はじめに
私は楽曲のコードを採譜して、Chordwikiという共有サイトに投稿しています。
その時に採譜の補助としてコード採譜アプリを使用しています。
使用していて以下のような問題がありました。
YAMAHAのChordTrackerは、簡単なコード進行であれば、それなりの精度で認識できます。
Chord aiは、ChordTrackerよりも高精度でコードを認識することができますが、コード進行が複雑だったり、コードが頻繁に変わるような場合は、うまく認識できないことがあります。
そこで、自分でより精度の高いコード認識AIを作ろうと思い、制作を開始しました。
この AI の開発過程で、精度を上げるためにどのような工夫をしたかについて紹介します。
最終的に完成した AI は Github 上に公開しています。
スペクトログラムに変換
音声データをモデルの入力として利用するためには、スペクトログラムに変換する必要があります。
生の音声データはサイズが大きいことや、効果的に特徴を抽出できない可能性があるためです。
変換の方法はいくつかありますが、今回はコード認識によく使われるCQT(Constant-Q Transform)を使用します。
CQTはSTFTに比べて入力データのサイズが小さく、周波数方向の情報がほぼ等しいためコード認識に適しています。
ピアノやベース、ギターなどコードの構成音を鳴らす楽器は、低域から中域の部分(C1 ~ C7)で鳴ります。そのため、低域から中域の部分の解像度が高いCQTのほうがいいのだと思います。
周波数方向の情報がほぼ同等と言いましたが、調整次第では低音域がつぶれてしまったりします。
以下の画像は音声データをCQTで変換したものです。
librosaで変換したものは低音域の解像度が高すぎて潰れてしまっています。
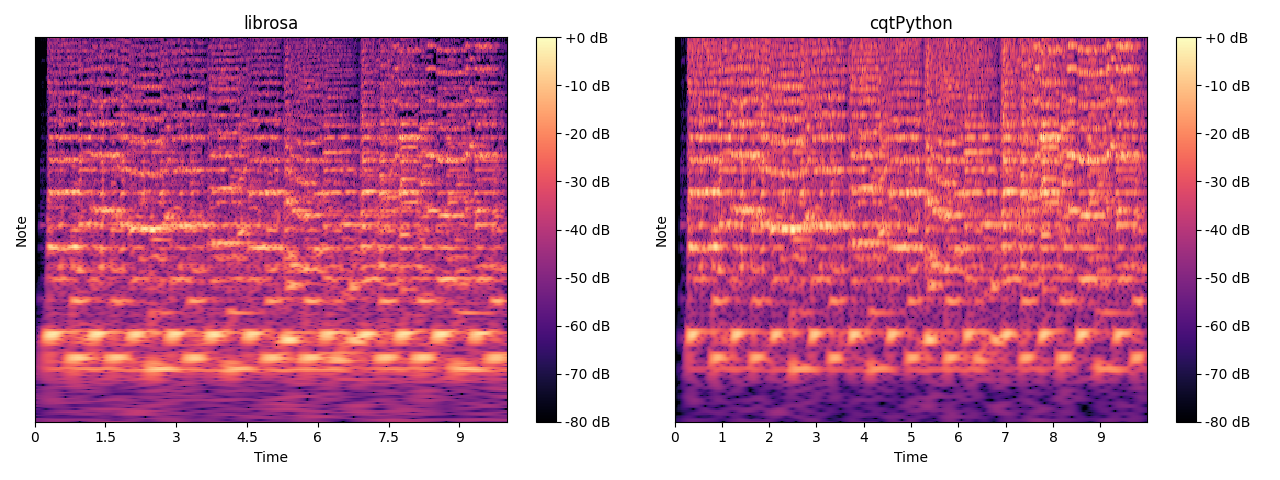
低音域の解像度は精度に影響するので調節が必要です。
librosaではfilter_scaleというパラメーターを調整することで、低音域の解像度を適切なレベルに調整することができます。
上記右の画像は調節後のもので、filter_scaleは0.69を利用しました。
オクターブあたりのビン数
CQT変換する際の1オクターブあたりの解像度を意味します。
オクターブあたりのビン数が12の場合、1オクターブは12音に分かれ、1オクターブあたり1の解像度で解析されます。
いろいろ試した結果、1オクターブあたり3の解像度が最適な値でした。これ以上高い解像度は、精度に貢献しません。
恐らく、1,2などでは細かなデータが抜け落ちてしまい、逆に4以上では複雑さが上がり、あまり精度に貢献しないのだと思います。
高い解像度は入力データのサイズも増加するため、保存するファイルの容量やモデルに使用するメモリも増加します。
それを加味して、1オクターブあたり3の解像度が最適だと思います。
データ保存
CQTは時間のかかる処理のため、事前に変換を行い、その結果をファイルに保存し、学習時に読み込みます。
モデルにデータを渡すときの工夫
データをモデルに入力する際は、バッチ内で同じ長さになるように切り出す必要があります。切り出す位置は、コードが変化する場所に合わせます。これは、ランダムに切り出すと精度の低下を引き起こすためです。
ランダムに切り出すことで精度が低下するのは、データの先頭がコードの途中になってしまうからです。
通常、コード変化後に構成音が演奏され、コードの途中ではベース音が動き、構成音も鳴らない場合もあるためです。
データ拡張
データ拡張のために周波数マスキング、時間マスキングを追加しています。
これはSpecAugmentから時間伸縮を除いたものです。
ピッチシフトをして、学習データを12倍に増やしています。
モデルが出力するもの
コード構成音ベクトル
コードを予測する際には、いきなりコードを出力するのではなく、コード構成音ベクトルを予測し、それに基づいてコードを予測しています。
