はじめに
導入
Linuxで使うbash等のシェルには、様々な○○置換という機能がありますが、その中でも「プロセス置換」( <(コマンド) や >(コマンド) ) というのはなかなかイメージし辛いのではないかと思います。
※特にコマンド置換 ( $(コマンド)や`コマンド` ) と名前が紛らわしいというのもあります。
これはパイプと機能的にも仕組み的にも近いものですので、この機会にパイプとの関連性も含め、仕組みを紹介したいと思います。
環境
bash,zsh共にプロセス置換の機能を持っていますが、以下ではbashを前提として仕組みを説明します。
なお、各動作確認は x86_64 WSL1(Win10)/Ubuntu18.04.2 LTS, bash4.4.19(1) で行っています。
プロセス置換の概要
利用目的
bash manページのプロセス置換の項にも説明はあるのですが、なかなかそれだけではイメージし辛いのではないかと思います。
そこで利用目的から把握するとなると、次のようになります。
- 2つ以上のプログラム間でデータをやり取りさせるために
- ユーザが一時ファイルを明示的に作ることなく
- かつ、データをやり取りする複数のプログラムを並行して動作させられる
- パイプラインよりも柔軟な使い方ができる機能
次の章で、実際の利用シーンを見てみます。
利用シーン
利用シーンとしては、データをやり取りするプログラムの内、「読み込みを行う方」「書き込みを行う方」どちらを主体として見るかで、2通りの使い分けがあります。
それぞれ、<( LIST ), >( LIST ) という記載を使い分けます。
※LISTの部分はコマンドリストであり、パイプ・リダイレクト含め一般のコマンドと変わりありません
読み込み主体
典型的な使い方としては、「コマンドを2つ実行したときのそれぞれの出力結果が同一内容か、あるいはどのような差分があるか、diffで確認する」が挙げられます。
この場合、読み込みを行う diff が主体ということです。
もしプロセス置換を使わない場合、次のようにリダイレクトを使うことが考えられます。この場合一時ファイル ( この場合 tmp1.out, tmp2.out ) を作る必要がありますし、diff を開始するには、それぞれのコマンド ( この場合 command1, command2 ) の終了を待つ必要があります。
$ command1 > tmp1.out
$ command2 > tmp2.out
$ diff tmp1.out tmp2.out
$ rm tmp1.out tmp2.out
これに対し、プロセス置換を使うと次のようになります。
$ diff <( command1 ) <( command2 )
使わない例に比較して、コマンドを1つにまとめてスッキリさせられるというメリットの他、ファイルを作らずに済む、並行動作が可能というメリットが生まれるのです。
実際に、tr と sed による英字の大文字化の効果が同じであることを diff + プロセス置換 で試した例が次のようになります。差分が出力されていないので、ちゃんと同じだと判断されていることが分かります。
$ hostname
angel
$ hostname | tr a-z A-Z
ANGEL
$ hostname | sed -e 's/.*/\U&/'
ANGEL
$ diff <( hostname | tr a-z A-Z ) <( hostname | sed -e 's/.*/\U&/' )
$
書き込み主体
もう一例、書き込み主体としては、tee によってリアルタイムで出力されるログにデータ加工をかけてファイルに保存するような、そういう用途も考えられます。
$ tee tmp.out
$ command < tmp.out > save.out
$ rm tmp.out
$ tee >( command > save.out )
tee を使う主目的は、標準出力経由でコンソール等にデータを出力させつつ、同一内容を別途ファイルに保存することですが、プロセス置換を使うことで「リアルタイムに」データを加工する用途に転換させられるのです。
パイプラインとの違い
「プログラム間のデータのやり取り」「一時ファイル不要」「並行動作」という意味では、各種シェルでサポートしている「パイプライン」という仕組みがあります。
