はじめに
動機
かなり初心者AdventCalendarにかこつけてみました。Linuxのシステムを運用する人であれ、プログラム開発をする人であれ、標準入力・標準出力という言葉には日常的に触れることかと思いますが。いまいちまだ良くわけが分かってないという人の助けになれば、ということで記事にしてみました。
辞書での定義は?
世の中にはIT用語辞典というのがありますね。そういったものを読めば分かるのではないでしょうか。標準入力の方を引いてみましょう。
(Weblio辞書より)
標準入力とは、UNIX環境でのキーボードに相当する装置のことである。
ふむふむなるほど。キーボードなんですね。と納得しかけた人は、いまいちど考え直してみることをお勧めします。辞書だからといって無条件に信用してはいけません。これは悪い部類の説明です。
(e-Wordsより)
標準入力とは、コンピュータ上で実行されているプログラムが、特に何も指定されていない場合に標準的に利用するデータ入力元。
こちらの説明はマトモです。うんそうだよね trivial だよ、という人はおそらくこれ以上読み進む必要はないでしょう。…が、「結局『標準』って言われても、じゃあ、なんやねん!?」という人もいるのではないでしょうか。
そういった方に続きを読んで貰えれば幸いです。
本題の前に
入力と出力ってなに?
よく見ると ( 見なくても ) 標準入力・標準出力というのは「標準の」「入力と出力」です。それでは入力と出力ってのが何か? 明らかにする必要があるでしょう。
一般に入力・出力というとそれなりに広い概念です。が、ここで扱っているのはファイルとしての入力・出力、つまりファイルからデータを読み込む、ファイルにデータを書き込むといった操作やデータの流れを指します。
「あれ? でもキーボードから打ち込んで…というのもファイルなのか?」と違和感を感じられるかも知れません。が、これはある意味Linux ( UNIX系OS ) の流儀です。通常のファイルも含め、バイト列としてデータを読み込んだり書き込んだり、どちらかができるものをファイルとして扱うという決めごとなのです。このファイルの中には、ネットワーク通信を行うための、ソケットと呼ばれるモノすら含まれます。
通常のファイル以外は「特殊 ( スペシャル ) ファイル」と呼ばれます。中にはファイル名を指定して操作することができるもの ( 有名どころでは/dev/nullとか ) もありますが、一時的に扱うものだと、ファイル名が特に与えられない、無名のモノも出てきます ( パイプやソケットなど )。
もちろん、扱う対象によって、できる操作というのは色々変わってきます。例えば通常のファイルであれば、最初からある程度データを読み込んだ時点で、また先頭に戻って読み込み直すといった操作ができますが、磁気テープという装置 ( /dev/st0等のファイル名の特殊ファイル ) は、一度データを読み出すと、明示的にテープを巻き戻すコマンドを実行しないと、また最初から読むことはできません。
ですが、「順々にデータをバイト列として取り出せる」「順々にデータをバイト列として流し込める※」どちらかあるいは両方を行うことができるのは共通です。この性質の持つものを、なんであれファイルという共通の概念で扱いましょう、ということです。
※注: 「流し込める」というのは、本当に最低限流し込めるだけであって、それがどこかに保存されるといったところまで必ずしも保証されていないことに注意が必要です。とはいえもちろん、通常のファイルであれば、流し込んだデータが保存されることは期待できますけれども。
明示的な入力・出力と標準入力・標準出力
明示的な入力・出力
さてそれでは、入力・出力の例としてどのようなものがあるでしょうか。例としてLinuxで良く使うcpコマンドを見てみます。
cp file1 file2というコマンドを実行すると、file1というファイルをfile2にコピーするという処理を実行します。これは、file1からファイルの内容の読み込みを行い、file2へ書き込みを行うというもので、次の図のように入力・出力が発生します。
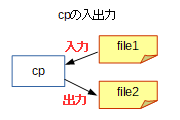