これは、コードのデータはかなり不均衡なデータであり、ベクトルを出力する方が不均衡を軽減できるためです。
実際に予測するベクトルは、コード構成音とベース音を組み合わせたサイズ25のベクトルです。
以下は実際に予測したコード構成音ベクトルです。
多少のノイズや途切れはあるものの、はっきりとしたものが得られています。

平滑化したコード構成音ベクトル
コード構成音ベクトルは出力が粗く、不自然に途切れてしまうことがあります。
以下の画像は平滑化する前のコード構成音ベクトルです。
不自然に途切れている箇所がいくつかあります。

出力を滑らかにするために、まったく同じベクトルを再度予測します。
以下の画像は平滑化後のベクトルです。
不自然な途切れがなくなり、はっきりとしたものになっていると思います。

コード遷移確率
人の場合、コードチェンジの瞬間をほとんど見分けることができます。耳コピができる人は、ほぼ100%コードチェンジの瞬間を見分けることができると思います。
コードチェンジが分かるということは、その瞬間まではコードが変化せず一定とわかります。
それをAIに学習させようというわけです。
コードチェンジが発生する瞬間は、曲全体のデータと比べて数えるほどしかありません。そのため、不均衡になり、学習が難しくなります。
調 (キー)
曲を耳コピするとき、コード進行をヒントにすることがあります。「王道進行」や「2-5-1進行」などよく使われるものがあります。
キーがわかっていれば、コード進行のルールや音の関係性のようなものを把握できるかもしれません。そうなることを期待して、キーを予測します。
不均衡データ対策
コードや遷移確率などのデータはかなり不均衡になっています。
そのまま学習してもサンプル数が少ないものはうまく検出できません。
不均衡データに対応するために、focallossというloss関数を使用します。
簡単に検出ができるものの重みを下げ、難しいサンプルを重視するというものです。
これを導入することによって不均衡データでもうまく学習できるようにします。
コード遷移確率や調の損失関数にはfocallossを、コード構成音ベクトルにはfocallossとtverskylossを組み合わせたfocaltverskyを使用しました。
損失関数のパラメータは、混同行列を見て調整しました。これはデータセットに依存するので、微調整する必要があります。
def tversky(y_true, y_pred, alpha=0.5, smooth=1e-6):
# flatten label and prediction tensors
y_true = K.flatten(y_true)
y_pred = K.flatten(y_pred)
# True Positives, False Positives & False Negatives
TP = K.sum(y_true * y_pred)
FP = K.sum((1 - y_true) * y_pred)
FN = K.sum(y_true * (1 - y_pred))
return (TP + smooth) / (TP + alpha * FP + (1 - alpha) * FN + smooth)
def focal_tversky(alpha=0.75, gamma=1.0):
# gamma 1.0 が 通常と同じ
# gamma 1.0 以下は使用しない
def wrap(y_true, y_pred):
pt_1 = tversky(y_true, y_pred, alpha)
return K.pow((1 - pt_1), gamma)
return wrap
実際に使用するときはこんな感じです。
loss = [focal_tversky(alpha=0.4, gamma=3.0), ...]
