------------+------------+-----------+-------------------+---------------+---------------------+--------------------+-------------------------+
| sandbox-xxx | sample | date_part | __UNPARTITIONED__ | 1589439354838 | 2020-05-14 06:55:54 | 1589439354874 | 2020-05-14 06:55:54 |
+-----------------+------------+-----------+-------------------+---------------+---------------------+--------------------+-------------------------+
・・・ん?
partition_id列に__UNPARTITIONED__(分類されていない)しかいない。。。
よくよく公式を読んでみた。
データがストリーミングされると、過去 7 日間と将来の 3 日間のデータがストリーミング バッファに置かれ、対応するパーティションに抽出されます。この範囲外のデータ(ただし過去 1 年、将来 6 か月の範囲内)は、ストリーミング バッファに配置され、次に UNPARTITIONED パーティションへ抽出されます。パーティショニングされていないデータが十分蓄積されると、対応するパーティションに読み込まれます。
参考: パーティション分割テーブルへのストリーミング
わかった。
ストリーミングだと、すぐにパーティションは反映されない、ということが。
じゃあ、普通にINSERT文で入れたらどうなるのか。
クエリで INSERT
(かっこいい言い方が分からないけど、わかりやすいでしょ)
というわけで、地道にINSERT文を書く。
$ bq query \
--use_legacy_sql=false \
'INSERT INTO `sample.date_part`
(`id`, `order_date`)
VALUES
(101, "2020-05-10 00:00:00" )
,(102, "2020-05-10 09:00:00" )
,(103, "2020-05-11 00:00:00" )
,(104, "2020-05-11 09:00:00" )
,(105, "2020-05-12 00:00:00" )
,(106, "2020-05-12 09:00:00" )
,(107, "2020-05-13 00:00:00" )
,(108, "2020-05-13 09:00:00" )
,(109, "2020-05-14 00:00:00" )
,(110, "2020-05-14 09:00:00" )
,(111, "2020-05-15 00:00:00" )
,(112, "2020-05-15 09:00:00" )'
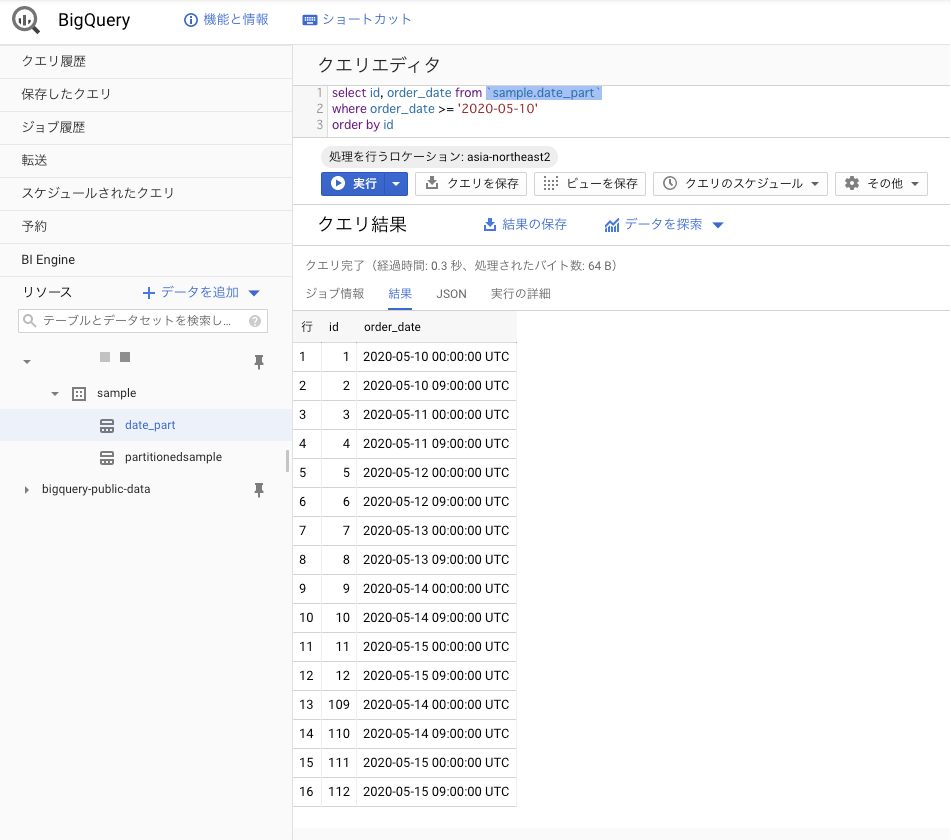
で、ストリーミングと同じように画面で確認する。
・・・ん?