実は、いずれもパイプという種類のファイルを活用するのは共通なのですが、その利用方法に違いがあります。
※パイプについては、「Linuxのファイルの種類」のパイプ(FIFOスペシャル) を参考にどうぞ。
※その他パイプを活用する機能としては、bash4のコプロセスのチュートリアルで取り上げた「コプロセス ( co-process )」もありますが、ここでは割愛します。
パイプライン
パイプラインのイメージ
パイプラインは、よく知られる通り command1 | command2 の形式でコマンドを指定することで、両者の標準出力・標準入力を同一のパイプに接続し、データのやり取りを可能にする機能です。
イメージとしては次の図のようになります。
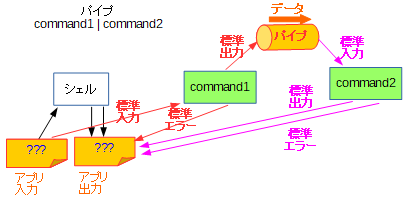
参考: 「標準入力・標準出力ってなに?」のリダイレクト・パイプライン
パイプラインの処理の流れ
実際にこれを実現するためには、シェルがプログラム実行に持ち込むまでに各種システムコールを駆使して、標準入力(ファイルディスクリプタ0番)・標準出力(ファイルディスクリプタ1番)をパイプに接続し直す処理を行います。
中でも鍵を握るのは、無名のパイプとそこに接続されたファイルディスクリプタを生成する pipe システムコールと、ファイルディスクリプタの複製を行う dup2 システムコールです。
以下、A | B というパイプラインを実行する時の処理の流れをまとめたものです。
※図中の○で表現されているのは、実際に(パイプを含む)ファイルに接続される、ファイルディスクリプタを表します
※一部余分な close コールが入っていますがそこは気にしないでください
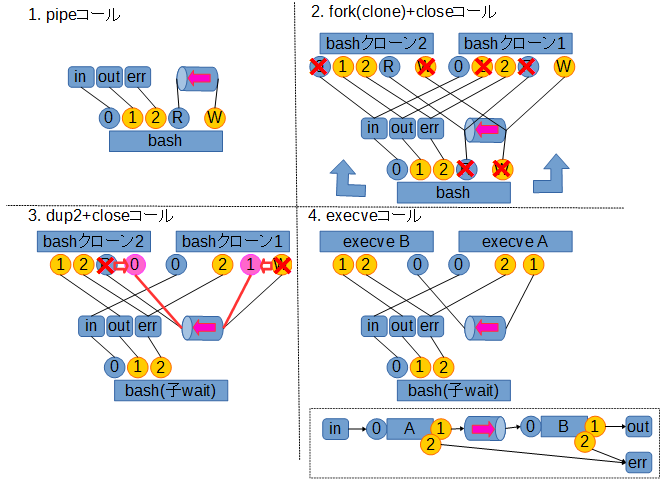
参考: 「1>/dev/null 2>&1と2>&1 1>/dev/nullの違い」へのご指摘の調査へのコメント
パイプラインの制約
このように、パイプを通じてデータをやり取りすることができるのですが、幾つかの制約があります。
- データの経路が直列のみ
A | B | C | …という形式で、直列にデータの流れを設けることはできますが、A→B と同時に A→C というように、複数並列にデータの経路を設けることができません - 標準入力・標準出力以外の手段がない
標準入力・標準出力を繋ぎなおすため、プログラム側で特別な対応なしに使うことができますが、逆にファイルを指定してデータをやり取りするプログラムでは使えません
このような制約のため、今回紹介しているプロセス置換の方がより柔軟に使えるという面があります。
プロセス置換
プロセス置換のイメージ
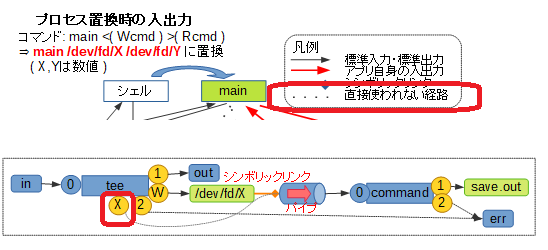
一方でプロセス置換を使った場合のデータの経路は、次のようなイメージになります。
これは、main <( Wcmd ) >( Rcmd ) というコマンド、2種類のプロセス置換を同時に使った場合のイメージです。
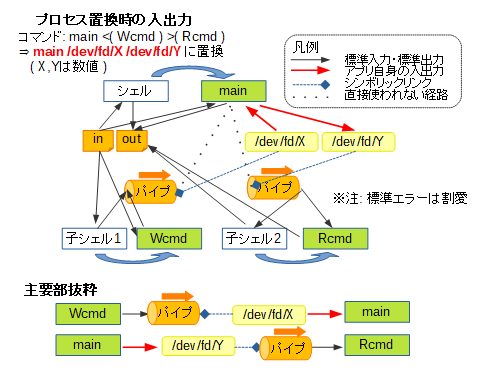
ここで次の注意点があります。
- 標準入力・標準出力のつなぎ替え
標準入力・標準出力のつなぎ替えが発生するのは、<( LIST ),>( LIST )で指定されたLIST部分を実行するための子シェル以降であり、主体となるコマンドでつなぎ替えが発生しないこと - 置換内容
<( LIST ),>( LIST )で指定された部分は、コマンド実行時には/dev/fd/X( Xはシェルが決めた数値 ) というファイル名に置き換えられること - シンボリックリンク
置換によって得られた/dev/fd/Xは、生成されたパイプへのシンボリックリンクとなること - 主体となるプログラムからの入出力
置換によって得られた/dev/fd/Xを入力あるいは出力に用いるのは、主体となるプログラム自身で行う必要がある、すなわち、主体となるプログラムは与えられたファイル名に基づき処理を行う機能を要すること
※ただし、この点はA < <( B )やA > >( B )のようにリダイレクトを併用することで、標準入力・標準出力での入出力に対応させることができます
