初めに
この記事は、Julia Advent Calendar 2018 の1日目の記事です。
初日なので「Juliaとは?」とか「Juliaの最新事情!」とかそういった内容の記事にすべきかもしれないのですが、空気を読まずに 半分仕事関係(半分趣味)の話題を書きます1。
TL;DR
- Google Colaboratory で Julia 動いた!
- 〃 XLA.jl 動いた!
- 〃 Julia + TPU での学習はまだちょと辛い…
XLA.jl とは?
先日、arXiv.org という論文投稿共有サイトに Automatic Full Compilation of Julia Programs and ML Models to Cloud TPUs という論文が公開されました。
端的に言うと、「Julia の動的性をフルに活かして Google Cloud TPU 上で動くもの(主に Deep Learning の学習とか推論とか)を動かしてみた」という内容です。
その論文にサンプルコード片は載っていたのですが、その時は実装例は見つけられませんでした。
ですが先日、そのコアとなる部分のコードが GitHub で公開され(ているのを見つけ)ました。それが XLA.jl です。
GCPのアカウントを有効化していればすぐに試すことも出来ます(無料ではない)し、なくても Google カウントさえ持っていれば、取り敢えず Google Colaboratory(以下 Colabと略記)で最低限の動作確認もできます! しかも無料!
ということで、実際に Colab で XLA.jl を動かしてみました!
Colab で TPU を有効にして Julia を動かす
Colab で Julia が動くようにする
すでに先人のハッキングにより、Google Colab 上で Julia と IJulia をインストールすることで Julia のノートブックを開いて動作させることが出来ます!2
この仕組みを利用して、ただの Julia ではなく、XLA.jl その他のパッケージを導入済みの環境を作って動作させることも出来ます。
具体的な手順は、XLA.jl の README に書いてある通りです。簡単に概要を記述しておきます:
- InstallJuliaXLA.ipynb(XLA.jl が用意したノートブックファイル)を Colab 上でオープン する
- 「接続 ▼」の右端の「▼」をクリックし、「ホスト型ランタイムに接続」を選択、表示が「接続中…」→「接続済み」に変わるのを待つ
- 最初のコードセルを実行する
注意点として、上記の方法で notebook を colab 上でオープンしてそのまま実行しようとすると、以下のような警告が表示されます。
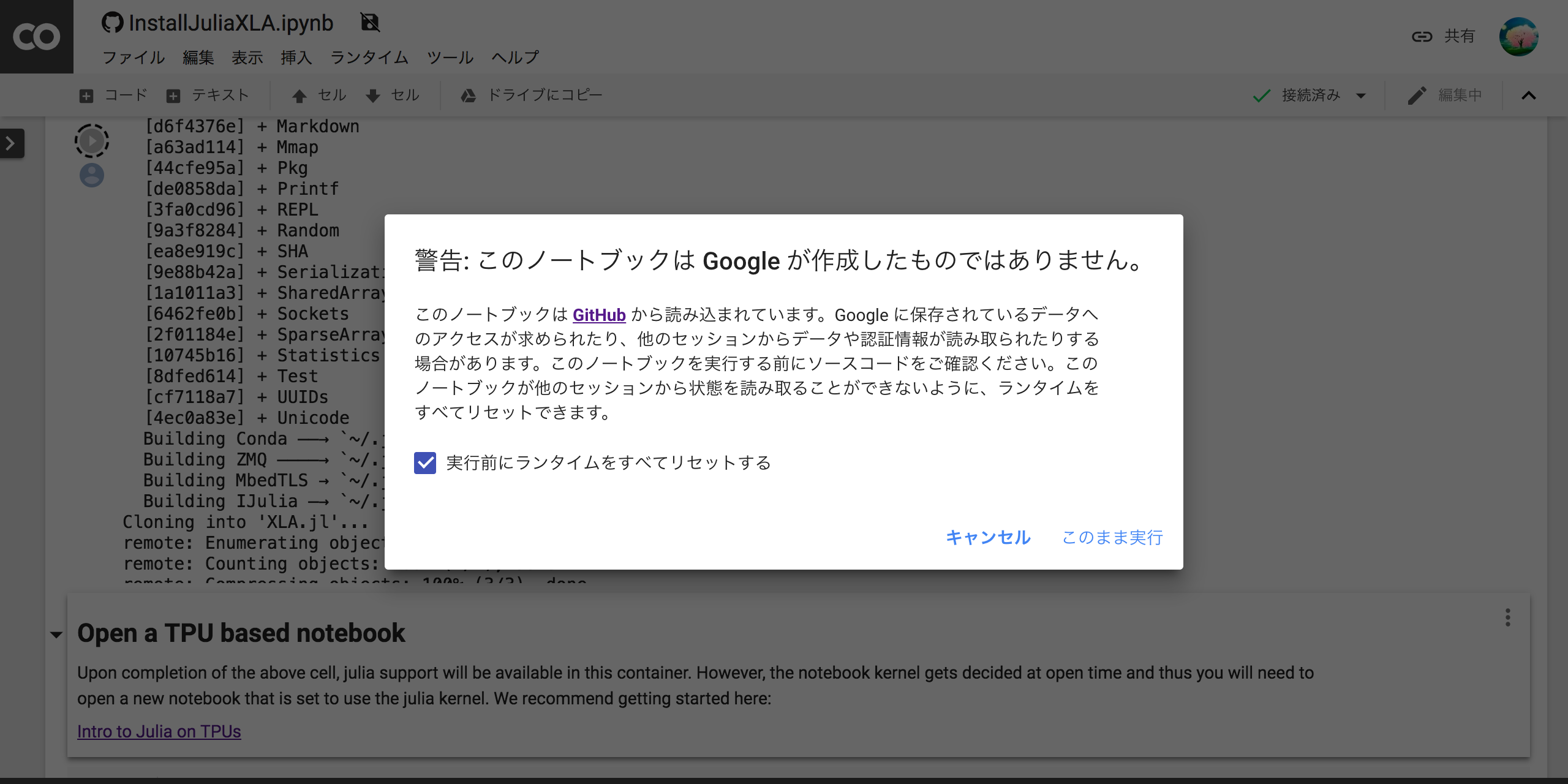