gammaの値は高いほど難しいサンプルを優先します。
実際のモデル
CNNとLSTMを組み合わせたモデルです。
LSTM部分はOpen-Unmixという音源分離モデルを参考にして作成しました。
実際のコードの予測は、CRFを使って結果が滑らかになるように出力しています。
import tensorflow as tf
import tensorflow.keras.backend as K
from tensorflow.keras import layers as L
from tensorflow.keras.layers import Dense
from tensorflow_addons.layers import StochasticDepth, GroupNormalization
from tensorflow.keras.utils import get_custom_objects
from tensorflow.python.ops import variables as tf_variables
import tensorflow_addons as tfa
import numpy as np
DENSE_KERNEL_INITIALIZER = "he_normal"
DENSE_USE_BIAS = False
class FlattenChannelDimension(L.Layer):
def __init__(self, **kwargs):
super(FlattenChannelDimension, self).__init__(**kwargs)
def build(self, input_shape):
self.channels = input_shape[-1]
def call(self, inputs):
return L.concatenate(
[inputs[:, :, :, i] for i in range(self.channels)]
)
def get_config(self):
config = super(FlattenChannelDimension, self).get_config()
return dict(list(config.items()))
class BBB(L.Layer):
def __init__(self, **kwargs):
super(BBB, self).__init__(**kwargs)
def call(self, inputs):
inputs = [inputs[:, :, idx:idx + 36] for idx in range(0, 504, 36)]
return K.stack(inputs, axis=-1)
def get_config(self):
config = super(BBB, self).get_config()
return dict(list(config.items()))
class ChannelAttention(L.Layer):
def __init__(self, **kwargs):
super(ChannelAttention, self).__init__(**kwargs)
self.concat = L.Concatenate()
self.conv1 = L.Conv2D(
filters=1,
kernel_size=3,
activation="sigmoid",
padding="same",
use_bias=False,
kernel_initializer=DENSE_KERNEL_INITIALIZER)
self.mul1 = L.Multiply()
def call(self, inputs):
avg_pool = K.mean(inputs, axis=-1, keepdims=True)
max_pool = K.max(inputs, axis=-1, keepdims=True)
x = self.concat([avg_pool, max_pool])
x = self.conv1(x)
return self.mul1([inputs, x])
def get_config(self):
config = super(ChannelAttention, self).get_config()
return dict(list(config.items()))
@classmethod
def from_config(cls, config):
return cls(**config)
class SpatialAttention(L.Layer):
def __init__(self, ratio=8, **kwargs):
super(SpatialAttention, self).__init__(**kwargs)
self.ratio = ratio