なので、パイプラインとは大分使い勝手が変わってくることになります。
プロセス置換の処理の流れ
さて、この時どのように処理が行われるか、上で紹介した tee コマンドを例に挙げて見てみます。
まず前提として、tee を単純に使用した場合、コマンドライン引数として与えたファイルを tee 自身が open して使う、という点に注意が必要です。処理の流れは次のようになり、結果的に標準出力経由と、指定したファイルの両方にデータを出力することになります。
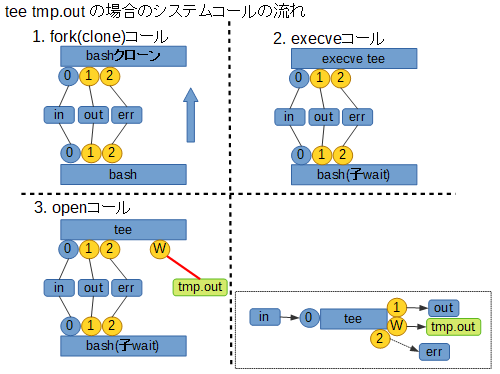
一方でプロセス置換を使った場合、パイプでの入出力経路が整えられた状態で各プログラムが起動されます。
その上で主体となる tee は、コマンドライン引数として ( 置換によって指定された ) /dev/fd/X を open することでパイプへの経路を確保します。
以下の図をご覧ください。

結局のところ、プロセス置換によるデータ連携は /dev/fd/X がパイプへのシンボリックリンクになっているから実現できることですが、シンボリックリンクの生成に tee自身はもちろんシェルも関与しません。これは後述しますが、Linux kernel の procfs の機能によるものです。
プロセス置換の特長と制限
上述のような処理を行うため、プロセス置換には次のような特長があります。
- 並列複数のデータ経路
置換を複数設けることで、並列にデータ経路 ( パイプ ) を複数設けることができます - ファイル名ベースでのアクセス
主体となるプログラムの方では、ファイル名ベースで入出力を扱う延長線上で、パイプへの入出力を行うことができます - パイプラインの解消
A | while read VAR; do シェル変数設定; doneのような複合コマンドとパイプラインが混在するケースの場合、途中で設定したシェル変数を大本のシェルに反映させることができません。これは、パイプラインを構成する各コマンドが子シェルの中で実行されるためです。
しかしこれを、while read VAR; do シェル変数設定; done < <( A )のプロセス置換に書き直してパイプラインを解消することで、大本のシェルに反映させられる形にできます
ただし、1点パイプラインの時と異なり、注意する点があります。
- プロセス置換で起動したプログラムの非同期性
パイプラインA | B | …については、シェルがまとめて1個のジョブとして扱い、A,B,… 全ての終了を待ち合わせた上でジョブの完了とします。また、個々のコマンドの終了ステータスもPIPESTATUSというシェル変数から取得することができます。
しかし、<( LIST )や>( LIST )で起動したLIST部分は非同期扱いとなるため、処理の完了待ちや終了ステータスの取得をシェルがサポートしてくれません。必要に応じて自前で対処を考える必要がでてきます。
procfsの機能
いくつかの疑問点
これまでプロセス置換の具体的な処理内容を見てきましたが、よくよく考えると疑問に思える出てくるかも知れません。
- シンボリックリンク名
/dev/fd/Xの衝突
異なるシェル上のプロセス置換でそれぞれ/dev/fd/Xのシンボリックを利用する際、名前が衝突して不都合が生じないか - 無名パイプへのシンボリックリンク
そもそもデータ連携に用いるパイプは無名ファイルであるところ、どうやってシンボリックリンクを作っているのか - 使われない入出力経路
これまでの画像に出てきた「直接使われない経路」や用途の不明なファイルディスクリプタ ( 図中 X で表されるもの ) は何のために存在しているのか
これらの点を解決しているのが、Linux kernel の持つ procfs の機能です。
procfsによるサポート
procfs は、タイプ proc によって /proc にマウントされる仮想的なファイルシステムです。
以下のように mount コマンドによってマウント状況を見ることができます。
$ mount -t proc
proc on /proc type proc (rw,nosuid,nodev,noexec,noatime)
