n8nで作る音声チャットフロー(macOSローカル環境)
macOS上に構築した n8n を使って、
- 音声入力
- 音声認識(Speech-to-Text)
- LLMによる応答生成
- 音声合成(Text-to-Speech)
- Webhookでブラウザに返却
までを自動化する方法を紹介します。
🎯 ゴール
- 音声をWebhookに送信するとテキストに変換される
- LLMが会話履歴を考慮して自然な応答を生成する
- 応答を音声に変換して返す
- ブラウザ上でそのまま再生できる
🏗️ 全体構成
- Webhook: 音声ファイルを受け取る
- Speech-to-Text: 音声をテキストに変換
- Memory Manager / Buffer Memory: 会話履歴を保持
- LLM(Geminiなど): 応答を生成
- Text-to-Speech(ElevenLabs API、Fish Audio、MiniMax Audio): 音声を合成
- Respond to Webhook: 音声を返す
📝 手順
1. Webhookで音声を受け取る
- ノード: Webhook
- 設定:
- Path:
voice_message - HTTP Method:
POST - Response Mode:
Response Node
- Path:
送信例(curl):
curl -X POST http://localhost:5678/webhook-test/voice_message \
-H "Content-Type: multipart/form-data" \
-F "voice_message=@sample.m4a"
2.音声をテキスト化する
• ノード: OpenAI - Speech to Text
設定:
• Resource: audio
• Operation: transcribe
• Binary Property Name: voice_message
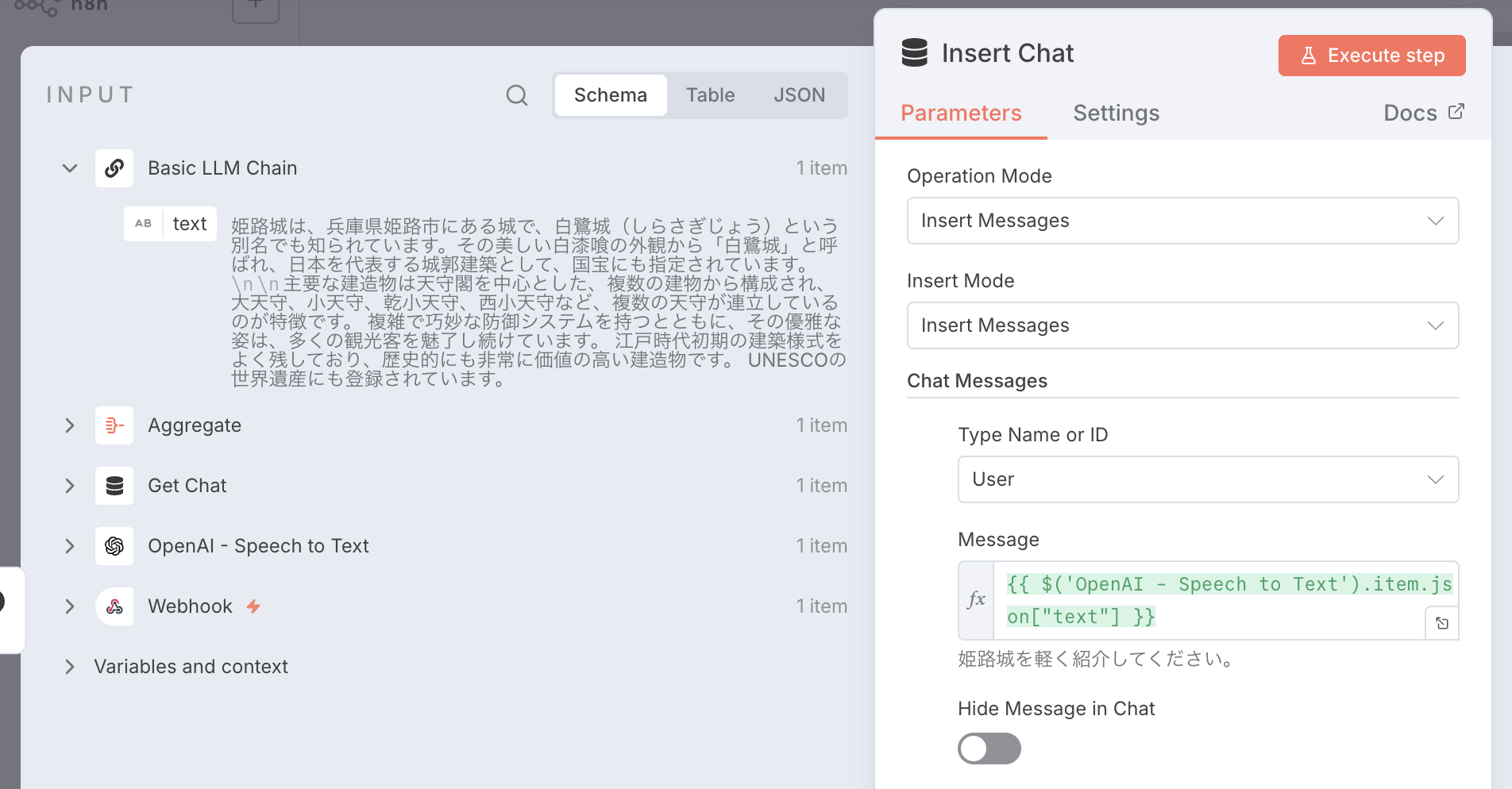
3. 会話履歴を管理する
• Get Chat: 過去の履歴を取得
• Aggregate: 履歴をまとめる
• Insert Chat: 新しい会話を保存
• Window Buffer Memory: セッション単位で履歴管理
これにより、LLMが過去のやり取りを踏まえて回答できます。
4. LLMで応答を生成
• ノード: Basic LLM Chain
• モデル例: Google Gemini Chat Model
設定:
• プロンプトに「過去の会話を考慮する」よう指示
5. 応答を音声に変換する
• ノード: HTTP Request
• サービス: ElevenLabs API
設定例:
POST https://api.elevenlabs.io/v1/text-to-speech/{voice_id}
Headers:
Content-Type: application/json
xi-api-key: YOUR_API_KEY
Body:
{
"text": "={{ $('Basic LLM Chain').item.json.text }}"
}
6. Webhookで音声を返す
• ノード: Respond to Webhook
設定:
• Respond With: Binary
• Binary Property: data
• Response Content Type: audio/mpeg
• Response Headers: Content-Disposition: inline(任意)
これでWebhookをブラウザで開くと、そのまま音声が再生されます。
✅ まとめ
音声入力 → テキスト化 → 応答生成 → 音声合成 → 音声返却 をn8nだけで実現可能
ElevenLabs API、Fish Audio、MiniMax Audioなどを使えば高品質な音声を返せる
Webhookレスポンスを工夫することでブラウザで直接再生も可能
ローカルのn8n環境でも十分に「音声チャット体験」を構築できます。
自分の声で質問して、AIが自然に返答してくれる環境を作ってみてください 🚀