取り敢えず「![]() 実行前にランタイムをすべてリセットする」のチェックを付けたまま「このまま実行」をクリックすればOKです。
実行前にランタイムをすべてリセットする」のチェックを付けたまま「このまま実行」をクリックすればOKです。
もしくは、一度キャンセルして「ファイル」→「ドライブにコピーを保存…」してから実行すれば、警告は表示されずそのまま実行できます。
TPU を有効にした Julia の notebook を開く
続いて TPU 使用が有効になった状態の notebook を開く必要があります。
こちらもすでに雛型が用意されており、先ほど開いた「InstallJuliaXLA.ipynb」の下の方のリンク「Intro to Julia on TPUs」をクリックすればOK。
新しいタブで「JuliaTPU.ipynb」が開くと思います。
今度はこのファイルを色々編集するので、先ほど説明したとおり「ファイル」→「ドライブにコピーを保存…」を実行して、ご自分の Google ドライブ にコピーを保存してから実行しましょう。

コードセルを上から順に実行してみてください。
エラーが出ずに一通り実行できればOK。
("Activate the XLA compiler project" 節のコードセルは、コメントにも書かれているとおり割と(5分くらい)時間かかります。気長に待ちましょう。またいくつか WARNING が表示されますが気にしなくて大丈夫です)
肝となるのは、最後に実行する("Connect to the TPU" 節の)2つのコードセルです。順に解説します。
using TensorFlow
sess = Session(Graph(); target="grpc://"*ENV["COLAB_TPU_ADDR"])
TensorFlow.jl の機能を使って、Cloud TPU へのセッションを接続しています3。
ENV["COLAB_TPU_ADDR"] は、コンテナの環境変数 COLAB_TPU_ADDR に設定されているアドレスを取得しています。わざわざこう書いているのは、新しいランタイム(ホスト)に接続する度にアドレスが変わるからですね。
run(sess, TensorFlow.Ops.configure_distributed_tpu())
# => "\n\x03\x02\x02\x02\x10\x01\x18\b\"\x18\0\0\0\0\0\x01\0\x01\0\0\x01\x01\x01\0\0\x01\0\x01\x01\x01\0\x01\x01\x01"
TPU との接続設定をしているらしいです。
ドキュメントが見つからないので詳細不明です。
戻り値のバイナリ文字列も、解析していないので不明ですが、Status::OK(); の戻り値だと思われます。
とにかくエラーではなくこのバイト列が返ってくれば、無事TPUに接続できました!