procfsの機能は多岐に渡るため、詳細はproc(5)manページ等を参照いただくのが良いかと思いますが、プロセス置換については以下に挙げる機能が関わってきます。
- プロセスに応じて内容の変化する
/proc/self/
procfsは、/proc/プロセスID/というディレクトリ毎にプロセス情報へアクセスする各種仮想的なサブディレクトリ・ファイルを管理していますが、/proc/self/という特殊なディレクトリはアクセスするプロセス自身の情報を管理するディレクトリとして働きます。
プロセス置換で現れる/dev/fdというのは、この特殊ディレクトリの配下の/proc/self/fd/へのシンボリックリンクになっているため、/dev/fd/Xは/proc/self/fd/Xと等価であり、その内容もプロセス毎に変化することになります。なので、シンボリックリンク名/dev/fd/Xの衝突が問題にならないのです。 - アクセス中のファイル実体へのシンボリックリンク機能
/proc/プロセスID/fd/あるいは/proc/self/fd/以下は、当該プロセスがアクセスしているファイル実体へのシンボリックリンクが、ファイルディスクリプタの番号に応じて procfsの機能により配置されています。これは、実体がパイプのような無名ファイルであっても使える優れものです。
参考:「Linuxのファイルの種類」の使用中のファイルを参照するシンボリックリンク
ただし、プログラムが/dev/fd/X( =/proc/self/fd/X) の形式でアクセスするためには、既にファイルディスクリプタ X を通じてパイプ実体へ接続されていなければなりません。
これまで出てきた「直接使われない経路」というのは、実はこの/dev/fd/Xを作り出すために存在する、パイプへのアクセス経路を確保するためのものだったのです。
procfsでの見え方
では実際に、プロセス置換を使った場合に procfs 上でファイルアクセス状況がどう見えるか、例を挙げます。
ここで実行コマンドは tee >( cat -n > save.out ) とします。
pstree でプロセスの親子関係を見ると次のようになります。
なお、この例ではシェルのPIDが213、プロセス置換によってできるシンボリックリンク名は /dev/fd/63 となっています。
$ pstree -ap 213
bash,213
├─bash,329
│ └─cat,331 -n
└─tee,330 /dev/fd/63
この状況で、主体となっている tee ( PID 330 )、プロセス置換で実行されている cat ( PID 331 ) それぞれのファイルアクセス状況は、procfs上で次のように見えます。
angel:~$ ls -l /proc/{330,331}/fd
/proc/330/fd:
total 0
lrwx------ 1 angel angel 0 Nov 28 21:47 0 -> /dev/tty1
lrwx------ 1 angel angel 0 Nov 28 21:47 1 -> /dev/tty1
lrwx------ 1 angel angel 0 Nov 28 21:46 2 -> /dev/tty1
l-wx------ 1 angel angel 0 Nov 28 21:47 3 -> 'pipe:[384]'
l-wx------ 1 angel angel 0 Nov 28 21:46 63 -> 'pipe:[384]'
/proc/331/fd:
total 0
lr-x------ 1 angel angel 0 Nov 28 21:47 0 -> 'pipe:[384]'
l-wx------ 1 angel angel 0 Nov 28 21:47 1 -> /tmp/save.out
lrwx------ 1 angel angel 0 Nov 28 21:46 2 -> /dev/tty1
ここで出てくる pipe:[384] というのがパイプ実体を表しています。これは実際のファイル名ではなく、kernel 内部の inode 384番で管理されている無名パイプです。
tee の方はファイルディスクリプタ63番への経路を元に /dev/fd/63 を open し、結果ファイルディスクリプタ3番での接続を実際の出力に使っています。