def build(self, input_shape):
channels = input_shape[-1]
self.dense_1 = Dense(channels // self.ratio, activation='relu', use_bias=True, bias_initializer='zeros', kernel_initializer=DENSE_KERNEL_INITIALIZER)
self.dense_2 = Dense(channels, use_bias=True, bias_initializer='zeros', kernel_initializer=DENSE_KERNEL_INITIALIZER)
self.gap2d = L.GlobalAveragePooling2D()
self.reshape_1 = L.Reshape((1, 1, channels))
self.gmp2d = L.GlobalMaxPooling2D()
self.reshape_2 = L.Reshape((1, 1, channels))
def call(self, inputs):
avg_pool = self.gap2d(inputs)
avg_pool = self.reshape_1(avg_pool)
avg_pool = self.dense_1(avg_pool)
avg_pool = self.dense_2(avg_pool)
max_pool = self.gmp2d(inputs)
max_pool = self.reshape_2(max_pool)
max_pool = self.dense_1(max_pool)
max_pool = self.dense_2(max_pool)
x = L.Add()([avg_pool, max_pool])
x = L.Activation("sigmoid")(x)
return L.Multiply()([inputs, x])
def get_config(self):
base_config = super(SpatialAttention, self).get_config()
base_config.update({"ratio": self.ratio})
return dict(list(base_config.items()))
@classmethod
def from_config(cls, config):
return cls(**config)
class FReLU(L.Layer):
def __init__(self, **kwargs):
super(FReLU, self).__init__(**kwargs)
self.conv1 = L.DepthwiseConv2D(3, strides=(1, 1), padding='same', use_bias=False)
self.bn1 = L.BatchNormalization()
self.max1 = L.Maximum()
def call(self, inputs):
#T(x)の部分
x = self.conv1(inputs)
x = self.bn1(x)
#max(x, T(x))の部分
x = self.max1([inputs, x])
return x
def get_config(self):
config = super(FReLU, self).get_config()
return dict(list(config.items()))
@classmethod
def from_config(cls, config):
return cls(**config)
class WeightNormDense(L.Dense):
def build(self, input_shape):
super().build(input_shape)
self.g = self.add_weight(
name='g',
shape=[self.units,],
initializer='one',
dtype=self.dtype,
trainable=True)
def call(self, inputs):
kernel = self.kernel * self.g / K.sqrt(K.sum(K.square(self.kernel), axis=0))
output = K.dot(inputs, kernel)
if self.use_bias:
output = K.bias_add(output, self.bias)
if self.activation is not None:
output = self.activation(output)
return output
def get_config(self):