この時、cpは明示的にfile1を入力元、file2を出力先として使います。いや、コマンドでそう指定したんだから当たり前だろうと思うかも知れませんが。もう一例見てみます。
今度はgzip file1というコマンドを実行した例です。同じようにfile1を入力元とし、今度出力先はfile1.gzという圧縮ファイルとなります。
※圧縮処理が終わったあと、gzipはfile1を削除してしまいますが、そのことは置いておきます。
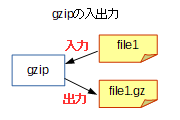
file1.gzを出力先にするのはそれは当たり前だろうと思うでしょうか。file1をターゲットに選んだんだから、それに合わせて.gzを付けたんだろう、とも言えますし、こちらは特に何もしていしなくてもgzipが勝手にファイル名を考えたんだ、とも言えます。
いずれにせよ、コマンドを指示した側の思惑があるにせよ、これらの例ではcp,gzipが入力元・出力先のファイルを選んでいるというところは共通しています。これを明示的と、ここでは表現しています。
なお、誤解があるといけないのは、入力・出力というのはファイルそのものではないというところです。ファイルに対して読み書きするためのデータの経路、そちらの方を指しています。
※これはOSの内部的にはファイルディスクリプタという数値で管理されています。
暗黙の入力・出力
では明示的の逆は考えられないでしょうか。つまり、暗黙の入力・出力です。
今度は、cpコマンドにちょっとオプションを追加してみます。
$ cp -v file1 file2
'file1' -> 'file2'
-vオプションの影響により、行われたコピー処理のサマリーが表示されます。…ということは、上で挙げたfile1,file2の入力・出力とは別に、この表示用の何かメッセージの出力が発生しているということです。
※この段階ではその出力先は詳らかとしません。
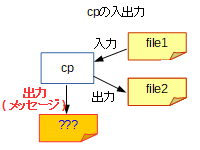
この時、cpはそのメッセージの出力先を自分で決めているのでしょうか。
…少なくとも、コマンドラインオプションその他でこちらからは指定していませんし、cpコマンドが自力で調べるというのも厳しいだろうというのは感じて頂けるでしょうか。
※何も情報はないけど、メッセージを出力する先を良い感じに自分で探し出す、というアプリをもし作るとしたら…、と考えてみて下さい。
ひょっとして「いや画面にメッセージを出すんだろ? 決まってるじゃないか」とお思いでしょうか…?
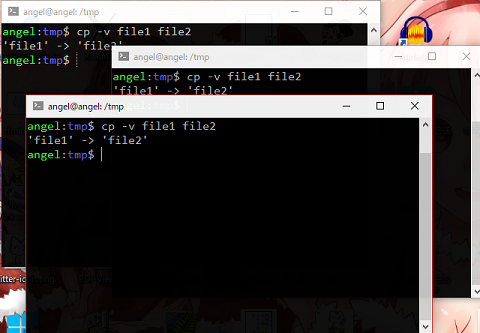
このような状況も有り得るわけで、どうやれば決定できるのでしょうか? というところまで意識していただければ、と思います。
実際問題として、先ほどの明示的な入力・出力と違い、cpはメッセージの出力先をどこにするか意識していません。これは暗黙の出力と言えます。
同じように、cpコマンドに-iオプションを指定した時。ファイルの上書きが発生する場面でy/nを指示する使いかたになります。これはcpにとってはy/nの入力を受け付ける訳ですが、これも入力元がどこかを意識はしません。暗黙の入力ということです。
標準入力・標準出力
ここまでで明示的、暗黙の入力・出力の2種類を挙げたことで、既にお察しのことかもしれませんが、標準入力・標準出力とは実はこの暗黙の入力・出力のことを指します。
言い換えると、コマンド/アプリ側で入力元・出力先を明示することなく使用できる入力・出力のことです。
これにはもう少し深い意味が含まれていることに注意する必要があります。それは、次のようなコマンド/アプリ開発者と使用者との間の約束事です。
- アプリ側では、標準入力・標準出力が暗黙の入力・出力として使えることを前提として良い。
- 標準入力・標準出力がどんなファイルに結び付けられているか、アプリ側で意識する必要はない。それはアプリ実行者が良いように用意しているはずだ。
- アプリ実行者には、そのアプリがどのように標準入力・標準出力を使うかを意識して、事前に適切な入力元・出力先を用意する義務がある。