cat の方はシェルによるつなぎ替えによって、標準入力 ( ファイルディスクリプタ0番 ) で同じパイプに接続されていることが分かります。
その他の使い方
最後の話題として、最近他の方のアイデアで興味深いものを見かけたため、紹介したいと思います。
名前付きパイプの代替
このプロセス置換も、ファイル名ベースでパイプに接続できるため、単純に使ったとしても名前付きパイプに近いのですが、しかしそのファイル名は「その場限り」になってしまうため、複数回のコマンド実行を通じて使える、本当の名前付きパイプとは少し違うところがあります。
しかし、Linuxであれば次のようにして、かつ一時的な名前付きパイプを作らずに、プロセス置換を名前付きパイプの代替とできるのではないかと分かりました。
※オリジナルのアイデアは、Bashのファイルディスクリプタを名前付きパイプのように使ってよいか(teratail) によるものです。
典型的には次のような手順になります。
-
exec {tp}< <(:)でテンポラリなパイプの作成と、ファイルディスクリプタの割り当て -
/dev/fd/$tpを出力ファイルとするプログラムの実行 ( バックグラウンド ) -
/dev/fd/$tpを入力ファイルとするプログラムの実行
※<&$tpによる入力リダイレクトでも可 -
exec {tp}<&-でファイルディスクリプタの解放
ファイルディスクリプタを割り当てている間、/dev/fd/$tp が一時的な名前付きパイプの代わりに使えるということです。なお、手順中出てくる tp はファイルディスクリプタを保存する変数名であり、好みの文字列に替えて構いません。
実際に名前付きパイプを使用するのは難しい面がある ( 条件を整えれば不要になることも多い ) のですが、一例として次のような場面で試してみました。
- 2ホスト(shost,dhost)間のSSHベースのファイル転送
- ただし直に通信ができないため、中継ホスト上から各ホストへSSH接続して中継する
- SSHは鍵認証ができない環境のため、パスワード認証でなんとかする
- 容量の関係上中継ホストには中間ファイルを残さない
- 帯域の問題から、通信速度に上限を設ける
要は scp の -3 オプション ( 中継ホストを介した remote-remote ファイル転送 ) 相当、あるいは帯域制限やパスワード認証の問題がなければ ssh shost cat FILE | ssh dhost 'cat > FILE' ができれば良かったところですが、これをパイプの仲介による scp,ssh の連携 ( scpがパイプラインの場合の前段 ssh shost cat FILEの代わりになる ) で実現したということです。
操作は次のようになります。
$ exec {tp}< <(:)
$ scp -l 10000 suser@shost:in.dat /dev/fd/$tp # 10000Kbpsに帯域制限
suser@shost's password:
^Z
[1]+ Stopped scp -l 10000 suser@shost:/tmp/zero.dat /dev/fd/$tp
$ ssh duser@dhost 'cat > out.dat' <&$tp
duser@dhost's password:
^Z
[2]+ Stopped ssh duser@dhost 'cat > out.dat' 0<&$tp
$ bg
[2]+ ssh duser@dhost 'cat > out.dat' 0<&$tp &
$ fg %1
scp -l 10000 suser@shost:in.dat /dev/fd/$tp
$ exec {tp}<&-
[2]+ Done ssh duser@dhost 'cat > out.dat' 0<&$tp
$
途中、^Z とあるのは、Ctrl-Z 入力により、パスワード認証成立直後のscp,ssh コマンドを一時停止しているものです。そうして、フォアグラウンド実行・バックグラウンド実行を調整して、並列に処理を走らせています。
終わりに
プロセス置換は、パイプラインと並び、あるいはそれ以上に、複数プログラム間のデータ連携に有用な機能です。この記事で機能やイメージを把握し、より活用につなげて頂ければ幸いです。