base_config = super(WeightNormDense, self).get_config()
return dict(list(base_config.items()))
Dense = WeightNormDense
# Squeeze and Excitation
def channel_spatial_squeeze_excite(inputs, ratio=8):
''' Create a channel-wise squeeze-excite block
Args:
input: input tensor
filters: number of output filters
Returns: a keras tensor
References
- [Squeeze and Excitation Networks](https://arxiv.org/abs/1709.01507)
'''
cbam = ChannelAttention()(inputs)
cbam = SpatialAttention(ratio=ratio)(cbam)
return cbam
def _add_lstm_layer(
n_layers,
hidden_size,
dropout=0.0,
bidirectional=True,
residual=False,
lstm_type="lstm"):
def wrap(input_layer):
layer = input_layer
for i in range(n_layers):
if lstm_type == "lstm":
lstm = L.LSTM(hidden_size, return_sequences=True, dropout=dropout)
elif lstm_type == "lnlstm":
lstm = L.RNN(tfa.rnn.LayerNormLSTMCell(hidden_size), return_sequences=True)
elif lstm_type == "peephole":
lstm = L.RNN(tfa.rnn.PeepholeLSTMCell(hidden_size), return_sequences=True)
if bidirectional:
pre_layer = L.Bidirectional(lstm)(layer)
else:
pre_layer = lstm(layer)
if i > 0 and residual:
layer = L.Add()([pre_layer, layer])
else:
layer = pre_layer
return layer
return wrap
def _dense(
input_layer,
hidden_size=128):
return Dense(
hidden_size,
use_bias=DENSE_USE_BIAS,
kernel_initializer=DENSE_KERNEL_INITIALIZER)(input_layer)
def _dense_bn_relu(
input_layer,
hidden_size=128,
activation=None,
name=None):
x = _dense(
input_layer,
hidden_size=hidden_size)
x = L.BatchNormalization()(x)
if activation:
if type(activation) == str:
x = L.Activation(activation, name=name)(x)
return x
def conv(filters, alpha=2, kernel_size=(3, 3), strides=(1, 1), droprate=0.5):
def wrap(inputs):
input_filters = int(inputs.shape[-1])
x = L.Conv2D(filters, kernel_size=kernel_size, strides=strides, padding="same", use_bias=False, kernel_initializer="he_normal")(inputs)
x = channel_spatial_squeeze_excite(x, ratio=8)
if alpha != 1:
x = L.Conv2D(filters // alpha, kernel_size=(1, 1), padding="same", use_bias=False, kernel_initializer="he_normal")(x)
if input_filters == filters // alpha:
x = StochasticDepth(droprate)([inputs, x])