なぜこのような設計にしたのか。それはLinuxの元となっているUNIXの思想の一部ではあると思うのですが、ただこうすることで、アプリ側はデータの流れがどこに繋がっているかを意識せず、データをどう加工するかに専念することができる、使用者側はアプリを使ってどのようにデータの流れを調整するかに注力する、そのような役割分担ができます。実際、パイプという機能を活用して処理を実現する場合、この役割分担を強く意識します。
アプリ作成者の立場として
3種類の標準
さて、上で約束事という言葉を使ったわけですが、実際に標準とされているのは実は3種類あります。
- 入力 … 標準入力の1系統
- 出力 … 標準出力、標準エラーの2系統
それぞれどのような役割を担うのか? それを決めるのは全く以てアプリ側の自由なのですが、ただ一般的な使われ方の傾向はあります。
再度cpコマンドの例を見てみます。今度は、処理のサマリーを出力する-vに、上書き確認を行う-iを追加し、実際にファイルの上書きが発生する状態を想定します。
$ cp -v -i file1 file2
cp: overwrite 'file2'? y
'file1' -> 'file2'
上書き確認のメッセージに対してyと答え、実際に上書きされたうえでサマリーが出力されている状況ですが、3種類が次のように使い分けられています。
- 標準入力 … 上書き確認y/nの入力
- 標準出力 … 処理のサマリーの出力
- 標準エラー … 上書き確認メッセージの出力
「え? 標準出力と標準エラー、何が違うの? 一緒じゃん」と思うなかれ。これはたまたま標準出力からの出力と標準エラーからの出力がまとめて見られる環境であるだけで、cpコマンド自体は内部で使い分けているのです。
実際の所は、アプリを開発する際、言語の持っている機能に沿って行けば良いのと思います。
例えばC++なら<iostream>のstd::cin,std::cout,std::cerrがそのまま標準入力、標準出力、標準エラーに対応しています。
RubyならSTDIN,STDOUT,STDERRといったオブジェクトがあるのはC++と同様で、getsやputsによる通常の入出力処理、warnによるエラー出力などでは特に意識しなくとも3種類の標準を自動的に利用してくれるようになっています。
ただ、一般的な傾向としては、次のようになるようです。
- 標準入力 … 加工対象のデータの入力元や、ユーザからのパラメータ入力受付用 (
cpでの上書き確認のy/n等 ) - 標準出力 … 加工済みデータの出力先や、ログ、メッセージ等情報出力用
- 標準エラー … 確認メッセージや警告、エラーといった情報の出力用
もちろん、この3種類の標準を使わなくとも、アプリ側で明示的に ( 必要ならばコマンドライン等で実行者から情報を貰って ) ファイルを扱うこともできます。もし標準を使うとしたら、という話です。
アプリ使用者の立場として
シェル上でのコマンド実行
こんどは使用者の立場としての話です。「事前に適切な入力元・出力先を用意する義務がある」と説明しました。が、それではどうやって用意すれば良いのでしょうか。
典型的な状況として、Linuxマシンに何らかの方法でログインし、シェル ( bash,zsh等 ) が起動している状況を考えてみます。
デフォルト
その中で1つの答えは。…。「特になにもしない」です。
何じゃそりゃ、と思われるかも知れませんが、シェルの標準入力・標準出力・標準エラーは既に用意されており、シェル上で起動したコマンドはそれらを引き継ぐからです。
シェルの標準入力は各種コマンドの入力用に、標準出力・標準エラーはプロンプトやらエラーメッセージやら様々な出力用に使われます ( 標準出力・標準エラーの使い分けはシェルにより様々です )。それが、そっくり起動されたアプリの入力・出力に使われるということです。
ちょうど次の図のようになります。
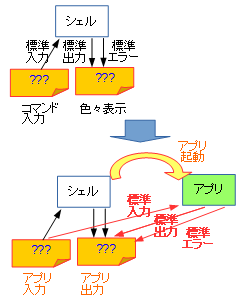
ちなみに、シェルからでなくてもLinux上で新しく(子)プロセス(アプリの実行単位のこと)を生成した場合、その標準入力・標準出力・標準エラーは生成元(親)プロセスのものを引き継ぐようになっています。
リダイレクト・パイプライン