TPU で何か計算させてみる
用意された JuliaTPU.ipynb はこれで終わりなので、空いているコードセルに実際に動かすコードを書いて何か実行してみましょう。
基本の流れは、「関数を書く」→「@tpu_compile マクロでコンパイルする」→「run(〜) で実行する」という感じ。
まずはコンパイルするところまで。
f(x) = x*x
data = XRTArray(rand(Float32,5,5))
f_compiled = @tpu_compile f(data)
f_compiled には、XLA.XRTCompilation という型のインスタンスが返ってきます。内容は、コンパイルされた関数のアドレス、引数の型情報、戻り値の型情報、といった感じのようです。
なお @tpu_compile f(data) というコードで実際の引数 data を渡しているように見えますが、実際にはこの変数に入っている値は利用していません、型の情報のみ利用しています。
では、これを実行してみましょう。
result_xrt = run(f_compiled, data)
# => 5×5 XRTArray{Float32,(5, 5),2}:
# 1.58015 2.46443 2.03454 1.20309 1.88146
# 1.31977 2.05313 1.87947 0.925927 1.49809
# 0.708691 1.70926 1.4994 0.889913 1.05901
# 0.903782 1.57549 1.35927 0.723185 1.20536
# 1.2778 1.81097 1.58336 1.20222 1.86314
↑出力値は一例です。
result_xrt には、XRTArray 型のオブジェクトが返ります。
型の詳細情報を見てみましょう:
dump(typeof(result_xrt))
# => XRTArray{Float32,(5, 5),2} <: AbstractArray{Float32,2}
# storage::XLA.XRTStorage{Float32,2}
<: AbstractArray{Float32,2} なので、32ビット浮動小数点数の2次元配列(行列)と互換性があります。
ある程度通常の配列と同等に扱えるようになっているように見えますが、実際にはこのままだと扱いにくいので、中身を取り出したり保存したりしたいときは一旦通常の配列に変換します。
result = convert(Array, result_xrt)
# => 5×5 Array{Float32,2}:
# 1.58015 2.46443 2.03454 1.20309 1.88146
# 1.31977 2.05313 1.87947 0.925927 1.49809
# 0.708691 1.70926 1.4994 0.889913 1.05901
# 0.903782 1.57549 1.35927 0.723185 1.20536
# 1.2778 1.81097 1.58336 1.20222 1.86314
ところで。この結果だけ見ると「本当にTPUで計算実行しているの?」と疑問に思われるかもしれません。
それを、ちょっとだけ感じる方法があります。
この関数をローカルで実行してみるのです。単純な計算なので結果は同じになるはずですよね?…
f(convert(Array, data))
# => 5×5 Array{Float32,2}:
# 1.5827 2.46311 2.03321 1.20028 1.88258
# 1.32179 2.0545 1.88101 0.924764 1.4995
# 0.709654 1.71077 1.50099 0.887963 1.06023
# 0.905574 1.57555 1.35924 0.721939 1.20704
# 1.27932 1.81105 1.58353 1.20211 1.86526
あれ? 全体的にほんの少しずつ異なる結果が出てしまいました。
でもこれで正解なのです。
TPUには十分な精度で効率良く高速にテンソル計算するための工夫が入っています。なので結果はCPU上で(BLASで)計算した結果と多少異なることがあるのです45。
Colab 上で MNIST を学習するしたかった
実際にTPU上で簡単な学習を実行してみましょう。
↑…と思って試していたのですが、どうもうまくいかなかったし先が長そうなので、基本的な動きだけ確認してみました。
モデル構築
以下は、MNIST の学習・推論のための簡単な3層MLP(3LP)モデルの例です。
using Flux
import Flux: glorot_uniform