return x
return wrap
class DualPathRNN(L.Layer):
def __init__(self, units, batch_size, dropout=0.1, **kwargs):
super(DualPathRNN, self).__init__(**kwargs)
self.units = units
self.batch_size = batch_size
self.dropout = dropout
def build(self, input_shape):
self.lstm_1 = L.Bidirectional(L.LSTM(self.units, return_sequences=True))
self.lstm_2 = L.Bidirectional(L.LSTM(self.units, return_sequences=True))
self.fc1 = L.Dense(self.units * 2)
self.fc2 = L.Dense(self.units * 2)
self.norm1 = L.LayerNormalization(center=False, scale=False)
self.norm2 = L.LayerNormalization(center=False, scale=False)
self.dropout1 = L.Dropout(self.dropout)
self.dropout2 = L.Dropout(self.dropout)
def call(self, inputs):
num_features = K.int_shape(inputs)[-1]
x = inputs
chunk_size = 256
x = tf.reshape(x, (-1, chunk_size, num_features))
x = self.lstm_1(x)
x = tf.reshape(x, (-1, self.units * 2))
x = self.fc1(x)
x = tf.reshape(x, (-1, chunk_size, self.units * 2))
x = self.dropout1(x)
x = self.norm1(x)
x = tf.reshape(x, (self.batch_size, -1, self.units * 2))
if K.int_shape(inputs)[-1] == K.int_shape(x)[-1]:
stage_1 = inputs + x
else:
stage_1 = x
x = self.lstm_2(stage_1)
x = tf.reshape(x, (-1, self.units * 2))
x = self.fc2(x)
x = tf.reshape(x, (self.batch_size, -1, self.units * 2))
x = self.dropout2(x)
x = self.norm2(x)
x = stage_1 + x
return x
def get_config(self):
base_config = super(DualPathRNN, self).get_config()
base_config.update({"units": self.units, "batch_size": self.batch_size})
return dict(list(base_config.items()))
@classmethod
def from_config(cls, config):
return cls(**config)
def chroma_net(
input_layer,
batch_size,
hidden_size=512,
stage_1_activation="tanh",
lstm_n_layers=1,
stage_2_activation="relu",
dropout=0.0,
dualRNN=False):
x = input_layer
if len(K.int_shape(input_layer)) > 3:
x = FlattenChannelDimension()(x)
x = BBB()(x)
# stem
x = L.Conv2D(24, kernel_size=(3, 3), strides=(1, 3), padding="same", use_bias=False, kernel_initializer="he_normal")(x)
x = conv(24, alpha=1, droprate=0.9)(x)
x = conv(24, alpha=1, droprate=0.9)(x)
x = conv(48, alpha=4, droprate=0.8)(x)
x = conv(48, alpha=4, droprate=0.8)(x)