しかし、シェルの標準入力等を引き継ぐだけでは大したことはできません。それで、どのシェルであっても、リダイレクト・パイプラインという入力・出力の調整方法が用意されています。
入力リダイレクトは、標準入力を指定のファイルに繋ぎ替える機能です。
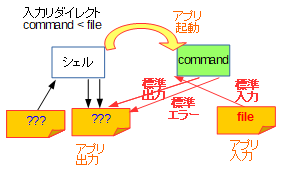
出力リダイレクトは、標準出力を指定のファイルに繋ぎ替える機能です。
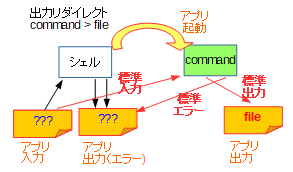
なおここでは紹介しませんが、標準エラーや、場合によっては標準でない入力・出力に関してもリダイレクト対象とする方法が、大抵のシェルでサポートされています。
そしてシェルでの処理の幅を大きく広げるのがパイプラインです。
パイプラインというのは、パイプという特殊ファイルを使って一方の出力がそのままもう一方の入力へ流れるように入力・出力を調整する方法を指します。次の図のように、入力・出力が繋ぎ替えられます。
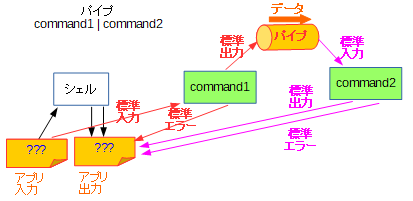
シェルがこのようにパイプを用意して仲介してあげることで、アプリ間でデータの遣り取りができるようになるわけです。
なお、ファイル名が与えられる訳ではないので実感し辛い面もありますが、パイプというのはデータがそのまま流れる土管のような役割を持った、特殊なファイルです。
くどいようですが、リダイレクトにせよ、パイプラインにせよ、標準入力や標準出力を繋ぎ替えるのはシェルの仕事です。起動されたアプリは、それらがどこに繋がっているのかを意識していません。パイプラインの場合にも、アプリ間でデータの遣り取りが行われてるなんてこと、当事者のアプリは意識しないのです。
シェル以外では?
Linuxを使う上では、ログインシェルからコマンドを実行する場面が多いとは言え、それ以外の状況というのも存在します。
例えば、cronジョブとしてスクリプトを実行する場合は? とか、systemdに登録してサービスとしてアプリを実行する場合は? とか…。それぞれの場面で、それぞれに標準入力・標準出力・標準エラーというのがあるはずです。
ただ、それらに関しては都度仕様を調べましょう、ということになるでしょう。
例えばsystemd配下のサービスの場合、標準出力・標準エラーは、journaldへのパイプに結び付けられ、出力がログとして逐次記録される、とか。( ※それも設定次第ですが )
いずれにせよ変わらないのは、アプリを実行する側が前もって入力・出力を用意すること、アプリは用意されている前提で動作すること、です。
その他の話題
キーボードと画面って?
ひょっとしたら、標準入力=キーボード、標準出力=画面というイメージを持っている方もいるかも知れません。「いやだって、キーボードから打ち込んだ文字がアプリに読み込まれて、アプリからのメッセージが画面に出てるでしょ?」という意見もあるでしょう。
実際問題として、ssh等の遠隔接続にせよ、ローカルでのCUI/GUIログインにせよ、シェルやその他アプリに入力するためにキーボードで操作しますし、出力を画面で確認しています。しかし、そのこととは区別する必要があります。
TTYとPTY
答えとしてはOSがあたかもキーボード+画面のような装置をエミュレートしている、そして関連するアプリが連携してデータを中継しているということになります。
今では画面、ディスプレイと言えば、様々なグラフィックの表示に対応しているものですが、最初からそうだったわけではありません。いやそもそも、遥か昔 ( Linuxもなかった頃ですが ) には、ディスプレイではなくて紙に印字された内容を見ていました。それに英字を入力するキーがセットになった、電動機械式のタイプライター、テレタイプ端末(TTY)です。
その後は、紙ではなくて文字表示機能を持ったディスプレイに表示するテキスト端末に置き換わり、そしてグラフィカルな表示が当たり前の今でも端末エミュレータというソフトとして生き残っています。上述のTTYという言葉はLinuxに残っていて、CUIログイン時の仮想コンソールを表す特殊ファイル名が/dev/tty1,/dev/tty2,…となっています。