# for Float32 Dense initialization
glorot_uniform(::Type{T}, dims...) where {T<:AbstractFloat} = (rand(T, dims...) .- T(0.5)) .* sqrt(T(24.0)/(sum(dims)))
function (::Type{Dense})(::Type{T}, in::Integer, out::Integer, σ = identity;
initW = glorot_uniform, initb = zeros) where {T<:AbstractFloat}
return Dense(param(initW(T, out, in)), param(initb(T, out)), σ)
end
_reshape_784x(x::AbstractMatrix) = x
_reshape_784x(x::AbstractArray) = reshape(x, 784, :)
model = Chain(
_reshape_784x,
Dense(Float32, 784, 128, relu),
Dense(Float32, 128, 64, relu),
Dense(Float32, 64, 10),
softmax
)
Flux.jl は、Julia で定番の DeepLearning フレームワークライブラリ(パッケージ)です。
XLA.jl には、Flux.jl で構築したモデルの XLA コンパイルを支援する機能も備えています。
なのでモデルは(自分で構築するなら)このように Flux.jl を使って構築すればOK6。
なお↑このコードは、型を指定してモデルを構築し、明示的に Float32 型でやり取りできるよう工夫を加えています。ただ XLA.jl でコンパイルする際にはこの工夫がなくても(Float64 でモデルを構築しても)問題なく動く模様です。
それでは次のステップ。
↑で作成した model(Flux.Chain 型のオブジェクト)を、XLA.ImmutableChain に変換します。
ic = ImmutableChain(model.layers...)
# typeof(ic): ImmutableChain{Tuple{typeof(_reshape_784x),Dense{typeof(relu),TrackedArray{…,Array{Float32,2}},TrackedArray{…,Array{Float32,1}}},Dense{typeof(relu),TrackedArray{…,Array{Float32,2}},TrackedArray{…,Array{Float32,1}}},Dense{typeof(identity),TrackedArray{…,Array{Float32,2}},TrackedArray{…,Array{Float32,1}}},typeof(softmax)}}
さらにこのモデルに含まれる各重み配列(Flux.TrackedArray)を XLA.XRTArray に変換します。
xrt(ic) = Flux.mapleaves(x->isa(x, AbstractArray) ? XRTArray(x) : x, ic)
xrtic = xrt(ic)
# typeof(xrtic): ImmutableChain{Tuple{typeof(_reshape_784x),Dense{typeof(relu),XRTArray{Float32,(128, 784),2},XRTArray{Float32,(128,),1}},Dense{typeof(relu),XRTArray{Float32,(64, 128),2},XRTArray{Float32,(64,),1}},Dense{typeof(identity),XRTArray{Float32,(10, 64),2},XRTArray{Float32,(10,),1}},typeof(softmax)}}
これの XRTAllocation というものを準備します。
ic_alloc = XRTAllocation(sess, XLA.struct_to_literal(xrtic))
# => XRTAllocation(Session(Ptr{Nothing} @0x00007f01f8bb3030), nothing, 4)
先ほどから度々出てくる XRT というのは、Google Cloud に用意されているサービスの1つで、XLA IR を受け取って低レベルのメモリ管理を提供するものです。
XLA.jl で、この XRT を利用するAPI類(型名)には皆 XRT〜 という prefix が付いています。XRTArray もそうですね、TPU 上でメモリ確保された配列、というワケです。