x = conv(48, alpha=4, droprate=0.7)(x)
x = conv(64, alpha=4, droprate=0.6)(x)
x = conv(64, alpha=4, droprate=0.6)(x)
x = conv(64, alpha=1, droprate=0.6)(x)
x = FlattenChannelDimension()(x)
x = _dense_bn_relu(x, hidden_size, activation=stage_1_activation)
if dualRNN:
x = DualPathRNN(hidden_size // 2, batch_size)(x)
else:
x = _add_lstm_layer(
n_layers=lstm_n_layers,
hidden_size=hidden_size // 2,
bidirectional=True,
dropout=dropout)(x)
x = _dense_bn_relu(x, hidden_size, activation=stage_2_activation)
return x
def ChordNet(
input_shape=(None, (12 * 3 * 7), 2),
batch_size=8,
use_sam=False,
):
input_cqt = L.Input(shape=input_shape)
feature = chroma_net(input_cqt, batch_size,
hidden_size=512,
dualRNN=True)
chroma = _dense_bn_relu(feature, 25)
chroma = L.ReLU(1.0, name="chroma")(chroma)
transition = L.Dense(2, activation="softmax", name="trans")(feature)
music_key = L.Dense(25, activation="softmax", name="key")(feature)
bass = L.Dense(13, activation="softmax", name="bass")(feature)
smooth_chroma = chroma_net(feature, batch_size,
hidden_size=256,
dualRNN=False)
smooth_chroma = _dense_bn_relu(smooth_chroma, 25)
smooth_chroma = L.ReLU(1.0, name="smooth_chroma")(smooth_chroma)
chord = L.Dense(529, activation="softmax", name="chord")(smooth_chroma)
model = tf.keras.Model(
inputs=[input_cqt],
outputs=[chroma, transition, bass, smooth_chroma, music_key, chord])
return model
DualPathRNNは短い幅を見るLSTMと長い幅を見るLSTMを組み合わせた感じでしょうか。
追記
DualPathRNNは、ほとんど意味がないことに気づき、現在は普通のLSTMを利用しています。
混合行列
これが学習済みモデルで予測したコードの混合行列です。対角成分が濃いほど正確に予測できています。
一部を除いてほとんど正確に予測できていると思います。
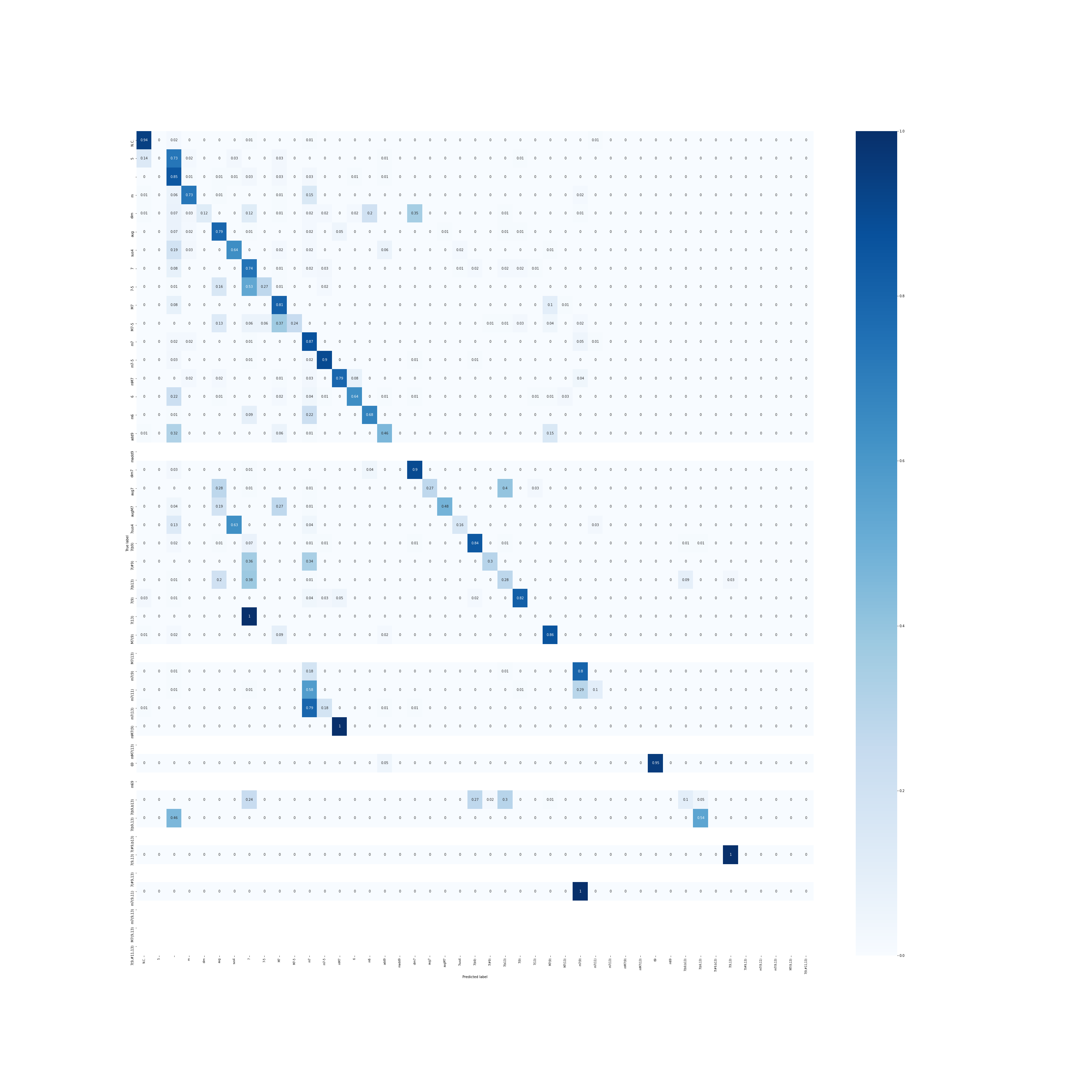
混合行列を見ながら手動で重みを調整すれば、先ほどよりも正確に予測ができます。
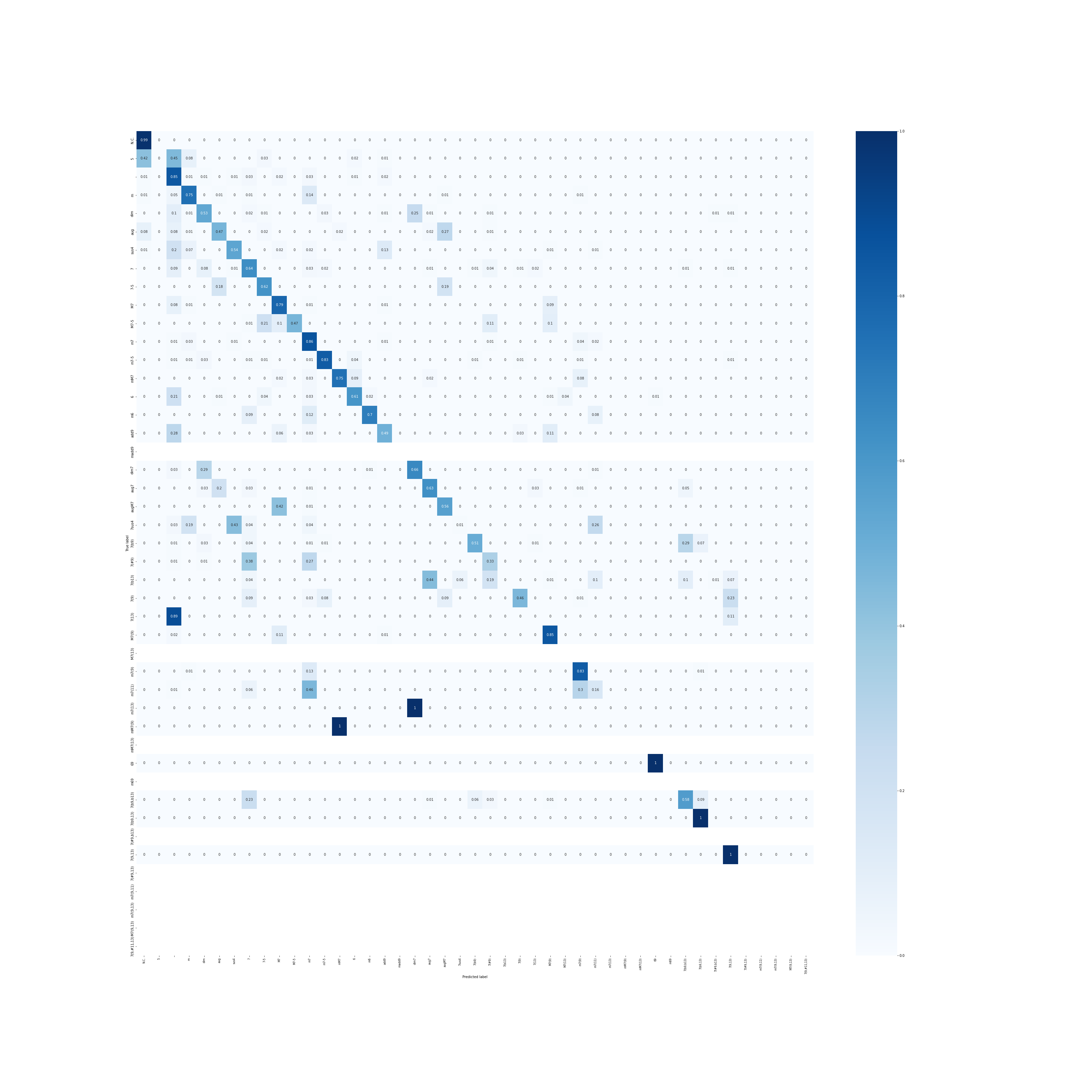
7sus4や7(13)、mM7(9)、m7(13)などが正しく予想できていませんね。
7sus4やm7(13)は、CキーでいうF/GやDm7/Gなど(9sus4?)で採譜してしまうことがあるのでその影響が出ていると思われます。mM7(9)は学習データに1件しかありません。
ちなみに真っ白な部分はテストデータに存在しないものです。
テストデータが足りていませんね...。複雑なコードの曲はあまりないのでデータに入れるのが大変です。
参考
【Python】不均衡な2クラスセグメンテーション問題に適用するロス関数のメモ
Tversky loss function for image segmentation using 3D fully convolutional deep networks
Focal Lossを提案した革新的物体検出モデルRetinaNetを解説!
[論文紹介] Focal Loss for Dense Object Detection