これはかつてのTTYのように、あたかもキーボードから打ち込まれたかのようにデータを読み込み、あたかも画面へ文字を送るかのようにデータを書き込むことができます。CUIログインすると、ログインシェルはこのファイルを標準入力・標準出力・標準エラーに結び付けた状態になります。
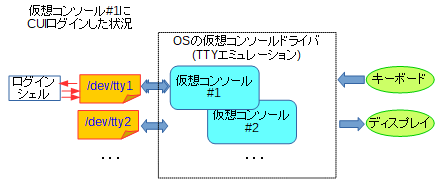
しかしながら、Linuxマシンに直接CUIログインする、という状況は実はそれほどなくて、GUIのターミナルであったり、遠隔でのログインでシェルが起動する状況の方が圧倒的に多いと思います。その時は、擬似(pseudo)TTYということでPTYが使われます。
PTYはマスター・スレーブの2種類のファイルの間をOSがデータを仲介する形態をとります。
例えば、gnome-terminalのようなGUIターミナルからシェルを経由した場合、あるいはputtyのようなSSHクライアント兼ターミナルエミュレータでSSHログインした場合、以下のような状況になります。
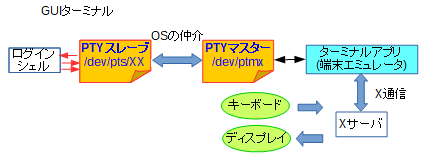
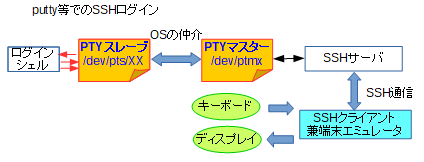
これらの状況を省略して、「シェルの標準入力はキーボード、標準出力・標準エラーは画面ですよ」というのは気持ちとしては良く分かりますし已むを得ないとは思うのですが、あくまでそのようにエミュレートするために各所連携してデータを中継している、というのは頭の片隅に置いて頂ければ、と思います。
ソケットへのリダイレクト
最初にファイルについて「このファイルの中には、ネットワーク通信を行うための、ソケットと呼ばれるモノすら含まれます」と説明しました。
加えて「アプリは標準入力等がどのファイルに接続されているかは意識しない」とも。
それであれば、アプリ側で特に通信処理を意識していなくとも、リダイレクトを用いることで、ネットワーク通信が行えるのではないでしょうか。
実は一部のシェルでは、ネットワーク通信用のソケットにリダイレクトを行うことができます。
bash$ head -n 1 < /dev/tcp/smtp.gmail.com/587
220 smtp.gmail.com ESMTP 69sm21462633pft.11 - gsmtp
これは、bashの機能を利用して、GmailのSMTPサーバに接続した時に送信されてくるメッセージを出力する例です。
bashでは、/dev/tcp/(IPアドレスまたはホスト名)/(ポート番号) という特定文字列 ( 実際に存在するファイル名ではない ) をリダイレクト先に指定することで、ソケットへのリダイレクトが行えます。この場合、smtp.gmail.comというSMTPサーバのTCP587番(submissionポート)との通信を指定したことになります。
headコマンドは、もちろん、それ自身にTCP通信機能はありません。しかし、入力・出力ができるという意味ではソケットも同じファイルであるため、headの入力処理で通信ができてしまうわけです。これを応用すれば、通信処理を明示的にアプリだけでも、リダイレクトを併用することで、通信を実現することも可能です。
ただし、本格的に通信処理を行う場合には、色々調整すべき事項があり、単純な入力・出力処理ではやはり力不足です。あくまで可能というだけであって、それで実際に処理を組むことは、あまりお勧めはしません。
まとめ
- Linuxでのファイルとは、一般のファイルも含め、データを読み込んだり書き込んだりできるもの
- 入力・出力とはファイルに対して読み書きする経路のこと
- 明示的にファイルを指定する入力・出力と、暗黙のうちに使用する入力・出力がある
- 暗黙のうちに使用できる入力・出力として、標準で3種、標準入力・標準出力・標準エラーが用意されている
- アプリを実行する側で、適切に標準入力・標準出力・標準エラーに結び付けるファイルを用意すること
- 特になにもしなければ、実行元の標準入力・標準出力・標準エラーが実行されたアプリに引き継がれる
- シェル上で入力・出力を調整する方法としてリダイレクト・パイプラインがある
- ログインシェルに接続されているのはキーボード・画面そのものではない。代わりに両者がセットになった装置をエミュレートしたものとしてTTY,PTYが接続されている。