そして XRTAllocation というのは、もうそのものズバリ、TPU 上のメモリ確保そのものを管理する型のようです。
ここでインスタンス化された ic_alloc は後で何度か使用します。
forward(順伝播)
順伝播は、ほぼ普通の関数呼び出しだけなので、先ほど見た簡単なTPU上の計算実行とほぼ同じコードになります。
まずは、TPU上でコンパイル:
# ↓`batchsize` は事前に定義済(例:`batchsize = 1000`)
compiled_fwd = @tpu_compile xrtic(XRTArray(sess, randn(Float32, 28, 28, 1, batchsize)))
↑こちらは何ら新しいことはないですね。
続いて実行:
# ↓の `xrtx` は、28x28x1x1000 の Float32 配列
result_sample_xrt = run(compiled_fwd, ic_alloc, XLA.gethandle!(sess, xrtx))
# => 10×1000 XRTArray{Float32,(10, 1000),2}:《以下略》
ここが少し今までと違っています。
まず xrtic が単純な関数ではなく、所謂「呼び出し可能オブジェクト(Functor)」なので、それをコンパイルした compiled_fwd を run するときのその第2引数に先ほどの ic_alloc を渡す必要があるようです。関数のポインタを明示しているようなイメージですね。
また引数として渡すものもそのまま渡すのではなく、XLA.gethandle!(sess, xrtx) のようにしています、これも変数のポインタを渡しているようなイメージです。
これで実行は出来ている模様です。以下のようにすれば、各列が「MNISTの10クラスのどれを表しているか」を確認できます:
Flux.onecold(convert(Array, result_sample_xrt))
# => 8
# 8
# 8
# 8
# 8
# 8
# 8
# 8
# 8
# 8
# 8
# 5
# 7
# ⋮《以下略》
backward(逆伝播)
逆伝播は、もう少し煩雑になります。
まず、今まで出てこなかったもう1人の登場人物の助けを借ります。
using Zygote
function my_derivative(f, args...)
y, back = Zygote._forward(Zygote.Context{Nothing}(nothing), f, args...)
J = Δ -> Zygote.tailmemaybe(back(Δ))
return J(1f0)[1]
end
Zygote.jl は、コード→コードで自動微分を実行するパッケージです。
これを利用して、関数と引数を受け取り、適用結果の勾配を求める関数 my_derivative() をまず定義しています。
# The function we're going to differentiate. `sum` stands in for the loss function here.
function f(ic, x)
my_derivative(ic -> sum(ic(x)), ic)
end
my_derivative() に適用させる関数は「ImmutableChain を受け取ってそれに入力を適用した結果から計算される loss を返す関数」。
その「ImmutableChain」と「入力」を受け取って勾配を返す関数として f() を定義しました。これは「内部で順伝播を行って、その結果から逆伝播で勾配を求めて返す」という動きになります。
この f を @tpu_compile するわけです。
compld = @tpu_compile f(xrtic, xrtx)
そして実行します。実行方法は先ほどの順伝播の例で見たものと全く同様です。
result_backward_tuple_xrtremote = run(compld, ic_alloc, XLA.gethandle!(sess, xrtx))
# => Remote NamedTuple{(:layers,),Tuple{Tuple{Nothing,NamedTuple{(:W, :b, :σ),Tuple{XRTArray{Float32,(128, 784),2},XRTArray{Float32,(128,),1},Nothing}},NamedTuple{(:W, :b, :σ),Tuple{XRTArray{Float32,(64, 128),2},XRTArray{Float32,(64,),1},Nothing}},NamedTuple{(:W, :b, :σ),Tuple{XRTArray{Float32,(10, 64),2},XRTArray{Float32,(10,),1},Nothing}},Nothing}}}
ただ今回は、戻り値が XRTArray ではなく、XRTRemoteStruct というものになっています。これは速い話、配列ではない何らかの「Cloud TPU 上のメモリに乗っているオブジェクト(へのポインタ)」を表しています。
