高速かつ高精度に物体検出を行う RetinaNet に使われている Focal Loss という損失関数を提案した論文を読んだので紹介します。
FAIR(Facebook AI Research) が書いた論文で ICCV 2017 に採択されています。

この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Reference
- Focal Loss for Dense Object Detection [Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár @ ICCV 2017]
- https://arxiv.org/abs/1708.02002
(文中の図表は論文より引用)
モチベーション
精度の良い object detector の多くは R-CNN1 ベースの two-stage object detector の構成を取っています。
そこで、 YOLO23 や SSD45 のような one-stage で高速に物体検出を行うネットワークが提案されてきました。
しかし、これらの one-stage detector は高速な一方で(当時の) state-of-the-art methods と比べると精度は劣るという課題がありました。
この論文では one-stage detector が two-stage detector と並ぶ精度を出せないのは「クラス間の不均衡」が原因であるという仮説をたてています。
画像のほとんどの pixel は background であり、foreground(背景以外のクラス)に属する pixel の数と比べると圧倒的な不均衡があるため、学習のほとんどが簡単な background 判定に支配されてしまいます。
(two-stage の場合は 1st stage で注目すべき部分を限定しているため、background の多くは 1st stage でフィルタリングされ、2nd stage は不均衡が解決された状態で学習することができます。)
そこで登場するのが Focal Loss です。
Focal Loss
Focal Loss は通常の cross entropy loss (CE) を動的に scaling させる損失関数です。
通常の CE と比較したのが次の図です。

通常の CE は以下のようなものです(binary cross entropy の場合)。
{\rm CE}(p_t) = -{\rm log}(p_t). \\
p_t = \left\{
\begin{array}{ll}
p & {\rm if}\: y = 1 \\
1 - p & {\rm otherwise.} \\
\end{array}
\right.
さきほどの図の γ = 0 の青い曲線は通常の CE を p を x 軸にグラフにしたものです。
図からわかるように、 0.6 といった十分に分類できている probability を出力したとしても、損失は無視できない値になっています。
そのため、簡単に background と分類できていても大量の exmaple が積み重なって、 foreground の損失よりも強くなってしまいます。
Focal Loss は、easy example (簡単に分類に成功している example)の損失を小さく scale します。
{\rm FL}(p_t) = -(1 - p_t) ^ \gamma {\rm log} (p_t).
γ はパラメータで、どのくらい easy example の損失を decay するかを決定します。
簡単に分類に成功している example では
(1 - p_t) ^ \gamma
が小さい値になるため、損失への寄与が小さくなります。
これによって、より難しい focus すべき example が学習に強く寄与できるようになります。
(論文中の実験では γ = 2 を採用しています。)
この論文では RetinaNet というアーキテクチャを設計し Focal Loss を用いて学習させています。
RetinaNet の設計の詳細は省きますが、精度を既存の object detector と比較したのが冒頭の図と次の表です。
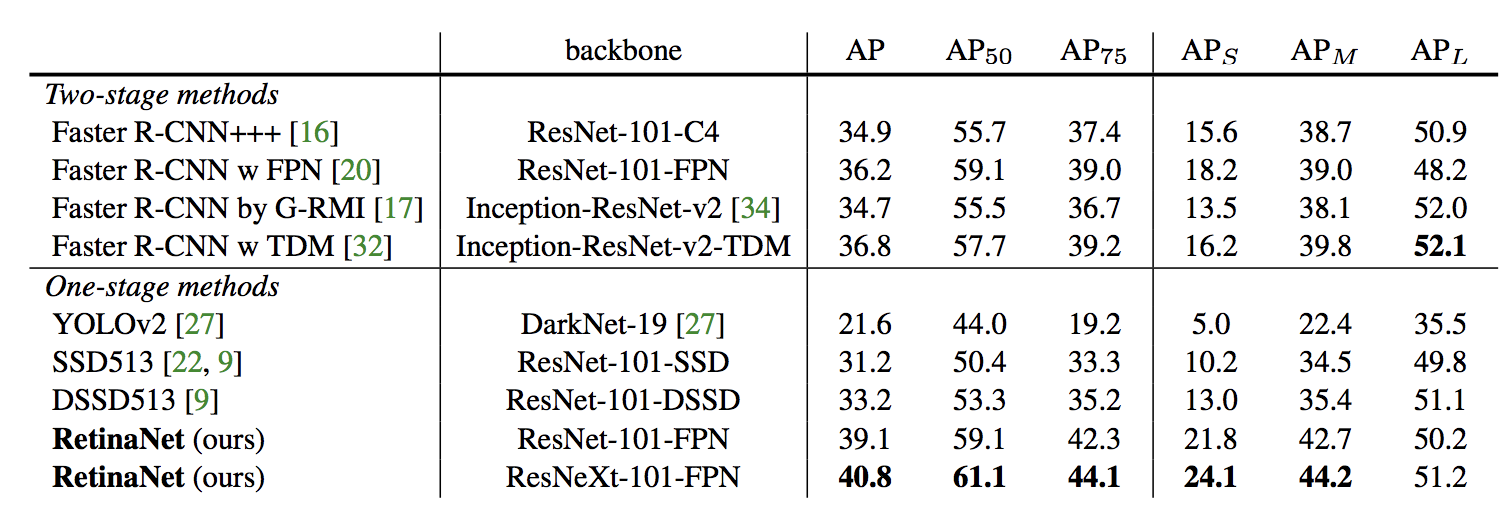
two-stage detector と同等(以上)の精度を達成しています。
感想
アイディアがシンプルで、 object detection 以外のタスクに対しても応用可能な手法ですごく好きな論文です。
実装も簡単なので試しやすく良い結果がでたので、何度かお世話になっています。
ちなみにこの論文のあとに書かれた YOLOv36 では Focal Loss を採用していませんが、 RetinaNet と精度・速度を比較していて Focal Loss に関する考察も書かれています。

また、facebook が公開している Detectron にも RetineNet の実装が含まれているので簡単に利用することもできそうです。
-
Rich feature hierarchies for accurate object detection and semantic segmentation [Ross Girshick, et al.]
R-CNN は、 まず物体のある bounding box の候補集合を提案し、その後 2nd stage で提案された各 box について classification を行うという構成になっています。
two-stage object detector は高い精度を記録していますが、一方で複雑さと推論速度に問題がありました。 ↩ -
You Only Look Once: Unified, Real-Time Object Detection [J. Redmon, et al.] ↩
-
YOLO9000: Better, Faster, Stronger [J. Redmon, et al.] ↩
-
SSD: Single Shot MultiBox Detector [W. Liu, et al.] ↩
-
DSSD : Deconvolutional Single Shot Detector [C.-Y. Fu, et al.] ↩
-
YOLOv3: An Incremental Improvement [J. Redmon, et al.] ↩