入ってるけど・・・今度は数が足りない。
ストリーミングの後に同じテーブルに入れたからわかりにくいんだけど。
12件づついれたはずだから、合計24件になるはずが、16件しかない。
idが100番以降のデータがINSERTしたやつ。
4件しかないね。。。
コマンドでパーティションの状況を確認してみる。
$ bq query --use_legacy_sql=true '
SELECT * FROM
[sample.date_part$__PARTITIONS_SUMMARY__]'
Waiting on bqjob_r263f2dfc1c8dbd87_0000017211fdbac4_1 ... (0s) Current status: DONE
+-----------------+------------+-----------+-------------------+---------------+---------------------+--------------------+-------------------------+
| project_id | dataset_id | table_id | partition_id | creation_time | creation_timestamp | last_modified_time | last_modified_timestamp |
+-----------------+------------+-----------+-------------------+---------------+---------------------+--------------------+-------------------------+
| sandbox-xxx | sample | date_part | 20200510 | 1589439735966 | 2020-05-14 07:02:15 | 1589439736180 | 2020-05-14 07:02:16 |
| sandbox-xxx | sample | date_part | 20200511 | 1589439735966 | 2020-05-14 07:02:15 | 1589439736180 | 2020-05-14 07:02:16 |
| sandbox-xxx | sample | date_part | 20200512 | 1589439735966 | 2020-05-14 07:02:15 | 1589439736180 | 2020-05-14 07:02:16 |
| sandbox-xxx | sample | date_part | 20200513 | 1589439735966 | 2020-05-14 07:02:15 | 1589439736180 | 2020-05-14 07:02:16 |
| sandbox-xxx | sample | date_part | 20200514 | 1589439735966 | 2020-05-14 07:02:15 | 1589439736180 | 2020-05-14 07:02:16 |
| sandbox-xxx | sample | date_part | 20200515 | 1589439735966 | 2020-05-14 07:02:15 | 1589439736180 | 2020-05-14 07:02:16 |
| sandbox-xxx | sample | date_part | __UNPARTITIONED__ | 1589439354838 | 2020-05-14 06:55:54 | 1589439354874 | 2020-05-14 06:55:54 |
+-----------------+------------+-----------+-------------------+---------------+---------------------+--------------------+-------------------------+
めっちゃパーティションできてる。
20200510~20200513 のパーティションにはいってるはずのデータは
1) パーティションができて、
2) 有効期限切れになって(設定は 30分)
3) データごと消された
ってことか。
検証その2追加:ストリーミングされたデータはいつパーティション分割される?
現在、だいたい 2020/05/14 16:00 ごろ。
まだ反映されていない。
16:30 まだ
17:45 反映されてる
しまった。ちょっと他のことしている間に反映されてた。
というわけで、90分くらい経ったら反映はされるんですかね。
ドキュメントには一定のデータが溜まったら、となっていたけどどのくらい溜まったら反映されるのかも謎。。。
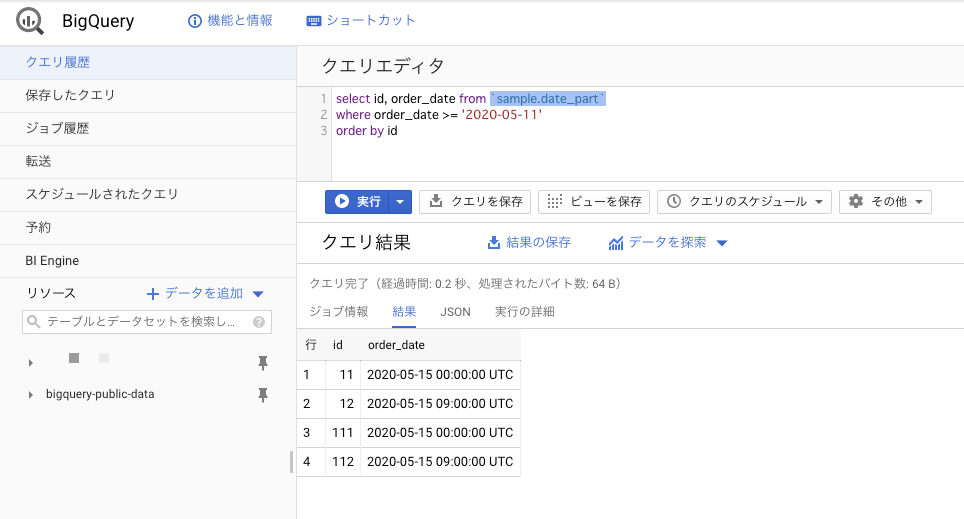
ちなみに、2020/05/15 10:00に確認するとこんな感じになっていた。
パーティションとしては存在しているけど、データは消されている。
※この時、昨日と同じくクエリを実行すると、キャッシュが効いているみたいで、14日のデータも出力されていた。
別の日付にするとキャッシュがきかなくて、15日だけの出力になった模様。
$ bq query --use_legacy_sql=true '
SELECT * FROM
[sample.date_part$__PARTITIONS_SUMMARY__]'
Waiting on bqjob_r74dfb65fa7411c0c_0000017215d85cc6_1 ... (0s) Current status: DONE
+-----------------+------------+-----------+--------------+---------------+---------------------+--------------------+-------------------------+
| project_id | dataset_id | table_id | partition_id | creation_time | creation_timestamp | last_modified_time | last_modified_timestamp |
+-----------------+------------+-----------+--------------+---------------+---------------------+--------------------+-------------------------+
| sandbox-akiando | sample | date_part | 20200514 | 1589439735966 | 2020-05-14 07:02:15 | 1589443792368 | 2020-05-14 08:09:52 |
| sandbox-akiando | sample | date_part | 20200515 | 1589439735966 | 2020-05-14 07:02:15 | 1589443792368 | 2020-05-14 08:09:52 |
+-----------------+------------+-----------+--------------+---------------+---------------------+--------------------+-------------------------+
結果
-
パーティションテーブルの作成の方法
CLIでのやり方は上の通り。 -
パーティションっていつ反映されるの?
クエリINSERTなら即時反映。
ストリーム挿入ならパーティション分割されるまで時間がかかる。(時間は不明) -
パーティションの有効期限が切れたらどうなるの?
データごと消される(涙)
参考
https://cloud.google.com/bigquery/docs/creating-column-partitions?hl=ja
https://cloud.google.com/bigquery/docs/schemas?hl=ja