内容を取得するには fetch() 関数を利用します。
result_backward_tuple = fetch(result_backward_tuple_xrtremote)
# => (layers = (nothing, (W = …, b = …, σ = nothing), …《略》),)
このネストされた NamedTuple 中の、W とか b とかに、XRTArray として(それぞれ対応する重みやバイアスの)勾配が格納されています。
これらを元の model の各対応する layer の重みにうまく適用していけば、どんどん学習が進む、というわけです。
肝心の学習は…
ここまで出来ていれば、理論上は学習も出来ます。
ただ、このままではあまり現実的じゃない。問題がいくつかあります:
- (順伝播+)逆伝播の計算をTPU上で行い、その勾配をいちいちCPUに戻して適用してまたTPUに上げて、ということをすると、データ転送のオーバーヘッドが馬鹿にならない7
- 勾配を重みに適用する処理(=最適化処理)が用意されていないのでそれは現状自前で用意するしかない(単純なSGDならベタで書いても大した手間じゃないけれど…)
- XLA.jl 自体がまだまだ開発途上なので、たまに動作が怪しい8…
これらがうまく解決できれば(経済面もクリアされれば)、誰でも気軽にJulia+TPUで機械学習出来る日がやってくると思われます。将来に期待!
まとめに変えて
今回実行した「JuliaTPU.ipynb」のコピーは、Colab の「コピーを GitHub Gist として保存…」機能9を使って Gist に上げてあります。→ JuliaTPU.ipynb のコピー
この記事で紹介しきれなかった内容も含めて、一通り実験した内容がすべて保存されているので、興味があれば覗いてみてください。
参考
- 外部パッケージ:
- ブログ記事:
- 論文:
-
Automatic Full Compilation of Julia Programs and ML Models to Cloud TPUs
- XLA.jl に関する論文
-
Fashionable Modelling with Flux
- Flux.jl に関する論文
-
DON’T UNROLL ADJOINT: DIFFERENTIATING SSA-FORM PROGRAMS
- Zygote.jl に関する論文
-
Automatic Full Compilation of Julia Programs and ML Models to Cloud TPUs
-
この記事の内容は、ほぼブログ記事 "Julia at NIPS and the Future of Machine Learning Tools" からの受け売りです。 ↩
-
Qiita にもすでにその記事存在します→ Google Colab で Julia を使ってみた by @ueuema さん ↩
-
TPUに接続するためだけに TensorFlow を使うってどうよ? TF自体のダウンロード重いし。TF抜きでもっと手軽に利用できるようにはならないものかなー。 ↩
-
だからってさっきのがTPUで計算したという証拠にはならないのですが、、、まぁそこは取り敢えず信じてもらうしか
 ↩
↩ -
ちなみにこれは、対象が機械学習(Deep Learning)モデルならば、実用上問題にならないレベルの精度です。 ↩
-
もちろん自分で構築しなくても、例えば Metalhead.jl で用意されている定義済のモデルを利用することも出来ます。 ↩
-
XLA.jl を紹介している論文では、勾配適用も含めて指定した回数のループ全てをTPU上で実行している模様です。XLA.jl 内にそのサンプルコードも転がっているのですが、Colab では実行できない模様(GCPじゃないとたぶん実行できない(課金が…))。 ↩
-
例えば、Flux.jl で用意されている
Conv(畳み込み層)を利用しようとしたら@tpu_compileでエラーになったり、単純なwhileループを持つ関数を@tpu_compileしようとしたらエラーになったり…それで挫折しました ↩
↩ -
この機能を使うと勝手に
というリンクが追加されるみたいで、Gist 上でそれをクリックすると Colab で開けるようになっているみたいです。 ↩